Apache Spark with Apache Gluten + Velox Benchmarks
Apache Spark powers much of today’s large-scale analytics, but its default SQL engine is still JVM-bound and row-oriented. Even with Project Tungsten’s code generation and vectorized readers, operators often pay heavy costs for Java object creation, garbage collection, and row-to-column conversions. These costs become visible on analytic workloads that scan large Parquet or ORC tables, perform wide joins, or run memory-intensive aggregations—leading to slower queries and inefficient CPU use.
Modern C++ engines such as Velox, ClickHouse, and DuckDB show that SIMD-optimized, cache-aware vectorization can process the same data far faster. But replacing Spark is impractical given its ecosystem and scheduling model. Apache Gluten solves this by translating Spark SQL plans into the open Substrait IR and offloading execution to a native C++ backend (Velox, ClickHouse, etc.). This approach keeps Spark’s APIs and Kubernetes deployment model while accelerating the CPU-bound SQL layer—the focus of this deep dive and benchmark study on Amazon EKS.
In this guide you will:
- Understand how the Spark + Gluten + Velox stack is assembled on Amazon EKS
- Review TPC-DS 3TB benchmark results against native Spark on Graviton4 (r8gd.12xlarge)
- Learn the configuration, deployment, and troubleshooting steps required to reproduce the study
Our TPC-DS 3TB benchmark on Amazon EKS (r8gd.12xlarge Graviton4) shows that Apache Gluten + Velox v1.6.0 delivered:
- 39% faster overall on Parquet — total runtime dropped from
3,650.56sto2,239.93s(1.63× speedup). - 81 of 103 queries improved, with peak speedups up to
4.36×on q93. 22 queries regressed, most within 20% (one outlier on q72). - Spark 3.5.8 on both sides; only the execution engine and related Spark settings differed.
TPC-DS 3TB Benchmark Results
Summary
Our TPC-DS 3TB benchmark on Amazon EKS demonstrates that Apache Gluten + Velox v1.6.0 delivers a 1.63× overall speedup compared to native Spark SQL on Parquet, with individual queries varying from ~77% faster to ~46% slower (excluding one outlier on q72).
| Name | Completion Time (seconds) | Speedup |
|---|---|---|
| Native Spark | 3,650.56 | Baseline |
| Gluten + Velox v1.6.0 | 2,239.93 | 1.63× (39% faster) |
📊 View complete benchmark results and raw data →
Benchmark Infrastructure
Benchmarks ran sequentially on the same cluster to ensure identical hardware and eliminate resource contention. Native Spark executed first, followed by Gluten + Velox.
To ensure an apples-to-apples comparison, both native Spark and Gluten + Velox jobs ran on identical hardware, storage, and data. Only the execution engine and related Spark settings differed.
Test Environment
| Component | Configuration |
|---|---|
| EKS Cluster | Amazon EKS 1.34 |
| Node Instance Type | r8gd.12xlarge (Graviton4, 48 vCPUs, 384GB RAM, 1.8TB NVMe SSD) |
| Node Group | 12 nodes dedicated for benchmark workloads |
| Executor Configuration | 23 executors × 5 cores × 20GB on-heap + 32GB off-heap |
| Driver Configuration | 5 cores × 20GB RAM |
| Dataset | TPC-DS 3TB (Parquet format) |
| Storage | Amazon S3 with optimized S3A connector |
| Iterations | 5 (median runtime per query) |
Spark Configuration Comparison
| Configuration | Native Spark | Gluten + Velox |
|---|---|---|
| Spark Version | 3.5.8 | 3.5.8 |
| Gluten Version | N/A | 1.6.0 |
| Java Runtime | OpenJDK 17 | OpenJDK 17 |
| Execution Engine | JVM-based Tungsten | Native C++ Velox |
| Key Plugins | Standard Spark | GlutenPlugin, ColumnarShuffleManager |
| Off-heap Memory | Default | 32GB enabled |
| Vectorized Processing | Limited Java SIMD | Full C++ vectorization (ARM Neon) |
| Memory Management | JVM GC | Unified native + JVM |
Critical Gluten-Specific Configurations
# Essential Gluten Plugin Configuration
"spark.plugins": "org.apache.gluten.GlutenPlugin"
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
# Memory Configuration - Critical for Gluten
"spark.memory.offHeap.enabled": "true"
"spark.memory.offHeap.size": "32g"
# Java 17 Compatibility (Required)
"spark.driver.extraJavaOptions": "--add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.misc=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED"
"spark.executor.extraJavaOptions": "--add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.misc=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED"
# AWS-Specific: Required for S3 region detection
"spark.hadoop.fs.s3a.endpoint.region": "us-west-2"
Performance Results
Overall Performance
| Name | Completion Time (seconds) | Performance |
|---|---|---|
| Native Spark | 3,650.56 | Baseline |
| Gluten + Velox v1.6.0 | 2,239.93 | 1.63× (39% faster) |
Performance Distribution
| Performance Range | Query Count | Percentage |
|---|---|---|
| 20%+ improvement | 57 | 55% |
| 10-20% improvement | 16 | 16% |
| ±10% | 16 | 16% |
| 10-20% degradation | 7 | 7% |
| 20%+ degradation | 7 | 7% |
Top 10 Query Improvements
| Query | Native Spark (s) | Gluten + Velox v1.6.0 (s) | Speedup |
|---|---|---|---|
| q93-v4.0 | 207.9 | 47.7 | 4.36× (+77%) |
| q23a-v4.0 | 409.6 | 99.2 | 4.13× (+76%) |
| q23b-v4.0 | 412.2 | 113.7 | 3.62× (+72%) |
| q5-v4.0 | 40.8 | 11.5 | 3.56× (+72%) |
| q97-v4.0 | 43.3 | 13.1 | 3.30× (+70%) |
| q78-v4.0 | 136.0 | 46.4 | 2.93× (+66%) |
| q59-v4.0 | 26.4 | 9.2 | 2.89× (+65%) |
| q65-v4.0 | 43.6 | 15.5 | 2.82× (+65%) |
| q86-v4.0 | 12.8 | 4.7 | 2.75× (+64%) |
| q35-v4.0 | 20.0 | 8.0 | 2.50× (+60%) |
Top 10 Query Regressions
| Query | Native Spark (s) | Gluten + Velox v1.6.0 (s) | Degradation |
|---|---|---|---|
| q72-v4.0 | 40.4 | 193.5 | 378% slower (0.21×) |
| q76-v4.0 | 41.9 | 61.2 | 46% slower (0.68×) |
| q77-v4.0 | 2.5 | 3.4 | 38% slower (0.72×) |
| q13-v4.0 | 8.8 | 11.9 | 36% slower (0.74×) |
| q27-v4.0 | 7.4 | 9.9 | 33% slower (0.75×) |
| q95-v4.0 | 85.9 | 106.7 | 24% slower (0.81×) |
| q52-v4.0 | 1.5 | 1.9 | 21% slower (0.83×) |
| q3-v4.0 | 4.1 | 5.0 | 20% slower (0.83×) |
| q92-v4.0 | 1.8 | 2.2 | 19% slower (0.84×) |
| q55-v4.0 | 1.4 | 1.6 | 17% slower (0.85×) |
Notes on Performance Differences
Gluten + Velox Outperforms Most Queries:
Example - Query 93 (+77%)
- The hot 200-task join stage went from p50
1m16.378s → 6.523s(~12× faster) after the SortMergeJoin was replaced byShuffledHashJoinExecTransformerand the two pre-join Sorts were eliminated. - Per-task peak memory on the same stage dropped from
3.3 GB(on-heap) to80 MB(off-heap), with JVM GC collapsing from3.628sto35ms. ColumnarShuffleManagerproduced~24%smaller serialized shuffle bytes (214.1 GB → 162.2 GB) at identical record counts, reducing both network and disk pressure on downstream stages.
