EKS 기반 EMR NVIDIA RAPIDS Accelerator for Apache Spark
NVIDIA RAPIDS Accelerator for Apache Spark는 NVIDIA CUDA의 기능을 기반으로 구축된 강력한 도구입니다. CUDA는 NVIDIA의 GPU 아키텍처에서 계산 프로세스를 향상시키기 위해 설계된 혁신적인 병렬 컴퓨팅 플랫폼입니다. NVIDIA에서 개발한 프로젝트인 RAPIDS는 CUDA를 기반으로 하는 오픈소스 라이브러리 모음으로 구성되어 GPU 가속 데이터 과학 워크플로우를 가능하게 합니다.
Spark 3용 RAPIDS Accelerator의 발명으로 NVIDIA는 Spark SQL 및 DataFrame 작업의 효율성을 크게 향상시켜 추출, 변환 및 로드 파이프라인을 성공적으로 혁신했습니다. RAPIDS cuDF 라이브러리의 기능과 Spark 분산 컴퓨팅 에코시스템의 광범위한 도달 범위를 결합하여 RAPIDS Accelerator for Apache Spark는 대규모 계산을 처리하기 위한 강력한 솔루션을 제공합니다. 또한 RAPIDS Accelerator 라이브러리는 UCX로 최적화된 고급 셔플을 통합하여 GPU 간 통신 및 RDMA 기능을 지원하도록 구성할 수 있어 성능을 더욱 향상시킵니다.
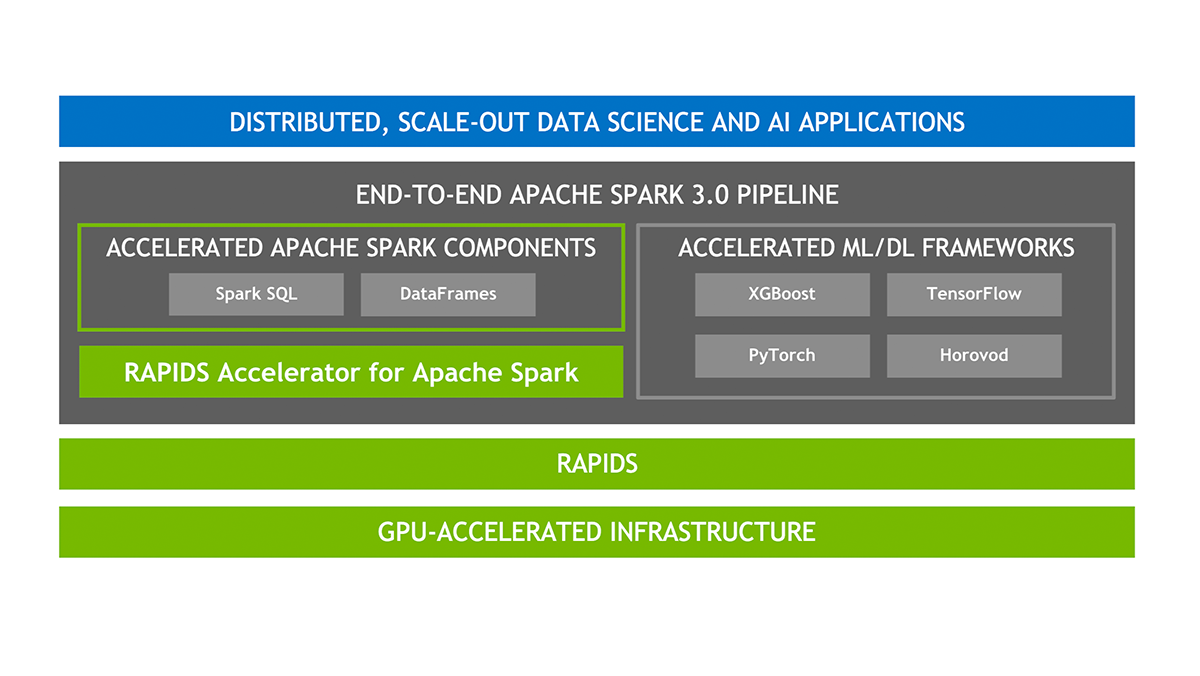
NVIDIA RAPIDS Accelerator for Apache Spark에 대한 EMR 지원
Amazon EMR과 NVIDIA RAPIDS Accelerator for Apache Spark의 통합 Amazon EMR on EKS는 이제 NVIDIA RAPIDS Accelerator for Apache Spark와 함께 GPU 인스턴스 유형 사용에 대한 지원을 확장합니다. 인공 지능(AI) 및 머신 러닝(ML)의 사용이 데이터 분석 영역에서 계속 확장됨에 따라 GPU가 제공할 수 있는 빠르고 비용 효율적인 데이터 처리에 대한 수요가 증가하고 있습니다. NVIDIA RAPIDS Accelerator for Apache Spark를 통해 사용자는 GPU의 우수한 성능을 활용하여 상당한 인프라 비용 절감을 달성할 수 있습니다.
