추론 준비 EKS 클러스터
추론 준비 EKS 클러스터는 AI/ML 추론 워크로드를 위해 특별히 설계된 사전 구성된 인프라 솔루션입니다. 이 솔루션은 AI on EKS inference charts 또는 자체 배포 및 모델을 사용하여 추론 서비스를 배포하고 실행하는 데 필요한 모든 구성 요소가 포함된 Kubernetes 클러스터를 제공합니다.
인프라에 대해 자세히 설명하는 확장된 Readme가 있습니다. 이 페이지에서는 이 아키텍처의 핵심 구성 요소와 이유를 강조합니다.
왜?
이 추론 준비 EKS 클러스터는 여정의 어느 단계에 있든 누구나 추론을 위해 EKS를 사용할 수 있도록 만들어졌습니다. LLM은 배포하기 어려울 수 있습니다: 모델 크기, 아키텍처, 기능 및 요구 사항에 따라 모델을 적절히 배포, 실행 및 확장하기 위해 다양한 도구가 필요�합니다. 또한 텍스트 -> 이미지 확산 모델이나 더 전통적인 머신 러닝 모델과 같이 LLM만이 아닌 모델을 실행하고 싶을 수도 있습니다.
이 인프라는 첫 번째 지원 계층입니다. 이 리포지토리에서 찾을 수 있는 Inference Charts 및 가이던스와 함께 AI on EKS는 원하는 추론을 실행할 수 있는 모든 도구와 지식을 갖추도록 목표로 합니다.
사용 사례
- 단일 모델 테스트: 모델을 배포하고 테스트하여 무엇을 하는지 또는 얼마나 잘 수행하는지 확인하고 싶은 경우.
- 다중 노드 분산 추론: 모델이 너무 커서 단일 노드에 맞지 않는 경우.
- 모델 오토스케일링: 들어오는 요청과 큐 길이에 따라 실행 중인 모델 수를 동적으로 조정해야 하는 경우.
- 모델 벤치마킹: 다양한 트래픽 패턴으로 주어진 데이터셋에서 모델이 어떻게 수행되는지 이해하고 싶은 경우. 이를 통해 서비스 수준 목표(SLO)를 충족하도록 모델 파라미터와 복제본을 조정할 수 있습니다.
- 다중 모델 아키텍처: LLM과 텍스트->이미지 확산 모델을 모두 테스트하고 싶은 경우.
소개
이 인프라는 다음과 같은 주요 기능을 갖춘 AI/ML 추론 워크로드에 최적화된 Amazon EKS 클러스터를 생성합니다:
- KubeRay Operator: 확장 가능한 추론을 위한 분산 Ray 워크로드 활성화
- LeaderWorkerSet: 다중 노드 분산 추론 활성화
- AIBrix 스택: 고급 추론 최적화 및 관리 기능
- GPU/Neuron 지원: NVIDIA GPU 및 AWS Neuron(Inferentia/Trainium) 워크로드 모두 준비
- AI/ML 관측성 스택: ML 워크로드를 위한 포괄적인 모니터링 및 관측성
- 오토스케일링: 비용 최적화를 위한 Karpenter 기반 노드 오토스케일링
클러스터는 AI on EKS Inference Charts와 원활하게 작동하도록 특별히 설계되어 추론 워크로드 배포를 위한 완전한 엔드투엔드 솔루션을 제공합니다.
리소스
이 인프라는 다음 AWS 리소스를 배포합니다:
핵심 인프라
- 여러 AZ에 걸쳐 퍼블릭 및 프라이빗 서브넷이 있는 Amazon VPC
- Amazon EKS Cluster (기본적으로 v1.33)
- EKS Managed Node Groups: EKS 컴퓨팅 노드로 사용되는 EC2 인스턴스의 오토 스케일링 그룹.
