Envoy gateway
AI 애플리케이션을 배포하는 조직은 근��본적인 과제에 직면합니다: 단일 모델로는 모든 요구사항을 충족할 수 없습니다. 개발자는 긴 컨텍스트 분석에는 Claude를, 추론 작업에는 OpenAI를, 비용에 민감한 워크로드에는 DeepSeek를 선택할 수 있습니다. 문제는 각 모델 제공자가 서로 다른 API를 사용한다는 것입니다. 중앙 집중식 제어가 없으면 팀은 쉽게 제공자를 전환하거나, 활용률에 대한 가시성을 확보하거나, 할당량을 적용할 수 없습니다.
Envoy AI Gateway는 지원되는 여러 LLM 제공자로 라우팅하는 단일 확장 가능한 OpenAI 호환 엔드포인트를 제공하여 이 과제를 해결하는 오픈소스 프로젝트입니다. 플랫폼 팀에게 비용 제어와 관측성을 제공하고, 개발자는 제공자별 SDK를 건드릴 필요가 없습니다.
Envoy AI Gateway의 주요 목표
- LLM/AI 트래픽의 라우팅 및 관리를 위한 통합 레이어 제공
- 서비스 안정성을 보장하기 위한 자동 페일오버 메커니즘 지원
- LLM/AI 트래픽에 대한 업스트림 인증을 포함한 엔드투엔드 보안 보장
- 사용량 제한 사용 사례를 지원하기 위한 정책 프레임워크 구현
- GenAI 관련 라우팅 및 서비스 품질 요구사항을 해결하기 위한 오픈소스 커뮤니티 육성
Envoy Gateway 기본 사항
Envoy AI Gateway는 표준 Kubernetes Gateway API와 Envoy Gateway 확장을 기반으로 하므로 기본 Envoy Gateway 프리미티브를 숙지해야 합니다:
- GatewayClass - Gateway를 관리하는 컨트롤러를 정의합니다. Envoy AI Gateway는 Envoy Gateway와 동일한 GatewayClass를 사용합니다.
- Gateway - 트래픽의 진입점입니다. Gateway 리소스는 리스너(HTTP/HTTPS 포트)를 정의합니다. Gateway를 생성하면 Envoy Gateway가 실제 Envoy 프록시 파드와 해당 Kubernetes Service(일반적으로 LoadBalancer)를 배포합니다. 이는 Network Load Balancer와 유사합니다(기술적으로 Kubernetes 클러스터 외부의 트래픽을 수락하려면 Envoy Gateway에 NLB를 연결해야 하지만).
- HTTPRoute - 호스트명, 경로 또는 헤더를 기반으로 HTTP 트래픽을 라우팅하는 지침입니다. 개념적으로 ALB의 인그레스 규칙 또는 리스너 규칙과 유사합니다.
- Backend - Kubernetes Service 또는 외부 엔드포인트입니다.
- BackendTrafficPolicy - HTTPRoute의 타임아웃, 재시도, 속도 제한과 같은 연결 동작을 구성합니다.
- ClientTrafficPolicy - Envoy 프록시 서버가 다운스트림 클라이언트와 작동하는 방식을 구성합니다.
- EnvoyExtensionPolicy - Envoy의 트래픽 처리 기능을 확장하는 방법입니다.
