AI를 위한 네트워킹
VPC 및 IP 고려 사항
EKS 클러스터에서 대량의 IP 주소 사용을 계획하십시오.
AWS VPC CNI는 Pod에 할당할 IP 주소의 "웜 풀"을 EKS 워커 노드에 유지합니다. Pod에 더 많은 IP 주소가 필요할 때 CNI는 EC2 API와 통신하여 노드에 주소를 할당해야 합니다. 높은 변동성 또는 대규모 스케일 아웃 기간 동안 이�러한 EC2 API 호출이 속도 제한을 받아 Pod 프로비저닝이 지연되고 결과적으로 워크로드 실행이 지연될 수 있습니다. 환경을 위한 VPC를 설계할 때 이 웜 풀을 수용하기 위해 Pod만을 위한 것보다 더 많은 IP 주소를 계획하십시오.
기본 VPC CNI 구성에서는 더 큰 노드가 더 많은 IP 주소를 소비합니다. 예를 들어 10개의 Pod를 실행하는 m5.8xlarge 노드는 총 60개의 IP를 보유합니다(WARM_ENI=1을 충족하기 위해). m5.16xlarge 노드는 100개의 IP를 보유합니다. VPC CNI를 구성하여 이 웜 풀을 최소화하면 노드에서의 EC2 API 호출이 증가하고 속도 제한 위험이 높아질 수 있습니다. 이러한 추가 IP 주소 사용을 계획하면 속도 제한 문제와 IP 주소 사용 관리를 피할 수 있습니다.
IP 공간이 제한된 경우 보조 CIDR 사용을 고려하십시오.
여러 연결된 VPC 또는 사이트에 걸친 네트워크로 작업하는 경우 라우팅 가능한 주소 공간이 제한될 수 있습니다. 예를 들어 VPC가 아래와 같이 작은 서브넷으로 제한될 수 있습니다. 이 VPC에서는 CNI 구성을 조정하지 않고는 m5.16xlarge 노드를 하나 이상 실행할 수 없습니다.
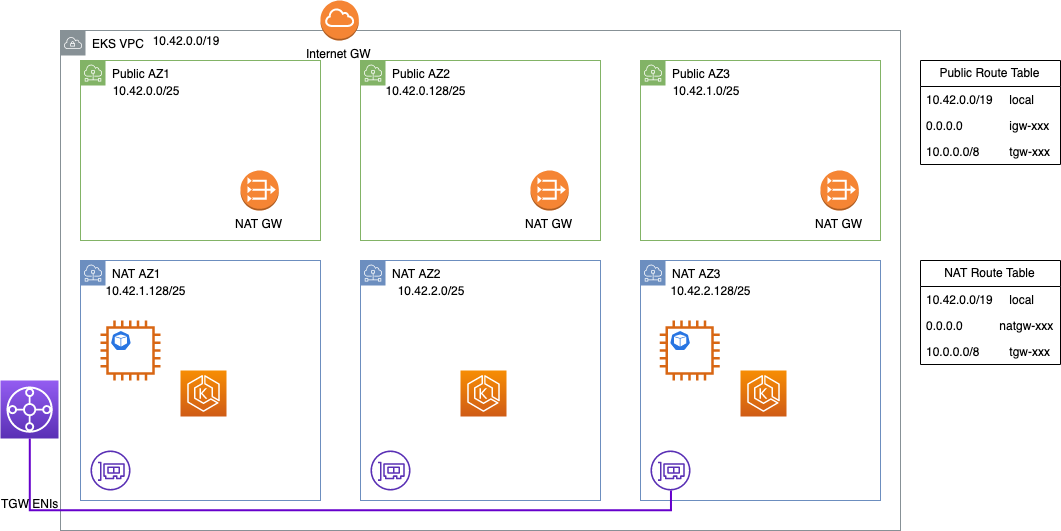
VPC 간에 라우팅할 수 없는 범위(예: RFC 6598 범위, 100.64.0.0/10)에서 추가 VPC CIDR을 추가할 수 있습니다. 이 경우 100.64.0.0/16, 100.65.0.0/16, 100.66.0.0/16을 VPC에 추가한 다음(최대 CIDR 크기이므로) 해당 CIDR로 새 서브넷을 생성했습니다. 기존 EKS 클러스터 컨트롤 플레인은 그대로 두고 노드 그룹을 새 서브넷에 다시 생성했습니다.