Example - Query 23a (+76%)
- Identical job/stage/task counts (
16/16/9790) and near-identical input on both runs — Catalyst chose the same physical plan, only operator implementations differ. - All 9
SortMergeJoins were replaced byShuffledHashJoinExecTransformerand all 18 pre-join Sort operators were eliminated; the hot 200-task join stage ran6.86×faster (2m47.28s → 24.358s). - Columnar shuffle reduced serialized bytes
36.5%at identical record counts (16.6B records); JVM GC dropped99.9%(3m19.058s → 200ms).
Gluten + Velox Underperforms on Some Queries:
Example - Query 72 (-378%)
152sof the152.8sregression is concentrated in a singleShuffledHashJoinprobe stage at identical 200 tasks and 1.01B shuffle records — no spill, no fallback, GC near zero.- Velox materialises
22.5Msmall column-vector batches (avg~222rows/batch — far below the 4,096-row target) through 9 cascaded downstream operators after the probe, paying per-batch operator overhead at every step. - Spark's whole-stage codegen handles the same 4.99B intermediate row stream as a single fused JVM function that never materialises it. This is a structural cost of Velox not implementing
SortMergeJoin, not a bug.
Example - Query 13 (-36%)
- Final
SortMergeJoin → ShuffledHashJoinExecTransformerswap adds+522%to per-task p50 on the 66-task probe stage; the hash table is probed against a complex 3-way disjunctive non-equi predicate per match. - Per-task off-heap peak memory rose from
42 KB → 160 MBon thestore_salesscan because Velox's columnar batches are less compact than Spark's row encoder for this 9-column int+decimal payload. - GC elimination saves only
~1.8sof wall time on this query — far less than the+3.2sper-task cost of the SHJ probe with disjunctive predicates, so the swap is a net loss when pre-sorted streams already exist.
Resource Usage Analysis
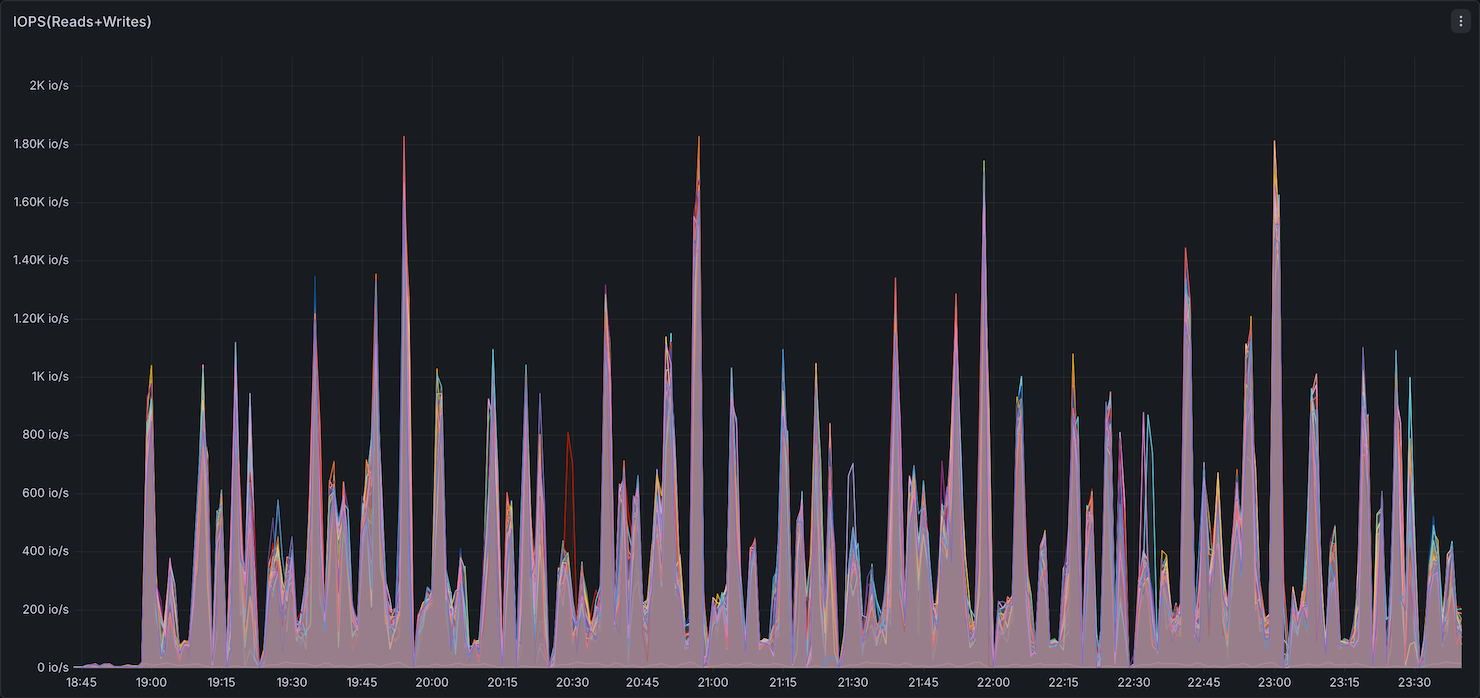
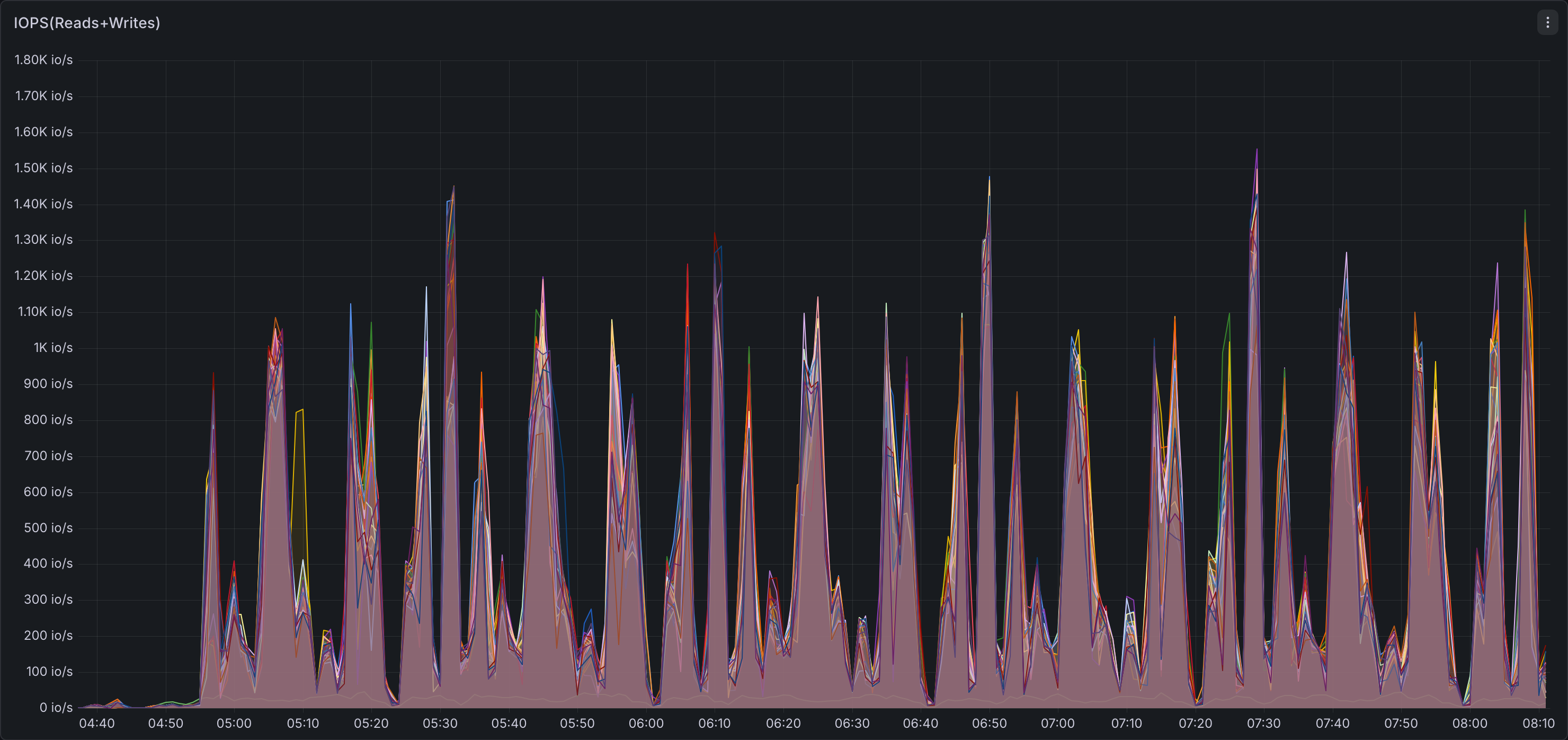
Both benchmarks ran sequentially on identical hardware (12× r8gd.12xlarge) to enable direct comparison. The dashboards below capture cluster-wide resource utilization during the full TPC-DS 3TB run for each engine.
