Using Task Governance to optimize operation performance
SageMaker HyperPod task governance is a management system designed to streamline resource allocation and ensure efficient utilization of compute resources across teams and projects for your Amazon EKS clusters. It provides administrators with the capability to set priority levels for various tasks, allocate compute resources for each team, determine how idle compute is borrowed and lent between teams, and configure whether a team can preempt its own tasks.
HyperPod task governance leverages Kueue for Kubernetes-native job queueing, scheduling, and quota management and is installed using the HyperPod task governance EKS add-on.
Installing the add-on
Setup Task Governance EKS add-on
To install SageMaker HyperPod task governance, you will need Kubernetes version 1.30 or greater and you will need to remove any existing installations of Kueue.
- Setup using the AWS Console
- Setup using AWS CLI
Navigate to your HyperPod Cluster in the SageMaker AI console. In the Dashboard tab, click Install under the Amazon SageMaker HyperPod task governance add-on.

To install the SageMaker HyperPod task governance EKS add-on, run the following command:
aws eks create-addon --region $REGION --cluster-name $EKS_CLUSTER_NAME --addon-name amazon-sagemaker-hyperpod-taskgovernance
Verify successful installation with:
aws eks describe-addon --region $REGION --cluster-name $EKS_CLUSTER_NAME --addon-name amazon-sagemaker-hyperpod-taskgovernance
If the installation was successful, you should see details about the installed add-on in the output.
Task governance concepts
Amazon SageMaker HyperPod task governance uses policies to define resource allocation and task prioritization. These policies are categorized into compute prioritization and compute allocation.
Cluster policy
Compute prioritization, also known as cluster policy, determines how idle compute is borrowed and how tasks are prioritized across teams. A cluster policy consists of two key components:
- Task Prioritization
- Idle Compute Allocation

As an administrator, you should define your organization's priorities and configure the cluster policy accordingly.
Idle compute allocation
Idle compute allocation defines how idle compute are distributed among teams. This determines whether and how teams can borrow idle compute. You can choose between the following allocation strategies:
- First-come first-serve: Teams are not prioritized over one another. Each incoming task has an equal chance of obtaining over-quota resources. Compute is allocated based on the order of task submission, meaning a single user could use 100% of the idle compute if they request it first.
- Fair-share: Teams borrow idle compute based on their assigned Fair-share weight. These weights are defined in Compute Allocation and determine how compute is distributed among teams when idle resources are available.
Task prioritization
Task prioritization determines how tasks are queued as compute becomes available. You can choose between the following methods:
- First-come first-serve: Tasks are queued in the order they are submitted.
- Task ranking: Tasks are queued based on their assigned priority. Tasks within the same priority class are processed on a first-come, first-serve basis. If Task Preemption is enabled in Compute Allocation, higher-priority tasks can preempt lower-priority tasks within the same team
Here's an example configuration for a cluster policy. In this example, we have inference tasks as top priority, and have enabled the idle compute allocation to the fair-share strategy (based on team weights).
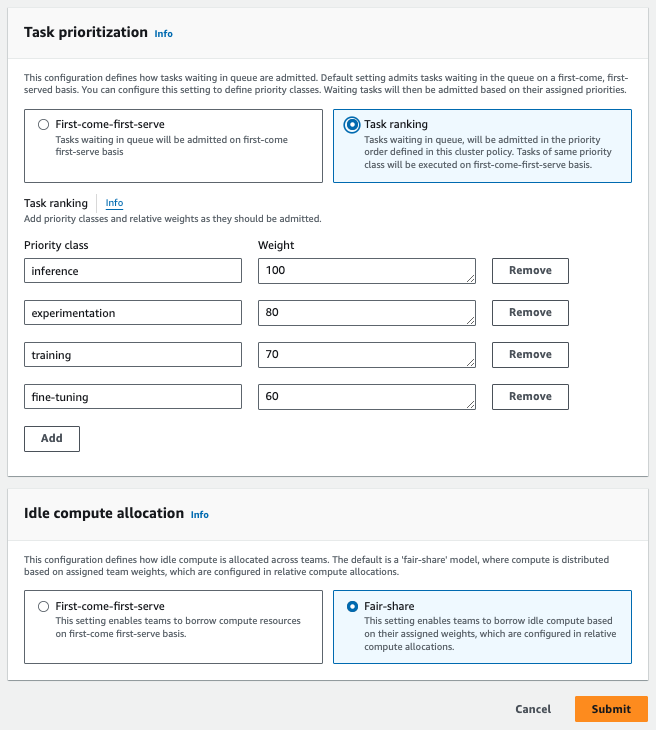
Compute allocations
Compute allocation, or compute quota, defines a team’s compute allocation and what weight (or priority level) a team is given for fair-share idle compute allocation.
