generative-ai-cdk-constructs
aws-rag-appsync-stepfn-opensearch
![]()
All classes are under active development and subject to non-backward compatible changes or removal in any future version. These are not subject to the Semantic Versioning model. This means that while you may use them, you may need to update your source code when upgrading to a newer version of this package.
| Language | Package |
|---|---|
 TypeScript TypeScript |
@cdklabs/generative-ai-cdk-constructs |
 Python Python |
cdklabs.generative_ai_cdk_constructs |
Table of contents
- Overview
- Initializer
- Pattern Construct Props
- Pattern Properties
- Default properties
- Troubleshooting
- Architecture
- Cost
- Security
- Supported AWS Regions
- Quotas
- Clean up
Overview
This CDK construct creates a pipeline for RAG (retrieval augmented generation) source. It ingests documents and then converts them into text formats. The output can be used for scenarios with long context windows. This means that your system can now consider and analyze a significant amount of surrounding information when processing and understanding text. This is especially valuable in tasks like language understanding and document summarization.
PDF files and images(.jpg,.jpeg,.svg,.png) are uploaded to an input Amazon Simple Storage Service (S3) bucket. Authorized clients (Amazon Cognito user pool) will trigger an AWS AppSync mutation to start the ingestion process, and can use subscriptions to get notifications on the ingestion status. The mutation call will trigger an AWS Step Function with three different steps:
- Input validation: an AWS Lambda function will verify the input formats of the files requested for ingestion. If the files are in a format which is not supported by the pipeline, an error message will be returned.
- Transformation: the input files are processed in parallel using a Map state through an AWS Lambda. The function uses the LangChain client to get the content of each file and store the text file in the output bucket. This is useful for workflows which want to use a long context window approach and send the entire file as context to a large language model. If the file name already exists in the output bucket, the input file will not be processed. For image files the the transformation step use Amazon Rekognition to detect lables and image moderation. It then generate a descriptive text of the image using anthropic.claude-v2:1 and save the text file in processed s3 bucket.
- Embeddings step: Files processed and stored in the output S3 bucket are consumed by an AWS Lambda function. Chunks from documents are created, as well as text embeddings using Amazon Bedrock (model: amazon.titan-embed-text-v1). For uploaded images multimodality embeddings are created using Amazon Bedrock (model: amazon.titan-embed-image-v1) The chunks and embeddings are then stored in a knowledge base (OpenSearch provisioned cluster). Make sure the model (amazon.titan-embed-text-v1,amazon.titan-embed-image-v1,anthropic.claude-v2:1) is enabled in your account. Please follow the Amazon Bedrock User Guide for steps related to enabling model access.
Documents stored in the knowledge base contain the following metadata:
- Timestamp: when the embeddings were created (current time in seconds since the Epoch)
- Embeddings model used: amazon.titan-embed-text-v1 , amazon.titan-embed-image-v1
If you have multiple workflows using GraphQL endpoints and want to use a single endpoint, you can use an AppSync Merged API. This construct can take as a parameter an existing AppSync Merged API; if provided, the mutation call and subscription updates will be targeted at the Merged API.
This construct will require an existing Amazon OpenSearch provisioned cluster. You can follow the steps in the official AWS Developer Guide to create and manage your OpenSearch domain.
AWS Lambda functions provisioned in this construct use Powertools for AWS Lambda (Python) for tracing, structured logging, and custom metrics creation. The table below provides the created metrics and the name of the service used, and can be accessed from Amazon CloudWatch Logs.
| AWS Lambda | Service | Custom Metrics |
|---|---|---|
| input_validation | INGESTION_INPUT_VALIDATION | SupportedFile (number of requests which provide a supported file format), UnsupportedFile (number of requests which provide an unsupported file format) |
| s3_file_transformer | INGESTION_FILE_TRANSFORMER | N/A |
| embeddings_job | INGESTION_EMBEDDING_JOB | N/A |
Index creation and embeddings model selection
As of today, the construct manages only one OpenSearch index. The index name is configured through the construct property openSearchIndexName. If the index doesn’t exist, the construct will create it when ingesting a document. This means that the value of the field knn_vector in the OpenSearch index will be set to the value of the length of the embedding vector for the embedding model selected. For instance, the model Amazon Titan Embeddings Text model V2 outputs a vector of size 1024 dimensions. Thus, if using this model, the OpenSearch vector index knn_vector field value will be set to 1024.
