EKS에서 ML 모델을 배포하려면 GPU 또는 Neuron 인스턴스에 대한 접근 권한이 필요합니다. 배포가 작동하지 않는 경우 이러한 리소스에 대한 접근 권한이 없기 때문인 경우가 많습니다. 또한 일부 배포 패턴은 Karpenter 자동 스케일링과 정적 노드 그룹에 의존합니다. 노드가 초기화되지 않으면 Karpenter 또는 노드 그룹의 로그를 확인하여 문제를 해결하세요.
참고: 이 Llama-2 모델의 사용은 Meta 라이선스의 적용을 받습니다. 모델 가중치와 토크나이저를 다운로드하려면 웹사이트를 방문하여 접근 권한을 요청하기 전에 라이선스에 동의해야 합니다.
이 블루프린트는 관측성, 로깅 및 확장성 측면의 개선 사항을 통합하기 위해 적극적으로 개선 중입니다.
RayTrain과 KubeRay를 활용한 Trn1에서의 Llama2 분산 사전 훈련
이 종합 가이드는 Amazon EKS의 KubeRay 클러스터 내에서 AWS Trainium (Trn1) 인스턴스와 AWS Neuron SDK를 사용하여 Llama2-7B 언어 모델을 사전 훈련하는 과정을 안내합니다. 이것은 KubeRay의 분산 훈련 기능에 최적화된 원본 Llama2 사전 훈련 튜토리얼의 맞춤형 버전입니다.
Llama-2란?
Llama-2는 텍스트 생성, 요약, 번역, 질의응답 등 다양한 자연어 처리(NLP) 작업을 위해 설계된 최첨단 대규모 언어 모델(LLM)입니다. 특정 사용 사례에 맞게 파인튜닝할 수 있는 강력한 도구입니다.
분산 훈련을 위한 RayTrain과 KubeRay의 장점
Llama-2와 같은 대규모 모델은 방대한 컴퓨팅 및 메모리 요구사항으로 인해 분산 훈련이 필수적입니다. RayTrain과 KubeRay의 조합은 특히 AWS Trainium과 함께 활용할 때 이러한 요구사항을 효율적이고 효과적으로 처리하기 위한 강력한 프레임워크를 제공합니다:
RayTrain:
- 간소화된 분산 훈련: RayTrain은 분산 훈련의 복잡성을 추상화하는 Ray 프레임워크 기반의 고수준 라이브러리입니다. 최소한의 코드 변경으로 여러 노드에 걸쳐 Llama-2 훈련을 확장할 수 있습니다. Ray의 액터 기반 아키텍처와 태스크 기반 병렬 처리는 분산 워크로드의 효율적인 실행을 가능하게 합니다.
- 유연한 전략: RayTrain은 데이터 병렬 처리와 모델 병렬 처리와 같은 다양한 분산 훈련 전략을 지원합니다. 데이터 병렬 처리는 데이터셋을 여러 노드에 분할하고, 모델 병렬 처리는 모델 자체를 분할합니다. 이러한 유연성으로 모델의 특정 요구사항과 훈련 환경의 아키텍처에 따라 훈련을 최적화할 수 있습니다.
- 장애 허용: RayTrain에는 내장된 장애 허용 메커니즘이 포함되어 있습니다. 노드가 실패하면 Ray가 다른 사용 가능한 노드에서 태스크를 재스케줄링하여 훈련 작업이 중단 없이 계속됩니다. 이 기능은 대규모 분산 훈련 환경에서 견고성을 유지하는 데 중요합니다.
- 사용 편의�성: RayTrain은 분산 훈련 작업의 설정과 실행을 단순화하는 직관적인 API를 제공합니다. Hugging Face Transformers와 같은 인기 있는 머신 러닝 라이브러리와의 통합으로 광범위한 수정 없이 기존 워크플로우에 RayTrain을 쉽게 통합할 수 있습니다.
KubeRay:
- Kubernetes와의 통합: KubeRay는 Kubernetes의 네이티브 기능을 활용하여 Ray 클러스터를 배포, 관리 및 확장합니다. 이 통합으로 Kubernetes의 강력한 오케스트레이션 기능을 사용하여 Ray 워크로드를 효과적으로 처리할 수 있습니다.
