EKS에서 ML 모델을 배포하려면 GPU 또는 Neuron 인스턴스에 대한 접근 권한이 필요합니다. 배포가 작동하지 않는 경우 이러한 리소스에 대한 접근 권한이 없기 때문인 경우가 많습니다. 또한 일부 배포 패턴은 Karpenter 자동 스케일링과 정적 노드 그룹에 의존합니다. 노드가 초기화되지 않으면 Karpenter 또는 노드 그룹의 로그를 확인하여 문제를 해결하세요.
참고: 이 Llama-2 모델의 사용은 Meta 라이선스의 적용을 받습니다. 모델 가중치와 토크나이저를 다운로드하려면 웹사이트를 방문하여 접근 권한을 요청하기 전에 라이선스에 동의해야 합니다.
이 블루프린트는 관측성, 로깅 및 확장성 측면의 개선 사항을 통합하기 위해 적극적으로 개선 중입니다.
Trainium, Neuronx-Nemo-Megatron 및 MPI operator를 사용한 Llama-2 모델 훈련
AWS Trainium, Neuronx-Nemo-Megatron 및 MPI Operator를 사용하여 Amazon Elastic Kubernetes Service (EKS)에서 Meta Llama-2-7b 모델을 훈련하는 종합 가이드에 오신 것을 환영합니다.
이 튜토리얼에서는 Amazon EKS에서 AWS Trainium 가속기를 사용하여 다중 노드 훈련 작업을 실행하는 방법을 배웁니다. 구체적으로 RedPajama 데이터셋의 하위 집합을 사용하여 4개의 AWS EC2 trn1.32xlarge 인스턴스에서 Llama-2-7b를 사전 훈련합니다.
Llama-2란?
Llama-2는 2조 개의 텍스트 및 코드 토큰으로 훈련된 대규모 언어 모델(LLM)입니다. 현재 사용 가능한 가장 크고 강력한 LLM 중 하나입니다. Llama-2는 자연어 처리, 텍스트 생성, 번역 등 다양한 작업에 사용할 수 있습니다.
Llama-2는 사전 훈련된 모델로 제공되지만, 이 튜토리얼에서는 모델�을 처음부터 사전 훈련하는 방법을 보여드립니다.
Llama-2-chat
Llama-2는 엄격한 훈련 과정을 거친 뛰어난 언어 모델입니다. 공개적으로 이용 가능한 온라인 데이터를 사용한 사전 훈련으로 시작합니다.
Llama-2는 세 가지 다른 모델 크기로 제공됩니다:
- Llama-2-70b: 700억 개의 파라미터를 가진 가장 큰 Llama-2 모델입니다. 가장 강력한 Llama-2 모델이며 가장 까다로운 작업에 사용할 수 있습니다.
- Llama-2-13b: 130억 개의 파라미터를 가진 중간 크기의 Llama-2 모델입니다. 성능과 효율성 사이의 좋은 균형을 제공하며 다양한 작업에 사용할 수 있습니다.
- Llama-2-7b: 70억 개의 파라미터를 가진 가장 작은 Llama-2 모델입니다. 가장 효율적인 Llama-2 모델이며 최고 수준의 성능이 필요하지 않은 작업에 사용할 수 있습니다.
어떤 Llama-2 모델 크기를 사용해야 하나요?
최적의 Llama-2 모델 크기는 특정 요구사항에 따라 달라지며, 최고 성능을 달성하기 위해 항상 가장 큰 모델이 필요한 것은 아닙니다. 적절한 Llama-2 모델 크기를 선택할 때 컴퓨팅 리소스, 응답 시간, 비용 효율성과 같은 요소를 평가하고 고려하는 것이 좋습니다. 결정은 애플리케이션의 목표와 제약 조건에 대한 종합적인 평가를 기반으로 해야 합니다.
성능 향상 Llama-2는 GPU에서 고성능 추론을 달성할 수 있지만, Neuron 가속기는 성능을 한 단계 더 끌어올립니다. Neuron 가속기는 머신 러닝 워크로드를 위해 특별히 설계되어 Llama-2의 추론 속도를 크게 향상시키는 하드웨어 가속을 제공합니다. 이는 Trn1/Inf2 인스턴스에서 Llama-2를 배포할 때 더 빠른 응답 시간과 개선된 사용자 경험으로 이어집니다.
솔루션 아키텍처
이 섹션에서는 솔루션의 아키텍처를 자세히 살펴봅니다.
Trn1.32xl 인스턴스: 머신 러닝 훈련 워크로드에 최적화된 EC2 Trn1 (Trainium) 인스턴스 패밀리의 일부인 EC2 가속 인스턴스 유형입니다.
