EKS에서 ML 모델을 배포하려면 GPU 또는 Neuron 인스턴스에 대한 액세스가 필요합니다. 배포가 작동하지 않는 경우 이러한 리소스에 대한 액세스가 누락되어 있는 경우가 많습니다. 또한 일부 배포 패턴은 Karpenter 자동 확장 및 정적 노드 그룹에 의존합니다. 노드가 초기화되지 않는 경우 Karpenter 또는 노드 그룹의 로그를 확인하여 문제를 해결하세요.
EKS 기반 JupyterHub
JupyterHub는 사용자가 Jupyter 노트북 및 기타 Jupyter 호환 환경에 액세스하고 상호 작용할 수 있게 해주는 강력한 다중 사용자 서버입니다. 여러 사용자가 동시에 노트북에 액세스하고 활용할 수 있는 협업 플랫폼을 제공하여 사용자 간의 협업과 공유를 촉진합니다. JupyterHub를 통해 사용자는 자신만의 격리된 컴퓨팅 환경("스포너"라고 함)을 만들고 해당 환경 내에서 Jupyter 노트북 또는 기타 대화형 컴퓨팅 환경을 시작할 수 있습니다. 이를 통해 각 사용자에게 파일, 코드 및 컴퓨팅 리소스를 포함한 자체 작업 공간이 제공됩니다.
EKS 기반 JupyterHub
Amazon Elastic Kubernetes Service(EKS)에 JupyterHub를 배포하면 JupyterHub의 다양성과 Kubernetes의 확장성 및 유연성이 결합됩니다. 이 블루프린트를 통해 사용자는 JupyterHub 프로필의 도움으로 EKS에서 다중 테넌트 JupyterHub 플랫폼을 구축할 수 있습니다. 각 사용자를 위한 EFS 공유 파일 시스템을 활용하여 노트북 공유를 쉽게 하고 개별 EFS 스토리지를 제공하여 사용자 파드가 삭제되거나 만료되더라도 데이터를 안전하게 저장할 수 있습니다. 사용자가 로그인하면 기존 EFS 볼륨 아래의 모든 스크립트와 데이터에 액세스할 수 있습니다.
EKS의 기능을 활용하면 사용자의 요구에 맞게 JupyterHub 환경을 원활하게 확장하여 효율적인 리소스 활용과 최적의 성능을 보장할 수 있습니다. EKS를 사용하면 자동 확장, 고가용성, 업데이트 및 업그레이드의 쉬운 배포와 같은 Kubernetes 기능을 활용할 수 있습니다. 이를 통해 사용자에게 신뢰할 수 있고 강력한 JupyterHub 경험을 제공하여 효과적으로 협업, 탐색 및 데이터 분석을 수행할 수 있도록 지원합니다.
EKS에서 JupyterHub를 시작하려면 이 가이드의 지침에 따라 JupyterHub 환경을 설정하고 구성하세요.
솔루션 배포
👈리소스 확인
👈유형 1 배포: JupyterHub 로그인
포트 포워드로 JupyterHub 노출:
웹 사용자 인터페이스를 로컬에서 보기 위해 JupyterHub 서비스에 액세스할 수 있도록 아래 명령을 실행합니다. 현재 dummy 배포는 ClusterIP가 있는 Web UI 서비스만 설정한다는 점에 유의하세요. 이를 내부 또는 인터넷 연결 로드 밸런서로 사용자 지정하려면 JupyterHub Helm 차트 값 파일에서 필요한 조정을 할 수 있습니다.
kubectl port-forward svc/proxy-public 8080:80 -n jupyterhub
로그인: 웹 브라우저에서 http://localhost:8080/로 이동합니다. 사용자 이름으로 user-1을 입�력하고 아무 비밀번호나 선택합니다.