기능
-
주요 기능 데이터 준비 작업에서 성능 향상을 경험하여 파이프라인의 후속 단계로 빠르게 전환할 수 있습니다. 이는 모델 훈련을 가속화할 뿐만 아니라 데이터 과학자와 엔지니어가 우선순위 작업에 집중할 수 있도록 합니다.
-
Spark 3은 데이터 수집에서 모델 훈련, 시각화에 이르기까지 엔드투엔드 파이프라인의 원활한 조정을 보장합니다. 동일한 GPU 가속 설정이 Spark와 머신 러닝 또는 딥러닝 프레임워크 모두에 사용할 수 있습니다. 이를 통해 별도의 클러스터가 필요 없으며 전체 파이프라인에 GPU 가속을 제공합니다.
-
Spark 3은 Catalyst 쿼리 옵티마이저에��서 컬럼 처리에 대한 지원을 확장합니다. RAPIDS Accelerator는 이 시스템에 연결하여 SQL 및 DataFrame 연산자의 속도를 높일 수 있습니다. 쿼리 계획이 실행되면 이러한 연산자는 향상된 성능을 위해 Spark 클러스터 내의 GPU를 활용할 수 있습니다.
-
NVIDIA는 Spark 작업 간의 데이터 교환을 최적화하도록 설계된 혁신적인 Spark 셔플 구현을 도입했습니다. 이 셔플 시스템은 UCX, RDMA 및 NCCL을 포함한 GPU 강화 통신 라이브러리를 기반으로 구축되어 데이터 전송 속도와 전반적인 성능을 크게 향상시킵니다.
솔루션 배포
👈XGBoost Spark 작업 시작
훈련 데이터셋
Fannie Mae's Single-Family Loan Performance Data는 2013년부터 시작하는 종합적인 데이터셋을 보유하고 있습니다. 이 데이터셋은 Fannie Mae의 단일 가족 사업 장부 일부의 신용 성과에 대한 귀중한 인사이트를 제공합니다. 이 데이터셋은 투자자가 Fannie Mae가 소유하거나 보증하는 단일 가족 대출의 신용 성과를 더 잘 이해할 수 있도록 설계되었습니다.
1단계: 사용자 지정 Docker 이미지 빌드
us-west-2에 위치한 EMR on EKS ECR 리포지토리에서 Spark Rapids 기본 이미지를 가져오려면 로그인합니다:
aws ecr get-login-password --region us-west-2 | docker login --username AWS --password-stdin 895885662937.dkr.ecr.us-west-2.amazonaws.com
다른 리전에 있는 경우 이 가이드를 참조하세요.
- 로컬에서 Docker 이미지를 빌드하려면 다음 명령을 사용합니다:
제공된 Dockerfile을 사용하여 사용자 지정 Docker 이미지를 빌드합니다. 0.10과 같은 이미지 태그를 선택합니다.
빌드 프로세스는 네트워크 속도에 따라 시간이 걸릴 수 있습니다. 결과 이미지 크기는 약 23.5GB입니다.
cd infra/emr-spark-rapids/examples/xgboost
docker build -t emr-6.10.0-spark-rapids-custom:0.10 -f Dockerfile .
