解决方案端到端架构
使用默认配置部署此解决方案将构建以下环境:

此解决方案在您的亚马逊云科技账户中部署 Amazon CloudFormation 模板并完成以下设置。
- Amazon CloudFront 分发托管在 Amazon S3 存储桶中的前端 Web 用户界面资产,以及由Amazon API Gateway 和 AWS Lambda 托管的后端 API。
- Amazon Cognito 用户池或 OpenID Connect (OIDC) 用于身份验证。
- Web 用户界面控制台使用 Amazon DynamoDB 来存储永久数据。
- AWS Step Functions, AWS CloudFormation,AWS Lambda 和 Amazon EventBridge 用于协调数据管道的生命周期管理。
- 数据管道在系统操作员指定的区域进行配置。它由Application Load Balancer (ALB)、Amazon ECS、Amazon Managed Streaming for Kafka (Amazon MSK)、Amazon Kinesis、Amazon S3、Amazon EMR Serverless、Amazon Redshift 和 Amazon QuickSight 组成。
数据管道
该解决方案的关键功能是构建数据管道来摄取、处理和分析点击流数据。数据管道由四个模块组成:
- 摄取模块
- 数据处理模块
- 数据建模模块
- 报表模块
下面介绍每个模块的架构图。
摄取模块
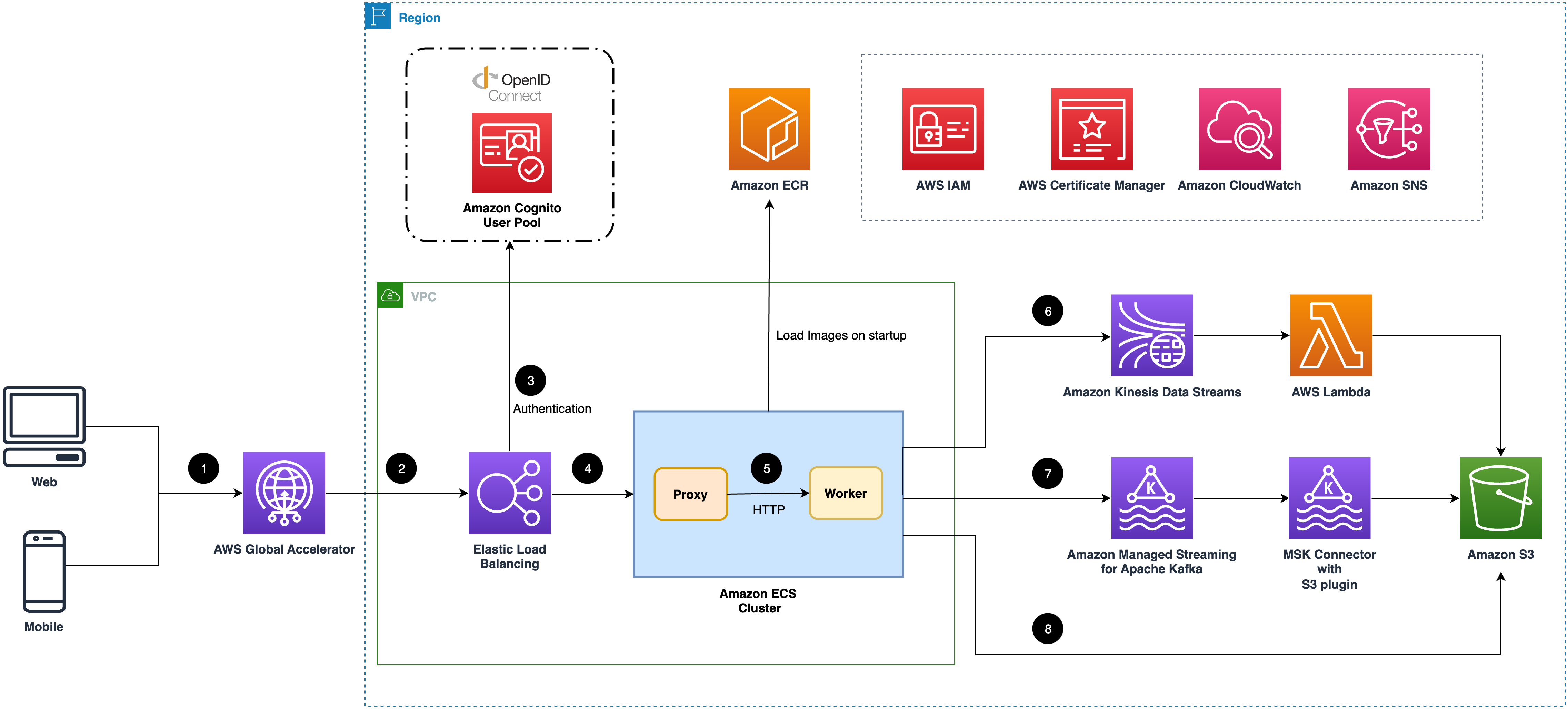
假设您在解决方案中创建了一个数据管道。此解决方案在您的账户中部署 Amazon CloudFormation 模板并完成以下设置。
注意
摄取模块支持三种类型的数据宿。
- (可选)摄取模块创建全球加速器终端节点,以减少从客户端(Web 应用程序或移动应用程序)发送事件的延迟。
- Elastic Load Balancing (ELB) 使用ALB用于负载平衡摄取 Web 服务器。
- (可选)如果您启用身份验证功能,ALB 将与 OIDC 提供商通信以对请求进行身份验证。
- ALB 将所有经过身份验证的有效请求转发到摄取服务器。
- Amazon ECS 集群托管着摄取服务器集群。每台服务器都由一个代理和一个工作器服务组成。代理是基于 HTTP 协议的交互组件,工作器程序将根据您的选择将事件发送到数据宿。
- Amazon Kinesis Data Streams 用作缓冲区。AWS Lambda 消费 Kinesis Data Streams 中的事件,然后将它们分批发送到 Amazon S3。
- Amazon MSK 作为缓冲区。MSK Connector 配置了 S3 连接器插件,该插件将事件批量发送到 Amazon S3。
- 摄取服务器将缓存一批事件,并将它们发送到 Amazon S3。
数据处理模块