Once an embedding model has been selected and documents have been ingested, you have to use the same embedding model for subsequent files to ingest. This is because every embeddings model develops its own distinctive embedding space. An embedding produced within one space holds no meaning or relevance in a different embedding space, even if the spaces are the same size. If you want to use a different embedding model, you will need to re-deploy the construct with a different index name (another index will be created) or destroy the stack containing the ingestion construct, and re-create it.
This also applies to the selection of the embedding model used to retrieve information from the OpenSearch index. You will have to use the same embedding model for querying as the one used to create the embeddings.
CRUD operations
As of today, the construct allows you to only ingest documents and create embeddings. The construct doesn’t support additional operations on documents/embeddings (update, deletion).
Here is a minimal deployable pattern definition:
TypeScript
import { Construct } from 'constructs';
import { Stack, StackProps, Aws } from 'aws-cdk-lib';
import * as os from 'aws-cdk-lib/aws-opensearchservice';
import * as cognito from 'aws-cdk-lib/aws-cognito';
import { RagAppsyncStepfnOpensearch, RagAppsyncStepfnOpensearchProps } from '@cdklabs/generative-ai-cdk-constructs';
// get an existing OpenSearch provisioned cluster in the same VPC as of RagAppsyncStepfnOpensearch construct
// Security group for the existing opensearch cluster should allow traffic on 443.
const osDomain = os.Domain.fromDomainAttributes(this, 'osdomain', {
domainArn: 'arn:' + Aws.PARTITION + ':es:us-east-1:XXXXXX',
domainEndpoint: 'https://XXXXX.us-east-1.es.amazonaws.com'
});
// get an existing userpool
const cognitoPoolId = 'us-east-1_XXXXX';
const userPoolLoaded = cognito.UserPool.fromUserPoolId(this, 'myuserpool', cognitoPoolId);
const rag_source = new RagAppsyncStepfnOpensearch(
this,
'RagAppsyncStepfnOpensearch',
{
existingOpensearchDomain: osDomain,
openSearchIndexName: 'demoindex',
cognitoUserPool: userPoolLoaded
}
)
Python
from constructs import Construct
from aws_cdk import (
aws_opensearchservice as os,
aws_cognito as cognito,
)
from cdklabs.generative_ai_cdk_constructs import RagAppsyncStepfnOpensearch
# get an existing OpenSearch provisioned cluster in the same VPC as of RagAppsyncStepfnOpensearch construct
# Security group for the existing opensearch cluster should allow traffic on 443.
os_domain = os.Domain.from_domain_attributes(
self,
'osdomain',
domain_arn='arn:aws:es:us-east-1:XXXXXX:resource-id',
domain_endpoint='https://XXXXX.us-east-1.es.amazonaws.com',
)
# get an existing userpool
cognito_pool_id = 'us-east-1_XXXXX';
user_pool_loaded = cognito.UserPool.from_user_pool_id(
self,
'myuserpool',
user_pool_id=cognito_pool_id,
)
rag_source = RagAppsyncStepfnOpensearch(
self,
'RagAppsyncStepfnOpensearch',
existing_opensearch_domain=os_domain,
open_search_index_name='demoindex',
cognito_user_pool=user_pool_loaded,
)
After deploying the CDK stack, the document summarization workflow can be invoked using GraphQL APIs. The API schema details are here: resources/gen-ai/aws-rag-appsync-stepfn-opensearch/schema.graphql.