<ACCOUNTID>를 AWS 계정 ID로 바꿉니다. 다음 명령으로 ECR 리포지토리에 로그인합니다:
aws ecr get-login-password --region us-west-2 | docker login --username AWS --password-stdin <ACCOUNTID>.dkr.ecr.us-west-2.amazonaws.com
- Docker 이미지를 ECR에 푸시하려면 다음을 사용합니다:
$ docker tag emr-6.10.0-spark-rapids-custom:0.10 <ACCOUNT_ID>.dkr.ecr.us-west-2.amazonaws.com/emr-6.10.0-spark-rapids-custom:0.10
$ docker push <ACCOUNT_ID>.dkr.ecr.us-west-2.amazonaws.com/emr-6.10.0-spark-rapids-custom:0.10
3단계에서 작업 실행 중에 이 이미지를 사용할 수 있습니다.
2단계: 입력 데이터 획득(Fannie Mae's Single-Family Loan Performance Data)
이 데이터셋은 Fannie Mae's Single-Family Loan Performance Data에서 가져옵니다. 모든 권리는 Fannie Mae에 있습니다.
- Fannie Mae 웹사이트로 이동합니다
- Single-Family Loan Performance Data를 클릭합니다
- 웹사이트를 처음 사용하는 경우 새 사용자로 등록합니다
- 자격 증명을 사용하여 로그인합니다
- HP를 선택합니다
Download Data를 �클릭하고Single-Family Loan Performance Data를 선택합니다- 연도 및 분기별로 정렬된
Acquisition and Performance파일의 표 형식 목록이 표시됩니다. 파일을 클릭하여 다운로드합니다. 예제 작업에서 사용할 3년 분량의 데이터(2020, 2021, 2022 - 각 연도에 4개의 파일, 각 분기에 하나씩)를 다운로드할 수 있습니다. 예: 2017Q1.zip - 다운로드한 파일의 압축을 풀어 로컬 머신에 csv 파일을 추출합니다. 예: 2017Q1.csv
- CSV 파일만
${S3_BUCKET}/${EMR_VIRTUAL_CLUSTER_ID}/spark-rapids-emr/input/fannie-mae-single-family-loan-performance/아래의 S3 버킷에 복사합니다. 아래 예제는 3년 분량의 데이터(각 분기에 하나의 파일, 총 12개 파일)를 사용합니다. 참고:${S3_BUCKET}및${EMR_VIRTUAL_CLUSTER_ID}값은 Terraform 출력에서 추출할 수 있습니다.
aws s3 ls s3://emr-spark-rapids-<aws-account-id>-us-west-2/949wt7zuphox1beiv0i30v65i/spark-rapids-emr/input/fannie-mae-single-family-loan-performance/
2023-06-24 21:38:25 2301641519 2000Q1.csv
2023-06-24 21:38:25 9739847213 2020Q2.csv
2023-06-24 21:38:25 10985541111 2020Q3.csv
2023-06-24 21:38:25 11372073671 2020Q4.csv
2023-06-23 16:38:36 9603950656 2021Q1.csv
2023-06-23 16:38:36 7955614945 2021Q2.csv
2023-06-23 16:38:36 5365827884 2021Q3.csv
2023-06-23 16:38:36 4390166275 2021Q4.csv
2023-06-22 19:20:08 2723499898 2022Q1.csv
2023-06-22 19:20:08 1426204690 2022Q2.csv
2023-06-22 19:20:08 595639825 2022Q3.csv
2023-06-22 19:20:08 180159771 2022Q4.csv
3단계: EMR Spark XGBoost 작업 실행
여기서는 작업을 실행하기 위해 도우미 셸 스크립트를 활용합니다. 이 스크립트는 사용자 입력이 필요합니다.
이 스크립트는 Terraform 출력에서 얻을 수 있는 특정 입력을 요청합니다. 아래 예시를 참조하세요.