- 프라이빗 서브넷 인터넷 액세스를 위한 NAT 게이트웨이
- 퍼블릭 서브넷 액세스를 위한 인터넷 게이트웨이
- 적절한 인그레스/이그레스 규칙이 있는 보안 그룹
EKS 애드온
- 인그레스 관리를 위한 AWS Load Balancer Controller
- 영구 스토리지를 위한 EBS CSI Driver
- 파드 네트워킹을 위한 VPC CNI
- 서비스 검색을 위한 CoreDNS
- 서비스 네트워킹을 위한 Kube-proxy
- 리소스 메트릭을 위한 Metrics Server
- 로깅 및 모니터링을 위한 Amazon CloudWatch Observability
AI/ML 관련 구성 요소
- 분산 Ray 워크로드를 위한 KubeRay Operator
- 다중 노드 분산 추론을 위한 LeaderWorkerSet
- GPU 리소스 관리를 위한 NVIDIA Device Plugin
- Inferentia/Trainium 지원을 위한 AWS Neuron Device Plugin
- 지능형 노�드 오토스케일링을 위한 Karpenter
관측성 스택
- 메트릭 수집을 위한 Prometheus
- 시각화 및 대시보드를 위한 Grafana
- 알림을 위한 AlertManager
- 노드 수준 메트릭을 위한 Node Exporter
- GPU 메트릭을 위한 DCGM Exporter (GPU 노드가 있을 때)
AIBrix 구성 요소
- 추론 최적화를 위한 AIBrix Core
- 트래픽 관리를 위한 게이트웨이 및 라우팅
- 성능 모니터링 및 최적화 도구
배포
아키텍처 다이어그램
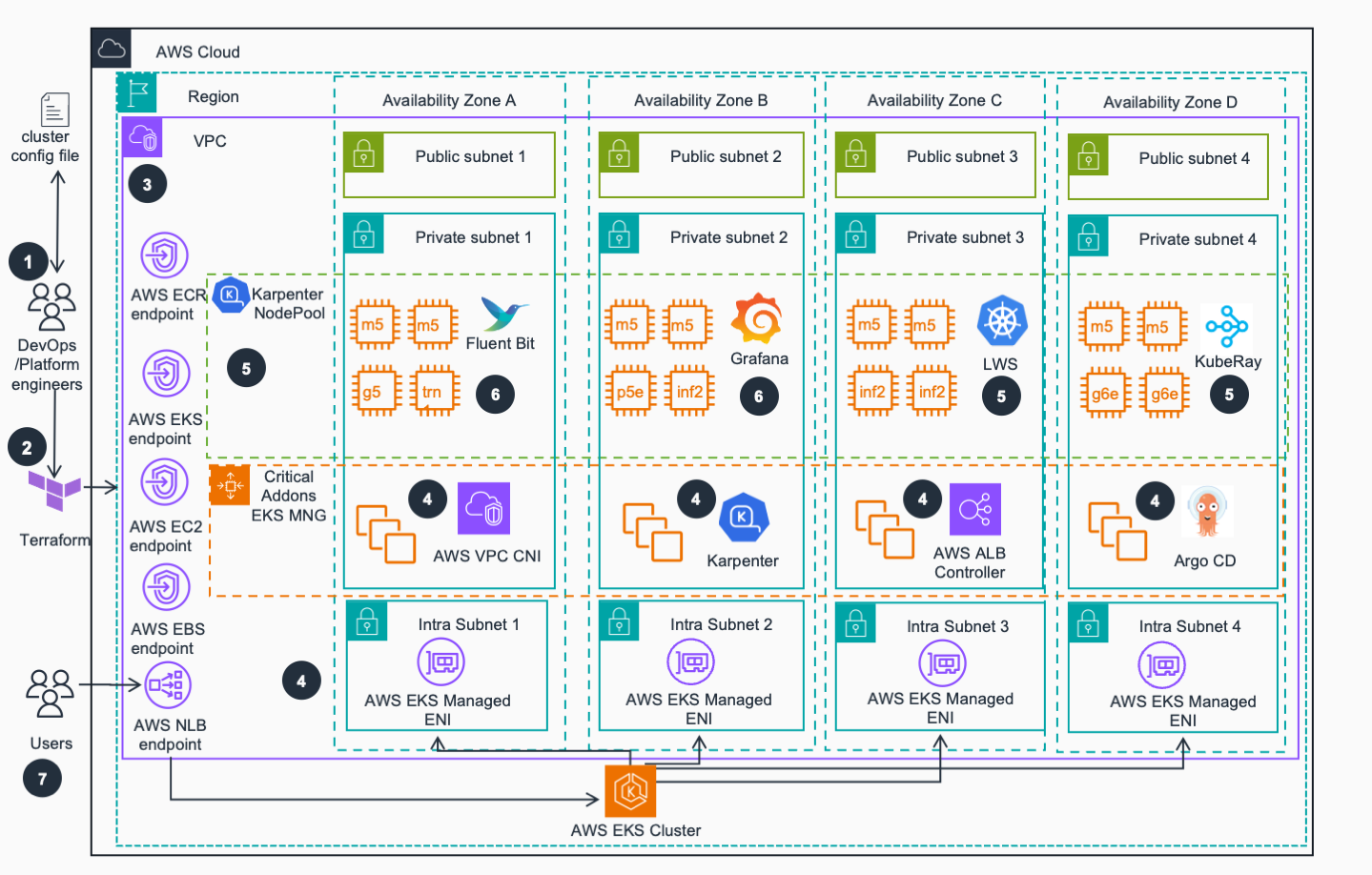
사전 요구 사항
- 적절한 권한으로 구성된 AWS CLI
- Terraform (>= 1.0)
- 클러스터 관리를 위한 kubectl
- 차트 배포를 위한 Helm (>= 3.0)
0단계: 복제 및 이동
git clone https://github.com/awslabs/ai-on-eks.git