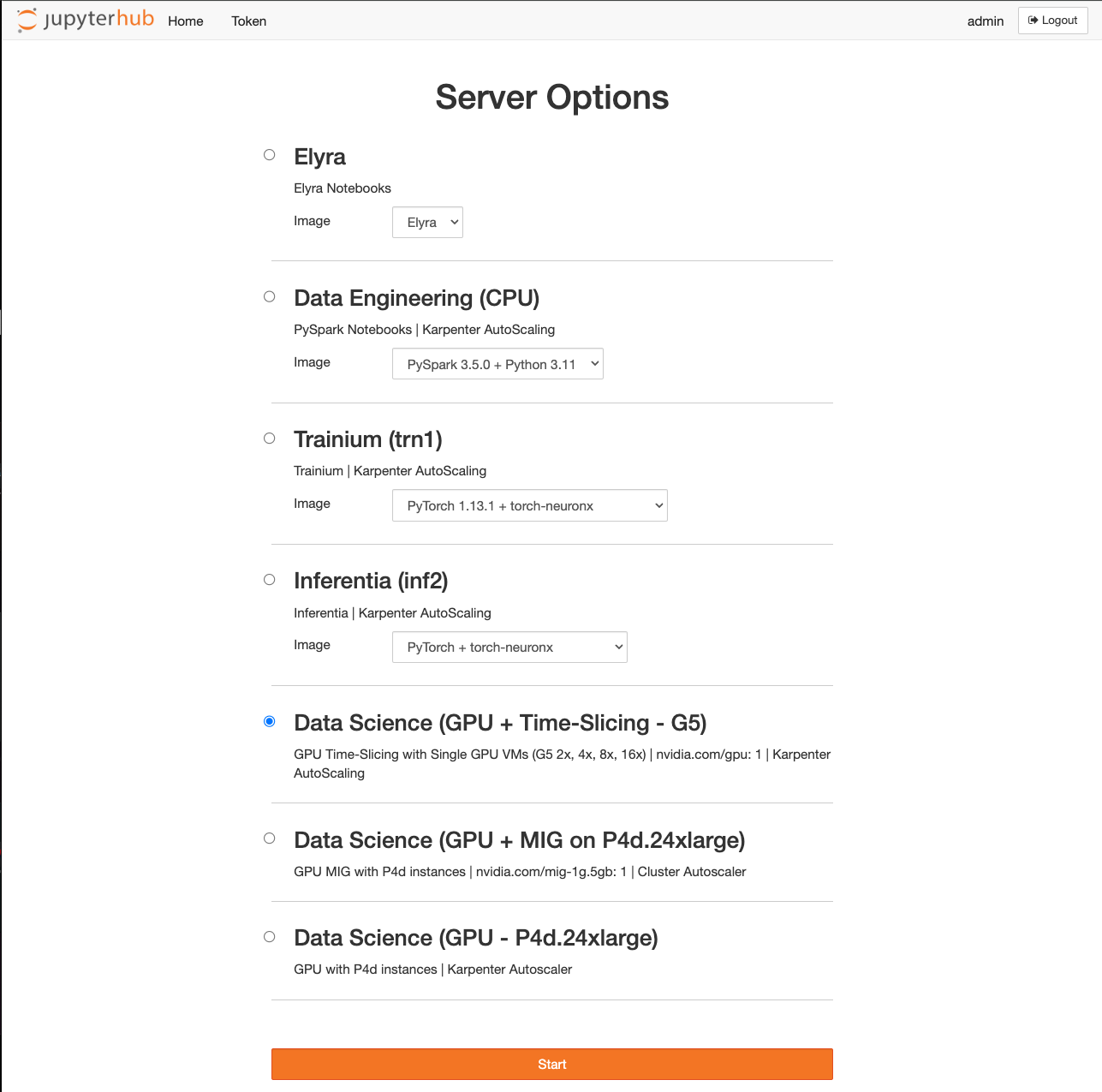
서버 옵션 선택: 로그인하면 선택할 수 있는 다양한 노트북 인스턴스 프로필이 표시됩니다. Data Engineering (CPU) 서버는 전통적인 CPU 기반 노트북 작업용입니다. Elyra 서버는 파이프라인을 빠르게 개발할 수 있는 Elyra 기능을 제공합니다:  .