cd infra/emr-spark-rapids/examples/xgboost
chmod +x execute_spark_rapids_xgboost.sh
./execute_spark_rapids_xgboost.sh
# 아래에 표시된 예시 입력
Did you copy the fannie-mae-single-family-loan-performance data to S3 bucket(y/n): y
Enter the customized Docker image URI: public.ecr.aws/o7d8v7g9/emr-6.10.0-spark-rapids:0.11
Enter EMR Virtual Cluster AWS Region: us-west-2
Enter the EMR Virtual Cluster ID: 949wt7zuphox1beiv0i30v65i
Enter the EMR Execution Role ARN: arn:aws:iam::<ACCOUNTID>:role/emr-spark-rapids-emr-eks-data-team-a
Enter the CloudWatch Log Group name: /emr-on-eks-logs/emr-spark-rapids/emr-ml-team-a
Enter the S3 Bucket for storing PySpark Scripts, Pod Templates, Input data and Output data.<bucket-name>: emr-spark-rapids-<ACCOUNTID>-us-west-2
Enter the number of executor instances (4 to 8): 8
파드 상태 확인
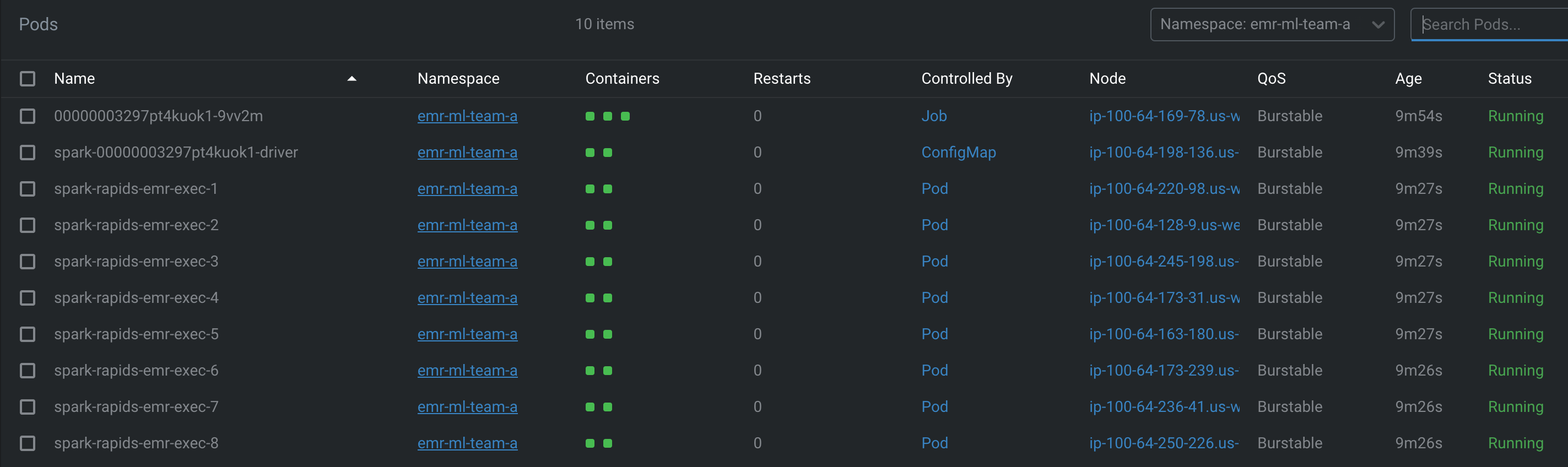
첫 번째 실행은 EMR Job Pod, Driver 및 Executor 파드용 이미지를 다운로드해야 하므로 더 오래 걸릴 수 있습니다. 각 파드는 Docker 이미지를 다운로드하는 데 최대 8분이 걸릴 수 있습니다. 이미지 캐싱 덕분에 후속 실행은 더 빠릅니다(보통 30초 미만).
4단계: 작업 결과 확인
- CloudWatch 로그 또는 S3 버킷에서 Spark 드라이버 파드 로그를 확인하려면 로그인합니다.
로그 파일의 샘플 출력은 다음과 같습니다:
/emr-on-eks-logs/emr-spark-rapids/emr-ml-team-a
spark-rapids-emr/949wt7zuphox1beiv0i30v65i/jobs/0000000327fe50tosa4/containers/spark-0000000327fe50tosa4/spark-0000000327fe50tosa4-driver/stdout
위 로그 파일의 샘플 출력은 다음과 같습니다:
Raw Dataframe CSV Rows count : 215386024 Raw Dataframe Parquet Rows count : 215386024 ETL takes 222.34674382209778
Training takes 95.90932035446167 seconds If features_cols param set, then features_col param is ignored.
