通用自然语言理解
支持各种中文文本理解任务,如文本分类、情感分析、提取和可定制的标签系统。
适用场景
用于文本分类、情感分析、文本匹配和实体识别等场景。
API参数说明
该API支持文本分类、情感分类、文本匹配和实体识别,共4大类任务。该API在不同的任务下有不同的输入参数。
文本分类
-
HTTP 方法:
POST -
Body 请求参数
| 名称 | 类型 | 是否必选 | 说明 |
|---|---|---|---|
| subtask_type | String | 是 | 固定为“文本分类” |
| text | String | 是 | 待分类的文本 |
| choices | List | 是 | 候选标签,请参考 请求 Body 示例。 |
| question | String | 是 | 用于指导模型的提示文本 |
- 请求 Body 示例
例子1:
{
"subtask_type": "文本分类",
"text": "待分类的文本",
"choices": [{
"entity_type": "投资",
"label": 0,
"entity_list": []
}, {
"entity_type": "科技",
"label": 0,
"entity_list": []
}, {
"entity_type": "体育",
"label": 0,
"entity_list": []
}, {
"entity_type": "美食",
"label": 0,
"entity_list": []
}, {
"entity_type": "旅游",
"label": 0,
"entity_list": []
}],
"question": "这是篇什么类型的新闻"
}
例子2:
{
"subtask_type": "文本分类",
"text": "待分类的文本",
"choices": [{
"entity_type": "农业工程",
"label": 0,
"entity_list": []
}, {
"entity_type": "哲学",
"label": 0,
"entity_list": []
}, {
"entity_type": "教育学",
"label": 0,
"entity_list": []
}, {
"entity_type": "理学",
"label": 0,
"entity_list": []
}, {
"entity_type": "农学",
"label": 0,
"entity_list": []
}],
"question": "这篇文章属于哪个学科"
}
- 返回参数
| 名称 | 类型 | 说明 |
|---|---|---|
| result | Dict | 与请求参数同格式,对应选项的label被置为1,同时增加score。请参考 返回示例。 |
- 返回示例
例子1的返回:
假设模型返回"待分类的文本"的类别为“体育”。
{
"subtask_type": "文本分类",
"text": "待分类的文本",
"choices": [{
"entity_type": "投资",
"label": 0,
"entity_list": []
}, {
"entity_type": "科技",
"label": 0,
"entity_list": []
}, {
"entity_type": "体育",
"label": 1,
"entity_list": [],
"score": 0.91592306
}, {
"entity_type": "美食",
"label": 0,
"entity_list": []
}, {