cd infra/solutions/inference-ready-cluster
1단계: (선택 사항) 변수 구성
배포를 사용자 지정하려면 terraform/blueprint.tfvars 파일을 편집합니다:
name = "my-inference-cluster"
region = "us-west-2"
enable_kuberay_operator = true
enable_ai_ml_observability_stack = true
enable_aibrix_stack = true
enable_leader_worker_set = true
availability_zones_count = 4
모든 변수는 variables.tf 파일에서 찾을 수 있습니다
2단계: 인프라 배포
# �설치 스크립트 실행
./install.sh
설치 스크립트는 자동으로 다음을 수행합니다:
- 기본 Terraform 구성 복사
- Terraform 초기화
- 인프라 계획 및 적용
- kubectl 컨텍스트 구성
3단계: VPC
지정된 구성에 따라 Amazon Virtual Private Network(VPC)가 프로비저닝되고 구성됩니다. 안정성에 대한 모범 사례에 따라 노드 획득 및 고가용성의 최상의 기회를 제공하기 위해 4개의 가용 영역(AZ)이 구성됩니다. 토폴로지 인식은 기본적으로 성능/비용을 위해 AI/ML 워크로드를 동일한 AZ에 유지하지만 가용성을 위해 구성할 수 있습니다.
4단계: EKS
Amazon Elastic Kubernetes Service(EKS) 클러스터는 컴퓨팅 노드에서 중요한 클러스터 애드온(CoreDNS, AWS Load Balancer Controller 및 Karpenter)을 실행하는 Managed Nodes Group(MNG)으로 프로비저닝됩니다. Karpenter는 구성에 따라 가장 비용 효율적인 인스턴스를 우선시하면서 다른 EKS 애드온 및 사용자가 배포할 추론 애플리케이션에 대한 컴퓨팅 용량을 관리합니다.
