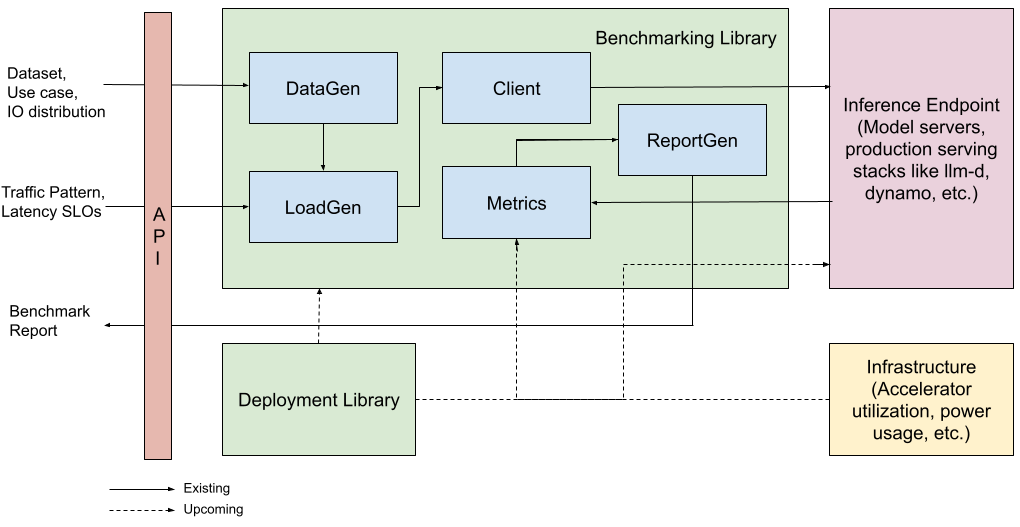
Benchmarking with Inference Perf
To make benchmarking easier and more consistent, the Inference Perf tool provides a standardized way to measure and compare LLM inference performance across different systems.
Inference Perf (GitHub - kubernetes-sigs/inference-perf: GenAI inference performance b...) is an open-source, model-server-agnostic tool for benchmarking GenAI inference workloads. It enables apples-to-apples comparisons across GPUs, CPUs, and custom accelerators, making benchmarking self-hosted LLMs easier and more consistent. The tool supports real-world and synthetic datasets, multiple APIs and model servers (including vLLM, SGLang, and TGI), and large deployments with frameworks like llm-d, Dynamo, and Inference Gateway.
Users can define input/output distributions (Gaussian, fixed-length, min-max) and simulate different load patterns, such as burst traffic, saturation, or autoscaling scenarios. Part of the wg-serving standardization effort, Inference Perf collects metrics like Time to First Token, Intertoken Latency, and Tokens per Second, helping teams compare performance, throughput, and cost efficiency across systems, moving from guesswork to data-driven decisions.