Flink Operator on EKS
Please note that we are working on adding more features to this blueprint such as Flink examples with multiple connectors, Ingress for WebUI, Grafana dashboards etc.
Introduction to Apache Flink
Apache Flink is an open-source, unified stream processing and batch processing framework that was designed to process large amounts of data. It provides fast, reliable, and scalable data processing with fault tolerance and exactly-once semantics. Some of the key features of Flink are:
- Distributed Processing: Flink is designed to process large volumes of data in a distributed fashion, making it horizontally scalable and fault-tolerant.
- Stream Processing and Batch Processing: Flink provides APIs for both stream processing and batch processing. This means you can process data in real-time, as it's being generated, or process data in batches.
- Fault Tolerance: Flink has built-in mechanisms for handling node failures, network partitions, and other types of failures.
- Exactly-once Semantics: Flink supports exactly-once processing, which ensures that each record is processed exactly once, even in the presence of failures.
- Low Latency: Flink's streaming engine is optimized for low-latency processing, making it suitable for use cases that require real-time processing of data.
- Extensibility: Flink provides a rich set of APIs and libraries, making it easy to extend and customize to fit your specific use case.
Architecture
Flink Architecture high level design with EKS.
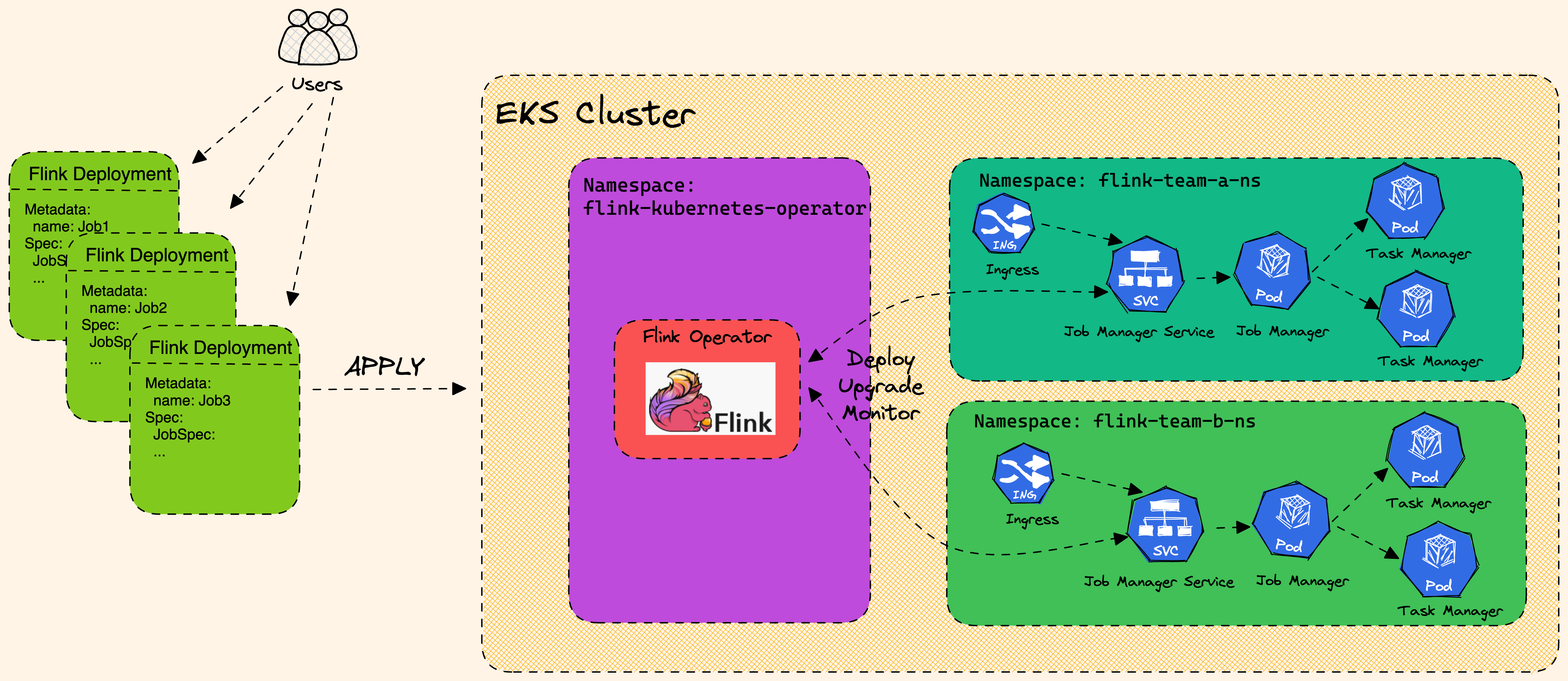
Flink Kubernetes Operator
Flink Kubernetes Operator is a powerful tool for managing Flink clusters on Kubernetes. Flink Kubernetes Operator (Operator) acts as a control plane to manage the complete deployment lifecycle of Apache Flink applications. The Operator can be installed on a Kubernetes cluster using Helm. The core responsibility of the Flink operator is to manage the full production lifecycle of Flink applications.
- Running, suspending and deleting applications
- Stateful and stateless application upgrades
- Triggering and managing savepoints
- Handling errors, rolling-back broken upgrades
Flink Operator defines two types of Custom Resources(CR) which are the extensions of the Kubernetes API.