5단계: EKS 애드온
환경별 Terraform 구성 파일에 정의된 구성에 따라 다른 중요한 EKS 애드온(LWS, KubeRay 등)이 배포됩니다(위의 1단계 참조)
6단계: 관측성
환경에서 메트릭과 로그를 수집하기 위해 FluentBit, Prometheus 및 Grafana를 포함한 관측성 스택이 배포됩니다. AI/ML 관련 워크로드를 모니터링하고 메트릭을 수집하기 위해 Service 및 Pod Monitor가 배포됩니다. Grafana 대시보드는 메트릭과 로그를 나란히 자동으로 시각화하도록 구성됩니다.
7단계: 클러스터 준비 완료
사용자는 EKS API에 액세스하고 AWS Network Load Balancer(NLB) 엔드포인트와 상호 작용하여 Kubernetes CLI를 사용하여 AI on EKS inference charts 또는 다른 리포지토리를 통해 컨테이너화된 AI/ML 추론 워크로드를 배포할 수 있습니다.
8단계: 배포 확인
모든 것이 제대로 배포되었는지 확인하려면 다음을 실행할 수 있습니다
kubectl get svc,pod,deployment -A
다음 출력이 표시되어야 합니다(섹션을 확장하여 출력 확인)
Details
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
aibrix-system service/aibrix-controller-manager-metrics-service ClusterIP 172.20.218.39 <none> 8080/TCP 13d
aibrix-system service/aibrix-gateway-plugins ClusterIP 172.20.142.245 <none> 50052/TCP 13d
aibrix-system service/aibrix-gpu-optimizer ClusterIP 172.20.14.220 <none> 8080/TCP 13d
aibrix-system service/aibrix-kuberay-operator ClusterIP 172.20.240.255 <none> 8080/TCP 13d
aibrix-system service/aibrix-metadata-service ClusterIP 172.20.252.24 <none> 8090/TCP 13d
aibrix-system service/aibrix-redis-master ClusterIP 172.20.155.43 <none> 6379/TCP 13d
argocd service/argocd-applicationset-controller ClusterIP 172.20.139.94 <none> 7000/TCP 13d
argocd service/argocd-dex-server ClusterIP 172.20.127.60 <none> 5556/TCP,5557/TCP 13d
argocd service/argocd-redis ClusterIP 172.20.48.202 <none> 6379/TCP 13d
argocd service/argocd-repo-server ClusterIP 172.20.232.147 <none> 8081/TCP 13d
argocd service/argocd-server ClusterIP 172.20.233.191 <none> 80/TCP,443/TCP 13d
default service/etcd-client ClusterIP 172.20.47.224 <none> 2379/TCP 12d
default service/etcd-server ClusterIP 172.20.69.95 <none> 2379/TCP,2380/TCP 12d
default service/kubernetes ClusterIP 172.20.0.1 <none> 443/TCP 13d
envoy-gateway-system service/envoy-aibrix-system-aibrix-eg-903790dc ClusterIP 172.20.249.100 <none> 80/TCP 13d
envoy-gateway-system service/envoy-gateway ClusterIP 172.20.113.229 <none> 18000/TCP,18001/TCP,18002/TCP,19001/TCP 13d
ingress-nginx service/ingress-nginx-controller LoadBalancer 172.20.27.209 k8s-ingressn-ingressn-ffa534dcb1-b4b54bcc24eaeddd.elb.us-west-2.amazonaws.com 80:31646/TCP,443:32024/TCP 13d
ingress-nginx service/ingress-nginx-controller-admission ClusterIP 172.20.249.118 <none> 443/TCP 13d
karpenter service/karpenter ClusterIP 172.20.149.70 <none> 8080/TCP 13d
kube-system service/aws-load-balancer-webhook-service ClusterIP 172.20.83.104 <none> 443/TCP 13d
kube-system service/eks-extension-metrics-api ClusterIP 172.20.87.142 <none> 443/TCP 13d
kube-system service/k8s-neuron-scheduler ClusterIP 172.20.248.128 <none> 12345/TCP 13d
kube-system service/kube-dns ClusterIP 172.20.0.10 <none> 53/UDP,53/TCP,9153/TCP 13d
kube-system service/kube-prometheus-stack-kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 13d