- 동적 스케일링: KubeRay는 Ray 클러스터의 동적 스케일링을 지원합니다. Ray의 내장 오토스케일러가 워크로드 요구에 따라 추가 액터 레플리카를 요청할 수 있으며, Karpenter나 Cluster Autoscaler와 같은 Kubernetes 도구가 이러한 요구를 충족하기 위해 새 노드 생성을 관리합니다.
- 수평 스케일링: 컴퓨팅 부하가 증가함에 따라 더 많은 워커 노드를 추가하여 Ray 클러스터를 수평으로 확장합니다. 이를 통해 대규모 분산 훈련 및 추론 작업을 효율적으로 처리할 수 있습니다.
- Custom Resource Definitions (CRDs): KubeRay는 Kubernetes CRD를 활용하여 Ray 클러스터와 작업을 정의하고 관리합니다. 이는 Kubernetes 에코시스템 내에서 Ray 워크로드를 처리하는 표준화된 방법을 제공합니다.
- 장애 허용: KubeRay는 Kubernetes의 자가 치유 기능을 활용합니다. Ray 헤드 노드나 워커 노드가 실패하면 Kubernetes가 자동으로 실패한 구성 요소를 다시 시작하여 최소한의 다운타임과 지속적인 운영을 보장합니다.
- 분산 스케줄링: Ray의 액터 기반 모델과 분산 태스크 스케줄링이 Kubernetes의 오케스트레이션과 결합되어 노드 장애 발생 시에도 고가용성과 효율적인 태스크 실행을 보장합니다.
- 선언적 구성: KubeRay를 사용하면 선언적 YAML 구성을 사용하여 Ray 클러스터와 작업을 정의할 수 있습니다. 이는 배포 및 관리 프로세스를 단순화하여 Ray 클러스터를 더 쉽게 설정하고 유지 관리할 수 있게 합니다.
- 통합 로깅 및 모니터링: KubeRay는 Prometheus 및 Grafana와 같은 Kubernetes의 로깅 및 모니터링 도구와 통합됩니다. 이는 Ray 클러스터의 성능과 상태에 대한 포괄적인 인사이트를 제공하여 디버깅과 최적화를 용이하게 합니다.
- 스팟 인스턴스: Kubernetes의 스팟 인스턴스 지원을 사용하여 비용 효율적으로 Ray 클러스터를 실행합니다. 이를 통해 필요에 따라 확장하는 능력을 유지하면서 저비용 컴퓨팅 리소스를 활용할 수 있습니다.
AWS Trainium:
- 딥러닝에 최적화: AWS Trainium 기반 Trn1 인스턴스는 딥러닝 워크로드를 위해 특별히 설계되었습니다. 높은 처리량과 낮은 지연 시간을 제공하여 Llama-2와 같은 대규모 모델 훈련에 이상적입니다. Trainium 칩은 기존 프로세서에 비해 상당한 성능 향상을 제공하여 훈련 시간을 단축합니다.
- Neuron SDK: AWS Neuron SDK는 Trainium에 맞게 딥러닝 모델을 최적화하도록 맞춤화되어 있습니다. 고급 컴�파일러 최적화와 혼합 정밀도 훈련 지원과 같은 기능을 포함하여 정확도를 유지하면서 훈련 워크로드를 더욱 가속화할 수 있습니다.
이 조합이 강력한 이유
- 간소화된 스케일링: RayTrain과 KubeRay는 여러 노드에 걸친 Llama-2 훈련 스케일링 프로세스를 단순화합니다. Ray의 효율적인 분산 실행과 KubeRay의 Kubernetes 네이티브 오케스트레이션으로 Trn1 인스턴스에서 AWS Trainium의 전체 성능을 활용하기 위해 훈련 워크로드를 쉽게 확장할 수 있습니다.
- 최적화된 성능: Neuron SDK는 Trainium의 아키텍처에 맞게 특별히 최적화하여 훈련 작업의 성능을 향상시킵니다. Ray의 효율적인 분산 태스크 관리와 KubeRay의 리소스 오케스트레이션과 결합하여 이 설정은 최적의 훈련 성능을 보장합니다.