. Trainium 및 Inferentia 서버는 노트북 서버를 Trainium 및 Inferentia 노드에 배포하여 가속화된 워크로드를 허용합니다. Time Slicing 및 MIG는 GPU 공유를 위한 두 가지 다른 전략입니다. 마지막으로 Data Science (GPU) 서버는 NVIDIA GPU에서 실행되는 전통적인 서버입니다.
이 타임슬라이싱 기능 시연을 위해 Data Science (GPU + Time-Slicing – G5) 프로필을 사용합니다. 이 옵션을 선택하고 Start 버튼을 선택하세요.
g5.2xlarge 인스턴스 유형으로 Karpenter가 생성한 새 노드는 NVIDIA device plugin에서 제공하는 타임슬라이싱 기능을 활용하도록 구성되었습니다. 이 기능을 사용하면 단일 GPU를 여러 할당 가능한 단위로 분할하여 효율적인 GPU 활용�이 가능합니다. 이 경우 NVIDIA device plugin Helm 차트 구성 맵에서 4개의 할당 가능한 GPU를 정의했습니다. 아래는 노드 상태입니다:
GPU: 노드는 NVIDIA device plugin의 타임슬라이싱 기능을 통해 4개의 GPU로 구성됩니다. 이를 통해 노드가 다양한 워크로드에 GPU 리소스를 더 유연하게 할당할 수 있습니다.
status:
capacity:
cpu: '8' # 노드에 8개의 CPU가 있습니다
ephemeral-storage: 439107072Ki # 노드의 총 임시 스토리지 용량은 439107072 KiB입니다
hugepages-1Gi: '0' # 노드에 0개의 1Gi hugepage가 있습니다
hugepages-2Mi: '0' # 노드에 0개의 2Mi hugepage가 있습니다
memory: 32499160Ki # 노드의 총 메모리 용량은 32499160 KiB입니다
nvidia.com/gpu: '4' # 노드에 타임슬라이싱을 통해 구성된 총 4개의 GPU가 있습니다
pods: '58' # 노드는 최대 58개의 파드를 수용할 수 있습니다
allocatable:
cpu: 7910m # 7910 밀리코어의 CPU가 할당 가능합니다
ephemeral-storage: '403607335062' # 403607335062 KiB의 임시 스토리지가 할당 가능합니다
hugepages-1Gi: '0' # 0개의 1Gi hugepage가 할당 가능합니다
hugepages-2Mi: '0' # 0개의 2Mi hugepage가 할당 가능합니다
memory: 31482328Ki # 31482328 KiB의 메모리가 할당 가능합니다
nvidia.com/gpu: '4' # 4개의 GPU가 할당 가능합니다
pods: '58' # 58개의 파드가 할당 가능합니다
두 번째 사용자(user-2) 환경 설정:
GPU 타임슬라이싱이 작동하는 것을 시연하기 위해 다른 Jupyter Notebook 인스턴스를 프로비저닝합니다. 이번에는 두 번째 사용자의 파드가 이전에 설정한 GPU 타임슬라이싱 구성을 활용하여 첫 번째 사용자와 동일한 노드에 예약되었는지 확인합니다. 이를 달성하려면 아래 단계를 따르세요:
시크릿 브라우저 창에서 JupyterHub 열기: 새 시크릿 창의 웹 브라우저에서 http://localhost:8080/로 이동합니다. 사용자 이름으로 user-2를 입력하고 아무 비밀번호나 선택합니다.
서버 옵션 선택: 로그인 후 서버 옵션 페이지가 표시됩니다. Data Science (GPU + Time-Slicing – G5) 라디오 버튼을 선택하고 Start를 선택합니다.
