Amazon EKS에서 AI/ML 추론 애플리케이션의 콜드 스타트 문제 해결
이 가이드는 관찰된 패턴에 따라 정기적으로 업데이트됩니다. 새로운 콘텐츠가 추가되고 기존 콘텐츠가 변경될 수 있습니다.
콜드 스타트 과제
AI/ML 추론 애플리케이션의 컨테이너화를 통해 조직은 변동하는 수요를 처리하기 위한 Kubernetes의 자동 스케일링, 고가의 GPU 하드웨어를 관리하기 위한 통합 리소스 오케스트레이션, 배포 파이프라인과 운영을 단순화하기 위한 선언적 구성을 활용할 수 있습니다.
Kubernetes는 애플리케이션 실행을 더 쉽게 만드는 많은 이점을 제공하지만, 애플리케이션 콜드 스타트는 여전히 과제입니다.
허용 가능한 시작 시간은 AI/ML 추론 애플리케이션마다 다르지만, 수십 초에서 수 분의 지연은 시스템 전체에 연쇄 효과를 일으켜 사용자 경험, 애플리케이션 성능, 운영 효율성, 인프라 비용 및 출시 시간에 영향을 미칩니다.
주요 영향은 다음과 같습니다:
- 요청 지연 시간 증가 및 사용자 경험 저하
- 유휴 상태의 고가 GPU 리소스
- 트래픽 급증 시 오토스케일링 프로세스의 응답성 감소
- 배포, 실험, 테스트 및 디버깅 중 긴 피드백 루프
이 가이드의 솔루션을 효과적으로 평가하고 구현하려면 애플리케이션 컨테이너 시작 시간에 기여하는 여러 복합 요인을 개략적으로 설명하고 나중에 더 자세히 살펴보는 것이 중요합니다:
- 애플리케이션을 호스팅하기 위한 컴퓨팅 용량(예: Amazon EC2 인스턴스)의 프로비저닝 및 부트스트래핑
- 일반적으로 큰 컨테이너 이미지와 모델 아티팩트 다운로드
가이드의 나머지 부분에서는 Amazon Elastic Kubernetes Service(Amazon EKS)에 배포된 애플리케이션을 위한 이러한 요인에 대한 권장 패턴과 솔루션을 살펴봅니다.
각 솔루션은 다음 측면을 다루는 구현 가이드를 제공합니다:
- 권장되는 AWS 및 Kubernetes 아키텍처에 대한 심층 논의
- 코드 예제와 함께 구현 세부 정보
- 주요 목적에 도움이 되는 방법
- 다른 솔루션과의 추가적인 잠재적 이점 및 통합
- 고려해야 할 트레이드오프
컨테이너 시작 시간 개선
컨테이너 이미지 풀 시간은 AI/ML 추론 애플리케이션의 시작 지연에 주요 기여 요인입니다. 이러한 애플리케이션은 프레임워크 종속성(예: PyTorch 또는 TensorFlow), 런타임(예: TorchServe, Triton 또는 Ray Serve), 번들된 모델 파일 및 관련 아티팩트의 포함으로 인해 여러 기가바이트 크기에 도달할 수 있습니다.
이 섹션에서는 다음 솔루션에 집중합니다:
- 이미지의 전체 크기 줄이기
- 컨테이너 이미지 풀 프로세스를 더 효율적으로 만들기
솔루션과 그 트레이드오프를 살펴볼 때, 그림 1의 다이어그램에 표시된 것처럼 AI/ML 추론 애플리케이션 컨테이너를 만드는 데 들어가는 다양한 레이어와 구성 요소를 참조할 것입니다.