"entity_type": "旅游",
"label": 0,
"entity_list": []
}],
"question": "这是篇什么类型的新闻"
}
例子2的返回:
{
"subtask_type": "文本分类",
"text": "待分类的文本",
"choices": [{
"entity_type": "农业工程",
"label": 0,
"entity_list": []
}, {
"entity_type": "哲学",
"label": 0,
"entity_list": []
}, {
"entity_type": "教育学",
"label":1,
"entity_list": [],
"score": 0.91592306
}, {
"entity_type": "理学",
"label": 0,
"entity_list": []
}, {
"entity_type": "农学",
"label": 0,
"entity_list": []
}],
"question": "这篇文章属于哪个学科"
}
情感分类
-
HTTP 方法:
POST -
Body 请求参数
| 名称 | 类型 | 是否必选 | 说明 |
|---|---|---|---|
| subtask_type | String | 是 | 固定为“情感分类” |
| text | String | 是 | 待分类的文本 |
| choices | List | 是 | 候选情感标签,请参考 请求 Body 示例。 |
| question | String | 是 | 用于指导模型的提示文本 |
- 请求 Body 示例
{
"subtask_type": "情感分类",
"text": "待分类的用户评论",
"choices": [{
"entity_type": "积极",
"label": 0,
"entity_list": []
}, {
"entity_type": "中性",
"label": 0,
"entity_list": []
}, {
"entity_type": "消极",
"label": 0,
"entity_list": []
}],
"question": "这句话的情感极性是什么"
}
- 返回参数
| 名称 | 类型 | 说明 |
|---|---|---|
| result | Dict | 与请求参数同格式,对应选项的label被置为1,同时增加score。请参考 返回示例。 |
- 返回示例
假设模型返回"待分类的用户评论"的情感极性为“中性”。
{
"subtask_type": "情感分类",
"text": "待分类的用户评论",
"choices": [{
"entity_type": "积极",
"label": 0,
"entity_list": []
}, {
"entity_type": "中性",
"label": 1,
"entity_list": [],
"score": 0.91592306
}, {
"entity_type": "消极",
"label": 0,
"entity_list": []
}],
"question": "这句话的情感极性是什么"
}
文本匹配
-
HTTP 方法:
POST -
Body 请求参数
| 名称 | 类型 | 是否必选 | 说明 |
|---|---|---|---|
| subtask_type | String | 是 | 固定为“文本匹配” |
| text | String | 是 | 第一个文本 |