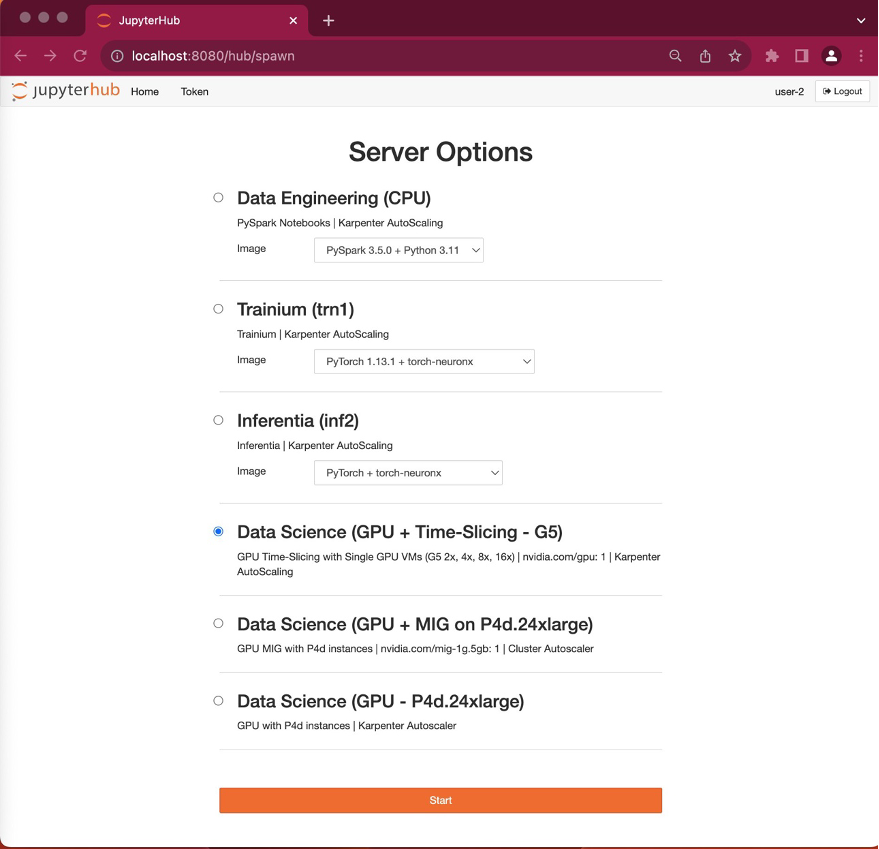
파드 배치 확인: 이 파드 배치는 user-1과 달리 몇 초밖에 걸리지 않습니다. Kubernetes 스케줄러가 user-1 파��드에서 생성한 기존 g5.2xlarge 노드에 파드를 배치할 수 있기 때문입니다. user-2도 동일한 도커 이미지를 사용하므로 도커 이미지를 가져오는 데 지연이 없고 로컬 캐시를 활용했습니다.
터미널을 열고 다음 명령을 실행하여 새 Jupyter Notebook 파드가 어디에 예약되었는지 확인합니다:
kubectl get pods -n jupyterhub -owide | grep -i user
user-1과 user-2 파드가 모두 동일한 노드에서 실행되고 있는지 확인합니다. 이는 GPU 타임슬라이싱 구성이 예상대로 작동하고 있음을 확인합니다.
유형 2 배포(선택 사항): Amazon Cognito를 통해 JupyterHub 로그인
로드 밸런서 DNS 이름으로 JupyterHub 도메인에 대한 CNAME DNS 레코드를 ChangeIP에 추가합니다.

ChangeIP의 CNAME 값 필드에 로드 밸런서 DNS 이름을 추가할 때 로드 밸런서 DNS 이름 끝에 점(.)을 추가해야 합니다.
이제 브라우저에서 도메인 URL을 입력하면 JupyterHub 로그인 페이지로 리디렉션됩니다.