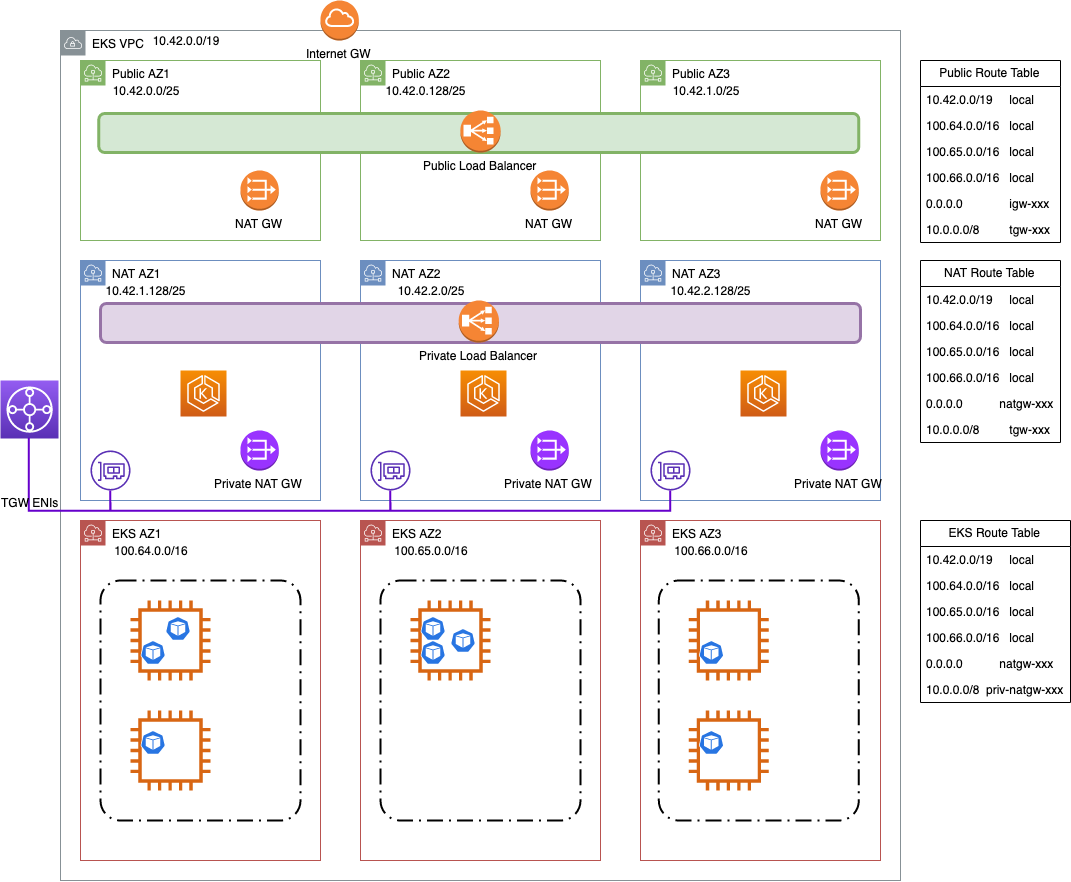
이 구성을 사용하면 연결된 VPC에서 EKS 클러스터 컨트롤 플레인과 계속 통신할 수 있지만 노드와 Pod는 워크로드와 웜 풀을 수용할 충분한 IP 주소를 갖게 됩니다.
VPC CNI 튜닝
VPC CNI 및 EC2 속도 제한
EKS 워커 노드가 시작되면 처음에는 EC2 인스턴스 통신을 위한 단일 IP 주소가 있는 단일 ENI가 연결됩니다. VPC CNI가 시작되면 Kubernetes Pod에 할당할 수 있는 IP 주소의 웜 풀을 프로비저닝하려고 합니다(EKS 모범 사례 가이드에서 자세한 내용 확인).