The code below provides an example of a mutation call and associated subscription to trigger a pipeline call and get status notifications:
Subscription call to get notifications about the ingestion process:
subscription MySubscription {
updateIngestionJobStatus(ingestionjobid: "123") {
files {
name
status
imageurl
}
}
}
_________________________________________________
Expected response:
{
"data": {
"updateIngestionJobStatus": {
"files": [
{
"name": "a.pdf",
"status": "succeed",
"imageurl":"s3presignedurl"
}
{
"name": "b.pdf",
"status": "succeed",
"imageurl":"s3presignedurl"
}
]
}
}
}
Where:
- ingestionjobid: id which can be used to filter subscriptions on client side The subscription will display the status and name for each file
- files.status: status update of the ingestion for the file specified
- files.name: name of the file stored in the input S3 bucket
Mutation call to trigger the ingestion process:
mutation MyMutation {
ingestDocuments(ingestioninput: {
embeddings_model:
{
provider: "Bedrock",
modelId: "amazon.titan-embed-text-v1",
streaming: true
},
files: [{status: "", name: "a.pdf"}],
ingestionjobid: "123",
ignore_existing: true}) {
files {
imageurl
status
}
ingestionjobid
}
}
_________________________________________________
Expected response:
{
"data": {
"ingestDocuments": {
"ingestionjobid": null
}
}
}
Where:
- files.status: this field will be used by the subscription to update the status of the ingestion for the file specified
- files.name: name of the file stored in the input S3 bucket
- ingestionjobid: id which can be used to filter subscriptions on client side
- embeddings_model: Based on type of modality (text or image ) the model provider , model id can be used.
Initializer
new RagApiGatewayOpensearch(scope: Construct, id: string, props: RagApiGatewayOpensearchProps)
Parameters
- scope Construct
- id string
- props RagAppsyncStepfnOpensearchProps
Pattern Construct Props
Note: One of either
existingOpensearchDomainorexistingOpensearchServerlessCollectionmust be specified, but not both.
| Name | Type | Required | Description |
|---|---|---|---|
| existingOpensearchDomain | opensearchservice.IDomain | Existing domain for the OpenSearch Service. Mutually exclusive with existingOpensearchServerlessCollection - only one should be specified. |
|
| existingOpensearchServerlessCollection | openSearchServerless.CfnCollection | Existing Amazon Amazon OpenSearch Serverless collection. Mutually exclusive with existingOpensearchDomain - only one should be specified. |
|
| openSearchIndexName | string | Index name for the Amazon OpenSearch Service. If doesn’t exist, the pattern will create the index in the cluster. | |
| cognitoUserPool | cognito.IUserPool | Cognito user pool used for authentication. | |
| openSearchSecret | secret.ISecret | Optional. Secret containing credentials to authenticate to the existing Amazon OpenSearch domain if fine grain control access if configured. If not provided, the Lambda function will use AWS Signature Version 4. | |
| vpcProps | ec2.VpcProps | Custom properties for a VPC the construct will create. This VPC will be used by the Lambda functions the construct creates. Providing both this and existingVpc is an error. | |
| existingVpc | ec2.IVpc | An existing VPC in which to deploy the construct. Providing both this and vpcProps is an error. | |
