spark-datafusion-comet-benchmark
Apache Spark with Apache DataFusion Comet Benchmarks
Apache Spark powers large-scale analytics, but its JVM-based execution faces performance limitations. Apache DataFusion Comet attempts to address this by offloading compute operations to a native Rust execution engine built on Apache Arrow DataFusion.
This benchmark evaluates Comet's performance on Amazon EKS using the TPC-DS 3TB workload.
Our TPC-DS 3TB benchmark shows that Apache DataFusion Comet (v0.17.0) delivered:
- 34% faster overall on Parquet — most queries improved by up to 73%, with only a single query (~37%) regressing.
- 40% faster overall on Iceberg — most queries improved by up to 72%, with only a single query (~23%) regressing.
TPC-DS 3TB Benchmark Results
Summary
Our TPC-DS 3TB benchmark on Amazon EKS demonstrates that Apache DataFusion Comet (v0.17.0) provides an overall speedup compared to native Spark SQL on both Parquet and Iceberg table formats, with individual queries varying from ~73% faster to ~37% slower.
- Parquet
- Iceberg
| Name | Completion Time (seconds) | Speedup |
|---|---|---|
| Native Spark | 3,650.56 | Baseline |
| Comet | 2,416.71 | 34% faster |
| Name | Completion Time (seconds) | Speedup |
|---|---|---|
| Native Spark | 4,665.47 | Baseline |
| Comet | 2,803.80 | 40% faster |
Benchmark Infrastructure
Benchmarks ran sequentially on the same cluster to ensure identical hardware and eliminate resource contention. Native Spark executed first, followed by Comet.
To ensure an apples-to-apples comparison, both native Spark and Comet jobs ran on identical hardware, storage, and data. Only the execution engine and related Spark settings differed.
Test Environment
| Component | Configuration |
|---|---|
| EKS Cluster | Amazon EKS 1.34 |
| Node Instance Type | r8gd.12xlarge (48 vCPUs, 384GB RAM, 1.8TB NVMe SSD) |
| Node Group | 4 nodes dedicated for benchmark workloads |
| Executor Configuration | 23 executors × 5 cores (requests) × 58GB RAM each |
| Driver Configuration | 5 cores × 20GB RAM |
| Dataset | TPC-DS 3TB (Parquet format) |
| Storage | Amazon S3 with optimized S3A connector |
Spark Configuration Comparison
| Configuration | Native Spark | Comet |
|---|---|---|
| Spark Version | 3.5.8 | 3.5.8 |
| Comet Version | N/A | 0.17.0 |
| Java Runtime | OpenJDK 17 | OpenJDK 17 |
| Execution Engine | JVM-based Tungsten | Rust + JVM hybrid |
| Key Plugins | Standard Spark | CometPlugin, CometShuffleManager |
| Off-heap Memory | 32GB enabled | 32GB enabled |
| Memory Management | JVM GC | Unified native + JVM |
| memoryThrottlingFactor | 0.7 | 0.7 |
Critical Comet-Specific Configurations
# Essential Comet Configuration
"spark.plugins": "org.apache.spark.CometPlugin"
"spark.shuffle.manager": "org.apache.spark.sql.comet.execution.shuffle.CometShuffleManager"
# Memory Configuration - Critical for Comet
"spark.memory.offHeap.enabled": "true"
"spark.memory.offHeap.size": "32g" # Required: 16GB minimum, 32GB recommended
# Comet Execution Settings
"spark.comet.exec.enabled": "true"
"spark.comet.exec.shuffle.enabled": "true"
"spark.comet.exec.shuffle.mode": "auto"
"spark.comet.explainFallback.enabled": "true"
"spark.comet.cast.allowIncompatible": "true"
"spark.comet.dppFallback.enabled": "true"
# AWS-Specific: Required for S3 region detection
"spark.hadoop.fs.s3a.endpoint.region": "us-west-2"
Performance Results
- Parquet
- Iceberg
Overall Performance
| Name | Completion Time (seconds) | Performance |
|---|---|---|
| Default | 3,650.56 | Baseline |
| DataFusion Comet 0.17.0 | 2,416.71 | 1.51× (+34% time) |
Performance Distribution
| Performance Range | Query Count | Percentage |
|---|---|---|
| 20%+ improvement | 81 | 79% |
| 10-20% improvement | 16 | 16% |
| ±10% | 5 | 5% |
| 10-20% degradation | 0 | 0% |
| 20%+ degradation | 1 | 1% |
Top 10 Query Improvements
| Query | Default (s) | DataFusion Comet 0.17.0 (s) | Speedup |
|---|---|---|---|
| q56-v4.0 | 5.8 | 1.5 | 3.75× (+73%) |
| q58-v4.0 | 5.4 | 1.8 | 2.99× (+67%) |
| q67-v4.0 | 141.2 | 50.5 | 2.80× (+64%) |
| q97-v4.0 | 43.3 | 17.1 | 2.54× (+61%) |
| q65-v4.0 | 43.6 | 17.7 | 2.47× (+59%) |
| q38-v4.0 | 27.6 | 12.0 | 2.30× (+57%) |
| q83-v4.0 | 2.8 | 1.2 | 2.29× (+56%) |
| q87-v4.0 | 27.7 | 12.2 | 2.27× (+56%) |
| q18-v4.0 | 22.0 | 9.8 | 2.25× (+56%) |
| q81-v4.0 | 18.0 | 8.2 | 2.19× (+54%) |
Query Regressions
Out of 103 TPC-DS query variants, q50 was the single regression under DataFusion Comet 0.17.0 — running 37% slower (82.7s → 113.2s, 0.73×). Every other query matched or outperformed native Spark.
| Query | Default (s) | DataFusion Comet 0.17.0 (s) | Degradation |
|---|---|---|---|
| q50-v4.0 | 82.7 | 113.2 | 37% slower (0.73×) |
Notes on Performance Differences
Two systemic wins drive most of Comet's speedup at the app level: off-heap columnar execution nearly eliminates JVM garbage collection (app-wide GC time −95%, 10,053 s → 538 s) and native columnar shuffle slashes shuffle-read volume (−78%, 12.4 TB → 2.8 TB). Aggregate executor task-time dropped 33%, with disk spill at zero in both runs.
Comet Outperforms Most Queries:
Example - Query 56 (+73%)
- Plan went fully native: all 7 Parquet scans became
CometNativeScan, and the broadcast exchanges, broadcast hash joins, hash aggregates, and sorts all converted to their Comet equivalents — all 7ColumnarToRowbridges were removed (105 → 74 plan nodes). - Shuffle read collapsed 2,345 MB → 40 MB (−98%) and GC fell 1,921 ms → 0 ms, cutting stage-time from 16.8 s to 5.8 s.
- Root cause: A small aggregation/broadcast-join query offloaded end-to-end to Comet, where columnar shuffle removes ~98% of shuffle bytes and the JVM row-conversion/GC overhead disappears.