VPC CNI는 워커 노��드에 추가 IP와 ENI를 할당하기 위해 AWS EC2 API 호출(예: AssignPrivateIpV4Address 및 DescribeNetworkInterfaces)을 수행해야 합니다. EKS 클러스터가 노드 또는 Pod 수를 스케일 아웃할 때 이러한 EC2 API 호출이 급증할 수 있습니다. 이러한 호출 급증은 서비스 성능을 돕고 모든 Amazon EC2 고객에게 공정한 사용을 보장하기 위해 EC2 API에서 속도 제한을 받을 수 있습니다. 이 속도 제한으로 인해 CNI가 더 많은 IP를 할당하려고 시도하는 동안 IP 주소 풀이 고갈될 수 있습니다.
이러한 실패는 아래와 같은 오류를 발생시키며, VPC CNI가 IP 주소를 프로비저닝할 수 없어 컨테이너 네트워크 네임스페이스 프로비저닝이 실패했음을 나타냅니다.
Failed to create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container "xxxxxxxxxxxxxxxxxxxxxx" network for pod "test-pod": networkPlugin cni failed to set up pod test-pod_default" network: add cmd: failed to assign an IP address to container
이 실패는 Pod 시작을 지연시키고 IP 주소가 할당될 때까지 이 작업이 재시도되면서 kubelet과 워커 노드에 압력을 가합니다. 이 지연을 피하기 위해 필요한 EC2 API 호출 수를 줄이도록 CNI를 구성할 수 있습니다.
대규모 클러스��터 또는 변동이 많은 클러스터에서 WARM_IP_TARGET 사용을 피하십시오
WARM_IP_TARGET은 작은 클러스터 또는 Pod 변동이 매우 낮은 클러스터에서 "낭비되는" IP를 제한하는 데 도움이 될 수 있습니다. 그러나 VPC CNI의 이 환경 변수는 대규모 클러스터에서 EC2 API 호출 수를 증가시켜 속도 제한의 위험과 영향을 높일 수 있으므로 신중하게 구성해야 합니다.
Pod 변동이 많은 클러스터의 경우 각 노드에서 실행할 예상 Pod 수보다 약간 높은 값으로 MINIMUM_IP_TARGET을 설정하는 것이 좋습니다. 이렇게 하면 CNI가 단일(또는 소수의) 호출로 모든 IP 주소를 프로비저닝할 수 있습니다.
[...
]
# EKS Addons
cluster_addons = {
vpc-cni = {
configuration_values = jsonencode({
env = {
MINIMUM_IP_TARGET = "30"
}
})
}
}
[...]
대형 인스턴스 유형에서 MAX_ENI 및 max-pods로 노드당 IP 수를 제한하십시오
16xlarge 또는 24xlarge와 같은 대형 인스턴스 유형을 사용할 때 ENI당 할당할 수 있는 IP 주소 수가 상당히 클 수 있습니다. 예를 들어, 기본 CNI 구성 WARM_ENI=1을 사용하는 c5.18xlarge 인스턴스 유형은 소수의 Pod를 실행할 때 100개의 IP 주소(ENI당 50개 IP * 2개 ENI)를 보유하게 됩니다.
일부 워크로드의 경우 CPU, 메모리 또는 기타 리소스가 50개 이상의 IP가 필요하기 전에 해당 c5.18xlarge의 Pod 수를 제한합니다. 이 경우 해당 인스턴스에서 최대 30-40개의 Pod를 실행할 수 있기를 원할 수 있습니다.
[...
]
# EKS Addons
cluster_addons = {
vpc-cni = {
configuration_values = jsonencode({
env = {
MAX_ENI = "1"
}
})
}
}
[...]
CNI에 MAX_ENI=1 옵션을 설정하면 각 노드가 프로비저닝할 수 있는 IP 주소 수가 제한되지만 kubernetes가 노드에 스케줄링하려는 Pod 수는 제한되지 않습니다. 이로 인해 더 많은 IP 주소를 프로비저닝할 수 없는 노드에 Pod가 스케줄링되는 상황이 발생할 수 있습니다.