| existingSecurityGroup | ec2.ISecurityGroup | Existing security group allowing access to Amazon OpenSearch domain. Used by the lambda functions built by this construct. If not provided, the construct will create one. | |
| existingBusInterface | events.IEventBus | Existing instance of an Amazon EventBridge bus. If not provided, the construct will create one. | |
| existingInputAssetsBucketObj | s3.IBucket | Existing instance of Amazon S3 Bucket object, providing both this and bucketInputsAssetsProps will cause an error. |
|
| bucketInputsAssetsProps | s3.BucketProps | User provided props to override the default props for the Amazon S3 Bucket. Providing both this and existingInputAssetsBucketObj will cause an error. |
|
| existingProcessedAssetsBucketObj | s3.IBucket | Existing instance of Amazon S3 Bucket object, providing both this and bucketProcessedAssetsProps will cause an error. |
|
| bucketProcessedAssetsProps | s3.BucketProps | User provided props to override the default props for the Amazon S3 Bucket. Providing both this and existingProcessedAssetsBucketObj will cause an error. |
|
| stage | string | Value will be appended to resources name Service. | |
| existingMergedApi | appsync.CfnGraphQLApi | Existing merged api instance. The merge API provides a federated schema over source API schemas. | |
| observability | boolean | Enables observability on all services used. Warning: associated cost with the services used. Best practice to enable by default. Defaults to true. | |
| customEmbeddingsDockerLambdaProps | DockerLambdaCustomProps | Allows to provide Embeddings custom lambda code and settings instead of the default construct implementation. | |
| customInputValidationDockerLambdaProps | DockerLambdaCustomProps | Allows to provide input validation custom lambda code and settings instead of the default construct implementation. | |
| customFileTransformerDockerLambdaProps | DockerLambdaCustomProps | Allows to provide file transformation custom lambda code and settings instead of the default construct implementation. |
Pattern Properties
| Name | Type | Description |
|---|---|---|
| vpc | ec2.IVpc | The VPC used by the construct (whether created by the construct or providedb by the client) |
| securityGroup | ec2.ISecurityGroup | The VPC used by the construct (whether created by the construct or providedb by the client) |
| ingestionBus | events.IEventBus | The VPC used by the construct (whether created by the construct or providedb by the client) |
| s3InputAssetsBucketInterface | s3.IBucket | Returns an instance of s3.IBucket created by the construct |
| s3InputAssetsBucket | s3.Bucket | Returns an instance of s3.Bucket created by the construct. IMPORTANT: If existingInputAssetsBucketObj was provided in Pattern Construct Props, this property will be undefined |
| s3ProcessedAssetsBucketInterface | s3.IBucket | Returns an instance of s3.IBucket created by the construct |
| s3ProcessedAssetsBucket | s3.Bucket | Returns an instance of s3.IBucket created by the construct. IMPORTANT: If existingProcessedAssetsBucketObj was provided in Pattern Construct Props, this property will be undefined |
| graphqlApi | appsync.IGraphqlApi | Returns an instance of appsync.IGraphqlApi created by the construct |
| stateMachine | StateMachine | Returns an instance of appsync.IGraphqlApi created by the construct |
