Inference Perf로 벤치마킹하기
벤치마킹을 더 쉽고 일관되게 만들기 위해 Inference Perf 도구는 다양한 시스템에서 LLM 추론 성능을 측정하고 비교하는 표준화된 방법을 제공합니다.
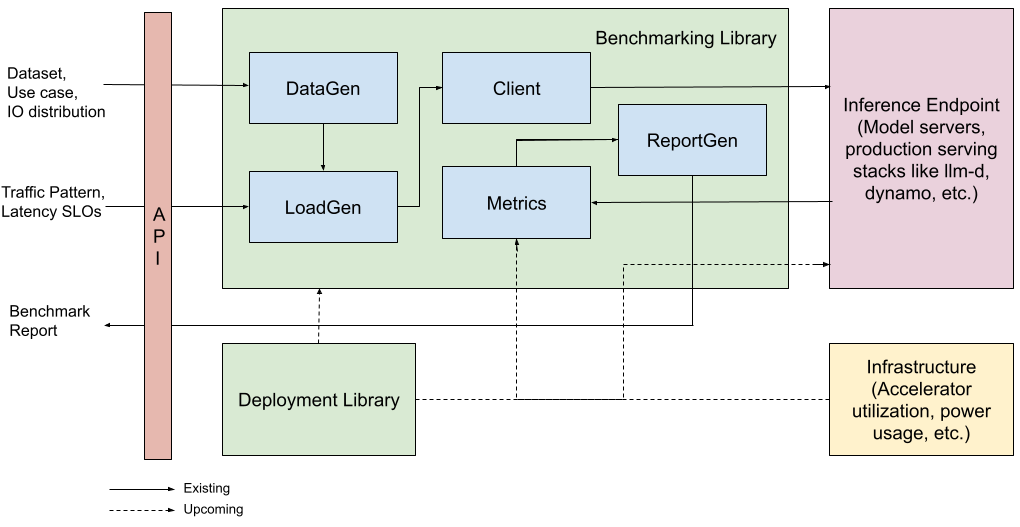
Inference Perf (GitHub - kubernetes-sigs/inference-perf: GenAI inference performance b...)는 GenAI 추론 워크로드 벤치마킹을 위한 오픈 소스, 모델 서버 불가지론적 도구입니다. GPU, CPU 및 맞춤형 가속기 간의 동일 조건 비교를 가능하게 하여 셀프 호스팅 LLM의 벤치마킹을 더 쉽고 일관되게 만듭니다. 이 도구는 실제 및 합성 데이터셋, 여러 API와 모델 서버(vLLM, SGLang, TGI 포함), llm-d, Dynamo, Inference Gateway와 같은 프레임워크를 사용한 대규모 배포를 지원합니다.
사용자는 입력/출력 분포(가우시안, 고정 길이, 최소-최대)를 정의하고 버스트 트래픽, 포화 또는 오토스케일링 시나리오와 같은 다양한 부하 패턴을 시뮬레이션할 수 있습니다. wg-serving 표준화 노력의 일부인 Inference Perf는 Time to First Token, Intertoken Latency, Tokens per Second와 같은 메트릭을 수집하여 팀이 시스템 간의 성능, 처리량 및 비용 효율성을 비교하고 추측에서 데이터 기반 결정으로 이동할 수 있도록 도와줍니다.