CPU Utilization
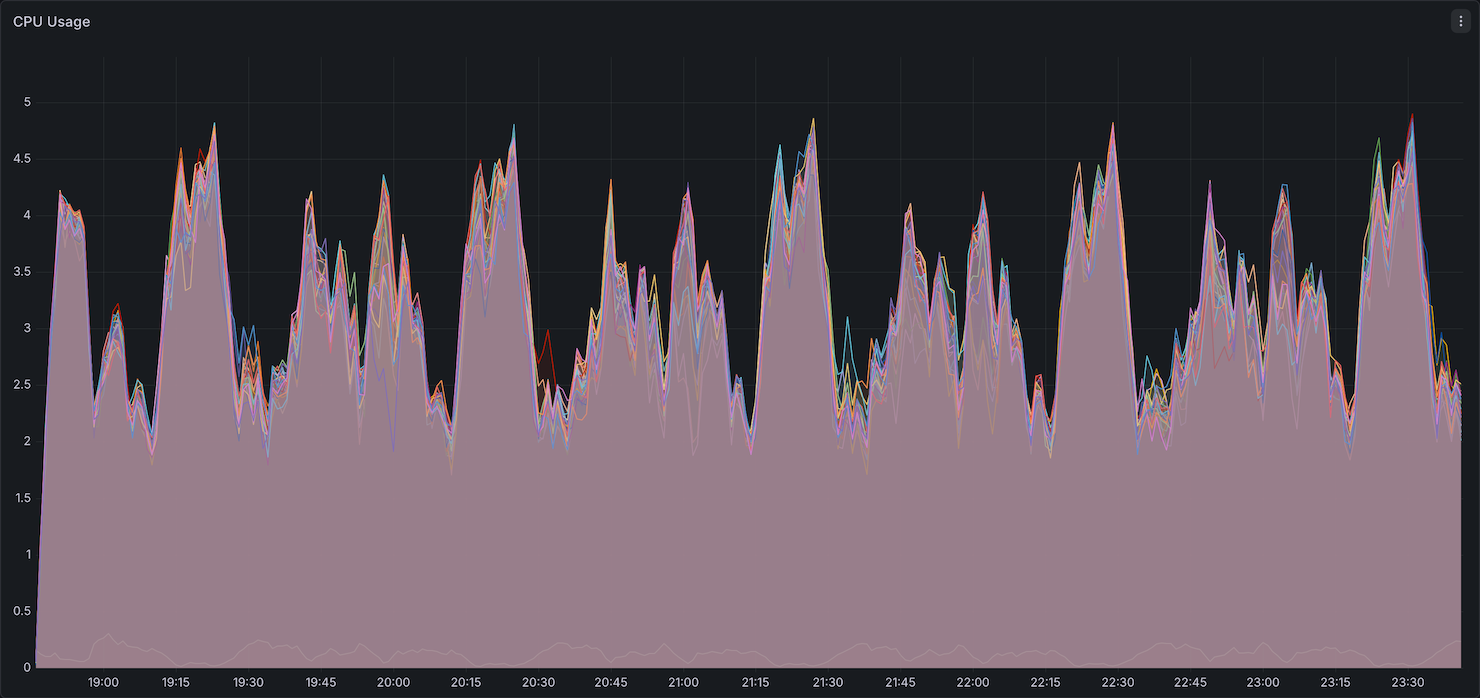
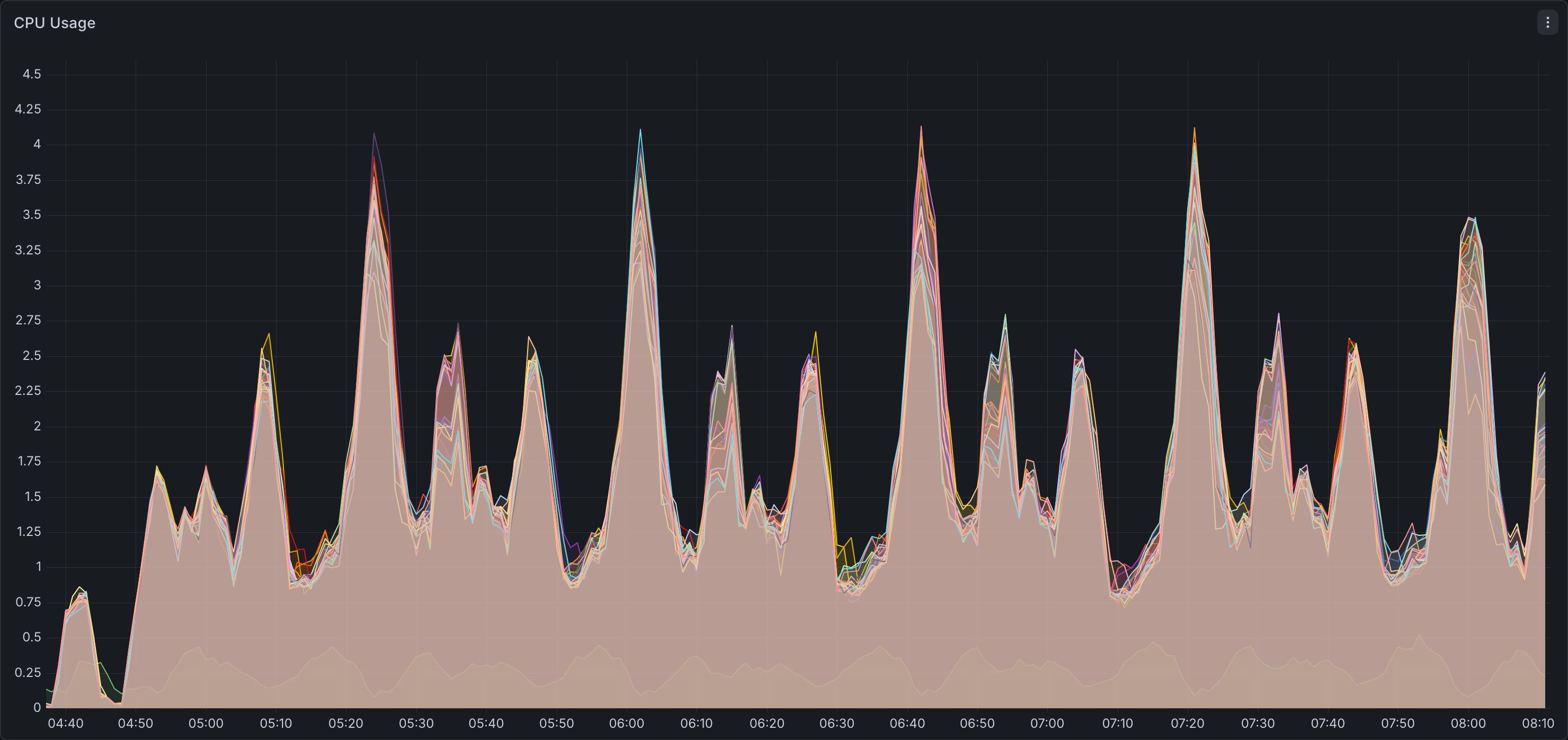
Memory Utilization
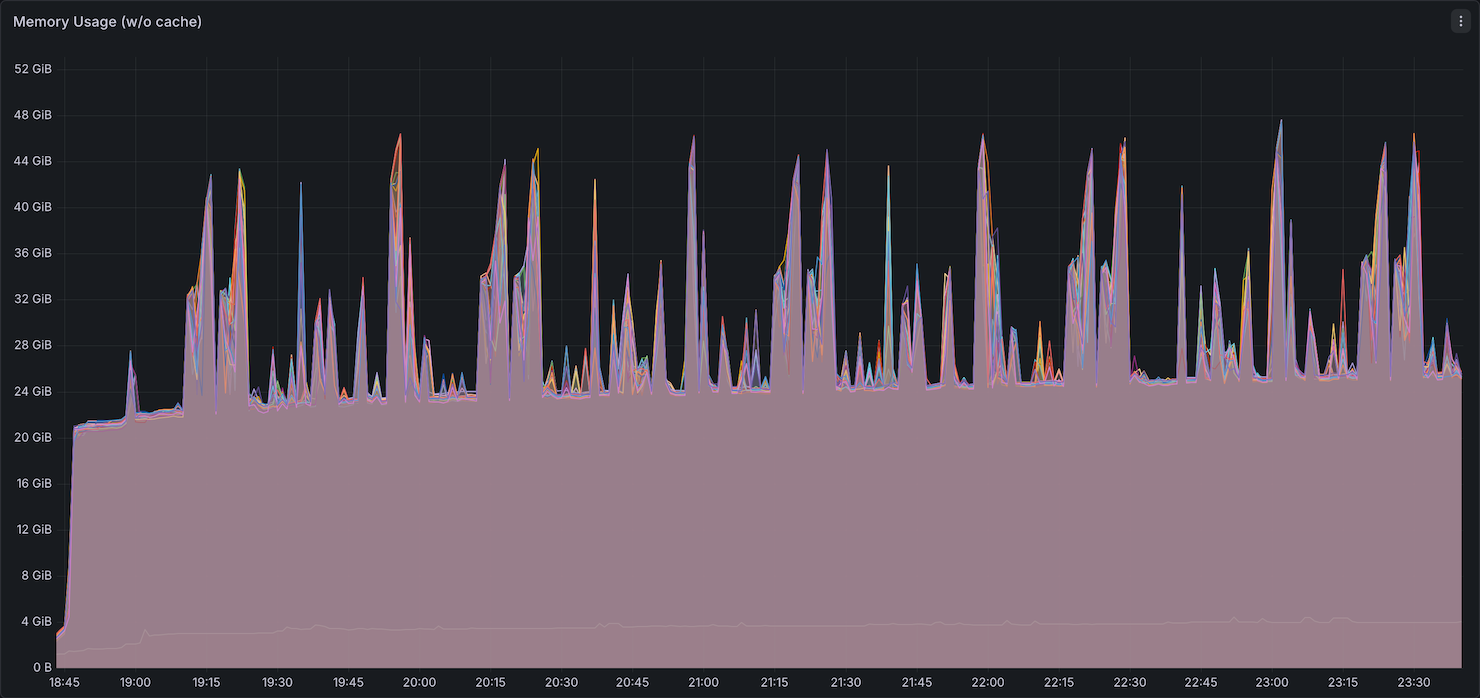
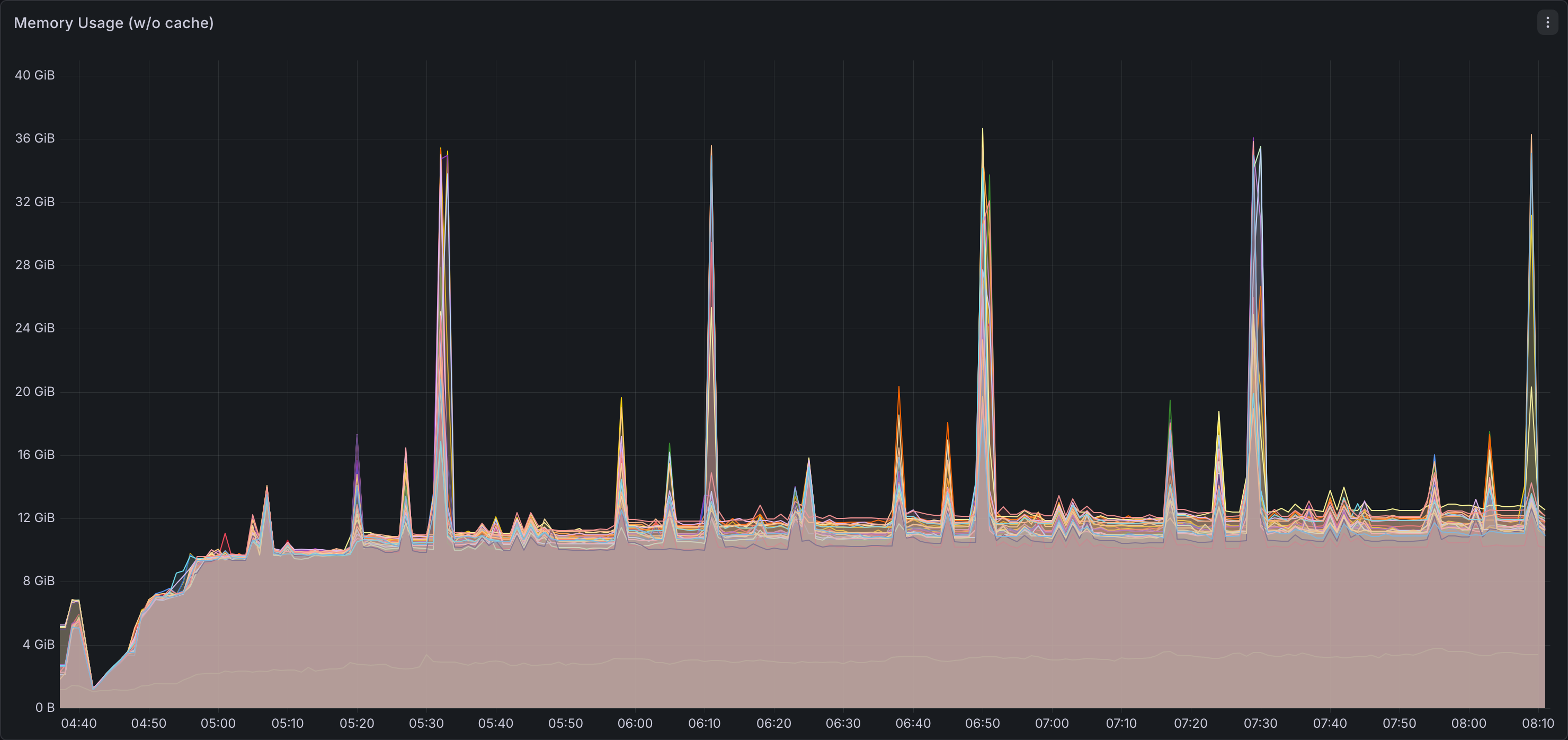
Network Bandwidth