IP를 제한하고 k8s가 너무 많은 Pod를 스케줄링하지 않도록 하려면 다음을 수행해야 합니다:
- CNI 구성 환경 변수를 업데이트하여
MAX_ENI=1설정 - 워커 노드의 kubelet에서
--max-pods옵션 업데이트
--max-pods 옵션을 구성하려면 워커 노드의 userdata를 업데이트하여 bootstrap.sh 스크립트의 --kubelet-extra-args를 통해 이 옵션을 설정할 수 있습니다. 이 스크립트는 kubelet의 max-pods 값을 구성하며, --use-max-pods false 옵션은 자체 값을 제공할 때 이 동작을 비활성화합니다:
eks_managed_node_groups = {
system = {
instance_types = ["m5.xlarge"]
min_size = 0
max_size = 5
desired_size = 3
pre_bootstrap_user_data = <<-EOT
EOT
bootstrap_extra_args = "--use-max-pods false --kubelet-extra-args '--max-pods=<your_value>'"
}
한 가지 문제는 ENI당 IP 수가 인스턴스 유형에 따라 다르다는 것입니다(예를 들어 m5d.2xlarge는 ENI당 15개 IP를 가질 수 있고 m5d.4xlarge는 ENI당 30개 IP를 보유할 수 있습니다). 이는 max-pods에 대한 값을 하드코딩하면 인스턴스 유형을 변경하거나 혼합 인스턴스 환경에서 문제가 발생할 수 있음을 의미합니다.
EKS 최적화 AMI 릴리스에는 AWS 권장 max-pods 값을 계산하는 데 사용할 수 있는 스크립트가 포함되어 있습니다. 혼합 인스턴스에 대해 이 계산을 자동화하려면 인스턴스 메타데이터에서 인스턴스 유형을 자동 검색하기 위해 --instance-type-from-imds 플래그를 사용하도록 인스턴스의 userdata도 업데이트해야 합니다.
eks_managed_node_groups = {
system = {
instance_types = ["m5.xlarge"]
min_size = 0
max_size = 5
desired_size = 3
pre_bootstrap_user_data = <<-EOT
/etc/eks/max-pod-calc.sh --instance-type-from-imds —cni-version 1.13.4 —cni-max-eni 1
EOT
bootstrap_extra_args = "--use-max-pods false --kubelet-extra-args '--max-pods=<your_value>'"
}
Karpenter를 사용한 Maxpods
기본적으로 Karpenter가 프로비저닝한 노드는 노드 인스턴스 유형에 따라 노드의 최대 Pod 수를 갖습니다. 위에서 언급한 --max-pods 옵션을 구성하려면 Provisioner 수준에서 .spec.kubeletConfiguration 내에 maxPods를 지정하여 정의합니다. 이 값은 Karpenter Pod 스케줄링 중에 사용되고 kubelet 시작 시 --max-pods로 전달됩니다.
아래는 예제 Provisioner 사양입니다:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
providerRef:
name: default
requirements:
- key: "karpenter.k8s.aws/instance-category"
operator: In
values: [ "c", "m", "r" ]
- key: "karpenter.sh/capacity-type" # If not included, the webhook for the AWS cloud provider will default to on-demand
operator: In
values: [ "spot", "on-demand" ]
# Karpenter provides the ability to specify a few additional Kubelet args.
# These are all optional and provide support for additional customization and use cases.
kubeletConfiguration:
maxPods: 30
애플리케이션
DNS 조회 및 ndots
기본 DNS 구성을 사용하는 Kubernetes Pod에는 다음과 같은 resolv.conf 파일이 있습니다:
nameserver 10.100.0.10
search namespace.svc.cluster.local svc.cluster.local cluster.local ec2.internal
options ndots:5
search 줄에 나열된 도메인 이름은 완전한 도메인 이름(FQDN)이 아닌 DNS 이름에 추가됩니다. 예를 들어, Pod가 servicename.namespace를 사용하여 Kubernetes 서비스에 연결하려고 하면 DNS 이름이 전체 kubernetes 서비스 이름과 일치할 때까지 도메인이 순서대로 추가됩니다:
servicename.namespace.namespace.svc.cluster.local <--- Fails with NXDOMAIN
servicename.namespace.svc.cluster.local <-- Succeed
도메인이 완전한지 여부는 resolv.conf의 ndots 옵션에 의해 결정됩니다. 이 옵션은 search 도메인을 건너뛰기 전에 도메인 이름에 있어야 하는 점의 수를 정의합니다. 이러한 추가 검색은 S3 및 RDS 엔드포인트와 같은 외부 리소스에 대한 연결에 지연을 추가할 수 있습니다.