Example - Query 58 (+67%)
- Same full-native conversion pattern as q56 — scans, filters, broadcast joins, and hash aggregates all become Comet operators, with 7
ColumnarToRowbridges removed. - Shuffle read dropped 395 MB → 28 MB (−93%) and GC 714 ms → 12 ms, cutting stage-time from 11.7 s to 4.3 s.
- Root cause: Identical mechanism to q56 — a broadcast-join + aggregation query fully accelerated by native columnar execution and near-zero-overhead shuffle.
Example - Query 67 (+64%)
- A large rollup/window query (
Expand+Sort+ windowed ranking) that Comet runs natively asCometExpand+CometSort+CometSortMergeJoin. - GC dropped 97,470 ms → 2,030 ms (−98%) — vanilla Spark spent ~97 s of its 140 s in garbage collection; shuffle read also fell 59.5 GB → 31.2 GB (−48%).
- Root cause: A memory-/GC-bound query. Moving the large intermediate data off-heap into Comet's columnar engine almost eliminates the GC pauses that dominated the vanilla-Spark run.
Comet Underperforms on One Query:
Example - Query 50 (-37%)
- Comet still won on the systemic metrics — GC 38,079 ms → 72 ms and its scan stages were faster (36.6 s → 23.6 s) — but the loss is isolated to a single stage: the large
store_sales ⋈ store_returnssort-merge-join + sort reducer. - That stage ran ~2× slower under Comet (
CometSortMergeJoin+CometSort, 90.0 s) than Spark's whole-stage-codegen SMJ + Sort (45.9 s). The +44 s from the slower native join/sort outweighs the −13 s saved on scans, netting +31 s. - Root cause: Comet's native sort-merge-join + sort path is currently ~2× slower than Spark's JIT-compiled codegen for this large fact-to-fact join, and that single stage dominates q50 — so its IO/GC savings cannot compensate.
DataFusion Comet v0.16.0 Results
Overall Performance
| Name | Completion Time (seconds) | Performance |
|---|---|---|
| Default | 3,650.56 | Baseline |
| DataFusion Comet 0.16.0 | 2,467.49 | 1.48× (+32% time) |
Performance Distribution
| Performance Range | Query Count | Percentage |
|---|---|---|
| 20%+ improvement | 68 | 66% |
| 10-20% improvement | 22 | 21% |
| ±10% | 10 | 10% |
| 10-20% degradation | 0 | 0% |
| 20%+ degradation | 3 | 3% |
Top 10 Query Improvements
| Query | Default (s) | DataFusion Comet 0.16.0 (s) | Speedup |
|---|---|---|---|
| q86-v4.0 | 12.8 | 3.7 | 3.47× (+71%) |
| q58-v4.0 | 5.4 | 1.8 | 2.98× (+66%) |
| q56-v4.0 | 5.8 | 2.0 | 2.96× (+66%) |
| q67-v4.0 | 141.2 | 50.7 | 2.79× (+64%) |
| q65-v4.0 | 43.6 | 17.3 | 2.52× (+60%) |
| q97-v4.0 | 43.3 | 17.4 | 2.49× (+60%) |
| q83-v4.0 | 2.8 | 1.2 | 2.37× (+58%) |
| q87-v4.0 | 27.7 | 12.5 | 2.21× (+55%) |
| q38-v4.0 | 27.6 | 12.5 | 2.20× (+55%) |
| q18-v4.0 | 22.0 | 10.1 | 2.18× (+54%) |
Top 3 Query Regressions
Only three queries showed regressions.
| Query | Default (s) | DataFusion Comet 0.16.0 (s) | Degradation |
|---|---|---|---|
| q39a-v4.0 | 5.1 | 7.2 | 42% slower (0.70×) |
| q39b-v4.0 | 4.7 | 6.7 | 41% slower (0.71×) |
| q50-v4.0 | 82.7 | 107.5 | 30% slower (0.77×) |
Notes on Performance Differences
Comet Underperforms on Some Queries:
Example - Query 39a (-42%)
- Plan is fully "Cometized" (no fallback, no row↔columnar transitions inside the pipeline). Wall regression is concentrated in two parallel "scan inventory + 3× BHJ + partial-agg" stages where DPP leaves a single ~20 MB matching Parquet file processed by one straggler task while every other task reads ~0 B.
- DPP collapses inventory to a single 20 MB partition that becomes a stage straggler; native scan + native partial-agg are slower than default's whole-stage-codegen on that single skewed task, and the larger straggler propagates a +1.82s delta into a +2.32s end-to-end regression.
Example - Query 39b (-41%)
- Plan is fully "Cometized"; the regression lives in two parallel
inventorypartial-aggregation stages (Comet 1444/1445 vs default 4051/4052) which contribute +1.541s of the +1.873s wall-clock delta. Heavy tasks process the same ~21 MB / 63 MB shuffle but Comet spends ~1.5s more wall and ~1.6s more CPU each. - Native
CometNativeScan → CometProject → CometBroadcastHashJoin × 3 → CometHashAggregate(stddev_samp+avg, 4-key group-by) → CometExchangepipeline burns more CPU per heavy task than Spark's whole-stage-codegen equivalent on this small ~180 MB dataset.
Comet Outperforms Most Queries:
Example - Query 86 (+71%)
- Default's dominant stage 5152 (Sort + SortMergeJoin + Expand + HashAggregate) ran 8.512s with 4.4 GB shuffle read, 320.3 MB peak on-heap memory, and 1.417s GC — Comet's equivalent stage 10295 finished in 914ms with stage shuffle read = 0 B and 0ms GC because AQE rewired the second join as a CometBroadcastHashJoin over a 6.1 MiB broadcast.
- AQE-driven SortMergeJoin → CometBroadcastHashJoin flip on the item side, enabled by Comet's denser columnar shuffle; eliminates the 4.4 GB SMJ shuffle read and the 320 MB on-heap aggregation buffer.
Example - Query 58 (+66%)
- All 3 SortMergeJoins (and 6 surrounding Sort nodes) in default's executed plan are absent in Comet's: the same 9 logical joins resolve as 8 CometBroadcastHashJoin + 1 BroadcastHashJoin after AQE.
- AQE chose broadcast joins everywhere under Comet, eliminating the 3 SMJ + 6 Sort pipeline; native CometExchange produced 29% smaller shuffle bytes on identical record counts.