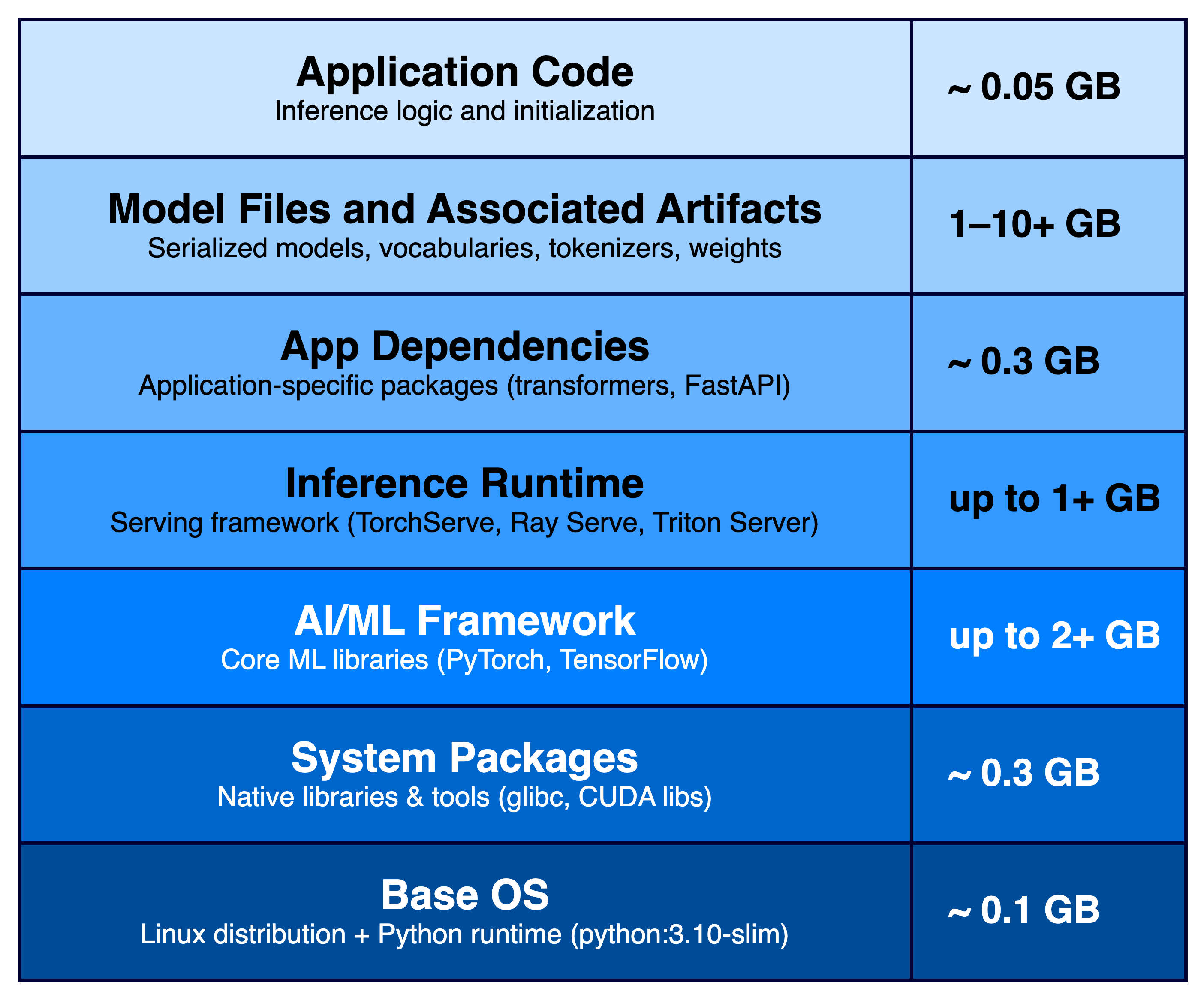 그림 1: AI/ML 추론 애플리케이션 컨테이너 이미지 레이어
그림 1: AI/ML 추론 애플리케이션 컨테이너 이미지 레이어
다이어그램에서 하위 레이어는 이미 상위 레이어의 아티팩트를 포함할 수 있습니다(예: pytorch/pytorch 기본 OS 이미지에 번들되어 있고 별도로 설치되지 않은 PyTorch AI/ML 프레임워크 및 추론 런타임 구성 요소). 이는 최적화를 단순화하거나 복잡하게 만들 수 있습니다.