Transformation takes 63.999391317367554 seconds +--------------+--------------------+--------------------+----------+ |delinquency_12| rawPrediction| probability|prediction| +--------------+--------------------+--------------------+----------+ | 0|[10.4500541687011...|[0.99997103214263...| 0.0| | 0|[10.3076572418212...|[0.99996662139892...| 0.0| | 0|[9.81707763671875...|[0.99994546175003...| 0.0| | 0|[9.10498714447021...|[0.99988889694213...| 0.0| | 0|[8.81903457641601...|[0.99985212087631...| 0.0| +--------------+--------------------+--------------------+----------+ only showing top 5 rows
Evaluation takes 3.8372223377227783 seconds Accuracy is 0.996563056111921
Fannie Mae Single Loan Performance Dataset용 ML 파이프라인
1단계: 누락된 값, 범주형 변수 및 기타 데이터 불일치를 처리하기 위해 데이터셋을 전처리하고 정리합니다. 여기에는 데이터 보간, 원-핫 인코딩 및 데이터 정규화와 같은 기술이 포함될 수 있습니다.
2단계: 대출 성과를 예측하는 데 더 유용한 정보를 제공할 수 있는 기존 기능에서 추가 기능을 생성합니다. 예를 들어 대출 대비 가치 비율, 차용인의 신용 점수 범위 또는 대출 시작 연도와 같은 기능을 추출할 수 있습니다.
3단계: 데이터셋을 두 부분으로 나눕니다: 하나는 XGBoost 모델 훈련용이고 다른 하나는 성능 평가용입니다. 이를 통해 모델이 보이지 않는 데이터에 얼마나 잘 일반화되는지 평가할 수 있습니다.
4단계: 훈련 데이터셋을 XGBoost에 공급하여 모델을 훈련합니다. XGBoost는 대출 속성과 해당 대출 성과 레이블을 분석하여 그들 사이의 패턴과 관계를 학습합니다. 목표는 주어진 기능을 기반으로 대출이 채무 불이행이 될 가능성이 있는지 또는 잘 수행될 가능성이 있는지 예측하는 것입니다.
5단계: 모델이 훈련되면 평가 데이터셋을 사용하여 성능을 평가합니다. 여기에는 모델이 대출 성과를 얼마나 잘 예측하는지 측정하기 위해 정확도, 정밀도, 재현율 또는 수신기 작동 특성 곡선 아래 면적(AUC-ROC)과 같은 메트릭을 분석하는 것이 포함됩니다.
6단계: 성능이 만족스럽지 않으면 모델의 정확도를 개선하거나 과적합과 같은 문제를 해결하기 위해 학습률, 트리 깊이 또는 정규화 파라미터와 같은 XGBoost 하이퍼파라미터를 조정할 수 있습니다.
7단계: 마지막으로 훈련되고 검증된 XGBoost 모델을 사용하여 새롭고 보이지 않는 대출 데이터에 대한 예측을 수행할 수 있습니다. 이러한 예측은 대출 채무 불이행과 관련된 잠재적 위험을 식별하거나 대출 성과를 평가하는 데 도움이 될 수 있습니다.
DCGM Exporter, Prometheus 및 Grafana를 사용한 GPU 모니터링
관측성은 GPU와 같은 하드웨어 리소스를 관리하고 최적화하는 데 중요한 역할을 합니다. 특히 GPU 사용률이 높은 머신 러닝 워크로드에서 그렇습니다. 실시간으로 GPU 사용량을 모니터링하고, 추세를 식별하고, 이상을 감지하는 기능은 성능 튜닝, 문제 해결 및 효율적인 리소스 활용에 큰 영향을 미칠 수 있습니다.