Datafuison Comet V0.15.0 Results
Overall Performance
| Name | Completion Time (seconds) | Speedup |
|---|---|---|
| Native Spark | 3,650.56 | Baseline |
| Comet | 3,246.87 | 11% faster |
Performance Distribution
| Performance Range | Query Count | Percentage |
|---|---|---|
| 20%+ improvement | 32 | 31% |
| 10-20% improvement | 19 | 18% |
| ±10% | 44 | 43% |
| 10-20% degradation | 4 | 4% |
| 20%+ degradation | 4 | 4% |
Top 10 Query Improvements
| Query | Native Spark (s) | Comet (s) | Improvement |
|---|---|---|---|
| q5-v4.0 | 40.8 | 20.0 | 51% faster |
| q56-v4.0 | 5.8 | 3.0 | 49% faster |
| q41-v4.0 | 0.8 | 0.4 | 47% faster |
| q45-v4.0 | 12.3 | 7.0 | 43% faster |
| q9-v4.0 | 83.8 | 49.0 | 42% faster |
| q80-v4.0 | 32.6 | 20.1 | 38% faster |
| q58-v4.0 | 5.4 | 3.3 | 38% faster |
| q86-v4.0 | 12.8 | 8.1 | 36% faster |
| q83-v4.0 | 2.8 | 1.8 | 36% faster |
| q73-v4.0 | 3.4 | 2.2 | 36% faster |
Top 10 Query Regressions
| Query | Native Spark (s) | Comet (s) | Degradation |
|---|---|---|---|
| q32-v4.0 | 2.9 | 5.6 | 90% slower |
| q50-v4.0 | 82.7 | 111.5 | 35% slower |
| q39a-v4.0 | 5.1 | 6.3 | 23% slower |
| q68-v4.0 | 5.9 | 7.1 | 21% slower |
| q20-v4.0 | 5.1 | 5.8 | 14% slower |
| q30-v4.0 | 15.9 | 17.7 | 11% slower |
| q67-v4.0 | 141.2 | 156.8 | 11% slower |
| q25-v4.0 | 8.9 | 9.9 | 10% slower |
| q29-v4.0 | 34.4 | 37.8 | 10% slower |
| q91-v4.0 | 2.1 | 2.3 | 10% slower |
Notes on Performance Differences
Why Comet Underperforms on Some Queries:
Example - Query 32 (-90.1%)
- The regressing stages run identical Spark WholeStageCodegen in both apps -- no Comet operators are involved in the slow stages
- Comet's best iteration (2,132ms) is faster than Default's best (2,338ms); the median regression is driven by single-task stragglers reaching 7.1s (10.5x p50) in Comet vs 1.8s max in Default
- Measurement artifact from infrastructure-level straggler interference on a single task out of 118 in Comet's non-Comet scan stages, amplified by 6.6x wider iteration variance (range 8,856ms vs 1,351ms)
Example - Query 39a (-23.1%)
- Inventory scan stage median task time 35-77% higher in Comet (234ms vs 173ms) due to columnar shuffle serialization overhead
- CometColumnarExchange retained 200 partitions where Default used 7, inflating broadcast stage from 32ms to 358ms and producing 3.2x more shuffle data (23.3 MB vs 7.2 MB)
- Two compounding factors: slower scan-stage serialization to Comet's columnar format (+330-538ms), and CometColumnarExchange overriding the natural partition count with 200 partitions for a broadcast exchange that only needed 7
Why Comet Outperforms Some Queries:
Comet's native Rust execution engine excels at CPU-intensive operations
Example - Query 5 (+50.9%)
- Shuffle read on the SortMergeJoin stage dropped 92% (27.9 GB to 2.2 GB) due to Comet's native columnar shuffle for web_sales (2.16B rows)
- GC time in the scan stage dropped from 7,236ms to 77ms; CometSort was 56% faster than Spark Sort (13.9 min vs 31.9 min total)
- Comet's native scan-filter-exchange pipeline for web_sales produced compact Arrow columnar shuffle data, massively reducing downstream shuffle read and sort time in the join stage, with cascading contention reduction benefiting non-Comet stages
Example - Query 56 (+49.0%)
- AQE converted all three SortMergeJoins to BroadcastHashJoins because CometExchange reported customer_address shuffle size as 2.7 MiB (vs 10.7 MiB in Default), falling below the 10 MB broadcast threshold
- Combined join stage time dropped from 8.6s to 1.4s; GC dropped from 2.8s to 206ms
- Comet's Arrow columnar shuffle encoding produced a more compact representation that caused AQE to select broadcast joins, eliminating sort buffers, shuffle overhead, and GC pressure from sort buffer allocation
Resource Usage Analysis
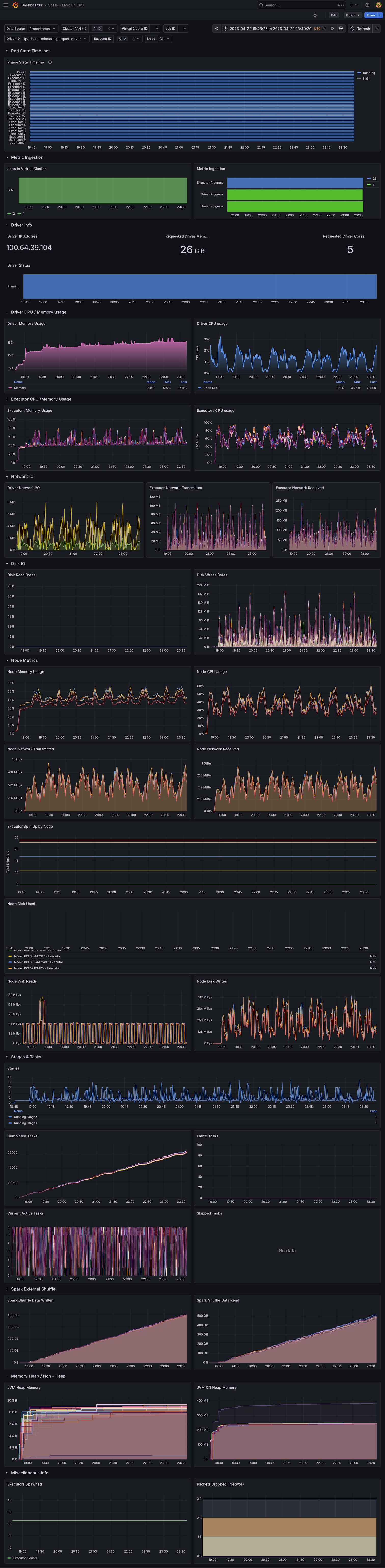
Both benchmarks ran sequentially on identical hardware to enable direct comparison.