- 비용 효율성: Ray의 오토스케일링 기능과 Kubernetes의 리소스 관리는 리소스를 효율적으로 할당하고 수요에 따라 클러스터를 확장하여 비용을 최적화하는 데 도움이 됩니다. 이를 통해 필요한 리소스만 사용하여 불필요한 지출을 줄일 수 있습니다.
이 기술 조합을 사용하면 분산 훈련과 하드웨어의 최신 발전을 활용하여 Llama-2를 효율적이고 효과적으로 사전 훈련할 수 있습니다.
Volcano란?
Volcano는 Kubernetes 기반의 오픈소스 배치 스케줄링 시스템으로, 고성능 컴퓨팅(HPC) 및 머신 러닝 워크로드를 관리하기 위해 특별히 설계되었습니다. Gang 스케줄링, 공정 공유, 선점과 같은 고급 스케줄링 기능을 제공하며, 이는 Kubernetes 환경에서 대규모 분산 훈련 작업을 효율적으로 실행하는 데 필수적입니다.
Volcano의 Gang 스케줄링 작동 방식
Volcano의 Gang 스케줄링은 작업(또는 "Gang")의 모든 파드가 동시에 스케줄링되도록 보장합니다. 이는 여러 파드가 올바르게 작동하기 위해 함께 시작해야 하는 분산 훈련 워크로드에 중요합니다. Gang의 파드 중 하나라도 리소스 제약으로 인해 스케줄링할 수 없는 경우 Gang의 어떤 파드도 시작되지 않습니다. 이는 부분 실행을 방지하고 실행이 시작되기 전에 작업에 필요한 모든 리소스가 사용 가능하도록 보장합니다.
1. 솔루션 배포
사전 요구사항
👈2. Docker 이미지 빌드 (선택 단계)
블루프린트 배포를 단순화하기 위해 이미 Docker 이미지를 빌드하여 퍼블릭 ECR에서 사용할 수 있도록 했습니다.
Docker 이미지를 커스터마이징하려면 Dockerfile을 업데이트하고 선택 단계를 따라 Docker 이미지를 빌드할 수 있습니다.
새로 생성된 이미지와 자체 프라이빗 ECR을 사용하여 RayCluster YAML 파일 llama2-pretrain-trn1-raycluster.yaml도 수정해야 합니다.
cd ai/training/raytrain-llama2-pretrain-trn1
./kuberay-trn1-llama2-pretrain-build-image.sh
이 스크립트를 실행한 후 생성된 Docker 이미지 URL과 태그를 기록하세요. 다음 단계에서 이 정보가 필요합니다.
3. KubeRay Operator로 Ray 클러스터 시작
2단계를 건너뛰는 경우 YAML 파일을 수정할 필요가 없습니다.
파일에 kubectl apply 명령을 실행하면 우리가 게시한 퍼블릭 ECR 이미지를 사용합니�다.
2단계에서 커스텀 Docker 이미지를 빌드한 경우 이전 단계에서 얻은 Docker 이미지 URL과 태그로 ai/training/raytrain-llama2-pretrain-trn1/llama2-pretrain-trn1-raycluster.yaml 파일을 업데이트하세요.
YAML 파일을 업데이트한 후(필요한 경우) 다음 명령을 실행하여 EKS 클러스터에서 KubeRay 클러스터 파드를 시작합니다:
kubectl apply -f llama2-pretrain-trn1-raycluster.yaml
파드 상태 확인:
kubectl get pods -l "ray.io/cluster=kuberay-trn1"
Volcano를 사용한 Ray 헤드 및 워커 파드의 Gang 스케줄링
Llama2 훈련을 위한 Ray 클러스터 배포 컨텍스트에서 Volcano는 Ray 헤드 및 워커 파드가 함께 효율적으로 스케줄링되도록 하는 데 중요합니다. 일반적으로 x86 인스턴스에서 실행되는 Ray 헤드 파드는 분산 훈련을 조정하고, AWS Trainium (Trn1) 인스턴스에서 실행되는 워커 파드는 계산 집약적인 작업을 수행합니다. Volcano의 Gang 스케줄링을 활용하여 헤드와 모든 워커 파드에 필요한 리소스가 동시에 할당되도록 하여 분산 훈련 작업이 지연 없이 시작될 수 있습니다.