Kubernetes의 기본 ndots 설정은 5입니다. 애플리케이션이 클러스터의 다른 Pod와 통신하지 않는 경우 ndots를 "2"와 같은 낮은 값으로 설정할 수 있습니다. 이는 좋은 시작점입니다. 왜냐하면 애플리케이션이 동일한 네임스페이스 내에서 그리고 클러스터 내의 다른 네임스페이스에서 서비스 검색을 수행할 수 있도록 하면서도 s3.us-east-2.amazonaws.com과 같은 도메인을 FQDN으로 인식(search 도메인 건너뛰기)할 수 있게 해주기 때문입니다.
다음은 Kubernetes 문서에서 ndots가 "2"로 설정된 예제 Pod 매니페스트입니다:
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: dns-example
spec:
containers:
- name: test
image: nginx
dnsConfig:
options:
- name: ndots
value: "2"
Pod 배포에서 ndots를 "2"로 설정하는 것은 합리적인 시작점이지만 모든 상황에서 보편적으로 작동하지는 않으며 전체 클러스터에 적용해서는 안 됩니다. ndots 구성은 Pod 또는 Deployment 수준에서 구성해야 합니다. 클러스터 수준 CoreDNS 구성에서 이 설정을 줄이는 것은 권장되지 않습니다.
AZ 간 네트워크 최적화
일부 워크로드는 다중 노드 추론, 다중 노드 훈련 또는 다중 복제본 추론과 같이 클러스터의 Pod 간에 데이터를 교환해야 할 수 있습니다. Pod가 여러 가용 영역(AZ)에 분산되어 있으면 AZ 간 이그레스로 인해 추가 비용이 발생할 수 있습니다. 이러한 워크로드의 경우 Pod를 동일한 AZ에 배치하는 것이 좋습니다. Pod를 동일한 AZ에 같은 위치에 배치하면 두 가지 주요 목적을 달성합니다:
- AZ 간 트래픽 비용 절감
- 실행기/Pod 간 네트워크 지연 시간 감소
Pod를 동일한 AZ에 배치하기 위해 podAffinity 기반 스케줄링 제약 조건을 사용할 수 있습니다. 스케줄링 제약 조건 preferredDuringSchedulingIgnoredDuringExecution은 Pod 사양에서 적용할 수 있습니다. 예를 들어, Spark에서는 드라이버 및 실행기 Pod에 대한 사용자 정의 템플릿을 사용할 수 있습니다:
spec:
executor:
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
topologyKey: topology.kubernetes.io/zone
labelSelector:
matchLabels:
"ray.io/cluster": "ray-cluster-name"
...
Pod가 생성된 후 Kubernetes Topology Aware Routing을 활용하여 Kubernetes 서비스가 더 효율적인 방식으로 트래픽을 라우팅하도록 할 수도 있습니다: https://aws.amazon.com/blogs/containers/exploring-the-effect-of-topology-aware-hints-on-network-traffic-in-amazon-elastic-kubernetes-service/
모든 실행기를 단일 AZ에 배치하면 해당 AZ가 단일 장애 지점이 됩니다. 이는 네트워크 비용과 지연 시간을 낮추는 것과 AZ 장애로 인한 워크로드 중단 이벤트 사이의 트레이드오프로 고려해야 합니다. 워크로드가 제한된 용량의 인스턴스에서 실행되는 경우 용량 부족 오류를 피하기 위해 여러 AZ를 사용하는 것을 고려할 수 있습니다.
inference-charts를 사용하는 경우, 처리량을 높이고 비용을 줄이기 위해 토폴로지 인식이 기본적으로 활성화됩니다. inference.modelServer.deployment.topologySpreadConstraints.enabled: false 및 inference.modelServer.deployment.podAffinity.enabled: false를 설정하여 비활성화할 수 있습니다.