假设您在解决方案中创建了数据管道并启用 ETL。此解决方案在您的云账户中部署 Amazon CloudFormation 模板并完成以下设置。
- Amazon EventBridge 用于定期触发 ETL 任务。
- 可配置的基于时间的调度程序调用 AWS Lambda 函数。
- Lambda 函数将启动基于 Spark 的 EMR Serverless 应用程序,以处理一批点击流事件。
- EMR Serverless 应用程序使用可配置的转换器和插件来处理来自源 S3 存储桶的点击流事件。
- 处理点击流事件后,EMR Serverless 应用程序会将处理过的事件汇入 S3 存储桶。
数据建模模块

假设您在解决方案中创建了数据管道并在 Amazon Redshift 中启用了数据建模模块。此解决方案在您的云账户中部署 Amazon CloudFormation 模板并完成以下设置。
- 将经过处理的点击流事件数据写入 Amazon S3 存储桶后,将发出
对象创建事件。 - 在 Amazon EventBridge 中为步骤 1 中触发的事件创建规则,并在事件发生时调用 AWS Lambda 函数。
- Lambda 函数将源事件作为待加载的条目保留在 Amazon DynamoDB 表中。
- 数据处理任务完成后,会向 Amazon EventBridge 发出一个事件。
- Amazon EventBridge 的预定义事件规则处理
EMR 任务成功事件。 - 该规则调用其目标,即 AWS Step Functions 工作流程。
- 工作流程从一个 Lambda 函数开始,该函数查询 DynamoDB 表以找出要加载的数据,然后为一批事件数据创建清单文件以优化加载性能。
- 等待几秒钟后,另一个 Lambda 函数开始检查加载任务的状态。
- 如果加载仍在进行中,则再等待几秒钟后再试。
- 加载所有对象后,工作流程结束。

- 加载数据工作流程完成之后,扫描元数据工作流程将会被触发。
- Lambda 函数检查工作流程是否需要继续。如果与上一次工作流程开启的间隔小于一天或者仍然有之前的工作流程正在运行,则当前工作流程将会被跳过。
- 如果满足继续工作流程的条件,
submit jobLambda 函数将会被触发。 submit jobLambda 函数提交一个扫描元数据的存储过程任务,开启元数据扫描过程。- 等待几秒钟后,
check statusLambda 函数开始检查扫描任务是否完成。 - 如果扫描任务仍然在运行,
check statusLambda 函数则继续等待几秒钟后再试。 - 一旦扫描任务完成,
store metadataLambda 函数将会被触发。 store metadataLambda 函数会将元数据保存到 DynamoDB 表中, 工作流程结束。

假设您在解决方案中创建了数据管道并在 Amazon Athena 中启用了数据建模。此解决方案在您的云账户中部署 Amazon CloudFormation 模板并完成以下设置。
- Amazon EventBridge 定期触发向 Amazon Athena 的数据加载。
- 可配置的基于时间的调度程序调用 AWS Lambda 函数。
- Lambda 函数为处理后的点击流数据创建 AWS Glue 表的分区。
- Amazon Athena 用于交互式查询点击流事件。
- 处理后的点击流数据通过 Glue 表进行扫描。
报表模块

假设您在解决方案中创建了一个数据管道,在 Amazon Redshift 中启用数据建模,然后在 Amazon QuickSight 中启用报表模块。此解决方案在您的云账户中部署 Amazon CloudFormation 模板并完成以下设置。
- Amazon QuickSight 中的 VPC 连接用于在 VPC 内安全地连接 Redshift。
- 数据源、数据集、模板、分析和控制面板均在 Amazon QuickSight 中创建,用于开箱即用的分析和可视化。
分析工作坊
分析工作坊(Analytics Studio)是供业务分析师或数据分析师查看和创建仪表板、查询和探索点击流数据以及管理元数据的统一网页界面。

- 当分析师访问分析工作坊时,请求会发送到 Amazon CloudFront,由其分发网络应用程序。
- 当分析师登录分析工作坊时,请求会重定向到 Amazon Cognito 用户池或 OpenID Connect (OIDC) 进行身份验证。
- Amazon API Gateway 托管后端 API 请求,并使用自定义 Lambda 授权器用 OIDC 的公钥对请求进行授权。
- API Gateway 与 AWS Lambda 集成,为 API 请求提供服务。
- Lambda 函数使用 Amazon DynamoDB 来检索和持久化数据。
- 当分析师创建分析时,Lambda 函数会请求数据管道区域的 Amazon QuickSight 创建资源,并获取嵌入 URL。
- 分析师的浏览器访问 QuickSight 嵌入 URL 以查看 QuickSight 仪表板和图表。