You will need at minimum two compute allocations created in order to borrow capacity and preempt tasks across teams. The total reserved quota should not surpass the cluster's available capacity for that resource, to ensure proper quota management. For example, if a cluster comprises 20 ml.c5.2xlarge instances, the cumulative quota assigned to teams should remain under 20. For more details on how compute is allocated in task governance, please follow the documentation for task governance.
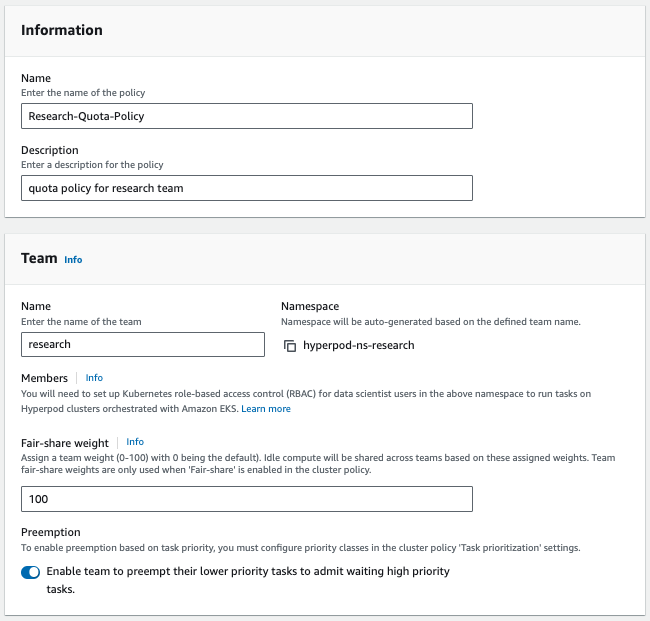
In the next section, we will walk through a detailed example with step-by-step instructions on configuring these settings.
Examples
This section demonstrates how to configure task governance using an example cluster with 4 g5.8xlarge instances. If you haven't set up the HyperPod task governance add-on, refer to the Task Governance Setup page.
This section will guide you on an end to end example of using task governance. We use a cluster of 4 g5.8xlarge instances split between two teams (Team A and Team B).
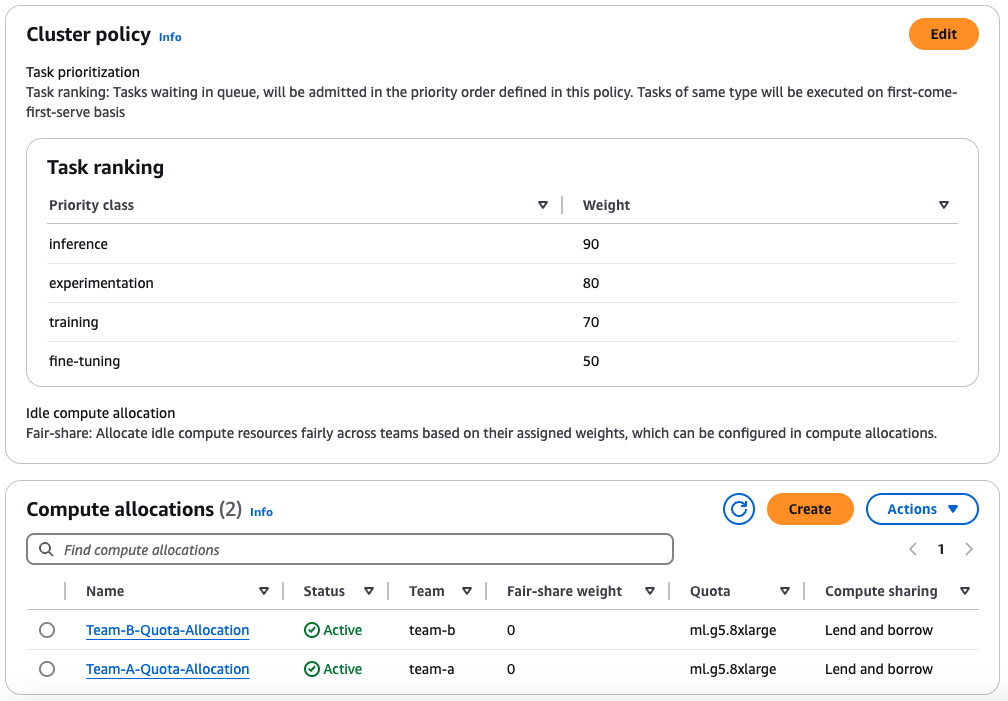
Before running the examples, we will set up a Cluster Policy and define Compute Allocations for the teams. The policy will use task ranking instead of the default FIFO (First-In-First-Out) behavior, allowing higher-priority tasks to preempt lower-priority ones.