| embeddingsLambdaFunction | lambda.DockerImageFunction | Returns an instance of lambda.DockerImageFunction used for the embeddings job created by the construct |
| fileTransformerLambdaFunction | lambda.DockerImageFunction | Returns an instance of lambda.DockerImageFunction used for the file transformation job created by the construct |
| inputValidationLambdaFunction | lambda.DockerImageFunction | Returns an instance of lambda.DockerImageFunction used for the input validation job created by the construct |
Default properties
Out of the box implementation of the construct without any override will set the following defaults:
Authentication
- Primary authentication method for the AppSync GraphQL API is Amazon Cognito User Pool.
- Secondary authentication method for the AppSync GraphQL API is IAM role.
Networking
- Set up a VPC
- Uses existing VPC if provided, otherwise creates a new one
- Set up a Security Group used by the AWS Lambda functions
- Uses existing Security Group, otherwise creates a new one
Amazon S3 Buckets
- Sets up two Amazon S3 Buckets
- Uses existing buckets if provided, otherwise creates new ones
Observability
By default the construct will enable logging and tracing on all services which support those features. Observability can be turned off by setting the pattern property observability to false.
- AWS Lambda: AWS X-Ray, Amazon CloudWatch Logs
- AWS Step Function: AWS X-Ray, Amazon CloudWatch Logs
- AWS AppSync GraphQL API: AWS X-Ray, Amazon CloudWatch Logs
Troubleshooting
| Error Code | Message | Description | Fix |
|---|---|---|---|
| Ingested | The file provided as input was correctly ingested | Not an error, informational only | |
| Error - internal os error cannot connect | The embeddings Lambda function is not able to connect to the Amazon OpenSearch instance | Verify the credentials and network settings to ensure that the Lambda function is authorized to access the cluster | |
| Error_File already exists | The file provided as input is already transformed in the output bucket | Remove the file from the transformed output bucket, and if needed also from the knowledge base | |
| Error_Unable to load document | The Lambda transformer function was unable to load the document provided as input argument | Verify that the input file is located in the input bucket | |
| Error_Unsupported | The input file document is in a format not supported by the workflow | Provide a file in a supported format | |
| Vector dimension mismatch | Files have been ingested using an embeddings model with an output vector size different from the knn_vector field of the OpenSearch index. See this bug for more details. | Use the same embeddings model to ingest all files. Also see the previous section Index creation and embeddings model selection. |
Architecture
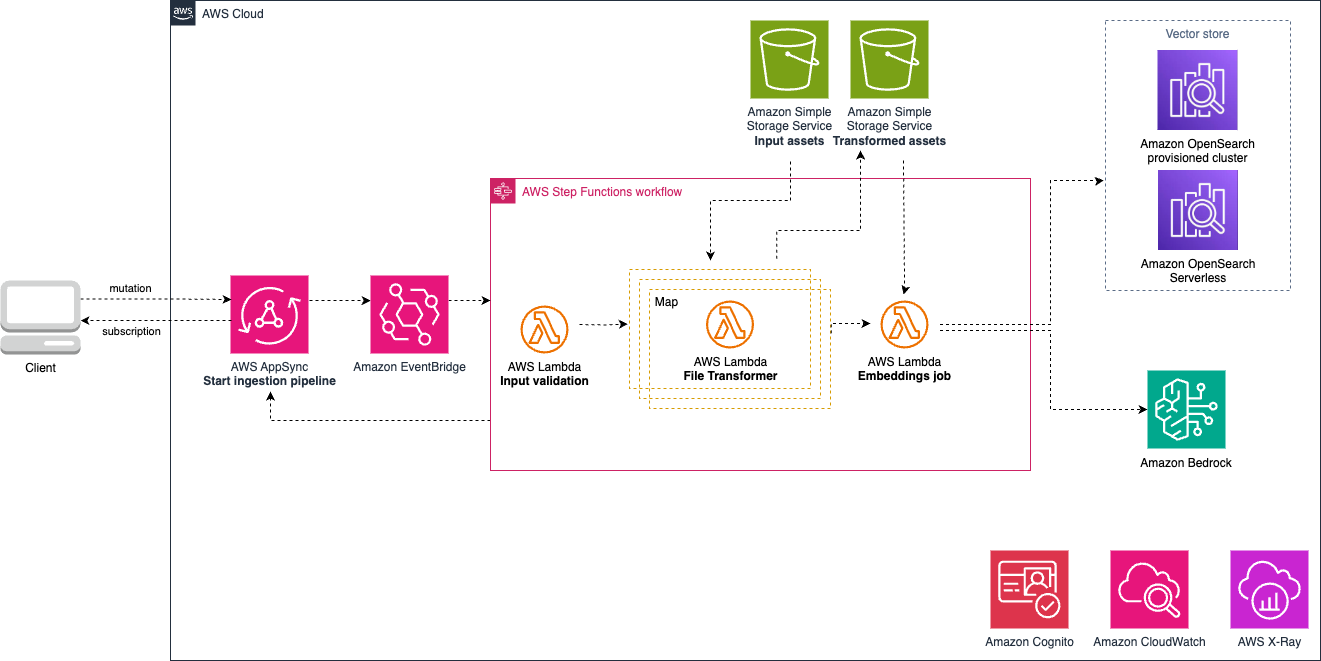
Cost
You are responsible for the cost of the AWS services used while running this construct. As of this revision, the cost for running this construct with the default settings in the US East (N. Virginia) Region is approximately $2,852.32 per month.
We recommend creating a budget through AWS Cost Explorer to help manage costs. Prices are subject to change. For full details, refer to the pricing webpage for each AWS service used in this solution.
The following table provides a sample cost breakdown for deploying this solution with the default parameters in the US East (N. Virginia) Region for one month.