- FlinkDeployment
- FlinkSessionJob
FlinkDeployment
-
FlinkDeployment CR defines Flink Application and Session Cluster deployments.
-
Application deployments manage a single job deployment on a dedicated Flink cluster in Application mode.
-
Session clusters allows you to run multiple Flink Jobs on an existing Session cluster.
FlinkDeployment in Application modes, Click to toggle content!
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: default
name: basic-example
spec:
image: flink:1.16
flinkVersion: v1_16
flinkConfiguration:
taskmanager.numberOfTaskSlots: "2"
serviceAccount: flink
jobManager:
resource:
memory: "2048m"
cpu: 1
taskManager:
resource:
memory: "2048m"
cpu: 1
job:
jarURI: local:///opt/flink/examples/streaming/StateMachineExample.jar
parallelism: 2
upgradeMode: stateless
state: running
FlinkSessionJob
-
The
FlinkSessionJobCR defines the session job on the Session cluster and each Session cluster can run multipleFlinkSessionJob. -
Session deployments manage Flink Session clusters without providing any job management for it
FlinkSessionJob using an existing "basic-session-cluster" session cluster deployment
apiVersion: flink.apache.org/v1beta1
kind: FlinkSessionJob
metadata:
name: basic-session-job-example
spec:
deploymentName: basic-session-cluster
job:
jarURI: https://repo1.maven.org/maven2/org/apache/flink/flink-examples-streaming_2.12/1.15.3/flink-examples-streaming_2.12-1.15.3-TopSpeedWindowing.jar
parallelism: 4
upgradeMode: stateless
Session clusters use a similar spec to Application clusters with the only difference that job is not defined in the yaml spec.
According to the Flink documentation, it is recommended to use FlinkDeployment in Application mode for production environments.
On top of the deployment types the Flink Kubernetes Operator also supports two modes of deployments: Native and Standalone.
- Native
- Standalone
Native
- Native cluster deployment is the default deployment mode and uses Flink’s built in integration with Kubernetes when deploying the cluster.
- Flink cluster communicates directly with Kubernetes and allows it to manage Kubernetes resources, e.g. dynamically allocate and de-allocate TaskManager pods.
- Flink Native can be useful for advanced users who want to build their own cluster management system or integrate with existing management systems.
- Flink Native allows for more flexibility in terms of job scheduling and execution.
- For standard Operator use, running your own Flink Jobs in Native mode is recommended.
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
...
spec:
...
mode: native
Standalone
-
Standalone cluster deployment simply uses Kubernetes as an orchestration platform that the Flink cluster is running on.
-
Flink is unaware that it is running on Kubernetes and therefore all Kubernetes resources need to be managed externally, by the Kubernetes Operator.
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
...
spec:
...
mode: standalone
Best Practices for Running Flink Jobs on Kubernetes
To get the most out of Flink on Kubernetes, here are some best practices to follow:
- Use the Kubernetes Operator: Install and use the Flink Kubernetes Operator to automate the deployment and management of Flink clusters on Kubernetes.
- Deploy in dedicated namespaces: Create a separate namespace for the Flink Kubernetes Operator and another one for Flink jobs/workloads. This ensures that the Flink jobs are isolated and have their own resources.
- Use high-quality storage: Store Flink checkpoints and savepoints in high-quality storage such as Amazon S3 or another durable external storage. These storage options are reliable, scalable, and offer durability for large volumes of data.
- Optimize resource allocation: Allocate sufficient resources to Flink jobs to ensure optimal performance. This can be done by setting resource requests and limits for Flink containers.
- Proper network isolation: Use Kubernetes Network Policies to isolate Flink jobs from other workloads running on the same Kubernetes cluster. This ensures that Flink jobs have the required network access without being impacted by other workloads.
- Configure Flink optimally: Tune Flink settings according to your use case. For example, adjust Flink's parallelism settings to ensure that Flink jobs are scaled appropriately based on the size of the input data.
- Use checkpoints and savepoints: Use checkpoints for periodic snapshots of Flink application state and savepoints for more advanced use cases such as upgrading or downgrading the application.
- Store checkpoints and savepoints in the right places: Store checkpoints in distributed file systems or key-value stores like Amazon S3 or another durable external storage. Store savepoints in a durable external storage like Amazon S3.
Flink Upgrade
Flink Operator provides three upgrade modes for Flink jobs. Check out the Flink upgrade docs for up-to-date information.
- stateless: Stateless application upgrades from empty state
- last-state: Quick upgrades in any application state (even for failing jobs), does not require a healthy job as it always uses the latest checkpoint information. Manual recovery may be necessary if HA metadata is lost.
- savepoint: Use savepoint for upgrade, providing maximal safety and possibility to serve as backup/fork point. The savepoint will be created during the upgrade process. Note that the Flink job needs to be running to allow the savepoint to get created. If the job is in an unhealthy state, the last checkpoint will be used (unless kubernetes.operator.job.upgrade.last-state-fallback.enabled is set to false). If the last checkpoint is not available, the job upgrade will fail.
last-state or savepoint are recommended modes for production
Deploying the Solution
👈Execute Sample Flink job with Karpenter
👈Execute Sample Flink job with Managed Node Groups and Cluster Autoscaler
👈Cleanup
👈To avoid unwanted charges to your AWS account, delete all the AWS resources created during this deployment