| choices | List | 是 | 每个元素的entity_type是提示词与第二个文本的拼接,例如“可以推断出:第二个文本”或“可以理解为:第二个文本”,请参考 请求 Body 示例。 |
| question | String | 是 | 用于指导模型的提示文本 |
- 请求 Body 示例
例子1:
{
"subtask_type": "文本匹配",
"text": "在白云的蓝天下,一个孩子伸手摸着停在草地上的一架飞机的螺旋桨。",
"choices": [{
"entity_type": "可以推断出:一个孩子正伸手摸飞机的螺旋桨。",
"label": 0,
"entity_list": []
}, {
"entity_type": "不能推断出:一个孩子正伸手摸飞机的螺旋桨。",
"label": 0,
"entity_list": []
}, {
"entity_type": "很难推断出:一个孩子正伸手摸飞机的螺旋桨。",
"label": 0,
"entity_list": []
}],
"question": "同义文本"
}
例子2:
{
"subtask_type": "文本匹配",
"text": "您好,我还款了怎么还没扣款",
"choices": [{
"entity_type": "可以理解为:今天一直没有扣款",
"label": 0,
"entity_list": []
}, {
"entity_type": "不能理解为:今天一直没有扣款",
"label": 0,
"entity_list": []
}],
"question": "同义文本"
}
- 返回参数
| 名称 | 类型 | 说明 |
|---|---|---|
| result | Dict | 与请求参数同格式,对应选项的label被置为1,同时增加score。请参考 返回示例。 |
- 返回示例
例子1的返回:
{
"subtask_type": "文本匹配",
"text": "在白云的蓝天下,一个孩子伸手摸着停在草地上的一架飞机的螺旋桨。",
"choices": [{
"entity_type": "可以推断出:一个孩子正伸手摸飞机的螺旋桨。",
"label": 0,
"entity_list": []
}, {
"entity_type": "不能推断出:一个孩子正伸手摸飞机的螺旋桨。",
"label": 1,
"entity_list": [],
"score": 0.91592306
}, {
"entity_type": "很难推断出:一个孩子正伸手摸飞机的螺旋桨。",
"label": 0,
"entity_list": []
}],
"question": "同义文本"
}
例子2的返回:
{
"subtask_type": "文本匹配",
"text": "您好,我还款了怎么还没扣款",
"choices": [{
"entity_type": "可以理解为:今天一直没有扣款",
"label": 1,
"entity_list": [],
"score": 0.91592306
}, {
"entity_type": "不能理解为:今天一直没有扣款",
"label": 0,
"entity_list": []
}],
"question": "同义文本"
}
实体识别
-
HTTP 方法:
POST -
Body 请求参数
| 名称 | 类型 | 是否必选 | 说明 |
|---|---|---|---|
| subtask_type | String | 是 | 固定为“实体识别” |
| text | String | 是 | 待分类的文本 |
| choices | List | 是 | 每个元素的entity_type是想要提取的实体类型。请参考 请求 Body 示例。 |
