Slurm on EKS
Deployment of ML models on EKS requires access to GPUs or Neuron instances. If your deployment isn't working, it’s often due to missing access to these resources. Also, some deployment patterns rely on Karpenter autoscaling and static node groups; if nodes aren't initializing, check the logs for Karpenter or Node groups to resolve the issue.
What is Slurm?
Slurm is an open-source, highly scalable workload manager and job scheduler designed for managing compute resources on compute clusters of all sizes. It provides three core functions: allocating access to compute resources, providing a framework for launching and monitoring parallel computing jobs, and managing queues of pending work to resolve resource contention.
Slurm is widely used in AI training to manage and schedule large-scale, GPU-accelerated workloads across high-performance computing clusters. It allows researchers and engineers to efficiently allocate computing resources, including CPUs, GPUs and memory, enabling distributed training of deep learning models and large language models by spanning jobs across many nodes with fine-grained control over resource types and job priorities. Slurm’s reliability, advanced scheduling features, and integration with both on-premise and cloud environments make it a preferred choice for handling the scale, throughput, and reproducibility that modern AI research and industry demand.
What is the Slinky Project?
The Slinky Project is an open-source suite of integration tools designed by SchedMD (the lead developers of Slurm) to bring Slurm capabilities into Kubernetes, combining the best of both worlds for efficient resource management and scheduling. The Slinky Project includes a Kubernetes operator for Slurm clusters, which implements custom-controllers and custom resource definitions (CRDs) to manage the lifecycle of Slurm Cluster and NodeSet resources deployed within a Kubernetes environment.
This Slurm cluster includes the following components:
| Component | Description |
|---|---|
| Controller (slurmctld) | The central management daemon that monitors resources, accepts jobs, and assigns work to compute nodes. |
| Accounting (slurmdbd) | Handles job accounting and user/project management through a MariaDB database backend. |
| Compute (slurmd) | The worker nodes that execute jobs, organized into NodeSets which can be grouped into different partitions. |
| Login | Provides SSH access points for users to interact with the Slurm cluster and submit jobs. |
| REST API (slurmrestd) | Offers HTTP-based API access to Slurm functionality for programmatic interaction with the cluster. |
| Authentication (sackd) | Manages credential authentication for secure access to Slurm services. |
| MariaDB | The database backend used by the accounting service to store job, user, and project information. |
| Prometheus Service Monitor | Configured within the controller to scrape metrics from scheduler, partition, node, and job endpoints for monitoring purposes. |
When paired with Amazon EKS, the Slinky Project unlocks the ability for enterprises who have standardized infrastructure management on Kubernetes to deliver a Slurm-based experience to their ML scientists. It also enables training, experimentation, and inference to happen on the same cluster of accelerated nodes.
Slurm on EKS Architecture
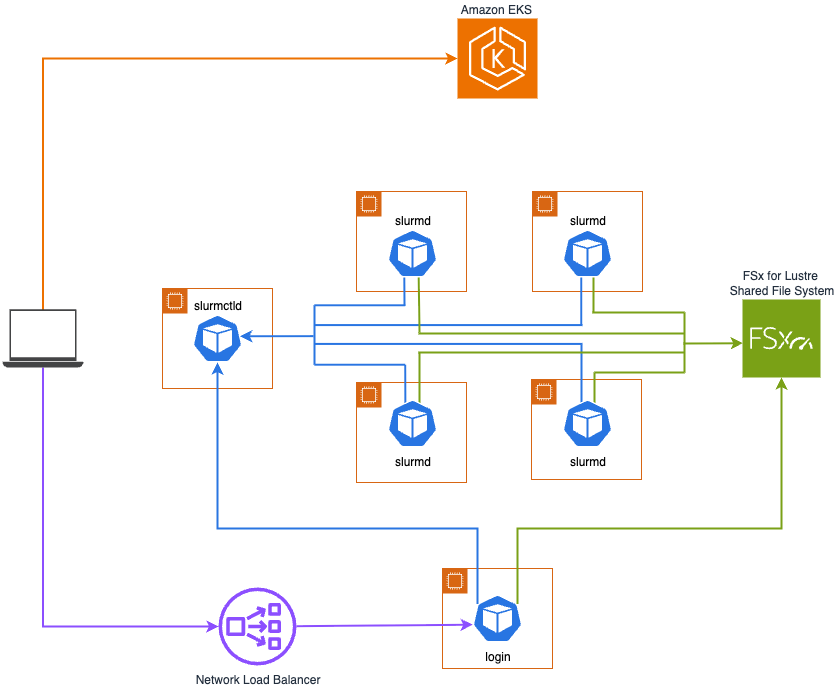
The diagram above depicts the Slurm on EKS deployment outlined in this guide. An Amazon EKS cluster acts as an orchestration layer, with core Slurm Cluster components hosted on a managed node group of m6i.xlarge instances, while a Karpenter NodePool manages the deployment of GPU accelerated compute nodes for the slurmd pods to run on. The Slinky Slurm operator and Slurm cluster are automatically deployed as ArgoCD applications.
The login LoadBalancer type service is annotated to dynamically create an AWS Network Load Balancer using the AWS Load Balancer Controller, allowing ML scientists to SSH into the login pod without interfacing with the Kubernetes API server via kubectl.
The login and slurmd pods also have an Amazon FSx for Lustre shared filesystem mounted. Having containerized slurmd pods allows many dependencies that would traditionally be installed manually using Conda or a Python virtual environment to be baked into the container image, but shared filesystems are still beneficial for storing training artifacts, data, logs, and checkpoints.
Key Features and Benefits
- Run Slurm workloads side by side with containerized Kubernetes applications on the same infrastructure. Both Slurm and Kubernetes workloads can be scheduled on the same node pools, increasing utilization and avoiding resource fragmentation.
- Manage both Slurm jobs and Kubernetes pods seamlessly, leveraging familiar tooling from both ecosystems without sacrificing control or performance.
- Dynamically add or removes compute nodes in response to workload demand, autoscaling allocated resources efficiently, handling spikes and lulls in demand to reduce infrastructure costs and idle resource waste.
- High-availability through Kubernetes orchestration. If a controller or worker pod fails, Kubernetes automatically restarts it, reducing manual intervention.
- Slurm’s sophisticated scheduling features (fair-share allocation, dependency management, priority scheduling) are integrated into Kubernetes, maximizing compute utilization and aligning resources with workload requirements.
- Slurm and its dependencies are deployed as containers, ensuring consistent deployments across environments. This reduces configuration drift and streamlines dev-to-prod transitions.
- Users can build Slurm images tailored to specialized needs (e.g., custom dependencies, libraries), promoting consistency and repeatability in scientific or regulated environments.
- Administrators can define custom Slurm clusters and node sets directly using Kubernetes Custom Resources, including partitioning compute nodes for different types of jobs (e.g., stable vs. opportunistic/backfill partitions)
- Slinky integrates with monitoring stacks for both Slurm and Kubernetes, providing robust metrics and visualization for administrators and users.