kuberay-operator service/kuberay-operator ClusterIP 172.20.117.159 <none> 8080/TCP 13d
lws-system service/lws-controller-manager-metrics-service ClusterIP 172.20.17.186 <none> 8443/TCP 13d
lws-system service/lws-webhook-service ClusterIP 172.20.173.201 <none> 443/TCP 13d
monitoring service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 13d
monitoring service/dcgm-exporter ClusterIP 172.20.79.5 <none> 9400/TCP 13d
monitoring service/fluent-bit ClusterIP 172.20.111.213 <none> 2020/TCP 13d
monitoring service/kube-prometheus-stack-alertmanager ClusterIP 172.20.45.163 <none> 9093/TCP,8080/TCP 13d
monitoring service/kube-prometheus-stack-coredns ClusterIP None <none> 9153/TCP 13d
monitoring service/kube-prometheus-stack-grafana ClusterIP 172.20.251.144 <none> 80/TCP 13d
monitoring service/kube-prometheus-stack-kube-controller-manager ClusterIP None <none> 10257/TCP 13d
monitoring service/kube-prometheus-stack-kube-etcd ClusterIP None <none> 2381/TCP 13d
monitoring service/kube-prometheus-stack-kube-proxy ClusterIP None <none> 10249/TCP 13d
monitoring service/kube-prometheus-stack-kube-scheduler ClusterIP None <none> 10259/TCP 13d
monitoring service/kube-prometheus-stack-kube-state-metrics ClusterIP 172.20.81.57 <none> 8080/TCP 13d
monitoring service/kube-prometheus-stack-operator ClusterIP 172.20.163.90 <none> 443/TCP 13d
monitoring service/kube-prometheus-stack-prometheus ClusterIP 172.20.1.251 <none> 9090/TCP,8080/TCP 13d
monitoring service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 172.20.88.160 <none> 9100/TCP 13d
monitoring service/my-cluster ClusterIP 172.20.54.44 <none> 9200/TCP,9300/TCP,9600/TCP,9650/TCP 13d
monitoring service/my-cluster-dashboards ClusterIP 172.20.161.35 <none> 5601/TCP 13d
monitoring service/my-cluster-masters ClusterIP None <none> 9200/TCP,9300/TCP 13d
monitoring service/opencost ClusterIP 172.20.162.78 <none> 9003/TCP,9090/TCP 13d
monitoring service/opensearch-discovery ClusterIP None <none> 9300/TCP 13d
monitoring service/opensearch-operator-controller-manager-metrics-service ClusterIP 172.20.183.236 <none> 8443/TCP 13d
monitoring service/prometheus-operated ClusterIP None <none> 9090/TCP 13d
NAMESPACE NAME READY STATUS RESTARTS AGE
aibrix-system pod/aibrix-controller-manager-5948f8f8b7-qjm7z 1/1 Running 0 13d
aibrix-system pod/aibrix-gateway-plugins-5978d98445-qj2jw 1/1 Running 0 13d
aibrix-system pod/aibrix-gpu-optimizer-64c978ddd8-bw7hk 1/1 Running 0 13d
aibrix-system pod/aibrix-kuberay-operator-8b65d7cc4-xrcm6 1/1 Running 0 13d
aibrix-system pod/aibrix-metadata-service-5499dc64b7-69tzc 1/1 Running 0 13d
aibrix-system pod/aibrix-redis-master-576767646c-w9lhl 1/1 Running 0 13d
...
EKS에서의 추론
EKS는 AI/ML 추론을 실행하기 위한 강력한 플랫폼입니다. EKS에서의 많은 추론 가능성에 대한 자세한 내용은 추론 섹션을 확인하세요.
Inference Charts 통합
이 인프라는 AI on EKS Inference Charts와 함께 작동하도록 특별히 설계되었습니다. 클러스터는 추론 워크로드의 원활한 배포를 위한 모든 필요한 구성 요소와 구성을 제공합니다.