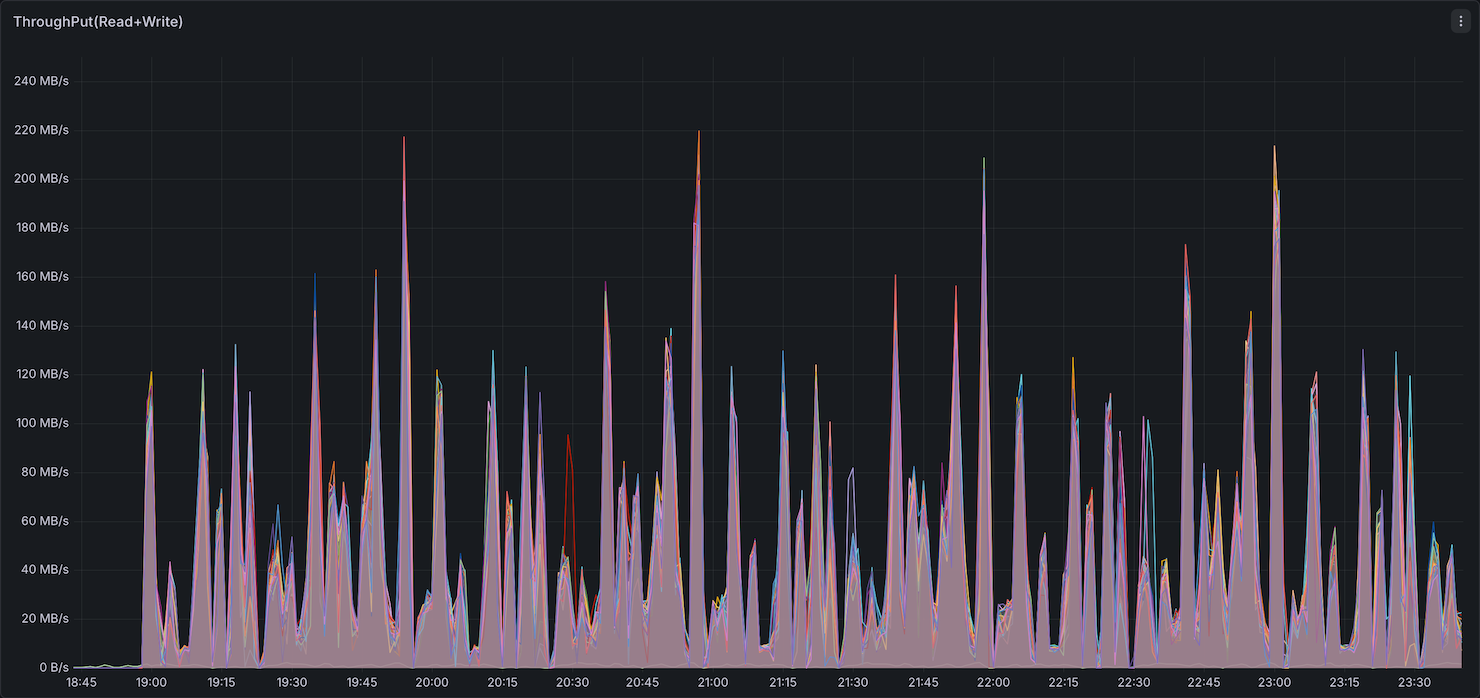
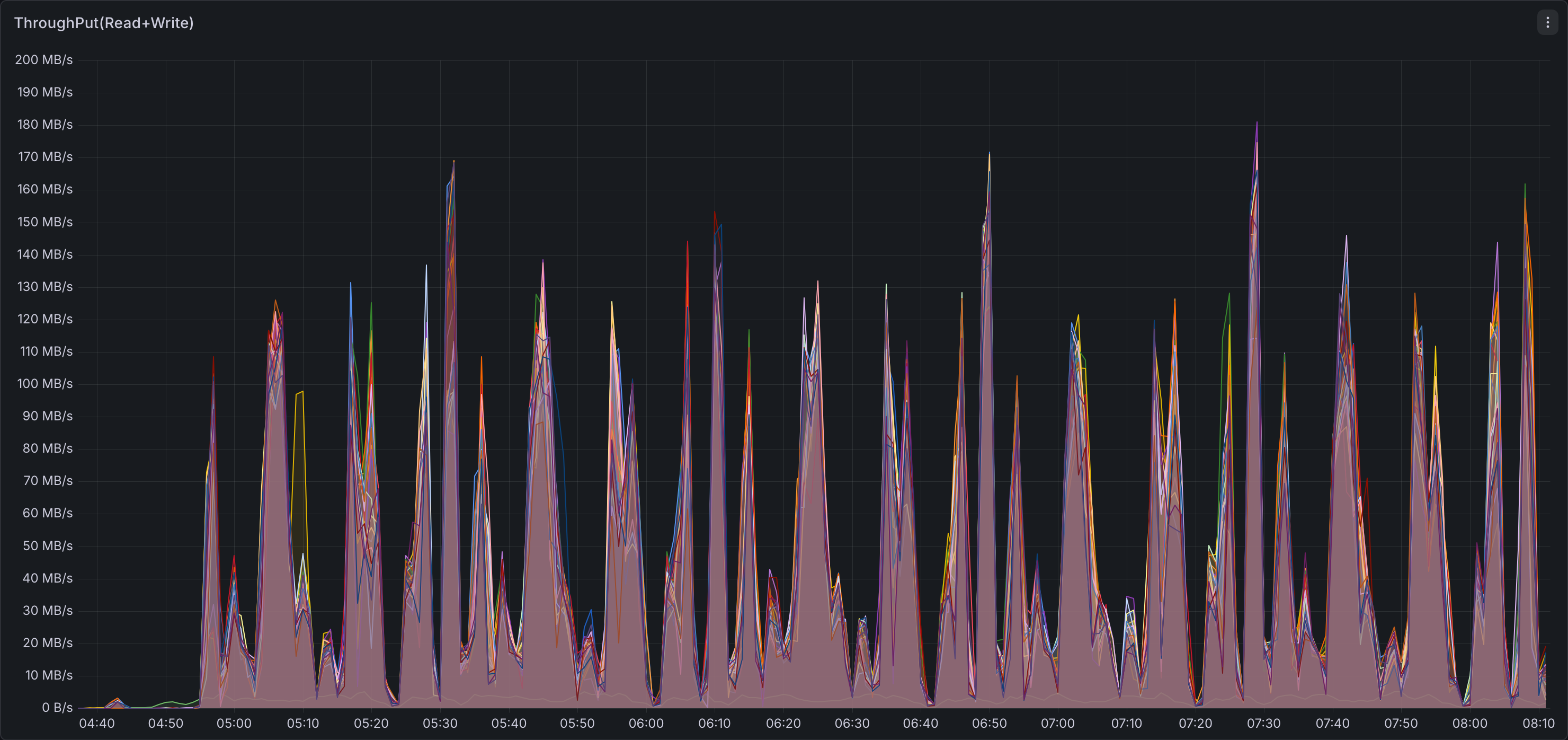
Storage I/O
Full Grafana Dashboard — Native Spark (Default)
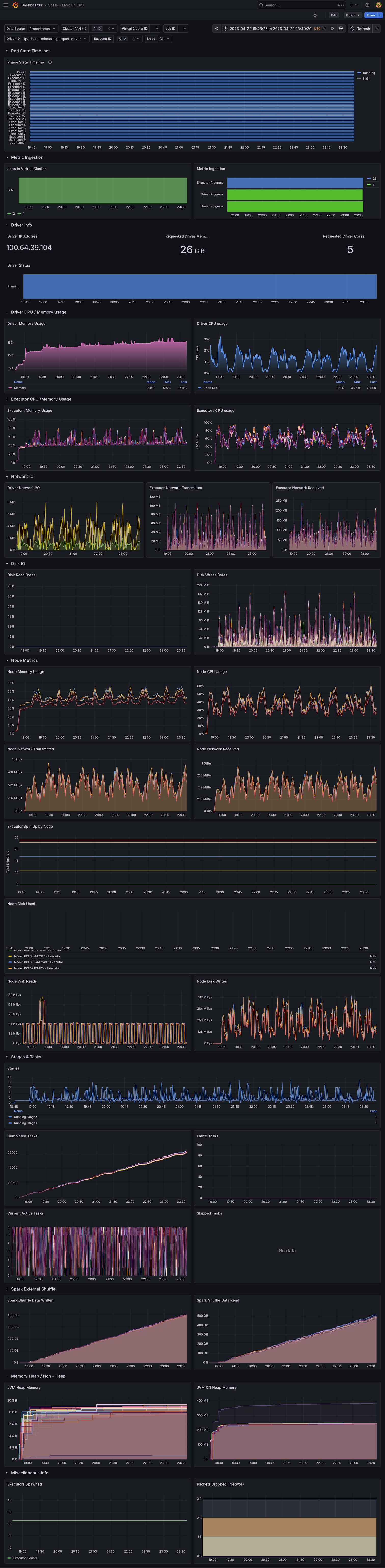
Full Grafana Dashboard — Gluten + Velox
When to Consider Gluten + Velox
Gluten + Velox may be a good fit for:
- Compute-bound TPC-DS-style analytics — Workloads with wide joins, complex aggregations, and large scans (q5, q23, q78, q93, q97 in our run all sped up by 2.5–4.4×).