Setup cluster policy
Setup env variables:
export HYPERPOD_CLUSTER_ARN={your-hyperpod-cluster-arn}
To update how tasks are prioritized and how idle compute is allocated, apply a Cluster Policy using the following configuration:
aws sagemaker \
create-cluster-scheduler-config \
--name "example-cluster-scheduler-config" \
--cluster-arn $HYPERPOD_CLUSTER_ARN \
--scheduler-config "PriorityClasses=[{Name=inference,Weight=90},{Name=experimentation,Weight=80},{Name=fine-tuning,Weight=50},{Name=training,Weight=70}],FairShare=Enabled"
This CLI command will output two values: CreateSchedulerConfigArn and ClusterSchedulerConfigId. This will generate a cluster policy with fair sharing enabled and the following priority classes:
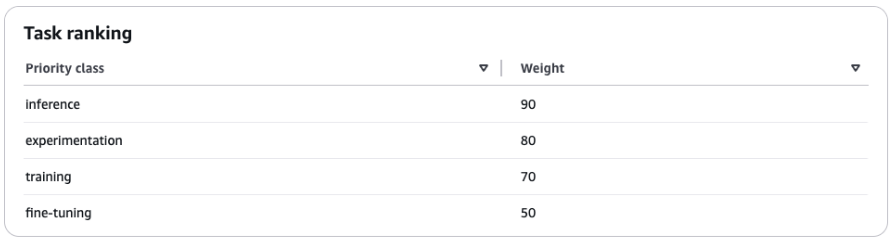
A higher weight indicates a higher priority. In this example, the inference priority class has the highest priority.
Setup compute allocations
Each team requires a Compute Allocation to manage their compute capacity. Both teams will have 2 instances allocated, 0 fair-share weight, and 50% borrowing capability.
aws sagemaker \
create-compute-quota \
--name "Team-A-Quota-Allocation" \
--cluster-arn $HYPERPOD_CLUSTER_ARN \
--compute-quota-config "ComputeQuotaResources=[{InstanceType=ml.g5.8xlarge,Count=2}],ResourceSharingConfig={Strategy=LendAndBorrow,BorrowLimit=50},PreemptTeamTasks=LowerPriority" \
--activation-state "Enabled" \
--compute-quota-target "TeamName=team-a,FairShareWeight=0"
aws sagemaker \
create-compute-quota \
--name "Team-B-Quota-Allocation" \
--cluster-arn $HYPERPOD_CLUSTER_ARN \
--compute-quota-config "ComputeQuotaResources=[{InstanceType=ml.g5.8xlarge,Count=2}],ResourceSharingConfig={Strategy=LendAndBorrow,BorrowLimit=50},PreemptTeamTasks=LowerPriority" \
--activation-state "Enabled" \
--compute-quota-target "TeamName=team-b,FairShareWeight=0"
Clone the examples repository
Navigate to your home directory or your preferred project directory, clone the repo.
cd ~
git clone https://github.com/aws-samples/awsome-distributed-training/
cd awsome-distributed-training/1.architectures/7.sagemaker-hyperpod-eks/task-governance
Borrow compute from another team
This section provides a walkthrough of a job submission using task governance, based on the setup created in the Setup for running the examples page.