- 请求 Body 示例
{
"subtask_type": "实体识别",
"text": "我们是首家支持英特尔、AMD 和 Arm 处理器的主要云提供商",
"choices": [{
"entity_type": "地址",
"label": 0,
"entity_list": []
}, {
"entity_type": "公司名",
"label": 0,
"entity_list": []
}, {
"entity_type": "人物姓名",
"label": 0,
"entity_list": []
}]
}
- 返回参数
| 名称 | 类型 | 说明 |
|---|---|---|
| result | Dict | 与请求参数同格式,对应实体的entity_list会增加抽取到的实体内容及位置。请参考 返回示例。 |
- 返回示例
假设模型返回"待分类的用户评论"的情感极性为“中性”。
{
"subtask_type": "实体识别",
"text": "我们是首家支持英特尔、AMD 和 Arm 处理器的主要云提供商",
"choices": [{
"entity_type": "地址",
"label": 0,
"entity_list": []
}, {
"entity_type": "公司名",
"label": 0,
"entity_list": [{
"entity_name":"英特尔",
"entity_type":"公司名",
"entity_idx":[
[7, 9]
]
},{
"entity_name":"AMD",
"entity_type":"公司名",
"entity_idx":[
[11, 13]
]
}]
}, {
"entity_type": "人物姓名",
"label": 0,
"entity_list": []
}]
}
开始使用
API资源浏览器
前提条件
通过AWS CloudFormation部署解决方案时,您需要:
- 设置参数API Explorer为yes。
- 设置参数API Gateway Authorization为NONE。
否则,在API资源浏览器中只能看到该API的参考定义,而不能进行在线测试等操作。
操作步骤
- 访问AWS CloudFormation控制台。
-
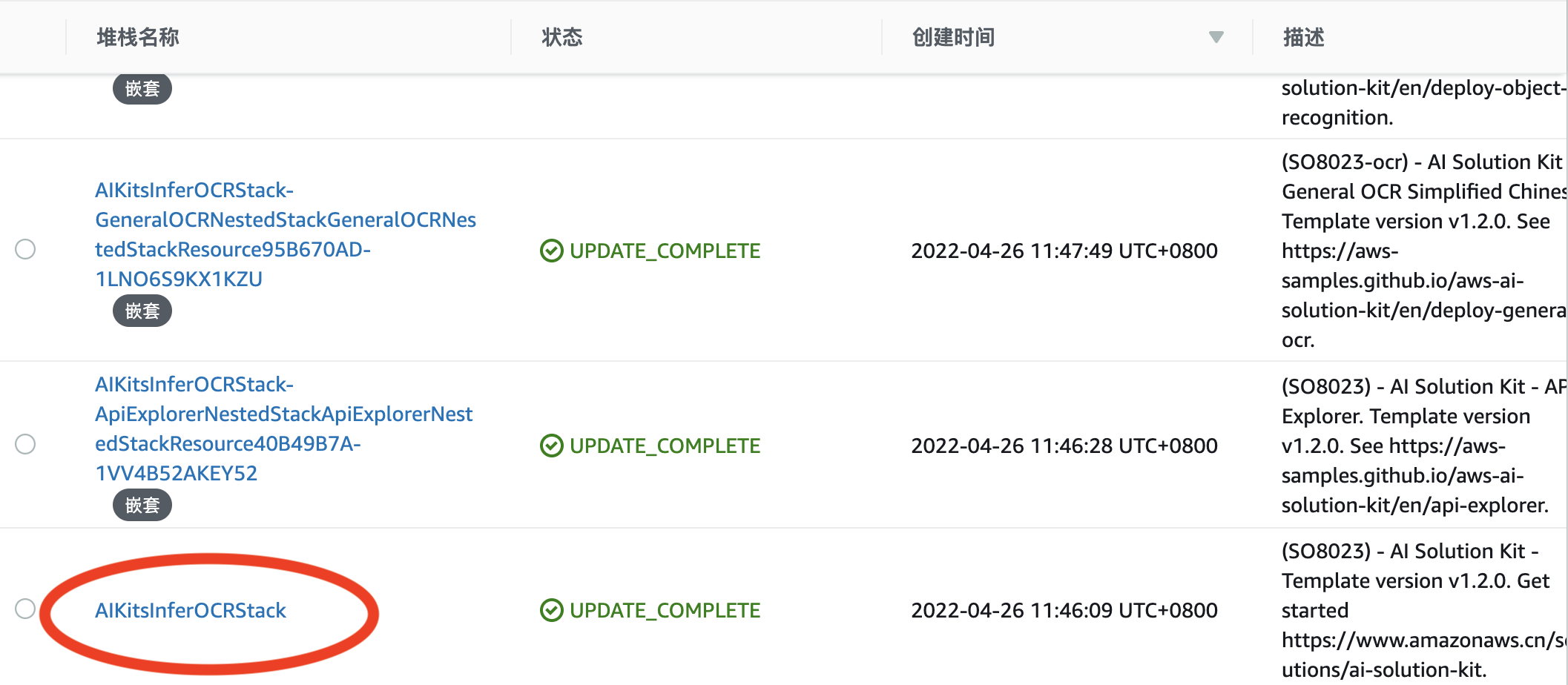
从堆栈列表中选择方案的根堆栈,而不是嵌套堆栈。列表中嵌套堆栈的名称旁边会显示嵌套(NESTED)。
-
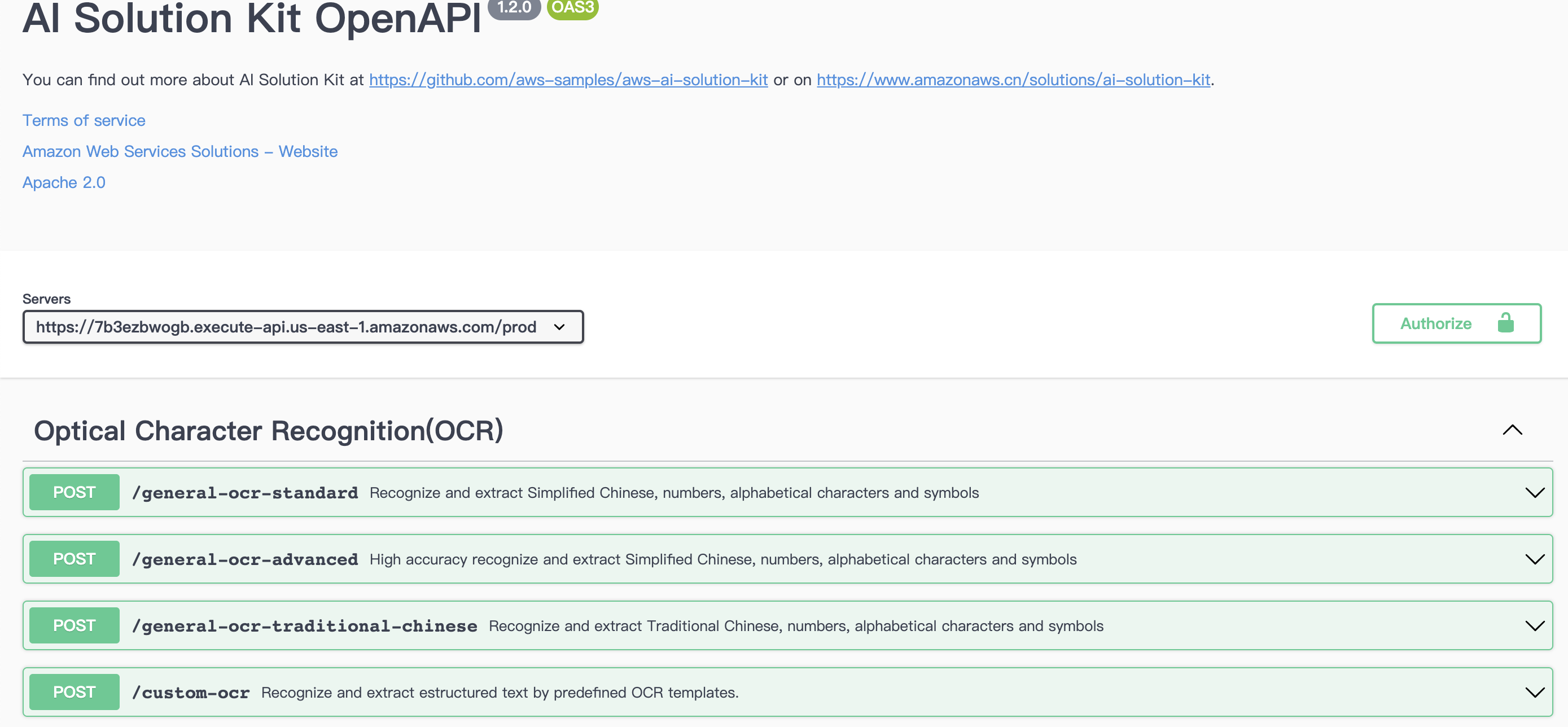
打开输出(Outputs)标签页,找到APIExplorer对应的URL。
-
点击URL访问API资源浏览器。页面将显示在部署解决方案时选中的API。
-
点击API右侧的向下箭头,展开显示API标准模型的请求方法。
- 点击右侧的测试(Try it out)按钮,并在Request body中输入正确的Body请求数据进行测试,并查看测试结果。
- 确认格式正确后,点击下方的Execute。
- 在Responses body中查看返回的JSON结果。您还可以通过右侧复制或下载按钮保存处理结果。
- 在Response headers中查看响应头的相关信息。
- (可选)点击Execute右侧Clear按钮,即可清空Request body与Responses测试结果。
Postman(AWS_IAM认证)
- 访问AWS CloudFormation控制台。
- 从堆栈列表中选择方案的根堆栈。
- 打开输出标签页,找到以 GeneralNLU 为前缀的URL。