- CPU-efficient batch pipelines on Graviton — The Velox backend takes advantage of ARM Neon SIMD on r8gd-class instances; off-heap columnar execution reduces JVM GC pressure.
- Drop-in acceleration without code changes — Existing Spark SQL/DataFrame code runs unchanged; unsupported operators automatically fall back to Spark's JVM engine.
Validate before adopting in production:
- Test your query mix — A small set of queries can regress (q72 in particular). Compare physical plans for
SortMergeJoin → ShuffledHashJoinswaps and look for high-cardinality intermediate streams that Spark's whole-stage codegen would have pipelined without materialization. - Tune off-heap memory — Velox needs significant off-heap allocation (this benchmark used 32GB). Plan for 20–30% of executor memory off-heap.
- Check Java 17 compatibility flags — The
--add-opensJVM options are required.
Historic Results — TPC-DS 1TB on c5d.12xlarge
The interactive dashboard and tables below capture an earlier benchmark run on a different instance class (c5d.12xlarge, x86) and a smaller dataset (1TB). It is preserved here for context and ecosystem comparisons.
Interactive Performance Dashboard
We benchmarked TPC-DS 1TB workloads on a dedicated Amazon EKS cluster to compare native Spark SQL execution with Spark enhanced by Gluten and the Velox backend. The interactive dashboard below provides a comprehensive view of performance gains and business impact.
Performance Comparison: Runtime Analysis
Query Speedup Distribution
Top 10 Performance Improvements
🔍 Performance Analysis Insights
- Complex Analytical Queries: Queries with heavy joins and aggregations (q93, q49, q50) show the highest improvements (3.8x-5.6x)
- Scan-Heavy Operations: Large table scans benefit significantly from native columnar processing
- Vectorization Benefits: Mathematical operations and filters see consistent 2x-3x improvements
- Memory-Intensive Queries: Queries like q23b (146s→52s) demonstrate native memory management advantages
- Edge Cases: 14 queries showed degradation, primarily those with simple operations where JNI overhead exceeded benefits
- Cost Savings: 69.8% reduction in execution time translates to ~42% lower compute costs on EKS
Summary
Our comprehensive TPC-DS 1TB benchmark on Amazon EKS demonstrates that Apache Gluten with Velox delivers a 1.72x overall speedup (72% faster) compared to native Spark SQL, with individual queries showing improvements ranging from 1.1x to 5.5x.
Benchmark Infrastructure Configuration
To ensure an apples-to-apples comparison, both native Spark and Gluten + Velox jobs ran on identical hardware, storage, and data. Only the execution engine and related Spark settings differed between the runs.
Test Environment Specifications
| Component | Configuration |
|---|---|
| EKS Cluster | Amazon EKS 1.33 |
| Node Instance Type | c5d.12xlarge (48 vCPUs, 96GB RAM, 1.8TB NVMe SSD) |
| Node Group | 8 nodes dedicated for benchmark workloads |
| Executor Configuration | 23 executors × 5 cores × 20GB RAM each |
| Driver Configuration | 5 cores × 20GB RAM |
| Dataset | TPC-DS 1TB (Parquet format) |
| Storage | Amazon S3 with optimized S3A connector |
Spark Configuration Comparison
| Configuration | Native Spark | Gluten + Velox |
|---|---|---|
| Spark Version | 3.5.3 | 3.5.2 |
| Java Runtime | OpenJDK 17 | OpenJDK 17 |
| Execution Engine | JVM-based Tungsten | Native C++ Velox |
| Key Plugins | Standard Spark | GlutenPlugin, ColumnarShuffleManager |
| Off-heap Memory | Default | 2GB enabled |
| Vectorized Processing | Limited Java SIMD | Full C++ vectorization |
| Memory Management | JVM GC | Unified native + JVM |
Critical Gluten-Specific Configurations
# Essential Gluten Plugin Configuration
spark.plugins: "org.apache.gluten.GlutenPlugin"
spark.shuffle.manager: "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
spark.memory.offHeap.enabled: "true"
spark.memory.offHeap.size: "2g"
# Java 17 Compatibility for Gluten-Velox
spark.driver.extraJavaOptions: "--add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.misc=ALL-UNNAMED"
spark.executor.extraJavaOptions: "--add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.misc=ALL-UNNAMED"
Performance Analysis: Top 20 Query Improvements
Gluten’s native execution path shines on wide, compute-heavy SQL. The table highlights the largest gains across the 104 TPC-DS queries, comparing median runtimes over multiple iterations.
| Rank | TPC-DS Query | Native Spark (s) | Gluten + Velox (s) | Speedup | % Improvement |
|---|---|---|---|---|---|
| 1 | q93-v2.4 | 80.18 | 14.63 | 5.48× | 448.1% |
| 2 | q49-v2.4 | 25.68 | 6.66 | 3.86× | 285.5% |
| 3 | q50-v2.4 | 38.57 | 10.00 | 3.86× | 285.5% |
| 4 | q59-v2.4 | 17.57 | 4.82 | 3.65× | 264.8% |
| 5 | q5-v2.4 | 23.18 | 6.42 | 3.61× | 261.4% |
| 6 | q62-v2.4 | 9.41 | 2.88 | 3.27× | 227.0% |
| 7 | q97-v2.4 | 18.68 | 5.99 | 3.12× | 211.7% |
| 8 | q40-v2.4 | 15.17 | 5.05 | 3.00× | 200.2% |
| 9 | q90-v2.4 | 12.05 | 4.21 | 2.86× | 186.2% |
| 10 | q23b-v2.4 | 147.17 | 52.96 | 2.78× | 177.9% |
| 11 | q29-v2.4 | 17.33 | 6.45 | 2.69× | 168.7% |
| 12 | q9-v2.4 | 60.90 | 23.03 | 2.64× | 164.5% |
| 13 | q96-v2.4 | 9.19 | 3.55 | 2.59× | 158.8% |
| 14 | q84-v2.4 | 7.99 | 3.12 | 2.56× | 156.1% |
| 15 | q6-v2.4 | 9.87 | 3.87 | 2.55× | 155.3% |
| 16 | q99-v2.4 | 9.70 | 3.81 | 2.55× | 154.6% |
| 17 | q43-v2.4 | 4.70 | 1.87 | 2.51× | 151.1% |
| 18 | q65-v2.4 | 17.51 | 7.00 | 2.50× | 150.2% |
| 19 | q88-v2.4 | 50.90 | 20.69 | 2.46× | 146.1% |
| 20 | q44-v2.4 | 22.90 | 9.36 | 2.45× | 144.7% |
Speedup Distribution Across Queries
| Speedup Range | Count | % of Total (≈97 queries) |
|---|---|---|
| ≥ 3× and < 5× | 9 | ≈ 9% |
| ≥ 2× and < 3× | 29 | ≈ 30% |
| ≥ 1.5× and < 2× | 30 | ≈ 31% |
| ≥ 1× and < 1.5× | 21 | ≈ 22% |
| < 1× (slower with Gluten) | 8 | ≈ 8% |
Key Performance Insights
| Dimension | Insight | Impact |
|---|---|---|
| Aggregate Gains |
|
|
| Query Patterns |
|
|
| Resource Utilization |
|
|
Business Impact Assessment
Cost Optimization Summary
With a 1.72× speedup, organizations can achieve:
- ≈42% lower compute spend for batch processing workloads
- Faster time-to-insight for business-critical analytics
- Higher cluster utilization through reduced job runtimes
Operational Benefits
- Minimal migration effort: Drop-in plugin with existing Spark SQL code
- Production-ready reliability preserves operational stability
- Kubernetes-native integration keeps parity with existing EKS data platforms
Technical Recommendations
When to Deploy Gluten + Velox
- High-Volume Analytics: TPC-DS-style complex queries with joins and aggregations
- Cost-Sensitive Workloads: Where 40%+ compute cost reduction justifies integration effort
- Performance-Critical Pipelines: SLA-driven workloads requiring faster execution
Implementation Considerations
- Query Compatibility: Test edge cases in your specific workload patterns
- Memory Tuning: Optimize off-heap allocation based on data characteristics
- Monitoring: Leverage native metrics for performance debugging and optimization
The benchmark results demonstrate that Gluten + Velox represents a significant leap forward in Spark SQL performance, delivering production-ready native acceleration without sacrificing Spark's distributed computing advantages.
