Run Apache Beam pipelines with Spark on EKS
Apache Beam (Beam) is a flexible programming model for building batch and streaming data processing pipelines. With Beam, developers can write code once and run it on various execution engines, such as Apache Spark and Apache Flink. This flexibility allows organizations to leverage the strengths of different execution engines while maintaining a consistent codebase, reducing the complexity of managing multiple codebases and minimizing the risk of vendor lock-in.
Beam on Amazon EKS
The Spark Operator for Kubernetes simplifies the deployment and management of Apache Spark on Kubernetes. By using the Spark Operator, we can directly submit Apache Beam pipelines as Spark Applications and deploy and manage them on EKS cluster, taking advantage of features such as automatic scaling and self-healing capabilities on the robust and managed infrastructure of EKS.
Solution overview
In this solution, we will show how to deploy your Beam pipeline, written in Python, on an EKS cluster with Spark Operator. It uses the example pipeline from Apache Beam github repo.
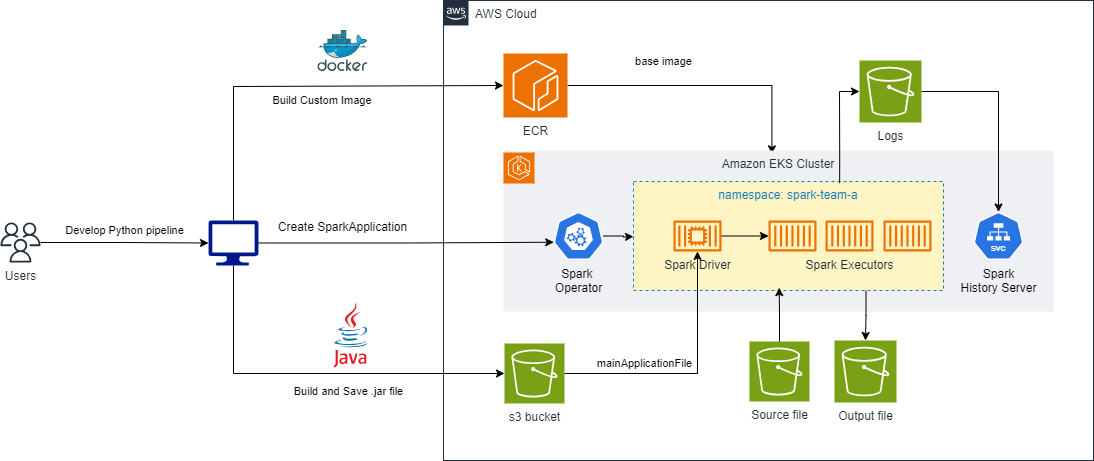
Deploy Beam pipeline
Deploying the Spark-Operator-on-EKS solution
👈Step 1: Build custom Docker Image with Spark and Beam SDK
Create a custom spark runtime image from the office spark base image, with a Python virtual environment and Apache Beam SDK pre-installed.
- Review the sample Dockerfile
- Customize the Dockerfile as needed for your environment
- Build the Docker image and push the image to ECR
cd examples/beam
aws ecr create-repository --repository-name beam-spark-repo --region us-east-1
docker build . --tag ${ACCOUNT_ID}.dkr.ecr.us-east-1.amazonaws.com/beam-spark-repo:eks-beam-image --platform linux/amd64,linux/arm64
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin ${ACCOUNT_ID}.dkr.ecr.us-east-1.amazonaws.com
docker push ${ACCOUNT_ID}.dkr.ecr.us-east-1.amazonaws.com/beam-spark-repo:eks-beam-image
We have created a docker image and published in ECR.
Step 2: Build and package the Beam pipeline with dependencies
With python 3.11 installed, create a Python virtual environment and install dependencies required for building the Beam pipeline:
python3 -m venv build-environment && \
source build-environment/bin/activate && \
python3 -m pip install --upgrade pip && \
python3 -m pip install apache_beam==2.58.0 \
s3fs \
boto3
Download the wordcount.py example pipeline and the sample input file. The wordcount Python example demonstrates an Apache Beam pipeline with the following stages: read files, split words, map, group, and sum word counts, and write output to files.
curl -O https://raw.githubusercontent.com/apache/beam/master/sdks/python/apache_beam/examples/wordcount.py
curl -O https://raw.githubusercontent.com/cs109/2015/master/Lectures/Lecture15b/sparklect/shakes/kinglear.txt
Upload the input text file to the S3 bucket.
aws s3 cp kinglear.txt s3://${S3_BUCKET}/
To run an Apache Beam Python pipeline on Spark, you may package the pipeline and all its dependencies into a single jar file. Use the below command to create the "fat" jar for the wordcount pipeline with all parameters, without actually executing the pipeline:
python3 wordcount.py --output_executable_path=./wordcountApp.jar \ --runner=SparkRunner \ --environment_type=PROCESS \ --environment_config='{"command":"/opt/apache/beam/boot"}' \ --input=s3://${S3_BUCKET}/kinglear.txt \ --output=s3://${S3_BUCKET}/output.txt
Upload the jar file to the S3 bucket to be used by the spark application.
aws s3 cp wordcountApp.jar s3://${S3_BUCKET}/app/
Step 3: Create and run the pipeline as SparkApplication
In this step, we create the manifest file for the SparkApplication object to submit the Apache Beam pipeline as a Spark application. Run the below commands to create a BeamApp.yaml file substituting the ACCOUNT_ID and S3_BUCKET values from the build environment.
envsubst < beamapp.yaml > beamapp.yaml
This command will replace the env variables in file beamapp.yaml.
Step 4: Execute Spark Job
Apply the YAML configuration file to create the SparkApplication on your EKS cluster to execute the Beam pipeline:
kubectl apply -f beamapp.yaml
Step 5: Monitor and review the pipeline job
Monitor and review the pipeline job The word count Beam pipeline may take a couple of minutes to execute. There are a few ways to monitor its status and review job details.
- We can use the Spark history server to check the running job
We used the spark-k8s-operator pattern to create the EKS cluster, which had already installed and configured a spark-history-server. Run the command below to start port-forwarding, then click the Preview menu and select Preview Running Application:
kubectl port-forward svc/spark-history-server 8080:80 -n spark-history-server
Open a new browser window and go to this address: http://127.0.0.1:8080/.
- Once the job completes successfully, in about 2 minutes, the output files (output.txt-*) containing words found in the input text and the count of each occurrence can be downloaded from the S3 bucket by running the below commands to copy the outputs to your build environment.
mkdir job_output && cd job_output
aws s3 sync s3://$S3_BUCKET/ . --include "output.txt-*" --exclude "kinglear*" --exclude app/*
Output looks like below:
...
particular: 3
wish: 2
Either: 3
benison: 2
Duke: 30
Contending: 1
say'st: 4
attendance: 1
...