Scenario: Team A submits a PyTorch job that requires 3 instances but only has 2 allocated. The system allows Team A to borrow 1 instance from Team B's idle capacity.
kubectl apply -f 1-imagenet-gpu-team-a.yaml --namespace hyperpod-ns-team-a
Verify the job is running (pulling the container image might take a moment):
kubectl get pods -n hyperpod-ns-team-a
NAME READY STATUS RESTARTS AGE
etcd-gpu-679b676b55-5xj5x 1/1 Running 0 5m
imagenet-gpu-team-a-1-worker-0 1/1 Running 0 5m
imagenet-gpu-team-a-1-worker-1 1/1 Running 0 5m
imagenet-gpu-team-a-1-worker-2 1/1 Running 0 5m
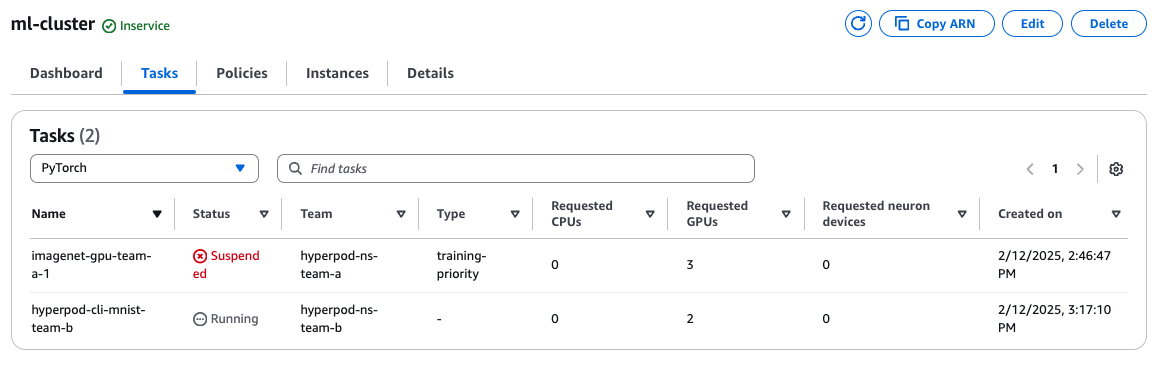
In the task tab of the console, you should see the job running:

Once the pods are running, you can check the output of logs to identify the elected master:
kubectl logs imagenet-gpu-team-a-1-worker-0 --namespace hyperpod-ns-team-a | grep master_addr=
[2025-02-04 18:58:08,460] torch.distributed.elastic.agent.server.api: [INFO] master_addr=imagenet-gpu-team-a-1-worker-2
You can then use the pod referenced in the master_addr to look at the current training progress:
kubectl logs imagenet-gpu-team-a-1-worker-2 --namespace hyperpod-ns-team-a
Reclaim guaranteed compute
This section provides a walkthrough of a job submission using task governance, based on the setup created in the Setup for running the examples. It also demonstrates how to run the sample application using the HyperPod CLI instead of kubectl. If you haven't installed the HyperPod CLI, refer to the Install HyperPod CLI page.
Scenario: Team B needs to reclaim its compute resources. By submitting a job requiring 2 instances, Team B's job is prioritized, and Job 1 is suspended due to resource unavailability.
In this example, we'll be using the hyperpod CLI, but we could also use kubectl and have identical behavior.
hyperpod start-job --config-file 2-hyperpod-cli-example-team-b.yaml
This command will give you a similar output:
{
"Console URL": "https://us-east-1.console.aws.amazon.com/sagemaker/home?region=us-east-1#/cluster-management/ml-cluster"
}
After the job has been submitted, you can see that the workers from Job 1 have been preempted, and only the workers in Team B's namespace are running.
Check running pods for Team B:
kubectl get pods -n hyperpod-ns-team-b
NAME READY STATUS RESTARTS AGE
hyperpod-cli-mnist-team-b-worker-0 1/1 Running 0 3m47s
hyperpod-cli-mnist-team-b-worker-1 1/1 Running 0 3m47s
Preempt low priority tasks
This section provides a walkthrough of a job submission using task governance, based on the setup created in the Setup for running the examples page.