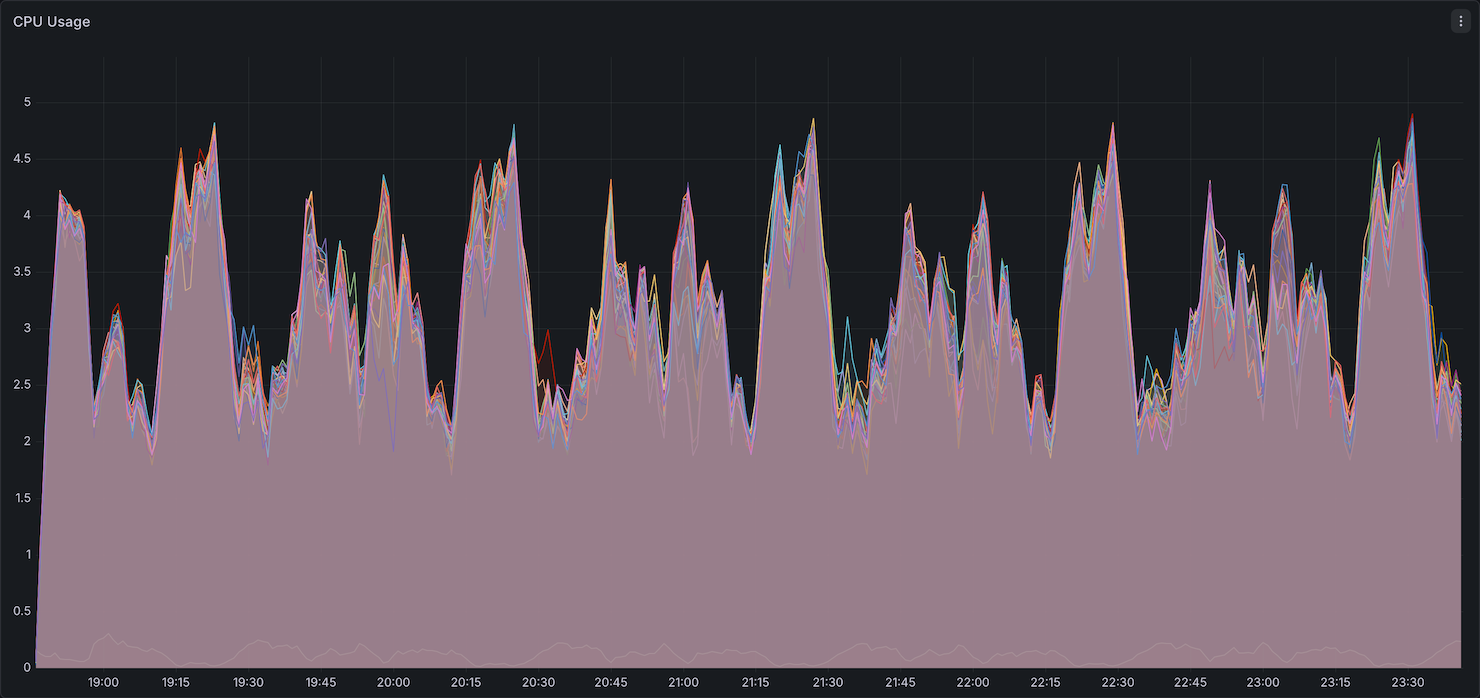
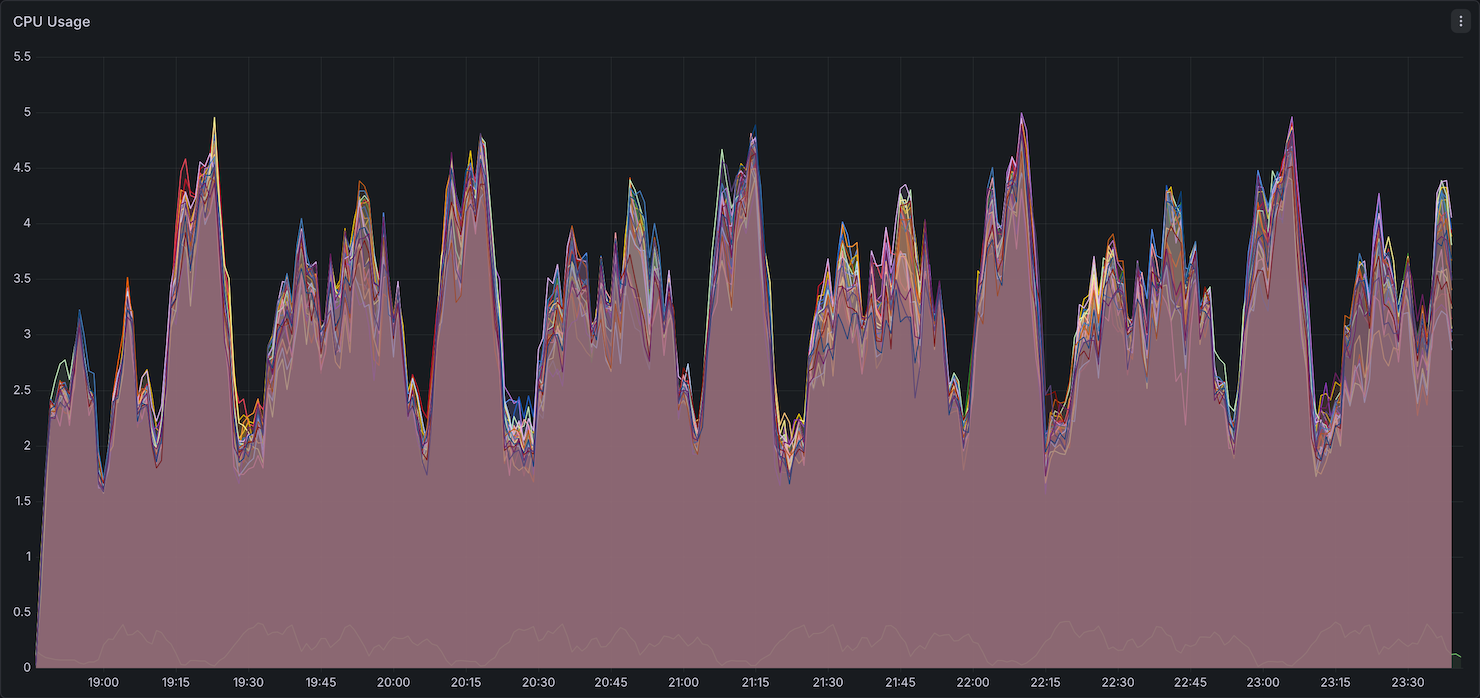
CPU Utilization
CPU utilization showed similar patterns between Native Spark and Comet, with both sustaining comparable peak and average usage throughout the benchmark.