| AWS Service | Dimensions | Cost [USD] |
|---|---|---|
| AWS Step Functions | 15 requests per hour for data ingestion, each with 2 files (4 steps per workflow) | 0.99 |
| Amazon Virtual Private Cloud | 0.00 | |
| AWS AppSync | 15 requests per hour to trigger data ingestion + (15 x 4 calls to notify clients through subscriptions) = 54,000 requests per month | 0.22 |
| Amazon EventBridge | 15 requests per hour = 10800 custom events per month | 0.01 |
| AWS Lambda | 15 ingestion requests per hour with 2 files each time, through 4 Lambda functions each allocated with 7076 MB of memory allocated and 512 MB of ephemeral storage allocated and an average run time of 30 seconds = 43200 requests per month | 142.59 |
| Amazon Simple Storage Service | 15 requests per hour for ingestion with 2 files in input format (PDF) with an average size of 1MB and transformed files to text format with an average size of 1 MB = 43.2 GB per month in S3 Standard Storage | 0.99 |
| Amazon Bedrock | Assumptions: On-Demand pricing with Titan Embeddings model to generate embeddings for 2 files of 1MB each per request at 15 requests per hour, which would represent ~2,5 million tokens per request as input. Max model input is 8k tokens per request and produces 1,536 tokens as output. 312.5 calls x $0.0001 for 1000 input tokens x 8k tokens/1000 = $0.25 per ingestion request x 15 requests per hour $3.75/h = $90/day x 30 = $2.7k per month | 2,700 |
| Amazon CloudWatch | 15 metrics using 5 GB data ingested for logs | 7.02 |
| AWS X-Ray | 100,000 requests per month through AppSync and Lambda calls | 0.50 |
| Total monthly cost | 2,852.32 |
The resources not created by this construct (Amazon Cognito User Pool, Amazon OpenSearch provisioned cluster, AppSync Merged API, AWS Secrets Manager secret) do not appear in the table above. You can refer to the decicated pages to get an estimate of the cost related to those services:
- Amazon OpenSearch Service Pricing
- AWS AppSync pricing (for Merged API if used)
- Amazon Cognito Pricing
- AWS Secrets Manager Pricing
Note You can share the Amazon OpenSearch provisioned cluster between use cases, but this can drive up the number of queries per index and additional charges will apply.
Security
When you build systems on AWS infrastructure, security responsibilities are shared between you and AWS. This shared responsibility model reduces your operational burden because AWS operates, manages, and controls the components including the host operating system, virtualization layer, and physical security of the facilities in which the services operate. For more information about AWS security, visit AWS Cloud Security.
This construct requires you to provide an existing Amazon Cognito User Pool and a provisioned Amazon OpenSearch cluster. Please refer to the official documentation on best practices to secure those services:
Optionnaly, you can provide existing resources to the constructs (marked optional in the construct pattern props). If you chose to do so, please refer to the official documentation on best practices to secure each service:
If you grant access to a user to your account where this construct is deployed, this user may access information stored by the construct (Amazon Simple Storage Service buckets, Amazon OpenSearch cluster, Amazon CloudWatch logs). To help secure your AWS resources, please follow the best practices for AWS Identity and Access Management (IAM).
AWS CloudTrail provides a number of security features to consider as you develop and implement your own security policies. Please follow the related best practices through the official documentation.
Note This construct requires you to provide documents in the input assets bucket. You should validate each file in the bucket before using this construct. See here for file input validation best practices. Ensure you only ingest the appropriate documents into your knowledge base. Any results returned by the knowledge base is eligible for inclusion into the prompt; and therefore, being sent to the LLM. If using a third-party LLM, ensure you audit the documents contained within your knowledge base. This construct provides several configurable options for logging. Please consider security best practices when enabling or disabling logging and related features. Verbose logging, for instance, may log content of API calls. You can disable this functionality by ensuring observability flag is set to false.
Supported AWS Regions
This solution optionally uses the Amazon Bedrock and Amazon OpenSearch service, which is not currently available in all AWS Regions. You must launch this construct in an AWS Region where these services are available. For the most current availability of AWS services by Region, see the AWS Regional Services List.
Note You need to explicity enable access to models before they are available for use in the Amazon Bedrock service. Please follow the Amazon Bedrock User Guide for steps related to enabling model access.
Quotas
Service quotas, also referred to as limits, are the maximum number of service resources or operations for your AWS account.
Make sure you have sufficient quota for each of the services implemented in this solution. For more information, refer to AWS service quotas.
To view the service quotas for all AWS services in the documentation without switching pages, view the information in the Service endpoints and quotas page in the PDF instead.
Clean up
When deleting your stack which uses this construct, do not forget to go over the following instructions to avoid unexpected charges:
- empty and delete the Amazon Simple Storage Bucket(s) created by this construct if you didn’t provide existing ones during the construct creation
- empty the data stored in the knowledge base (Amazon OpenSearch provisioned cluster), as well as the index created if an existing one was not provided
- if the observability flag is turned on, delete all the associated logs created by the different services in Amazon CloudWatch logs
© Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.