-
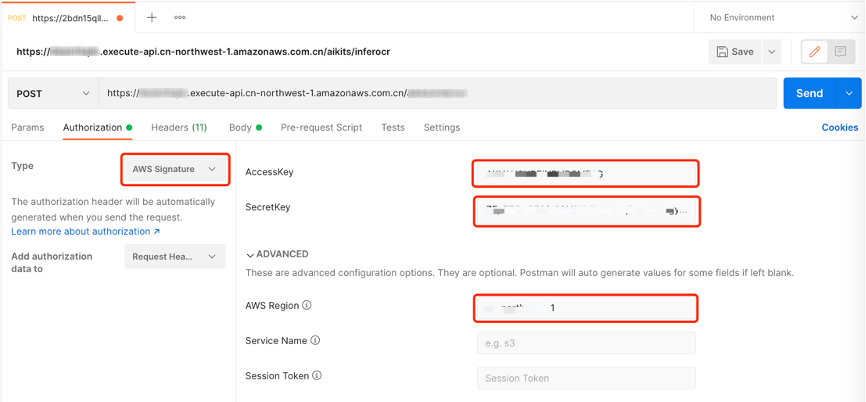
在Postman中新建标签页,并把URL粘贴到地址栏,选择POST作为HTTP调用方法。

-
打开Authorization配置,在下拉列表里选择Amazon Web Service Signature,并填写对应账户的AccessKey、SecretKey和Amazon Web Service Region(例如,cn-north-1或cn-northwest-1)。
-
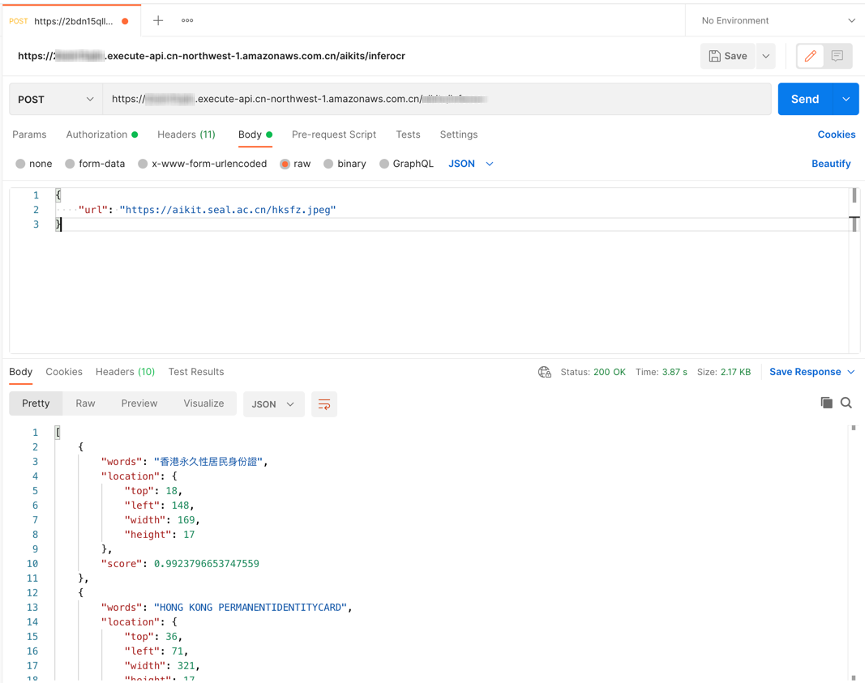
打开Body配置项,选中raw和JSON数据类型。
-
在Body中输入测试数据,单击Send按钮即可看到相应返回结果。
{
"url": "图像的URL地址"
}
cURL
- Windows
curl --location --request POST "https://[API_ID].execute-api.[AWS_REGION].amazonaws.com/[STAGE]/general_nlu" ^
--header "Content-Type: application/json" ^
--data-raw "{\"url\": \"图像的URL地址\"}"
- Linux/MacOS
curl --location --request POST 'https://[API_ID].execute-api.[AWS_REGION].amazonaws.com/[STAGE]/general_nlu' \
--header 'Content-Type: application/json' \
--data-raw '{
"url":"图像的URL地址"
}'
Python(AWS_IAM认证)
import requests
import json
from aws_requests_auth.boto_utils import BotoAWSRequestsAuth
auth = BotoAWSRequestsAuth(aws_host='[API_ID].execute-api.[AWS_REGION].amazonaws.com',
aws_region='[AWS_REGION]',
aws_service='execute-api')
url = 'https://[API_ID].execute-api.[AWS_REGION].amazonaws.com/[STAGE]/general_nlu'
payload = {
'url': '图像的URL地址'
}
response = requests.request("POST", url, data=json.dumps(payload), auth=auth)
print(json.loads(response.text))
Python(NONE认证)
import requests
import json
url = "https://[API_ID].execute-api.[AWS_REGION].amazonaws.com/[STAGE]/general_nlu"
payload = json.dumps({
"url": "图像的URL地址"
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
Java
OkHttpClient client = new OkHttpClient().newBuilder()
.build();
MediaType mediaType = MediaType.parse("application/json");