Envoy AI Gateway는 다음 CRD를 도입합니다:
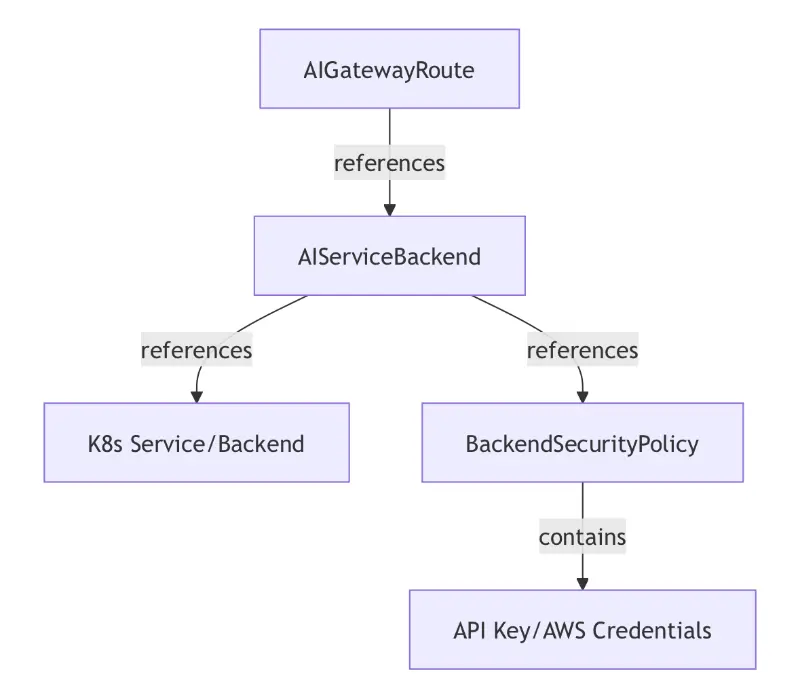
- AIGatewayRoute - AI 트래픽에 대한 통합 API 및 라우팅 규칙을 정의합니다
- AIServiceBackend - Bedrock과 같은 개별 AI 서비스 백엔드를 나타냅니다
- BackendSecurityPolicy - 백엔드 접근에 대한 인증을 구성합니다
- BackendTLSPolicy - 백엔드 연결에 대한 TLS 파라미터를 정의합니다
이 envoy gateway 블루프린트는 Amazon EKS에 Envoy AI Gateway를 배포하고 두 가지 사용 사례를 지원합니다:
- 다중 모델 라우팅
- 속도 제한
솔루션 배포
👈셀프 호스팅 모델 배포
Envoy AI gateway는 현재 OpenAI API 스키마를 사용할 수 있는 셀프 호스팅 모델을 지원합니다. AI on EKS Inference Charts를 사용하여 두 개의 모델을 배포합니다.
1. Hugging Face 토큰 시크릿 생성
Hugging Face 토큰으로 Kubernetes 시크릿을 생성합니다:
kubectl create secret generic hf-token --from-literal=token=your_huggingface_token
2. 사전 구성된 모델 배포
사용 가능한 사전 구성된 모델 중에서 선택하여 배포합니다:
이러한 배포에는 활성화해야 하는 GPU/Neuron 리소스가 필요하며 CPU 전용 인스턴스보다 비용이 더 많이 듭니다.
# helm 차트 저장소 추가
helm repo add ai-on-eks https://awslabs.github.io/ai-on-eks-charts/
helm repo update
# 모델 1: qwen3 모델 배포
helm install qwen3-1.7b ai-on-eks/inference-charts -f https://raw.githubusercontent.com/awslabs/ai-on-eks-charts/refs/heads/main/charts/inference-charts/values-qwen3-1.7b-vllm.yaml \
--set nameOverride=qwen3 \
--set fullnameOverride=qwen3 \
--set inference.serviceName=qwen3
# 모델 2: gpt oss 모델 배포
helm install gpt-oss ai-on-eks/inference-charts -f https://raw.githubusercontent.com/awslabs/ai-on-eks-charts/refs/heads/main/charts/inference-charts/values-gpt-oss-20b-vllm.yaml \
--set nameOverride=gpt-oss \
--set fullnameOverride=gpt-oss \
--set inference.serviceName=gpt-oss
모델이 실행 중인지 확인
kubectl get pod
NAME READY STATUS RESTARTS AGE
gpt-oss-67c5bcdd5c-lx9vh 1/1 Running 0 44h
qwen3-b5fdf6bd5-cxkwd 1/1 Running 0 44h
AWS Bedrock 모델에 대한 접근 활성화
모든 Amazon Bedrock 파운데이션 모델에 대한 접근은 올바른 AWS Marketplace 권한이 있으면 기본적으로 활성화됩니다. Amazon Bedrock의 모델 접근 관리에 대한 자세한 내용은 Amazon Bedrock 파운데이션 모델에 접근을 검토하세요.
Model ID를 포함한 관련 모델 정보와 Amazon Bedrock을 통해 사용 가능한 파운데이션 모델 목록은 Amazon Bedrock에서 지원되는 파운데이션 모델을 검토하세요.
다중 모델 라우팅
x-ai-eg-model 헤더를 기반으로 다른 AI 모델로 요청을 라우팅합니다. 이 헤더를 통해 Envoy AI gateway는 게이트웨이 내에 구성된 적절한 라우트를 식별하고 클라이언트 트래픽을 관련 백엔드 kubernetes 서비스로 라우팅합니다. 이 경우 셀프 호스팅 모델 또는 Amazon Bedrock 모델을 노출하는 서비스입니다.