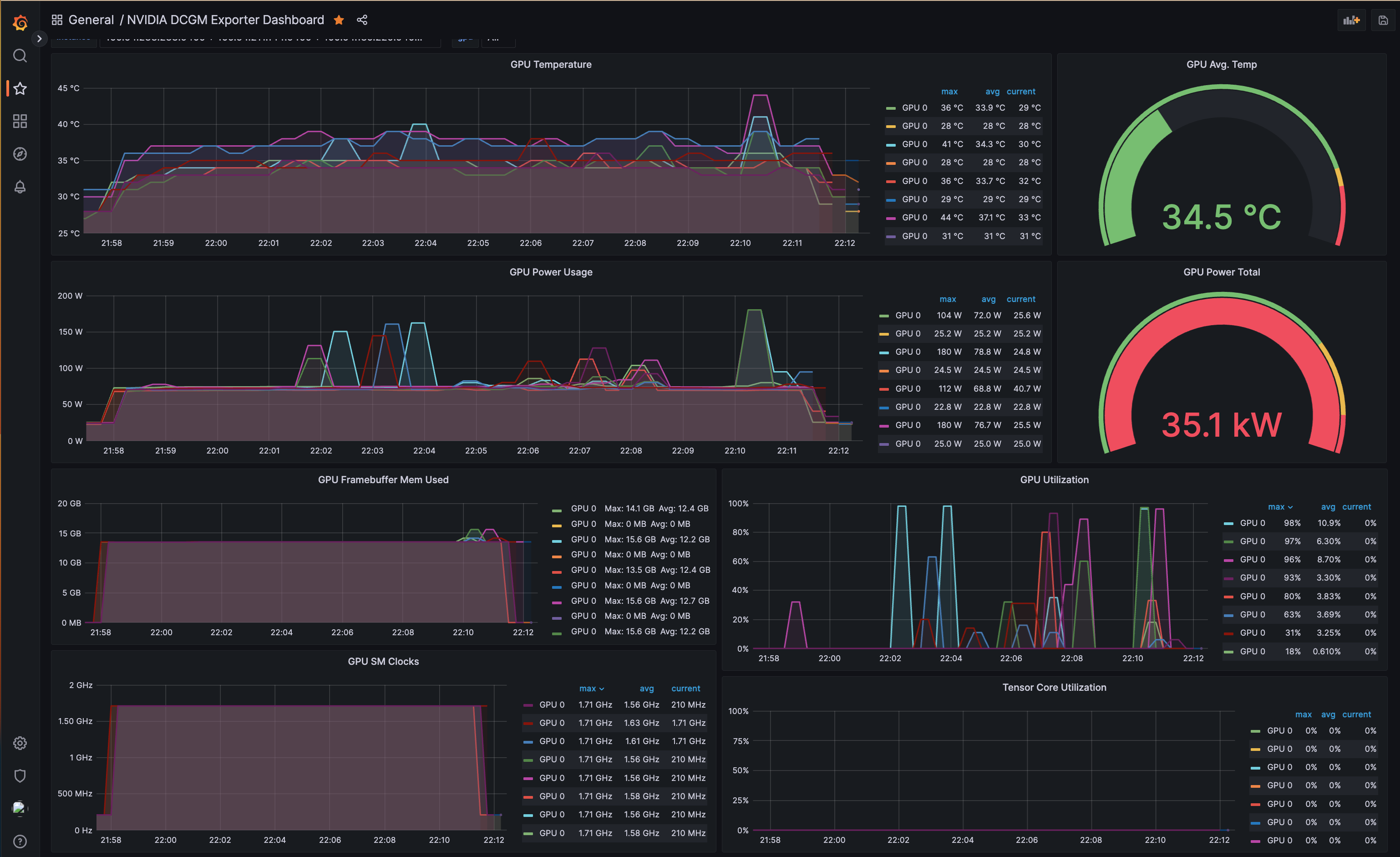
NVIDIA GPU Operator는 GPU 관측성에서 핵심 역할을 합니다. Kubernetes에서 GPU 워크로드를 실행하는 데 필요한 구성 요소의 배포를 자동화합니다. 그 구성 요소 중 하나인 DCGM(Data Center GPU Manager) Exporter는 선도적인 오픈소스 모니터링 솔루션인 Prometheus가 수집할 수 있는 형식으로 GPU 메트릭을 내보내는 오픈소스 프로젝트입니다. 이러한 메트릭에는 GPU 온도, 메모리 사용량, GPU 사용률 등이 포함됩니다. DCGM Exporter를 사용하면 GPU별로 이러한 메트릭을 모니터링하여 GPU 리소스에 대한 세분화된 가시성을 제공할 수 있습니다.