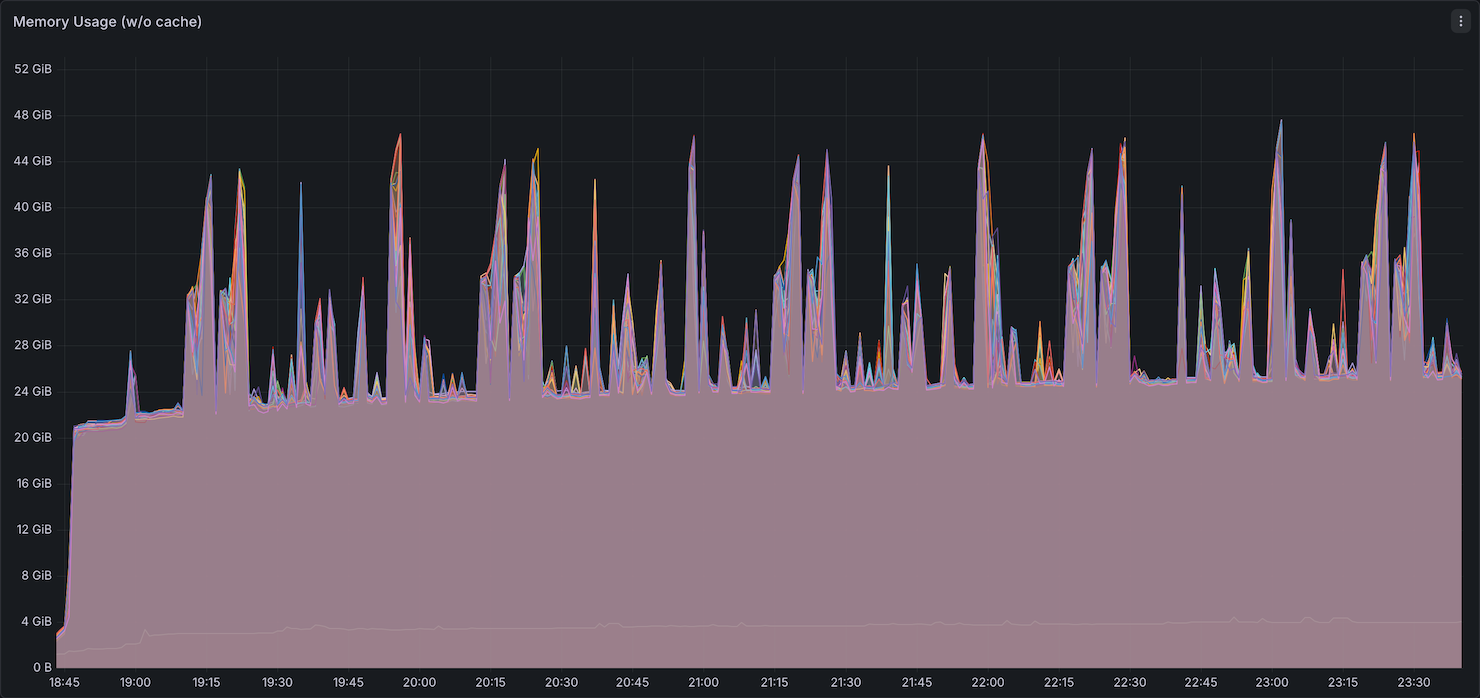
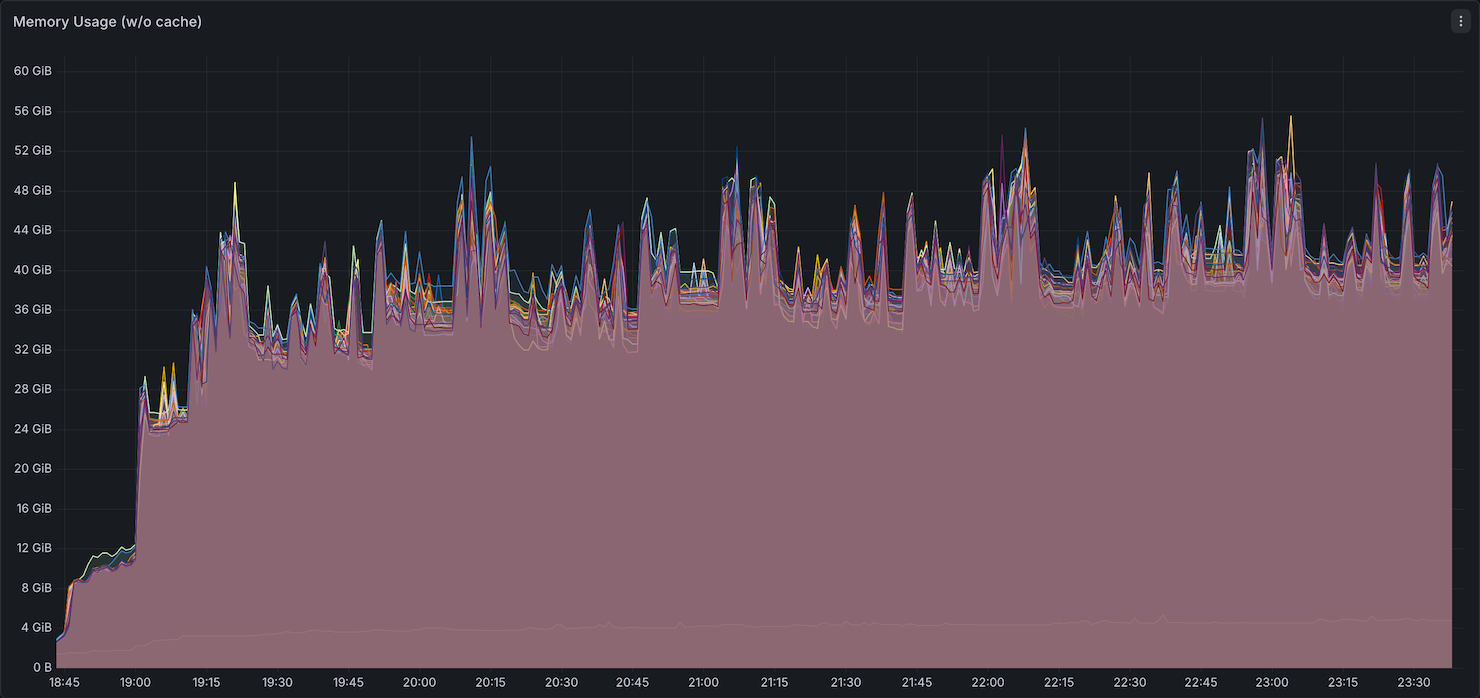
Memory Utilization
Comet consumed more memory than Native Spark, peaking around ~52GB compared to ~48GB for Native Spark. Native Spark's memory usage returned to a baseline of ~20GB between queries, while Comet remained elevated. This is expected — Comet offloads most compute operations to its native Rust engine using off-heap memory, so the JVM heap sees less activity while native allocations persist between queries. This suggests that on-heap JVM memory per executor could potentially be reduced when running Comet, shifting the memory budget toward off-heap allocation.
Network Bandwidth
Network bandwidth was comparable between Native Spark and Comet, with both showing similar transmit and receive throughput.