공통 게이트웨이 인프라 배포
cd ../../blueprints/gateways/envoy-ai-gateway
kubectl apply -f gateway.yaml
serviceaccount/ai-gateway-dataplane-aws created
gatewayclass.gateway.networking.k8s.io/envoy-gateway created
envoyproxy.gateway.envoyproxy.io/ai-gateway created
gateway.gateway.networking.k8s.io/ai-gateway created
clienttrafficpolicy.gateway.envoyproxy.io/ai-gateway-buffer-limit created
모델 백엔드 구성
kubectl apply -f model-backends.yaml
backend.gateway.envoyproxy.io/gpt-oss-backend created
aiservicebackend.aigateway.envoyproxy.io/gpt-oss created
backend.gateway.envoyproxy.io/qwen3-backend created
aiservicebackend.aigateway.envoyproxy.io/qwen3 created
backend.gateway.envoyproxy.io/bedrock-backend created
aiservicebackend.aigateway.envoyproxy.io/bedrock created
backendsecuritypolicy.aigateway.envoyproxy.io/bedrock-policy created
backendtlspolicy.gateway.networking.k8s.io/bedrock-tls created
모델 라우트 구성
kubectl apply -f multi-model-routing/ai-gateway-route.yaml
aigatewayroute.aigateway.envoyproxy.io/multi-model-route created
테스트
python3 multi-model-routing/client.py
예상 출력:
🚀 AI Gateway Multi-Model Routing Test
============================================================
Gateway URL: http://k8s-envoygat-envoydef-xxxxxxxxxx-xxxxxxxxxxxxxxxx.elb.us-west-2.amazonaws.com
=== Testing Qwen3 1.7B ===
Status Code: 200
✅ SUCCESS: Qwen3 - [response content]
=== Testing Self-hosted GPT ===
Status Code: 200
✅ SUCCESS: GPT - [response content]
=== Testing Bedrock Claude ===
Status Code: 200
✅ SUCCESS: Bedrock Claude - [response content]
🎯 Final Results:
• Qwen3 1.7B: ✅ PASS
• GPT OSS 20B: ✅ PASS
• Bedrock Claude: ✅ PASS
📊 Summary: 3/3 models working
속도 제한
AI 워크로드를 위한 자동 추적 기능이 있는 토큰 기반 속도 제한입니다.
기능:
- 토큰 기반 속도 제한 (입력, 출력 및 총 토큰)
x-user-id헤더를 사용한 사용자 기반 속도 제한- 분산 속도 제한을 위한 Redis 백엔드 (자동 배포됨)
- 시간 창당 사용자별 구성 가능한 제한
속도 제한 구성
kubectl apply -f rate-limiting/ai-gateway-route.yaml
kubectl apply -f rate-limiting/ai-gateway-rate-limit.yaml
kubectl apply -f rate-limiting/backend-traffic-policy.yaml
속도 제한 테스트
python3 rate-limiting/client.py
구성 세부 정보
라우팅 구성
AI Gateway는 x-ai-eg-model 헤더를 기반으로 요청을 라우팅합니다:
| 헤더 값 | 백엔드 | 엔드포인트 | 모델 유형 |
|---|---|---|---|
Qwen/Qwen3-1.7B | qwen3 | /v1/chat/completions | 셀프 호스팅 |
openai/gpt-oss-20b | gpt-oss | /v1/chat/completions | 셀프 호스팅 |
anthropic.claude-3-haiku-20240307-v1:0 | bedrock | /anthropic/v1/messages | AWS Bedrock |
Bedrock 통합 세부 정보
- 인증: Pod Identity (설치 스크립트를 통해 자동 구성됨)
- 스키마: 네이티브 Bedrock 지원을 위한 AWSAnthropic
- 엔드포인트:
/anthropic/v1/messages(Anthropic Messages API 형식) - 리전:
backend-security-policy.yaml에서 구성 가능 (기본값: us-west-2)
리소스
중요 참고사항
- 다중 모델 라우팅: 배포된 AI 모델 서비스와 AWS Bedrock 접근 권한 필요
- 속도 제한: 실제 토큰 사용 데이터를 반환하는 실제 AI 모델과 저장을 위한 Redis 필요
- Bedrock 통합: AWS Bedrock API 접근, 적절한 IAM 설정 및 Pod Identity 구성 필요
- 인증: Bedrock용 Pod Identity는 설치 스크립트를 통해 배포할 때 자동으로 구성됨
이것은 실제 AI 모델 배포 및 AWS Bedrock 통합과 함께 AI Gateway 기능을 보여주는 작동하는 구성 예제입니다.