Inference Charts 사전 요구 사항
인프라는 자동으로 다음을 제공합니다:
- KubeRay Operator - Ray-vLLM 배포에 필요
- GPU/Neuron Device Plugins - 하드웨어 리소스 관리용
- 관측성 스택 - 모니터링을 위한 Prometheus 및 Grafana
- AIBrix 통합 - 추론 최적화 및 관리용
지원되는 추론 패턴
클러스터는 inference charts에서 제공하는 모든 추론 패턴을 지원합니다:
vLLM 배포
- Kubernetes Deployment를 사용한 직접 vLLM 배포
- 단일 노드 추론 워크로드에 적합
- GPU 및 Neuron 가속기 모두 지원
Ray-vLLM 배포
- Ray Serve의 분산 vLLM
- 워크로드 수요에 따른 자동 확장
- Prometheus/Grafana 통합을 통한 고급 관측성
- 최적의 성능을 위한 토폴로지 인식 스케줄링
AIBrix 배포
- AIBrix 지원 LLM 배포
- 여러 복제본에 대한 효율적인 LLM 라우팅
- 혼합 GPU 및 Neuron 가속기 지원
예제 배포
클러스터가 준비되면 추론 워크로드를 배포할 수 있습니다:
# Hugging Face 토큰 시크릿 생성
kubectl create secret generic hf-token --from-literal=token=your_hf_token
# vLLM으로 GPU Qwen 3 1.7B 모델 배포
helm repo add ai-on-eks https://awslabs.github.io/ai-on-eks-charts/
helm repo update
helm install qwen3-1-7b ai-on-eks/inference-charts -f https://raw.githubusercontent.com/awslabs/ai-on-eks-charts/refs/heads/main/charts/inference-charts/values-qwen3-1.7b-vllm.yaml
사용 가능한 항목에 대한 자세한 내용은 inference charts 섹션을 확인하세요.
관측성 통합
인프라는 추론 워크로드를 위한 포괄적인 관측성을 제공합니다:
- Prometheus Metrics: 추론 메트릭의 자동 수집
- Grafana Dashboards: Ray 및 vLLM용 사전 구성된 대시보드
- Log Aggregation: Fluent Bit을 사용한 중앙 집중식 로깅
- GPU/Neuron 모니터링: 하드웨어 사용률 메트릭
Grafana 대시보드 액세스:
kubectl port-forward -n monitoring svc/kube-prometheus-stack-grafana 3000:80
관측성 기능 사용에 대한 자세한 내용은 관측성을 참조하세요.
비용 최적화
클러스터에는 여러 비용 최적화 기능이 포함되어 있습니다:
- Karpenter 오토스케일링: 자동 노드 프로비저닝 및 디프로비저닝
- 스팟 인스턴스 지원: 스팟 인스턴스�를 사용하도록 노드 그룹 구성
- 토폴로지 인식: AZ 전반에 걸쳐 효율적인 리소스 활용
- 리소스 제한: 워크로드에 대한 적절한 리소스 요청 및 제한
문제 해결
이 섹션에서는 추론 준비 EKS 클러스터를 배포하고 운영할 때 발생할 수 있는 일반적인 문제와 자세한 해결 방법 및 진단 단계를 다룹니다.