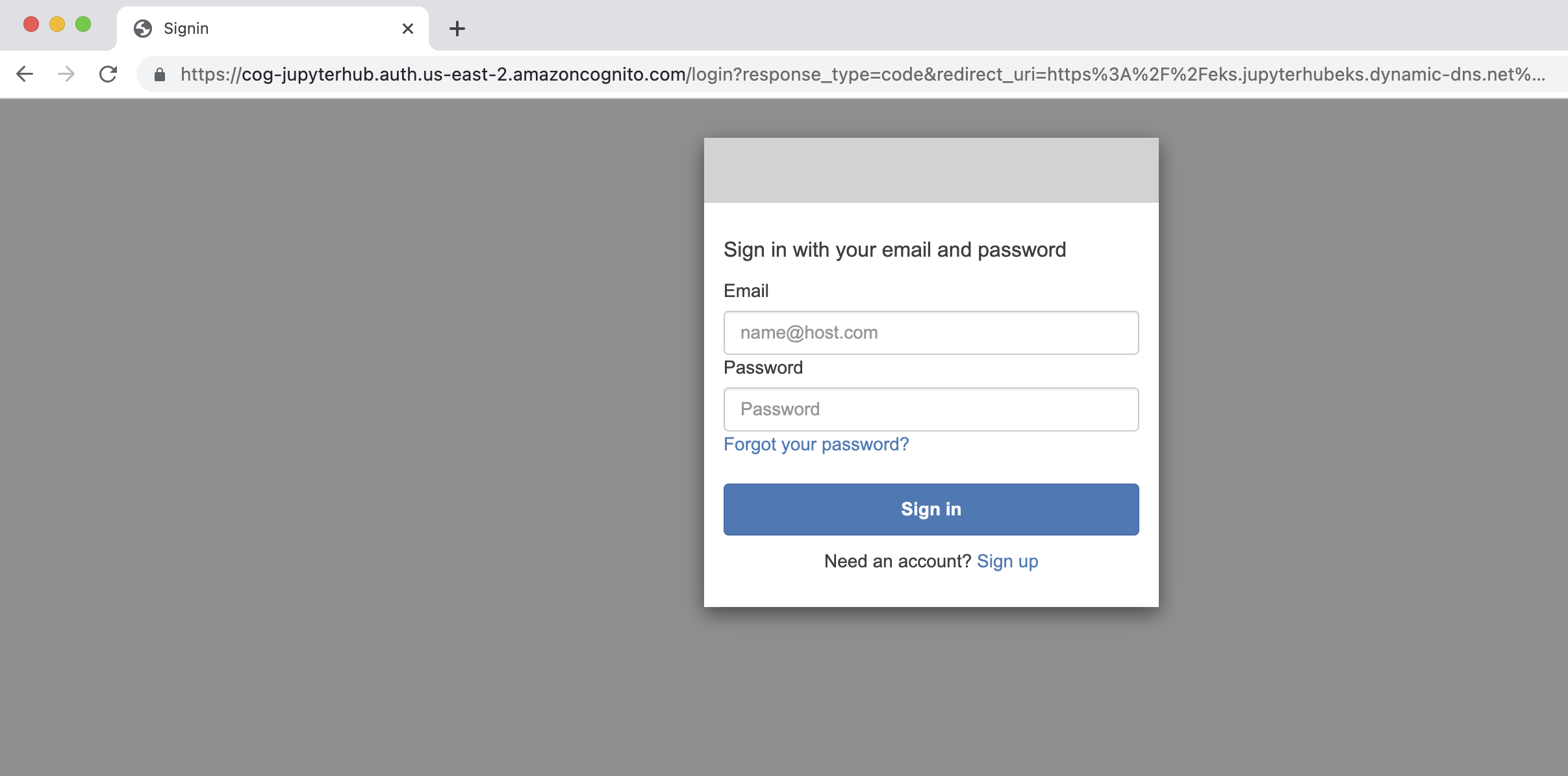
Cognito 가입 및 로그인 프로세스를 따라 로그인합니다.