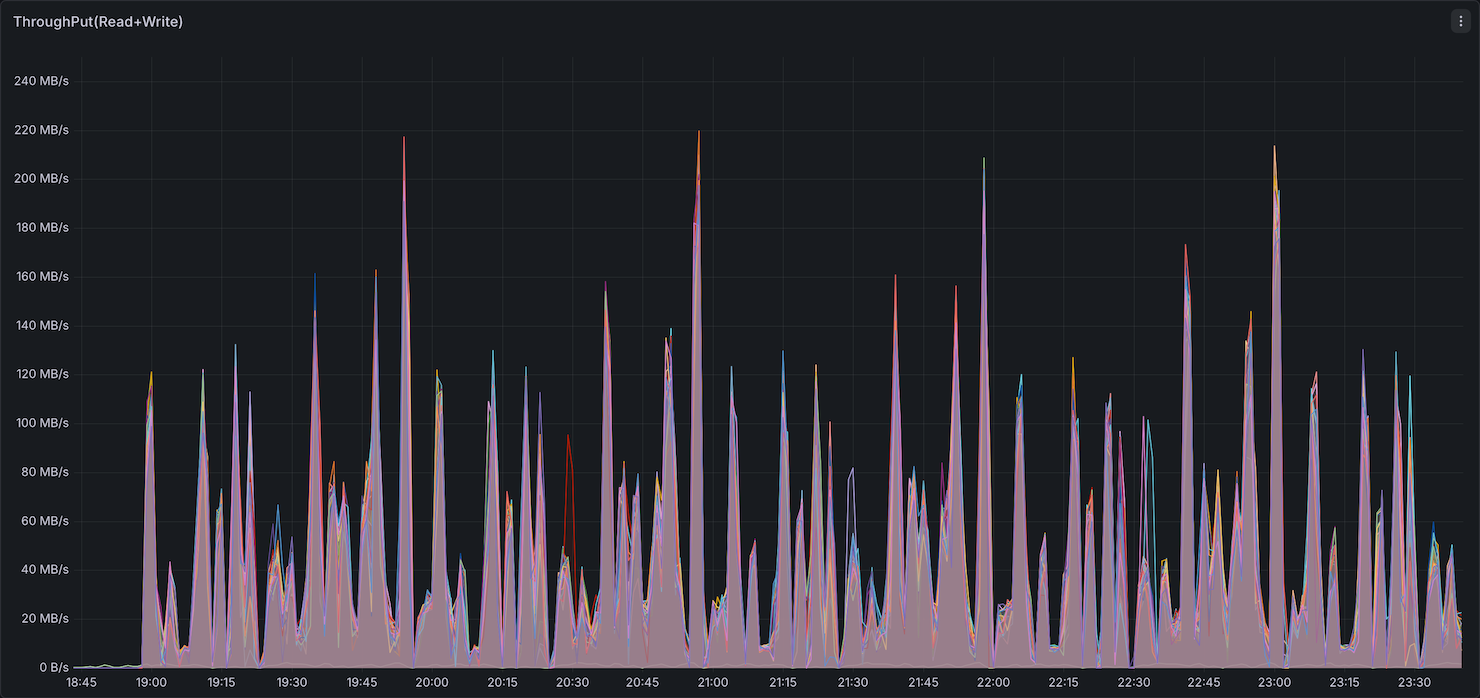
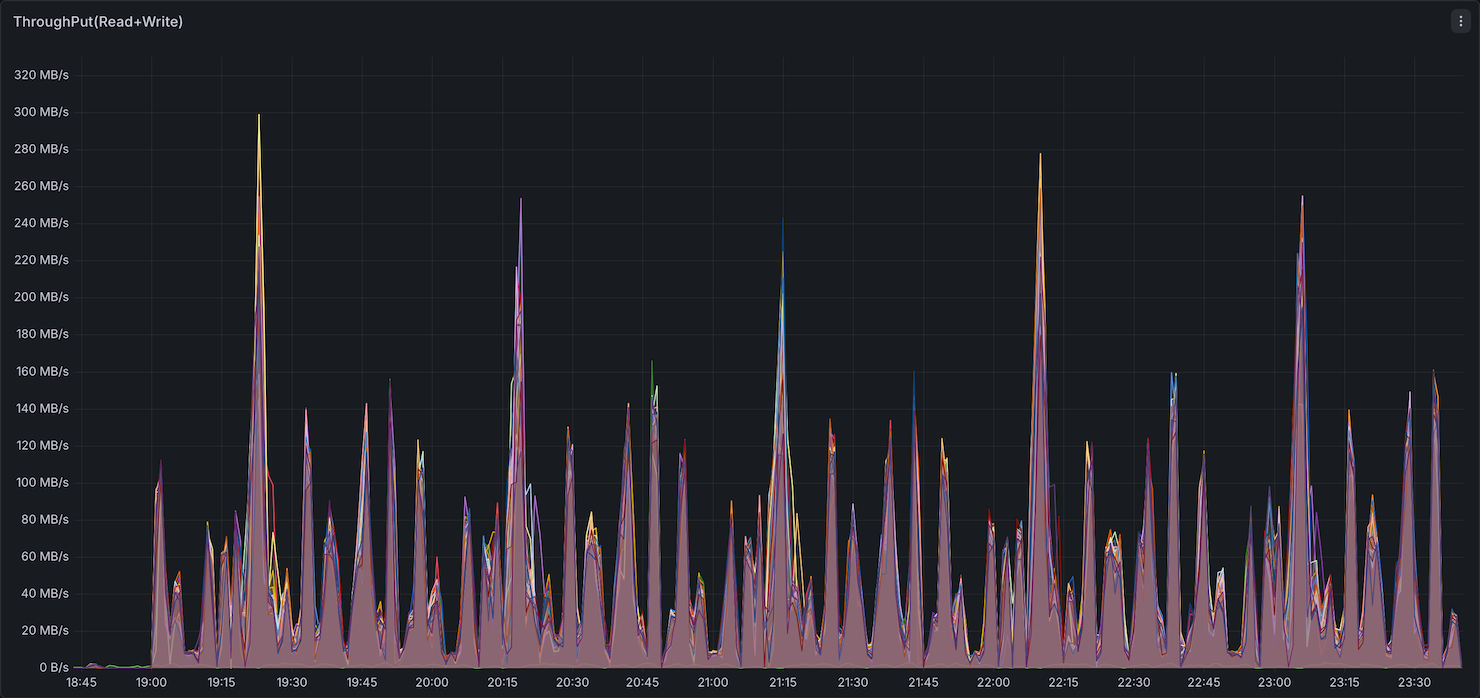
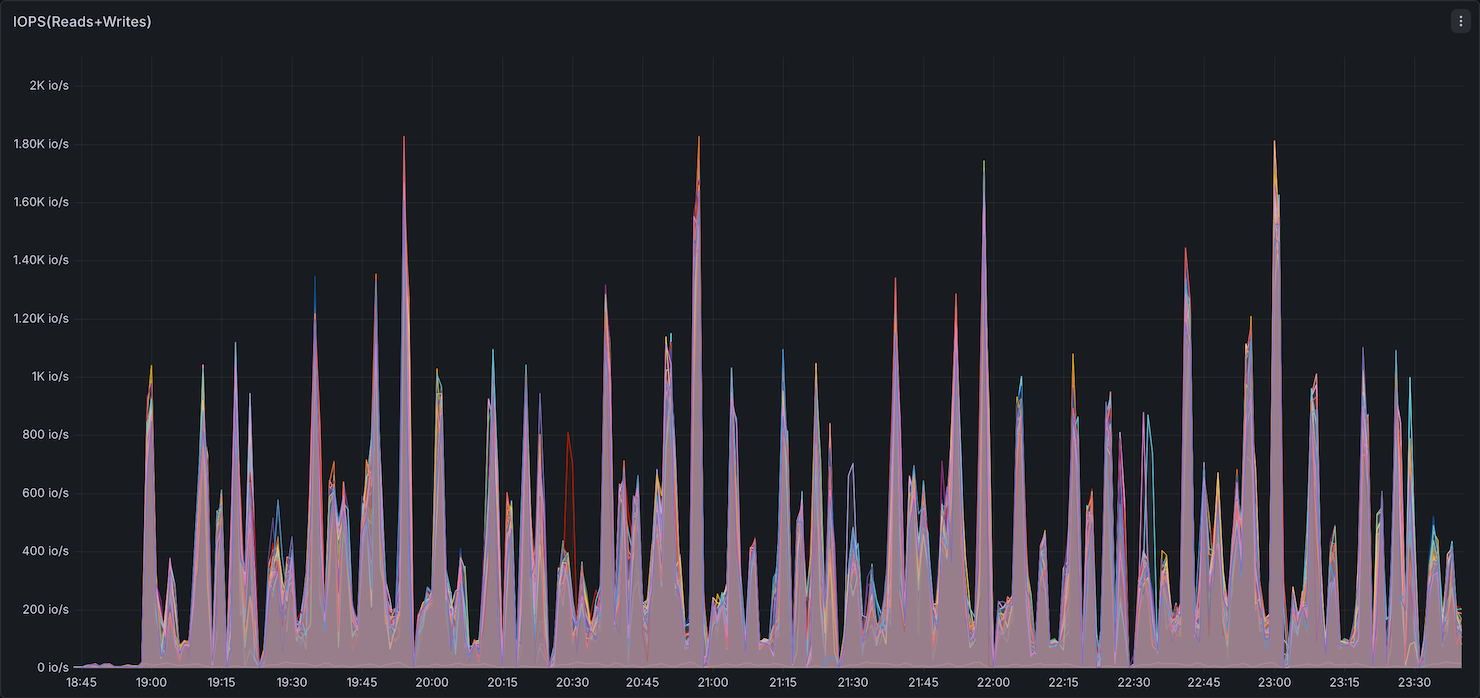
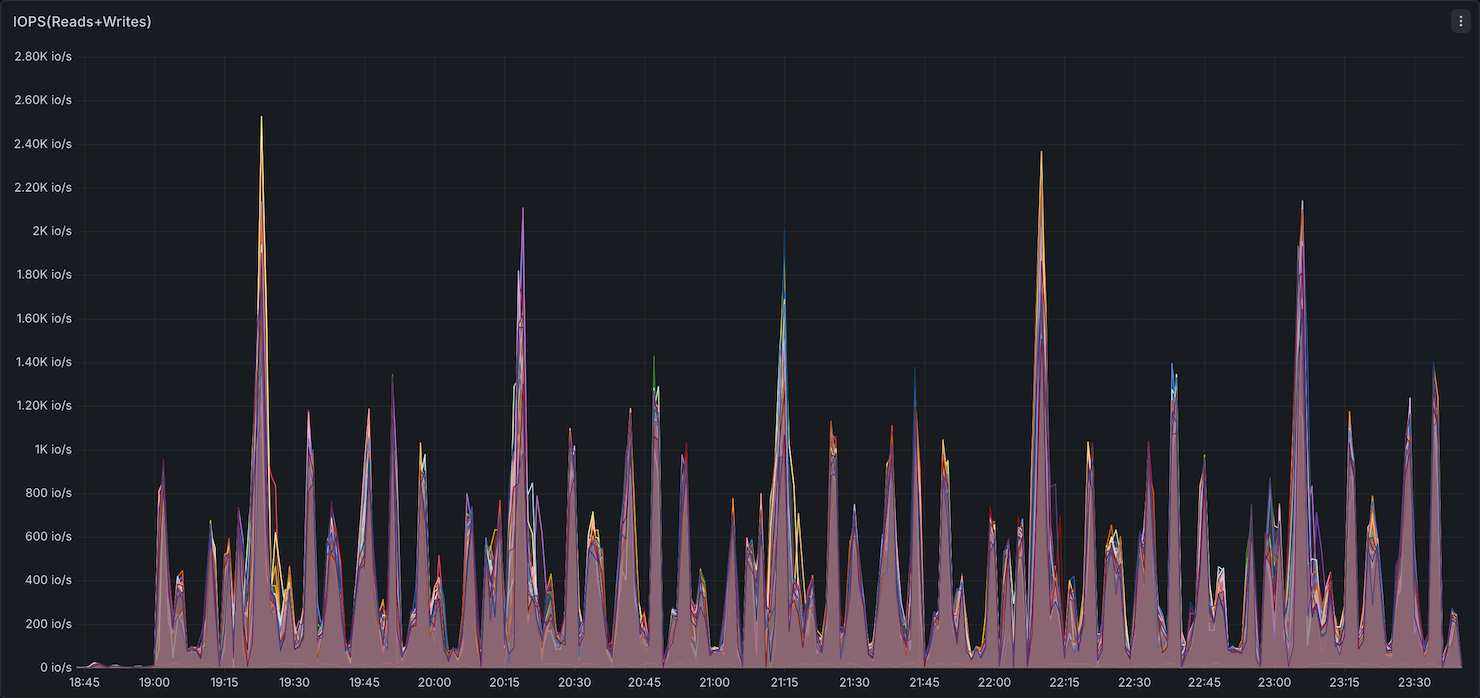
Storage I/O
Storage utilization (IOPS and throughput) showed Comet with higher peak IOPS than Native Spark.
Full Grafana Dashboard — Native Spark (Default)
Full Grafana Dashboard — Comet
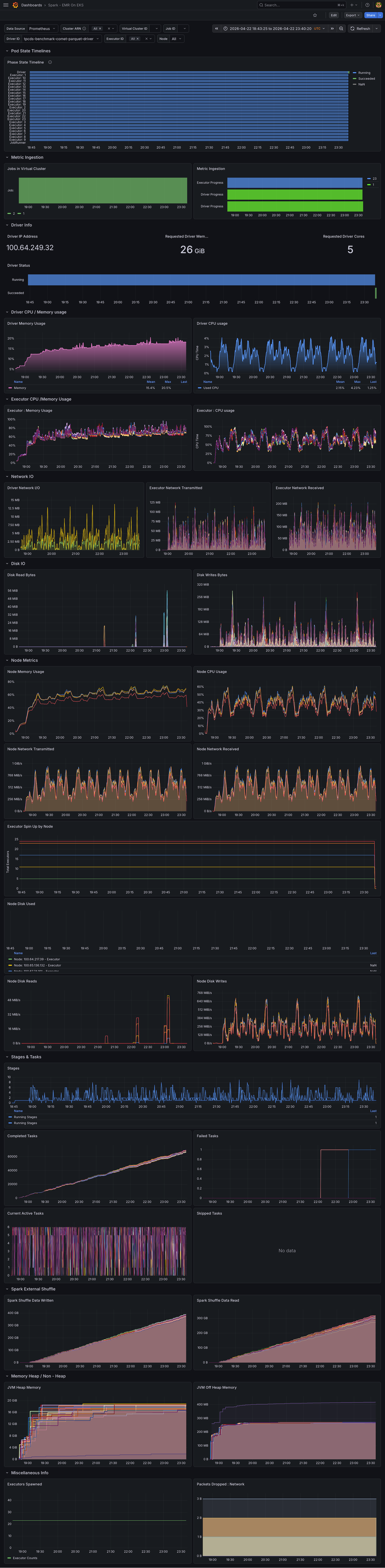
Summary: Comet uses slightly more memory than Native Spark (higher peak and elevated baseline between queries), while CPU, network, and storage utilization remain comparable. The 11% overall speedup comes without a significant increase in resource consumption. Since Comet performs most compute off-heap in its native Rust engine, operators may be able to reduce on-heap JVM memory per executor and allocate more toward off-heap, potentially improving cost efficiency.