MPI Worker Pods: MPI (Message Passing Interface) 작업을 실행하도록 구성된 Kubernetes 파드입니다. MPI는 분산 메모리 병렬 컴퓨팅을 위한 표준입니다. 각 워커 파드는 16개의 Trainium 가속기와 8개의 Elastic Fabric Adapters (EFA)가 장착된 trn1.32xlarge 인스턴스에서 실행됩니다. EFA는 Amazon EC2 인스턴스에서 실행되는 고성능 컴퓨팅 애플리케이션을 지원하는 네트워크 장치입니다.
MPI Launcher Pod: 워커 파드 전체에서 MPI 작업을 조정하는 역할을 담당하는 파드입니다. 훈련 작업이 클러스터에 처음 제출되면 MPI 런처 파드가 생성되어 워커들이 온라인 상태가 되기를 기다리고, 각 워커에 연결한 다음 훈련 스크립트를 호출합니다.
MPI Operator: Kubernetes에서 오퍼레이터는 Kubernetes 애플리케이션을 패키징, 배포 및 관리하는 방법입니다. MPI Operator는 MPI 워크로드의 배포 및 관리를 자동화합니다.
FSx for Lustre: 머신 러닝, 고성능 컴퓨팅(HPC), 비디오 처리, 금융 모델링과 같은 워크로드에 적합한 공유 고성능 파일 시스템입니다. FSx for Lustre 파일 시스템은 훈련 작업의 워커 파드 간에 공유되어 훈련 데이터에 접근하고 모델 아티팩트 및 로그를 저장하기 위한 중앙 저장소를 제공합니다.
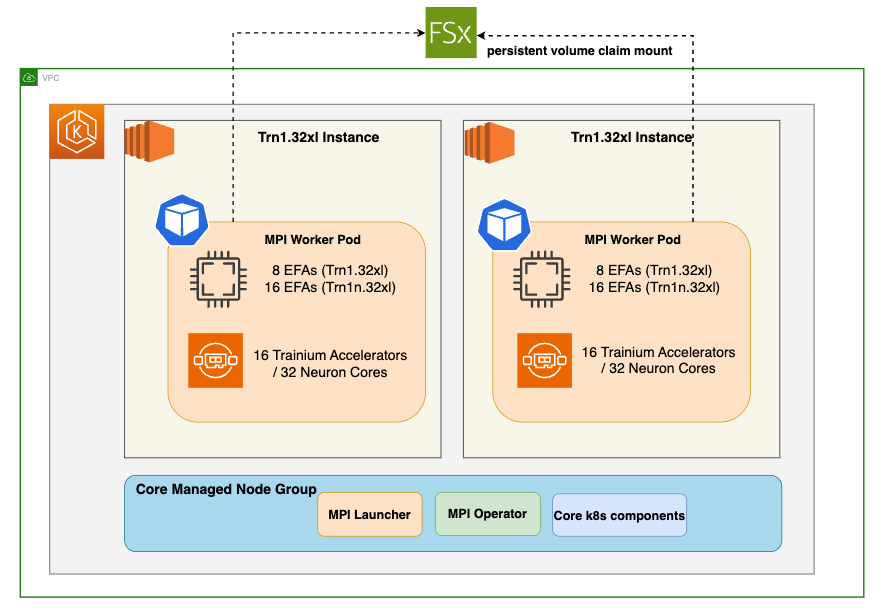
솔루션 배포
Amazon EKS에서 AWS Trainium을 사용하여 Llama-2를 훈련하는 단계
참고: 이 게시물은 Meta의 Llama 토크나이저를 사용하며, 토크나이저 파일을 다운로드하기 전에 수락해야 하는 사용자 라이선스로 보호됩니다. 여기에서 접근 권한을 요청하여 Llama 파일에 대한 접근 권한이 있는지 확인하세요.
사전 요구사항
👈분산 훈련
EKS 클러스터가 배포되면 neuronx-nemo-megatron 컨테이너 이미지를 빌드하고 이미지를 ECR에 푸시하는 다음 단계를 진행할 수 있습니다.
neuronx-nemo-megatron 컨테이너 이미지 빌드
examples/llama2 디렉토리로 이동
cd examples/llama2/
1-llama2-neuronx-pretrain-build-image.sh 스크립트를 실행하여 neuronx-nemo-megatron 컨테이너 이미지를 빌드하고 ECR에 이미지를 푸시합니다.
리전을 입력하라는 메시지가 표시되면 위에서 EKS 클러스터를 시작한 리전을 입력하세요.
./1-llama2-neuronx-pretrain-build-image.sh
참고: 이미지 빌드 및 ECR 푸시에는 약 10분이 소요됩니다
CLI 파드 시작 및 연결
이 단계에서는 공유 FSx 스토리지에 대한 접근이 필요합니다. 이 스토리지에 파일을 복사하려면 먼저 위에서 생성한 neuronx-nemo-megatron Docker 이미지를 실행하는 CLI 파드를 시작하고 연결합니다.