성공적인 로그인은 로그인한 사용자를 위한 JupyterHub 환경을 엽니다.
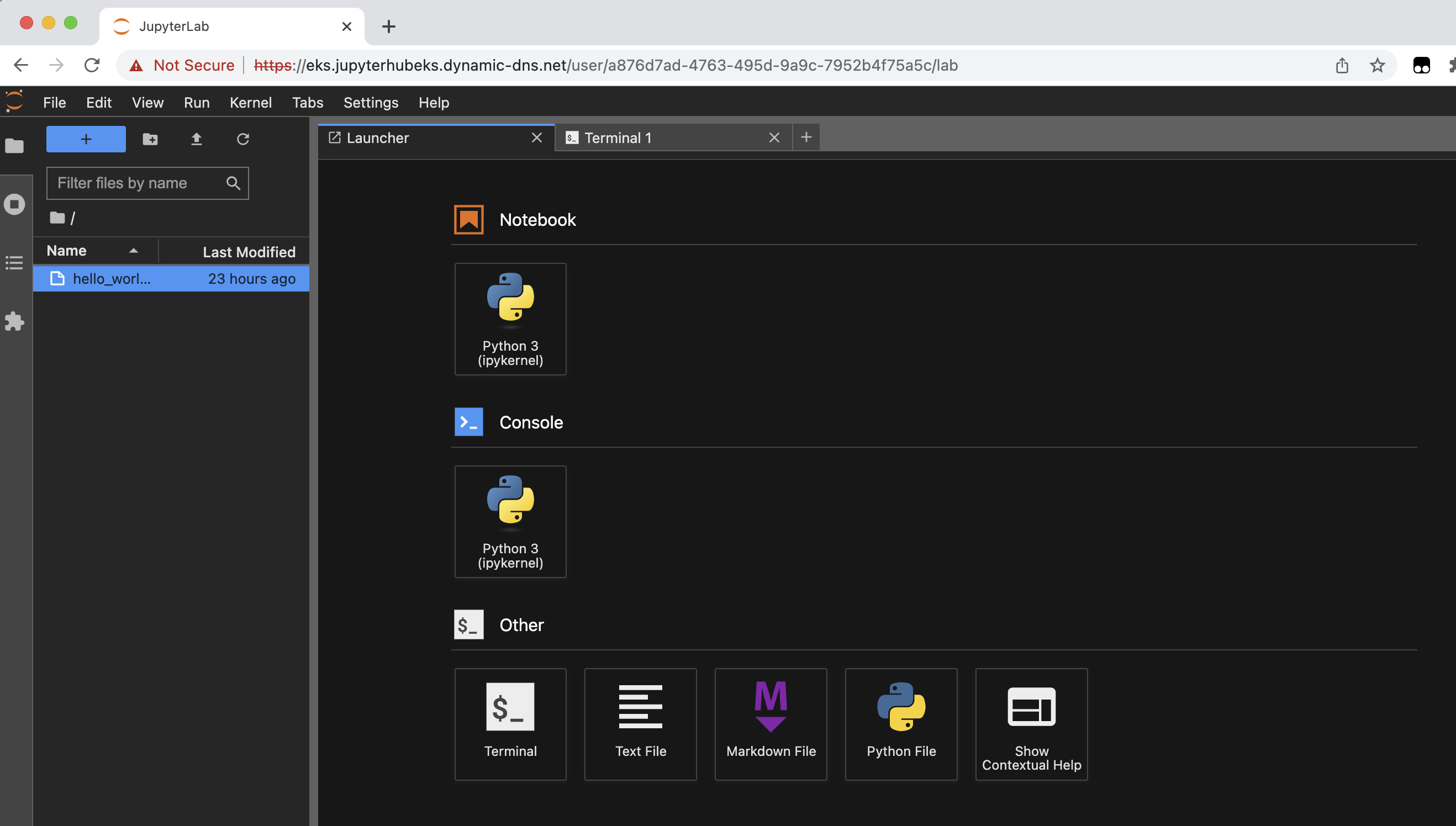
JupyterHub에서 공유 및 개인 디렉터리 설정을 테스트하려면 다음 단계를 따르세요:
- 런처 대시보드에서 터미널 창을 엽니다.