배포 문제
1. Terraform Apply 실패
증상:
terraform apply중 리소스 생성 오류로 Terraform 실패- 순차 배포 중 모듈별 실패
일반적인 원인 및 해결 방법:
AWS 권한 부족:
# AWS 자격 증명 및 권한 확인
aws sts get-caller-identity
aws iam get-user
# 필요한 권한 포함:
# - EKS 클러스터 생성 및 관리
# - EC2 인스턴스 관리
# - VPC 및 네트워킹 리소스
# - IAM 역할 생성 및 연결
# - KMS 키 관리
서비스 할당량 제한:
# EC2 서비스 할당량 확인
aws service-quotas get-service-quota --service-code ec2 --quota-code L-1216C47A # Running On-Demand instances
aws service-quotas get-service-quota --service-code ec2 --quota-code L-34B43A08 # Running On-Demand G instances
aws service-quotas get-service-quota --service-code ec2 --quota-code L-6E869C2A # Running On-Demand Inf instances
# 필요한 경우 할당량 증가 요청
aws service-quotas request-service-quota-increase --service-code ec2 --quota-code L-34B43A08 --desired-value 32
리전 가용성:
# 리전에서 인스턴스 유형이 사용 가능한지 확인
aws ec2 describe-instance-type-offerings --location-type availability-zone --filters Name=instance-type,Values=g5.xlarge,inf2.xlarge
2. EKS 클러스터 생성 문제
증상:
- EKS 클러스터 생성 실패 또는 "CREATING" 상태에서 멈춤
- 노드 그룹이 클러스터에 조인 실패
진단 단계:
# 클러스터 상태 확인
aws eks describe-cluster --name inference-cluster --region us-west-2
일반적인 해결 방법:
- VPC에 4개의 가용 영역에 걸쳐 충분한 IP 주소가 있는지 확인
- 퍼블릭 서브넷에서 NAT 게이트웨이 생성 확인
- 보안 그룹 구성이 필요한 EKS 통신을 허용하는지 확인
노드 및 파드 문제
3. Pending 상태에서 멈춘 파드
증상:
- 추론 워크로드가 "Pending" 상태로 유지
- Karpenter가 노드를 프로비저닝하지 않음
진단 명령:
# 파드 이벤트 및 리소스 요청 확인
kubectl describe pod <pod-name> -n <namespace>
# Karpenter 로그 확인
kubectl logs -n karpenter deployment/karpenter
# 사용 가능한 노드 및 용량 확인
kubectl get nodes -o wide
kubectl describe nodes
일반적인 ��원인 및 해결 방법:
GPU/Neuron 할당량 부족:
# Karpenter NodePool 구성 확인
kubectl get nodepool -o yaml
4. GPU 감지 및 Device Plugin 문제
증상:
- GPU 노드에 0개의 할당 가능한 GPU 표시
- NVIDIA device plugin이 실행되지 않음
진단 단계:
# 노드에서 GPU 가시성 확인
kubectl get nodes -o json | jq '.items[] | {name: .metadata.name, gpus: .status.allocatable["nvidia.com/gpu"]}'
# 노드 레이블 확인
kubectl get nodes --show-labels | grep gpu
해결 방법:
# 필요한 경우 NVIDIA device plugin 재시작
kubectl delete pods -n nvidia-device-plugin -l app.kubernetes.io/name=nvidia-device-plugin
5. AWS Neuron 설정 문제
증상:
- inf2/trn1 인스턴스에서 Neuron 장치가 감지되지 않음
- Neuron device plugin 실패
진단 명령:
# Neuron device plugin 확인
kubectl get pods -n kube-system | grep neuron
# Neuron 장치 확인
kubectl get nodes -o json | jq '.items[] | {name: .metadata.name, neuron: .status.allocatable["aws.amazon.com/neuron"]}'
# Neuron 스케줄러 확인
kubectl get pods -n kube-system | grep my-scheduler
해결 방법:
# Neuron 런타임 설치 확인
kubectl describe node <inf2-node> | grep neuron
# Neuron device plugin 로그 확인
kubectl logs -n kube-system <neuron-device-plugin-pod>
모델 배포 문제
6. 모델 다운로드 실패
증상:
- 이미지 풀 또는 모델 다운로드 오류로 파드 시작 실패
- Hugging Face 인증 실패