다음 스크립트를 실행하여 CLI 파드를 시작합니다:
./2-launch-cmd-shell-pod.sh
다음으로, CLI 파드가 'Running' 상태가 될 때까지 다음 명령을 주기적으로 실행합니다:
kubectl get pod -w
CLI 파드가 'Running' 상태가 되면 다음 명령을 사용하여 연결합니다:
kubectl exec -it cli-cmd-shell -- /bin/bash
Llama 토크나이저 및 Redpajama 데이터셋을 FSx에 다운로드
CLI 파드 내에서 Llama 토크나이저 파일을 다운로드합니다. 이 파일들은 Meta의 Llama 라이선스로 보호되므로 huggingface-cli login 명령을 실행하여 접근 토큰으로 Hugging Face에 로그인해야 합니다. 접근 토큰은 Hugging Face 웹사이트의 Settings -> Access Tokens에서 찾을 수 있습니다.
huggingface-cli login
토큰을 입력하라는 메시지가 표시되면 접근 토큰을 붙여넣고 ENTER를 누릅니다.
다음으로, 다음 python 코드를 실행하여 llama7-7b 토크나이저 파일을 /shared/llama7b_tokenizer에 다운로드합니다:
python3 <<EOF
import transformers
tok = transformers.AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
tok.save_pretrained("/shared/llama7b_tokenizer")
EOF
다음으로, RedPajama-Data-1T-Sample 데이터셋(10억 개의 토큰을 포함하는 전체 RedPajama 데이터셋의 작은 하위 집합)을 다운로드합니다.
CLI 파드에 연결된 상태에서 git을 사용하여 데이터셋을 다운로드합니다
cd /shared
git clone https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T-Sample \
data/RedPajama-Data-1T-Sample
데이터셋 토큰화
neuronx-nemo-megatron에 포함된 전처리 스크립트를 사용하여 데이터셋을 토큰화합니다. 이 전처리 단계는 trn1.32xl 인스턴스에서 약 60분이 소요됩니다.
cd /shared
# 필요한 스크립트가 포함된 neuronx-nemo-megatron 저장소 클론
git clone https://github.com/aws-neuron/neuronx-nemo-megatron.git
# 개별 redpajama 파일을 단일 jsonl 파일로 결합
cat /shared/data/RedPajama-Data-1T-Sample/*.jsonl > /shared/redpajama_sample.jsonl
# llama 토크나이저를 사용하여 전처리 스크립트 실행
python3 neuronx-nemo-megatron/nemo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py \
--input=/shared/redpajama_sample.jsonl \
--json-keys=text \
--tokenizer-library=huggingface \
--tokenizer-type=/shared/llama7b_tokenizer \
--dataset-impl=mmap \
--output-prefix=/shared/data/redpajama_sample \
--append-eod \
--need-pad-id \
--workers=32
훈련 스크립트에서 데이터셋 및 토크나이저 경로 수정
참고: 나중에 EKS에서 훈련 작업을 시작할 때 훈련 파드는 FSx의 neuronx-nemo-megatron/nemo/examples 디렉토리에서 훈련 스크립트를 실행합니다. 이는 모든 변경 사항에 대해 neuronx-nemo-megatron 컨테이너를 다시 빌드하지 않고도 FSx에서 직접 훈련 스크립트를 수정할 수 있어 편리합니다.
test_llama.sh 스크립트 /shared/neuronx-nemo-megatron/nemo/examples/nlp/language_modeling/test_llama.sh를 수정하여 다음 두 줄을 업데이트합니다. 이 줄들은 훈련 파드 워커에게 FSx 파일 시스템에서 Llama 토크나이저와 데이터셋을 찾을 위치를 알려줍니다.
실행:
sed -i 's#^\(: ${TOKENIZER_PATH=\).*#\1/shared/llama7b_tokenizer}#' /shared/neuronx-nemo-megatron/nemo/examples/nlp/language_modeling/test_llama.sh
sed -i 's#^\(: ${DATASET_PATH=\).*#\1/shared/data/redpajama_sample_text_document}#' /shared/neuronx-nemo-megatron/nemo/examples/nlp/language_modeling/test_llama.sh
변경 전:
: ${TOKENIZER_PATH=$HOME/llamav2_weights/7b-hf}
: ${DATASET_PATH=$HOME/examples_datasets/llama_7b/book.jsonl-processed_text_document}
변경 후:
: ${TOKENIZER_PATH=/shared/llama7b_tokenizer}
: ${DATASET_PATH=/shared/data/redpajama_sample_text_document}
nano에서 변경 사항을 저장하려면 CTRL-X를 누른 다음 y를 누르고 ENTER를 누릅니다.
완료되면 exit를 입력하거나 CTRL-d를 눌러 CLI 파드를 종료합니다.