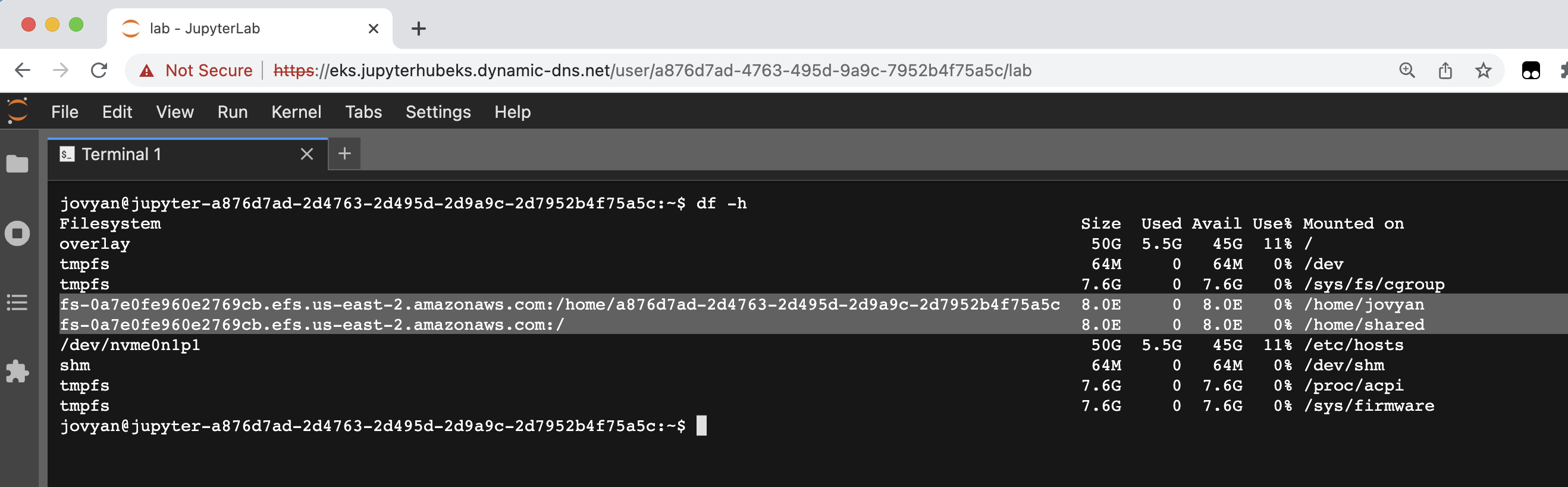
- 명령을 실행합니다
df -h
생성된 EFS 마운트를 확인합니다. 각 사용자의 개인 홈 디렉터리는 /home/jovyan에서 사용할 수 있습니다. 공유 디렉터리는 /home/shared에서 사용할 수 있습니다
유형 3 배포(선택 사항): OAuth(Keycloak)를 통해 JupyterHub 로그인
참고: OAuth 제공업체에 따라 약간 다르게 보일 수 있습니다.
로드 밸런서 DNS 이름으로 JupyterHub 도메인에 대한 CNAME DNS 레코드를 ChangeIP에 추가합니다.
ChangeIP의 CNAME 값 필드에 로드 밸런서 DNS 이름을 추가할 때 로드 밸런서 DNS 이름 끝에 점(.)을 추가해야 합니다.
이제 브라우저에서 도메인 URL을 입력하면 JupyterHub 로그인 페이지로 리디렉션됩니다.
Keycloak 가입 및 로그인 프로세스를 따라 로그인합니다.
성공적인 로그인은 로그인한 사용자를 위한 JupyterHub 환경을 엽니다.