RequestBody body = RequestBody.create(mediaType, "{\n \"url\":\"图像的URL地址\"\n}");
Request request = new Request.Builder()
.url("https://xxxxxxxxxxx.execute-api.xxxxxxxxx.amazonaws.com/[STAGE]/general_nlu")
.method("POST", body)
.addHeader("Content-Type", "application/json")
.build();
Response response = client.newCall(request).execute();
成本预估
您需要承担运行解决方案时使用亚马逊云科技各个服务的成本费用。截至这次发布的版本,影响解决方案的成本因素主要包括:
- AWS Lambda调用次数
- AWS Lambda运行时间
- Amazon API Gateway调用次数
- Amazon API Gateway数据输出量
- Amazon CloudWatch Logs存储量
- Amazon Elastic Container Registry存储量
说明
Amazon SageMaker相关的费用仅适用于图像超分辨率方案。
成本预估示例1
以由西云数据运营的亚马逊云科技中国(宁夏)区域(cn-northwest-1)为例,处理时间1秒
使用本方案处理此文本所需的成本费用如下表所示:
| 服务 | 用量 | 费用 |
|---|---|---|
| AWS Lambda | 调用百万次 | ¥1.36 |
| AWS Lambda | 内存8192MB,每次运行1秒 | ¥907.8 |
| Amazon API Gateway | 调用百万次 | ¥28.94 |
| Amazon API Gateway | 数据输出以每次10KB计算,¥0.933/GB | ¥9.33 |
| Amazon CloudWatch Logs | 每次10KB,¥6.228/GB | ¥62.28 |
| Amazon Elastic Container Registry | 0.5GB存储,每月每GB¥0.69 | ¥0.35 |
| 合计 | ¥1010.06 |
成本预估示例2
以美国东部(俄亥俄州)区域(us-east-2)为例,处理时间1秒
使用本方案处理此文本所需的成本费用如下表所示:
| 服务 | 用量 | 费用 |
|---|---|---|
| Amazon Lambda | 调用百万次 | $0.20 |
| Amazon Lambda | 内存8192MB,每次运行1秒 | $133.3 |
| Amazon API Gateway | 调用百万次 | $3.5 |
| Amazon API Gateway | 数据输出以每次10KB计算,$0.09/GB | $0.9 |
| Amazon CloudWatch Logs | 每次10KB,$0.50/GB | $5 |
| Amazon Elastic Container Registry | 0.5GB存储,每月每GB$0.1 | $0.05 |
| 合计 | $142.95 |
卸载部署
您可以通过AWS CloudFormation卸载 General NLU 功能,具体步骤请见部署解决方案:更新AWS CloudFormation堆栈(添加或删除AI功能),并在参数部分确认 GeneralNLU 参数设置为no。
卸载时间:10 Minutes