架构概览
架构图
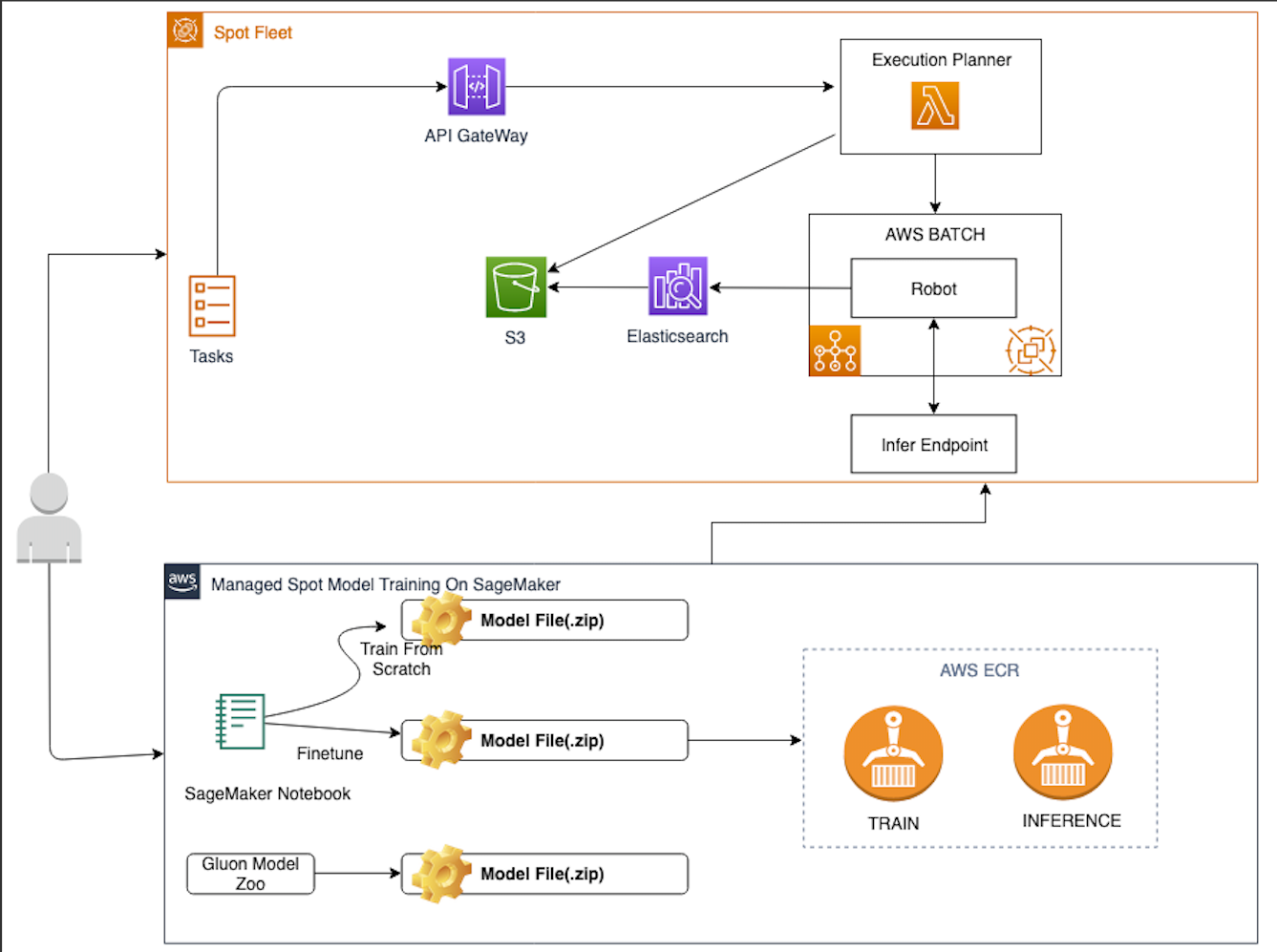
架构与工作原理简介
使用流程
- 运营人员通过REST API指定S3文件夹和要执行的任务类型,及配置的运行机器的资源类型,如OCR,s3://a-media-bucket/images,3 instances
- Execution Planner接收到指令后去S3爬取全部待处理文件的元数据并存放在DynamoDB中,随后以AWS Batch Job的形式启动相应的机器人执行相应的任务。
- 机器人将调用预先部署好的模型推理接口,将任务的结果存放在转移到S3
任务生成
首先,要将待盘活的数字资产存储在Amazon S3上。然后,您只需要向Amazon API Gateway发出REST请求,指定要处理的Amazon S3文件夹和要使用的机器人类型即可。机器人具体运行流程如下:
- Amazon API Gateway将请求转发到AWS Lambda。
- AWS Lambda 递归取出Amazon S3中所有待处理的文件路径,并生成待处理文件列表。
- AWS Lambda 将待处理文件列表存入Amazon Elasticsearch Service中。
- AWS Lambda 启动Amazon SageMaker的推理终端节点。
- AWS Lambda 通过AWS Step Functions启动一个或者多个AWS Batch任务。
- AWS Batch 执行相应资产盘活任务,从 Amazon S3 存储桶中读取源文件,并调用 Sagemaker的终端节点进行推理。推理结果会被写入 Amazon Elasticsearch Service (https://amazonaws-china.com/cn/elasticsearch-service/) 的索引中,识别结果将被写入您指定的S3路径。