Scenario: Team B submits a high-priority job requiring 2 instances. Since high-priority jobs take precedence, Job 2 is suspended, ensuring Team B’s critical workload runs first.
kubectl apply -f 3-imagenet-gpu-team-b-higher-prio.yaml --namespace hyperpod-ns-team-b
Since this job uses a priority-class with a higher weight than the other jobs, the lower-priority Job 2 is preempted:
kubectl get pods -n hyperpod-ns-team-b
NAME READY STATUS RESTARTS AGE
etcd-gpu-6584d647d4-5z564 1/1 Running 0 11s
hyperpod-cli-mnist-team-b-worker-0 1/1 Terminating 0 28s
hyperpod-cli-mnist-team-b-worker-1 1/1 Terminating 0 28s
imagenet-gpu-team-b-2-worker-0 1/1 Running 0 10s
imagenet-gpu-team-b-2-worker-1 1/1 Running 0 10s
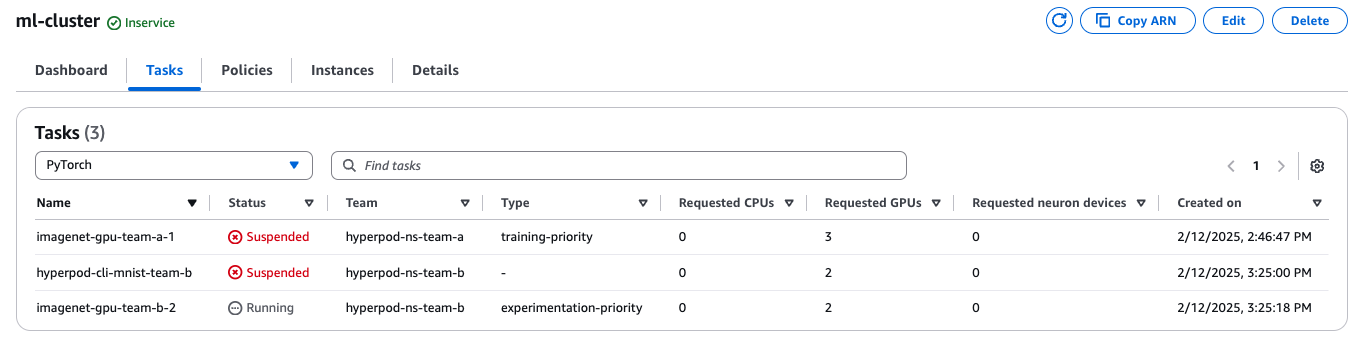
Inspecting workloads
We can also inspect the workloads on a particular namespace:
kubectl get workloads -n hyperpod-ns-team-b
This is an example output of the command after running all 3 scenarios:
NAME QUEUE RESERVED IN ADMITTED FINISHED AGE
pod-etcd-gpu-6584d647d4-sp6xx-bb3f9 hyperpod-ns-team-b-localqueue hyperpod-ns-team-b-clusterqueue True 11s
pytorchjob-hyperpod-cli-mnist-team-b-2c720 hyperpod-ns-team-b-localqueue False 45s
pytorchjob-imagenet-gpu-team-b-2-ef5c0 hyperpod-ns-team-b-localqueue hyperpod-ns-team-b-clusterqueue True 11s
We can see that the workload for Job 2 has been set to ADMITTED: False because the newly submitted workload took precedence.
When we describe the suspended workload, we can see the reason it was preempted.
kubectl describe workload pytorchjob-hyperpod-cli-mnist-team-b-2c720 -n hyperpod-ns-team-b
Status:
Conditions:
Last Transition Time: 2025-02-04T19:06:25Z
Message: couldn't assign flavors to pod set worker: borrowing limit for nvidia.com/gpu in flavor ml.g5.8xlarge exceeded
Observed Generation: 1
Reason: Pending
Status: False
Type: QuotaReserved
Last Transition Time: 2025-02-04T19:06:25Z
Message: Preempted to accommodate a workload (UID: d34468c2-1ce5-47cd-a61d-689be78b6121) due to prioritization in the ClusterQueue
Observed Generation: 1
Reason: Preempted
Status: True
Type: Evicted
Last Transition Time: 2025-02-04T19:06:25Z
Message: The workload has no reservation
Observed Generation: 1
Reason: NoReservation
Status: False
Type: Admitted
Last Transition Time: 2025-02-04T19:06:25Z
Message: Preempted to accommodate a workload (UID: d34468c2-1ce5-47cd-a61d-689be78b6121) due to prioritization in the ClusterQueue
Reason: InClusterQueue
Status: True
Type: Preempted
Last Transition Time: 2025-02-04T19:06:25Z
Message: Preempted to accommodate a workload (UID: d34468c2-1ce5-47cd-a61d-689be78b6121) due to prioritization in the ClusterQueue
Observed Generation: 1
Reason: Preempted
Status: True
Type: Requeued