진단 단계:
# 다운로드 오류에 대한 파드 로그 확인
kubectl logs <pod-name> -n <namespace>
# Hugging Face 토큰 시크릿 확인
kubectl get secret hf-token -o yaml
kubectl get secret hf-token -o jsonpath='{.data.token}' | base64 -d
해결 방법:
# Hugging Face 토큰 시크릿 재생성
kubectl delete secret hf-token
kubectl create secret generic hf-token --from-literal=token=<your-hf-token>
# 파드에서 인터넷 연결 확인
kubectl run test-pod --image=curlimages/curl -it --rm -- curl -I https://huggingface.co
7. 메모리 부족(OOM) 문제
증상:
- OOMKilled 상태로 파드가 종료됨
- 모델이 완전히 로드되지 않음
진단 명령:
# 파드 리소스 사용량 확인
kubectl top pods -n <namespace>
# 노드 메모리 사용량 확인
kubectl top nodes
# OOM 종료에 대한 파드 이벤트 검토
kubectl get events --field-selector reason=OOMKilling
해결 방법:
# 더 큰 GPU를 얻기 위해 인스턴스 유형 증가
# 더 큰 인스턴스 유형 또는 모델 샤딩 사용 고려
네트워킹 및 로드 밸런서 문제
8. 서비스 연결 문제
증상:
- 추론 엔드포인트에 액세스할 수 없음
- 로드 밸런서가 프로비저닝되지 않음
진단 단계:
# 서비스 상태 확인
kubectl get svc -A
# AWS Load Balancer Controller 확인
kubectl logs -n kube-system deployment/aws-load-balancer-controller
# 보안 그룹 및 NACL 확인
aws ec2 describe-security-groups --filters "Name=group-name,Values=*inference-cluster*"
해결 방법:
# AWS Load Balancer Controller 재시작
kubectl rollout restart deployment/aws-load-balancer-controller -n kube-system
# 인그레스 주석 및 구성 확인
kubectl describe ingress <ingress-name>
모니터링 및 관측성 문제
9. Prometheus/Grafana 작동 안 함
증상:
- 모니터링 대시보드에 액세스할 수 없음
- 메트릭이 수집되지 않음
진단 명령:
# 모니터링 스택 파드 확인
kubectl get pods -n monitoring
# Prometheus 대상 확인
kubectl port-forward -n monitoring svc/kube-prometheus-stack-prometheus 9090:9090
# http://localhost:9090/targets로 이동
# Grafana 액세스 확인
kubectl port-forward -n monitoring svc/kube-prometheus-stack-grafana 3000:80
# http://localhost:3000으로 이동
해결 방법:
# 모니터링 구성 요소 재시작
kubectl rollout restart deployment/kube-prometheus-stack-grafana -n monitoring
# 서비스 모니터 확인
kubectl get servicemonitor -A
성능 및 확장 문제
10. 느린 모델 추론
증상:
- 모델 응답에서 높은 지연 시간
- 낮은 처리량 성능
진단 단계:
# 리소스 사용률 확인
kubectl top pods -n <namespace> --containers
# GPU 사용률 모니터링 (GPU를 사용하는 경우)
kubectl exec -it <pod-name> -- nvidia-smi
해결 방법:
- 모델이 적절한 하드웨어 가속을 사용하고 있는지 확인
- 여러 모델이 리소스를 놓고 경쟁하는지 확인
- 지연 시간에 맞게 모델 파라미터 최적화
- 모델을 확장하고 로드 밸런싱 사용
일반 디버깅 명령
# 클러스터 정보 가져오기
kubectl cluster-info
kubectl get nodes -o wide
# 모든 시스템 파드 확인
kubectl get pods -A | grep -v Running
# 최근 이벤트 보기
kubectl get events --sort-by='.lastTimestamp' -A
# Karpenter 프로비저닝 확인
kubectl logs -n karpenter deployment/karpenter --tail=100
# EKS 애드온 확인
aws eks describe-addon --cluster-name inference-cluster --addon-name vpc-cni
추가 도움 받기
문제가 계속되는 경우:
- AWS 서비스 상태 확인: AWS Service Health Dashboard 방문
- CloudWatch 로그 검토: CloudWatch에서 EKS 컨트롤 플레인 로그 확인
- 문서 참조: EKS 문제 해결 가이드 참조
- 커뮤니티 지원: AI on EKS GitHub Issues에 질문 게시