CLI 파드가 더 이상 필요하지 않으면 다음을 실행하여 제거할 수 있습��니다:
kubectl delete pod cli-cmd-shell
이제 사전 컴파일 및 훈련 작업을 시작할 준비가 되었습니다!
먼저 다음 명령을 실행하여 MPI 오퍼레이터가 제대로 작동하는지 확인합니다:
kubectl get all -n mpi-operator
MPI Operator가 설치되어 있지 않으면 진행하기 전에 MPI Operator 설치 지침을 따르세요.
훈련 작업을 실행하기 전에 먼저 모델 아티팩트를 준비하기 위해 사전 컴파일 작업을 실행합니다. 이 단계는 Llama-2-7b 모델의 기본 컴퓨트 그래프를 추출하고 컴파일하여 Trainium 가속기에서 실행할 수 있는 Neuron 실행 파일(NEFF)을 생성합니다. 이러한 NEFF는 FSx의 영구 Neuron 캐시에 저장되어 나중에 훈련 작업에서 접근할 수 있습니다.
사전 컴파일 작업 ��실행
사전 컴파일 스크립트 실행
./3-llama2-neuronx-mpi-compile.sh
4개의 trn1.32xlarge 노드를 사용할 때 사전 컴파일은 약 10분이 소요됩니다.
kubectl get pods | grep compile을 주기적으로 실행하고 컴파일 작업이 'Completed'로 표시될 때까지 기다립니다.
사전 컴파일이 완료되면 다음 스크립트를 실행하여 4개의 trn1.32xl 노드에서 사전 훈련 작업을 시작할 수 있습니다:
훈련 작업 실행
./4-llama2-neuronx-mpi-train.sh
훈련 작업 출력 보기
훈련 작업 출력을 모니터링하려면 먼저 훈련 작업과 연결된 런처 파드의 이름을 찾습니다:
kubectl get pods | grep launcher
런처 파드의 이름을 확인하고 'Running' 상태인 것을 확인한 후 다음 단계는 UID를 확인하는 것입니다. 다음 명령에서 test-mpi-train-launcher-xxx를 실제 런처 파드 이름으로 대체하면 UID가 출력됩니다:
kubectl get pod test-mpi-train-launcher-xxx -o json | jq -r ".metadata.uid"
UID를 사용하여 로그 경로를 확인하고 훈련 로그를 tail할 수 있습니다. 다음 명령에서 UID를 위의 값으로 대체하세요.
kubectl exec -it test-mpi-train-worker-0 -- tail -f /shared/nemo_experiments/UID/0/log
로그 확인이 완료되면 CTRL-C를 눌러 tail 명령을 종료할 수 있습니다.
Trainium 가속기 활용률 모니터링
Trainium 가속기 활용률을 모니터링하려면 neuron-top 명령을 사용할 수 있습니다. Neuron-top은 trn1/inf2/inf1 인스턴스에서 Neuron 및 시스템 관련 성능 메트릭을 모니터링하기 위한 콘솔 기반 도구입니다. 다음과 같이 워커 파드 중 하나에서 neuron-top을 시작할 수 있습니다:
kubectl exec -it test-mpi-train-worker-0 -- /bin/bash -l neuron-top
TensorBoard에서 훈련 작업 메트릭 보기
TensorBoard는 훈련 작업을 모니터링하고 탐색하는 데 일반적으로 사용되는 웹 기반 시각화 도구입니다. 훈련 메트릭을 빠르게 모니터링할 수 있으며 서로 다른 훈련 실행 간의 메트릭을 쉽게 비교할 수도 있습니다.
TensorBoard 로그는 FSx for Lustre 파일 시스템의 /shared/nemo_experiments/ 디렉토리에서 사용할 수 있습니다.
다음 스크립트를 실행하여 Llama-2 훈련 작업 진행 상황을 시각화할 수 있는 TensorBoard 배포를 생성합니다:
./5-deploy-tensorboard.sh
배포가 준비되면 스크립트는 새 TensorBoard 배포에 대한 암호로 보호된 URL을 출력합니다.
URL을 실행하여 훈련 진행 상황을 확인합니다.
TensorBoard 인터페이스를 열면 왼쪽 메뉴에서 훈련 작업 UID를 선택한 다음 메인 애플리케이션 창에서 다양한 훈련 메트릭(예: reduced-train-loss, throughput, grad-norm)을 탐색합니다.
훈련 작업 중지
훈련 작업을 중지하고 런처/워커 파드를 제거하려면 다음 명령을 실행합니다:
kubectl delete mpijob test-mpi-train
그런 다음 kubectl get pods를 실행하여 런처/워커 파드가 제거되었는지 확인할 수 있습니다.
정리
이 솔루션을 사용하여 생성된 리소스를 제거하려면 정리 스크립트를 실행합니다:
cd ai-on-eks/infra/trainium-inferentia
./cleanup.sh