Architecture Overview — Apache Spark vs. Apache Spark with Gluten + Velox
Understanding how Gluten intercepts Spark plans clarifies why certain workloads accelerate so sharply. The diagrams and tables below contrast the native execution flow with the Velox-enhanced path.
Execution Path Comparison
Memory & Processing Comparison
| Aspect | Native Spark | Gluten + Velox | Impact |
|---|---|---|---|
| Memory Model | JVM heap objects | Apache Arrow off-heap columnar | JVM GC time dropped ~99.7% in our 3TB run (2h47m → 27s) |
| Processing | Row-by-row iteration via whole-stage codegen | SIMD vectorized columnar batches | Higher per-cycle throughput on scan/filter/aggregate |
| CPU Cache | Mixed locality across row layouts | Cache-friendly column layouts | Better cache reuse on wide scans and aggregations |
| Shuffle | UnsafeRow + Snappy | ColumnarShuffleManager (Arrow-encoded) | 22–25% smaller shuffle bytes overall (11.3 TB → 8.7 TB read) |
What Is Apache Gluten — Why It Matters
Apache Gluten is a middleware layer that offloads Spark SQL execution from the JVM to high-performance native execution engines. For data engineers, this means:
Core Technical Benefits
- Zero Application Changes: Existing Spark SQL and DataFrame code works unchanged
- Automatic Fallback: Unsupported operations gracefully fall back to native Spark
- Cross-Engine Compatibility: Uses Substrait as intermediate representation
- Production Ready: Handles complex enterprise workloads without code changes
Gluten Plugin Architecture
Key Configuration Parameters
# Essential Gluten Configuration
sparkConf:
# Core Plugin Activation
"spark.plugins": "org.apache.gluten.GlutenPlugin"
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
# Memory Configuration
"spark.memory.offHeap.enabled": "true"
"spark.memory.offHeap.size": "4g" # Critical for Velox performance
# Fallback Control
"spark.gluten.sql.columnar.backend.velox.enabled": "true"
"spark.gluten.sql.columnar.forceShuffledHashJoin": "true"
What Is Velox — Why Gluten Needs It (Alternatives)
Velox is Meta's C++ vectorized execution engine optimized for analytical workloads. It serves as the computational backend for Gluten, providing:
Velox Core Components
| Layer | Component | Purpose |
|---|---|---|
| Operators | Filter, Project, Aggregate, Join | Vectorized SQL operations |
| Expressions | Vector functions, Type system | SIMD-optimized computations |
| Memory | Apache Arrow buffers, Custom allocators | Cache-efficient data layout |
| I/O | Parquet/ORC readers, Compression | High-throughput data ingestion |
| CPU | AVX2/AVX-512, ARM Neon | Hardware-accelerated processing |
Velox vs Alternative Backends
| Feature | Velox | ClickHouse | Apache Arrow DataFusion |
|---|---|---|---|
| Language | C++ | C++ | Rust |
| SIMD Support | AVX2/AVX-512/Neon | AVX2/AVX-512 | Limited |
| Memory Model | Apache Arrow Columnar | Native Columnar | Apache Arrow Native |
| Spark Integration | Native via Gluten | Via Gluten | Experimental |
| Performance | Excellent | Excellent | Good |
| Maturity | Production (Meta) | Production | Developing |
Configuring Spark + Gluten + Velox
The instructions in this section walk through the baseline artifacts you need to build an image, configure Spark defaults, and deploy workloads on the Spark Operator.
Docker Image Configuration
Create a production-ready Spark image with Gluten + Velox:
You can find the sample Dockerfile here: Dockerfile-spark-gluten-velox
Spark Configuration Examples
Use the templates below to bootstrap both shared Spark defaults and a sample SparkApplication manifest.
- spark-defaults.conf
- SparkApplication YAML
# spark-defaults.conf - Optimized for Gluten + Velox
# Core Gluten Configuration
spark.plugins org.apache.gluten.GlutenPlugin
spark.shuffle.manager org.apache.spark.shuffle.sort.ColumnarShuffleManager
# Memory Configuration - Critical for Performance
spark.memory.offHeap.enabled true
spark.memory.offHeap.size 4g
spark.executor.memoryFraction 0.8
spark.executor.memory 20g
spark.executor.memoryOverhead 6g
# Velox-specific Optimizations
spark.gluten.sql.columnar.backend.velox.enabled true
spark.gluten.sql.columnar.forceShuffledHashJoin true
spark.gluten.sql.columnar.backend.velox.bloom_filter.enabled true
# Java 17 Module Access (Required)
spark.driver.extraJavaOptions --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.misc=ALL-UNNAMED
spark.executor.extraJavaOptions --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.misc=ALL-UNNAMED
# Adaptive Query Execution
spark.sql.adaptive.enabled true
spark.sql.adaptive.coalescePartitions.enabled true
spark.sql.adaptive.skewJoin.enabled true
# S3 Optimizations
spark.hadoop.fs.s3a.fast.upload.buffer disk
spark.hadoop.fs.s3a.multipart.size 128M
spark.hadoop.fs.s3a.connection.maximum 200
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: "test-gluten-velox"
namespace: spark-team-a
spec:
type: Scala
mode: cluster
image: "your-registry/spark-gluten-velox:latest"
imagePullPolicy: Always
sparkVersion: "3.5.8"
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.12-3.5.8.jar"
arguments:
- "1000" # High iteration count to see Velox benefits
driver:
cores: 2
memory: "4g"
memoryOverhead: "1g"
serviceAccount: spark-team-a
env:
- name: JAVA_HOME
value: "/usr/lib/jvm/java-17-openjdk-amd64"
executor:
cores: 4
memory: "8g"
memoryOverhead: "2g"
instances: 2
serviceAccount: spark-team-a
env:
- name: JAVA_HOME
value: "/usr/lib/jvm/java-17-openjdk-amd64"
sparkConf:
# Gluten Configuration
"spark.plugins": "org.apache.gluten.GlutenPlugin"
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
"spark.memory.offHeap.enabled": "true"
"spark.memory.offHeap.size": "2g"
# Debugging and Monitoring
"spark.gluten.sql.debug": "true"
"spark.sql.planChangeLog.level": "WARN"
"spark.eventLog.enabled": "true"
"spark.eventLog.dir": "s3a://your-bucket/spark-event-logs"
# Java 17 Compatibility
"spark.driver.extraJavaOptions": "--add-opens=java.base/java.nio=ALL-UNNAMED"
"spark.executor.extraJavaOptions": "--add-opens=java.base/java.nio=ALL-UNNAMED"
Why these defaults?
spark.pluginsactivates the Apache Gluten runtime so query plans can offload to Velox.- Off-heap configuration reserves Arrow buffers that prevent JVM garbage collection pressure.
- Adaptive query execution settings keep shuffle partitions balanced under both native and Gluten runs.
- S3 connector tuning avoids bottlenecks when scanning the TPC-DS dataset from Amazon S3.
Running Benchmarks
Follow the workflow below to reproduce the benchmark from data generation through post-run analysis.
TPC-DS Benchmark Setup
The complete TPC-DS harness is available in the repository: examples/benchmark/tpcds-benchmark-spark-gluten-velox/README.md.
Step 1: Generate TPC-DS Data
Follow this link to generate the test data in S3 bucket. The benchmark in this guide uses the 3TB scale.