Overall Performance
| Name | Completion Time (seconds) | Performance |
|---|---|---|
| Default Iceberg | 4,665.47 | Baseline |
| DataFusion Comet Iceberg 0.17.0 | 2,803.80 | 1.66× (+40% time) |
Performance Distribution
| Performance Range | Query Count | Percentage |
|---|---|---|
| 20%+ improvement | 98 | 95% |
| 10-20% improvement | 3 | 3% |
| ±10% | 1 | 1% |
| 10-20% degradation | 0 | 0% |
| 20%+ degradation | 1 | 1% |
Top 10 Query Improvements
| Query | Default Iceberg (s) | DataFusion Comet Iceberg 0.17.0 (s) | Speedup |
|---|---|---|---|
| q56-v4.0 | 6.7 | 1.9 | 3.56× (+72%) |
| q90-v4.0 | 31.6 | 10.1 | 3.12× (+68%) |
| q67-v4.0 | 147.6 | 50.0 | 2.96× (+66%) |
| q97-v4.0 | 46.5 | 17.2 | 2.69× (+63%) |
| q49-v4.0 | 47.6 | 18.6 | 2.56× (+61%) |
| q38-v4.0 | 30.5 | 13.4 | 2.29× (+56%) |
| q87-v4.0 | 30.5 | 13.4 | 2.27× (+56%) |
| q35-v4.0 | 21.8 | 9.9 | 2.20× (+54%) |
| q48-v4.0 | 16.3 | 7.6 | 2.15× (+53%) |
| q78-v4.0 | 151.9 | 70.9 | 2.14× (+53%) |
Query Regressions
Out of 103 TPC-DS query variants, q50 was the single regression under DataFusion Comet Iceberg 0.17.0 — running 23% slower (96.3s → 118.3s, 0.81×). Every other query matched or outperformed native Spark.
| Query | Default Iceberg (s) | DataFusion Comet Iceberg 0.17.0 (s) | Degradation |
|---|---|---|---|
| q50-v4.0 | 96.3 | 118.3 | 23% slower (0.81×) |
DataFusion Comet Iceberg v0.16.0 Results
Overall Performance
| Name | Completion Time (seconds) | Performance |
|---|---|---|
| Default Iceberg | 4,665.47 | Baseline |
| DataFusion Comet Iceberg 0.16.0 | 2,922.30 | 1.60× (+37% time) |
Performance Distribution
| Performance Range | Query Count | Percentage |
|---|---|---|
| 20%+ improvement | 93 | 90% |
| 10-20% improvement | 6 | 6% |
| ±10% | 1 | 1% |
| 10-20% degradation | 0 | 0% |
| 20%+ degradation | 3 | 3% |
Top 10 Query Improvements
| Query | Default Iceberg (s) | DataFusion Comet Iceberg 0.16.0 (s) | Speedup |
|---|---|---|---|
| q86-v4.0 | 14.9 | 4.7 | 3.14× (+68%) |
| q56-v4.0 | 6.7 | 2.2 | 3.09× (+68%) |
| q90-v4.0 | 31.6 | 11.6 | 2.73× (+63%) |
| q67-v4.0 | 147.6 | 54.3 | 2.72× (+63%) |
| q97-v4.0 | 46.5 | 18.3 | 2.53× (+61%) |
| q49-v4.0 | 47.6 | 19.1 | 2.49× (+60%) |
| q38-v4.0 | 30.5 | 14.4 | 2.12× (+53%) |
| q35-v4.0 | 21.8 | 10.4 | 2.09× (+52%) |
| q87-v4.0 | 30.5 | 14.6 | 2.08× (+52%) |
| q78-v4.0 | 151.9 | 74.4 | 2.04× (+51%) |
Top 3 Query Regressions
Only three queries showed regressions.
| Query | Default Iceberg (s) | DataFusion Comet Iceberg 0.16.0 (s) | Degradation |
|---|---|---|---|
| q39b-v4.0 | 4.9 | 7.4 | 53% slower (0.65×) |
| q39a-v4.0 | 5.8 | 8.0 | 37% slower (0.73×) |
| q50-v4.0 | 96.3 | 117.4 | 22% slower (0.82×) |
When to Consider Comet
Comet may be beneficial for:
- Workloads dominated by specific query patterns - If your workload consists primarily of queries similar to q5, q56, q41, q45 (40%+ faster), Comet could provide net benefits
- Targeted query optimization - Scenarios where you can isolate and route specific query patterns that align with Comet's strengths
- Future versions - As the project matures, performance characteristics may change and improve significantly
Running Benchmarks
Prerequisites
- EKS cluster with Spark Operator installed
- S3 bucket with TPC-DS benchmark data
- Docker registry access (ECR or other)
Step 1: Build Docker Image
Build the Comet-enabled Spark image:
cd data-stacks/spark-on-eks/benchmarks/datafusion-comet-benchmarks
# Build and push to your registry
docker build -t <your-registry>/spark-comet:3.5.8 -f Dockerfile-comet .
docker push <your-registry>/spark-comet:3.5.8
Step 2: Install NodeLocal DNS Cache
To mitigate the DNS query volume issue, install NodeLocal DNS Cache:
kubectl apply -f node-local-cache.yaml
This caches DNS results locally on each node, preventing the excessive DNS queries to Route53 Resolver.
Step 3: Update Bucket Names
Update the S3 bucket references in the benchmark manifests:
# For Comet benchmark
export S3_BUCKET=your-bucket-name
envsubst < tpcds-benchmark-comet-parquet.yaml | kubectl apply -f -
# For native Spark baseline
envsubst < tpcds-benchmark-parquet.yaml | kubectl apply -f -
Or manually edit the YAML files and replace ${S3_BUCKET} with your bucket name.
Step 4: Monitor Benchmark Progress
# Check job status
kubectl get sparkapplications -n spark-team-a
# View logs
kubectl logs -f -n spark-team-a -l spark-app-name=tpcds-benchmark-comet