NVIDIA GPU Operator는 DCGM Exporter와 함께 GPU 메트릭을 Prometheus 서버로 내보냅니다. 유연한 쿼리 언어를 통해 Prometheus를 사용하면 데이터를 분할하여 리소스 사용 패턴에 대한 인사이트를 생성할 수 있습니다.
그러나 Prometheus는 장기 데이터 저장용으로 설계되지 않았습니다. 여기에서 Amazon Managed Service for Prometheus(AMP)가 등장합니다. 기본 인프라를 관리할 필요 없이 대규모로 운영 데이터를 쉽게 분석할 수 있게 해주는 완전 관리형, 안전하고 확장 가능한 Prometheus 서비스를 제공합니다.
이러한 메트릭을 시각화하고 유용한 대시보드를 만드는 것은 Grafana가 뛰어난 부분입니다. Grafana는 모니터링 및 관측성을 위한 오픈소스 플랫폼으로 수집된 메트릭을 직관적으로 표현하기 위한 풍부한 시각화를 제공합니다. Prometheus와 결합하면 Grafana는 DCGM Exporter가 수집한 GPU 메트릭을 사용자 친화적인 방식으로 표시할 수 있습니다.
NVIDIA GPU Operator는 메트릭을 Prometheus 서버로 내보내도록 구성되어 있으며, Prometheus 서버는 이러한 메트릭을 Amazon Managed Prometheus(AMP)에 원격 쓰기합니다. 사용자는 블루프린트의 일부로 배포된 Grafana WebUI에 로그인하고 AMP를 데이터 소스로 추가할 수 있습니다. 그런 다음 실시간 성능 모니터링 및 리소스 최적화를 용이하게 하는 쉽게 소화할 수 있는 형식으로 GPU 메트릭을 제공하는 오픈소스 GPU 모니터링 대시보드를 가져올 수 있습니다.
- NVIDIA GPU Operator: Kubernetes 클러스터에 설치된 NVIDIA GPU Operator는 GPU 리소스의 수명 주기를 관리합니다. 각 GPU 장착 노드에 NVIDIA 드라이버와 DCGM Exporter를 배포합니다.
- DCGM Exporter: DCGM Exporter는 각 노드에서 실행되어 GPU 메트릭을 수집하고 Prometheus에 노출합니다.
- Prometheus: Prometheus는 DCGM Exporter를 포함한 다양한 소스에서 메트릭을 수집하는 시계열 데이터베이스입니다. 정기적으로 익스포터에서 메트릭을 가져와 저장합니다. 이 설정에서는 수집된 메트릭을 AMP에 원격 쓰기하도록 Prometheus를 구성합니다.
- Amazon Managed Service for Prometheus(AMP): AMP는 AWS에서 제공하는 완전 관리형 Prometheus 서비스입니다. Prometheus 데이터의 장기 저장, 확장성 및 보안을 처리합니다.
- Grafana: Grafana는 수집된 메트릭에 대해 AMP를 쿼리하고 유용한 대시보드에 표시할 수 있는 시각화 도구입니다.
이 블루프린트에서는 DCGM을 활용하여 GPU 메트릭을 Prometheus와 Amazon Managed Prometheus(AMP) 모두에 씁니다. GPU 메트릭을 확인하려면 다음 명령을 실행하여 Grafana를 사용할 수 있습니다:
kubectl port-forward svc/grafana 3000:80 -n grafana
사용자 이름으로 admin을 사용하여 Grafana에 로그인하고 다음 AWS CLI 명령을 사용하여 Secrets Manager에서 비밀번호를 검색합니다:
aws secretsmanager get-secret-value --secret-id emr-spark-rapids-grafana --region us-west-2
로그인한 후 AMP 데이터 소스를 Grafana에 추가하고 오픈소스 GPU 모니터링 대시보드를 가져옵니다. 그런 다음 아래 스크린샷과 같이 Grafana 대시보드를 사용하여 메트릭을 탐색하고 시각화할 수 있습니다.
정리
👈AWS 계정에 원치 않는 요금이 청구되지 않도록 이 배포 중에 생성된 모든 AWS 리소스를 삭제하세요