Step 2: Submit Native & Gluten Jobs
Before submitting benchmark jobs, ensure:
- S3 Bucket is configured: Export the S3 bucket name from your Terraform outputs
- Benchmark data is available: Verify TPC-DS data (e.g., 3TB) exists in the same S3 bucket
Export S3 bucket name from Terraform outputs:
# Get S3 bucket name from Terraform outputs
export S3_BUCKET=$(terraform -chdir=path/to/your/terraform output -raw s3_bucket_id_data)
# Verify the bucket and data exist
aws s3 ls s3://$S3_BUCKET/TPCDS-TEST-3TB/
Submit benchmark jobs:
The Native Spark baseline manifest lives next to the Comet benchmark assets and is reused as the apples-to-apples baseline for both engines. The Gluten + Velox manifests are split by CPU architecture.
- Native Spark
- Gluten + Velox (ARM64)
- Gluten + Velox (AMD64)
cd data-stacks/spark-on-eks/benchmarks/datafusion-comet-benchmarks
envsubst < tpcds-benchmark-parquet.yaml | kubectl apply -f -
cd data-stacks/spark-on-eks/benchmarks/gluten-velox-benchmarks
envsubst < tpcds-benchmark-gluten-parquet-arm64.yaml | kubectl apply -f -
cd data-stacks/spark-on-eks/benchmarks/gluten-velox-benchmarks
envsubst < tpcds-benchmark-gluten-parquet-amd64.yaml | kubectl apply -f -
Step 3: Monitor Benchmark Progress
- Status
- Logs
- History UI
kubectl get sparkapplications -n spark-team-a
kubectl logs -f -n spark-team-a -l spark-app-name=tpcds-benchmark-parquet
kubectl logs -f -n spark-team-a -l spark-app-name=tpcds-benchmark-gluten-parquet-arm64
kubectl port-forward svc/spark-history-server 18080:80 -n spark-history-server
Step 4: Spark History Server Analysis
Access detailed execution plans and metrics:
kubectl port-forward svc/spark-history-server 18080:80 -n spark-history-server
- Point your browser to
http://localhost:18080. - Locate both
spark-<ID>-nativeandspark-<ID>-glutenapplications. - In the Spark UI, inspect:
- SQL tab execution plans
- Presence of
WholeStageTransformerstages in Gluten jobs - Stage execution times across both runs
- Executor metrics for off-heap memory usage
Step 5: Summarize Findings
- Export runtime metrics from the Spark UI or event logs for both jobs.
- Capture query-level comparisons (duration, stage counts, fallbacks) to document where Gluten accelerated or regressed.
- Feed the results into cost or capacity planning discussions—speedups translate directly into smaller clusters or faster SLA achievement.
Key Metrics to Analyze
As you compare native and Gluten runs, focus on the following signals:
-
Query Plan Differences:
- Native:
WholeStageCodegenstages - Gluten:
WholeStageTransformerstages
- Native:
-
Memory Usage Patterns:
- Native: High on-heap usage, frequent GC
- Gluten: Off-heap Arrow buffers, minimal GC
-
CPU Utilization:
- Native: 60-70% efficiency
- Gluten: 80-90+ % efficiency with SIMD
Performance Analysis and Pitfalls
Gluten reduces friction for Spark adopters, but a few tuning habits help avoid regressions. Use the notes below as a checklist during rollout.
Common Configuration Pitfalls
# ❌ WRONG - Insufficient off-heap memory
"spark.memory.offHeap.size": "512m" # Too small for real workloads
# ✅ CORRECT - Adequate off-heap allocation
"spark.memory.offHeap.size": "4g" # 20-30% of executor memory
# ❌ WRONG - Missing Java module access
# Results in: java.lang.IllegalAccessError
# ✅ CORRECT - Required for Java 17
"spark.executor.extraJavaOptions": "--add-opens=java.base/java.nio=ALL-UNNAMED"
# ❌ WRONG - Velox backend not enabled
"spark.gluten.sql.columnar.backend.ch.enabled": "true" # ClickHouse, not Velox!
# ✅ CORRECT - Velox backend configuration
"spark.gluten.sql.columnar.backend.velox.enabled": "true"
Performance Optimization Tips
-
Memory Sizing:
- Off-heap: 20-30% of executor memory
- Executor overhead: 15-20% reserved for Arrow buffers
- Driver memory: 8-20 GB for complex queries (this benchmark used 20 GB)
-
CPU Optimization:
- Velox supports both x86 SIMD (AVX2/AVX-512) and ARM Neon — pick the instance class that matches your cost/perf target. Our 3TB benchmark ran on Graviton4 (
r8gd.12xlarge). - Set spark.executor.cores = 4-8 for optimal vectorization
- Reserve NVMe-backed instance storage for shuffle and spill (e.g.,
/mnt/k8s-disks/0)
- Velox supports both x86 SIMD (AVX2/AVX-512) and ARM Neon — pick the instance class that matches your cost/perf target. Our 3TB benchmark ran on Graviton4 (
-
I/O Configuration:
- Enable S3A fast upload:
spark.hadoop.fs.s3a.fast.upload.buffer=disk - Increase connection pool to 200 connections:
spark.hadoop.fs.s3a.connection.maximum=200 - Use larger multipart sizes of 128 MB:
spark.hadoop.fs.s3a.multipart.size=128M
- Enable S3A fast upload:
Debugging Gluten Issues
# Enable debug logging
"spark.gluten.sql.debug": "true"
"spark.sql.planChangeLog.level": "WARN"
# Check for fallback operations
kubectl logs <spark-pod> | grep -i "fallback"
# Verify Velox library loading
kubectl exec <spark-pod> -- find /opt/spark -name "*velox*"
# Monitor off-heap memory usage
kubectl top pod <spark-pod> --containers
Verifying Gluten+Velox Execution in Spark History Server
When Gluten+Velox is working correctly, you'll see distinctive execution patterns in the Spark History Server that indicate native acceleration:
Key Indicators of Gluten+Velox Execution:
- VeloxSparkPlanExecApi.scala references in stages and tasks
- WholeStageCodegenTransformer nodes in the DAG visualization
- ColumnarBroadcastExchange operations instead of standard broadcast
- GlutenWholeStageColumnarRDD in the RDD lineage
- Methods like
executeColumnarandmapPartitionsat VeloxSparkPlanExecApi.scala lines
Example DAG Pattern:
AQEShuffleRead
├── ColumnarBroadcastExchange
├── ShuffledColumnarBatchRDD [Unordered]
│ └── executeColumnar at VeloxSparkPlanExecApi.scala:630
└── MapPartitionsRDD [Unordered]
└── mapPartitions at VeloxSparkPlanExecApi.scala:632
What This Means:
- VeloxSparkPlanExecApi: Gluten's interface layer to the Velox execution engine
- Columnar operations: Data processed in columnar format (more efficient than row-by-row)
- WholeStageTransformer: Multiple Spark operations fused into single native Velox operations
- Off-heap processing: Memory management handled by Velox, not JVM garbage collector
If you see traditional Spark operations like mapPartitions at <WholeStageCodegen> without Velox references, Gluten may have fallen back to JVM execution for unsupported operations.
Conclusion
Apache Gluten with the Velox backend consistently accelerates Spark SQL workloads on Amazon EKS, delivering a 1.63× overall speedup (39% time reduction) in our TPC-DS 3TB benchmark on Graviton4 (r8gd.12xlarge). 81 of 103 queries improved — top wins reached 4.4× on q93 and 4.1× on q23a — while a small set regressed, most notably q72. The performance gains stem from offloading compute-intensive operators to a native, vectorized engine, reducing JVM overhead and improving CPU efficiency.
When planning your rollout:
- Start by mirroring the configurations documented above, then tune off-heap memory and shuffle behavior based on workload shape.
- Use the Spark Operator deployment flow to A/B test native and Gluten runs so you can quantify gains and detect fallbacks early.
- Monitor Spark UI and metrics exports to build a data-backed case for production adoption or cluster right-sizing.
With the Docker image, Spark defaults, and example manifests provided in this guide, you can reproduce the benchmark end-to-end and adapt the pattern for your own cost and performance goals.
For complete implementation examples and benchmark results, see the GitHub repository.