다음은 Llama2 훈련을 위한 RayCluster와 Volcano를 통합하는 예제 구성입니다:
Terraform 블루프린트가 default 네임스페이스에 fsx-claim PVC를 생성하기 때문에 이 배포에 default 네임스페이스를 사용합니다.
전용 네임스페이스에 클러스터를 배포하려면 PVC가 네임스페이스에 바인딩되므로 FSX for Lustre 파일 시스템도 동일한 네임스페이스에 생성되어야 합니다.
# Volcano와 KubeRay 문서: https://docs.ray.io/en/master/cluster/kubernetes/k8s-ecosystem/volcano.html
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: llama2-training-queue
namespace: default
spec:
weight: 1
capability:
cpu: '500'
memory: 1500Gi
---
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: kuberay-trn1
namespace: default
labels:
ray.io/scheduler-name: volcano
volcano.sh/queue-name: llama2-training-queue
spec:
rayVersion: 2.22.0
headGroupSpec:
...
...
Running 상태의 ray-head 파드 1개와 ray-worker 파드 2개가 표시되어야 합니다:
이미지를 가져오고 파드가 준비되기까지 최대 10분��이 소요될 수 있습니다.
NAME READY STATUS RESTARTS AGE
kuberay-trn1-head-67t46 0/1 Pending 0 2m50s
kuberay-trn1-worker-workergroup-fz8bs 0/1 Pending 0 2m50s
kuberay-trn1-worker-workergroup-gpnxh 0/1 Pending 0 2m50s
헤드 파드의 로그 확인:
Ray 헤드가 시작되었고 클러스터가 작동 중임을 나타내는 메시지를 찾습니다.
kubectl logs kuberay-trn1-head-xxxxx
Ray 대시보드 접근 (포트 포워딩):
Ray 대시보드는 클러스터 상태와 작업 진행 상황에 대한 귀중한 인사이트를 제공합니다. 접근하려면:
포트 포워딩:
로컬 머신에서 클러스터 내 헤드 파드로 Ray 대시보드 포트(8265)를 포워딩합니다.
kubectl port-forward service/kuberay-trn1-head-svc 8265:8265
브라우저를 열고 웹 브라우저에서 http://localhost:8265로 이동하여 대시보드를 확인합니다.
4. FSx 공유 파일 시스템에서 사전 훈련 데이터 생성
데이터 생성 단계는 FSx for Lustre에 모든 데이터를 생성하는 데 최대 20분이 소요될 수 있습니다.
이 단계에서는 KubeRay의 Job 사양을 활용하여 데이터 생성 프로세스를 시작합니다. Ray 헤드 파드에 직접 작업을 제출합니다. 이 작업은 모델을 훈련할 준비를 하는 데 핵심적인 역할을 합니다.
기존 RayCluster에 작업을 제출하기 위해 clusterSelector를 사용하는 아래 RayJob 정의 사양을 확인하세요.
# ----------------------------------------------------------------------------
# RayJob: llama2-generate-pretraining-test-data
#
# 설명:
# 이 RayJob은 Llama2 모델 훈련에 필요한 사전 훈련 테스트 데이터를 생성하는
# 역할을 합니다. 지정된 데이터셋에서 데이터를 소싱하고 처리하여 후속 훈련 단계에서
# 사용할 수 있도록 준비합니다. 이 작업은 이러한 데이터 준비 단계를 수행하는
# Python 스크립트(`get_dataset.py`)를 실행합니다.
# 사용법:
# `kubectl apply -f 1-llama2-pretrain-trn1-rayjob-create-test-data.yaml`을 사용하여
# Kubernetes 클러스터에 이 구성을 적용합니다.
# Ray 클러스터(`kuberay-trn1`)가 지정된 네임스페이스에서 실행 중이고 접근 가능한지 확인하세요.
# ----------------------------------------------------------------------------
apiVersion: ray.io/v1
kind: RayJob
metadata:
name: llama2-generate-pretraining-test-data
namespace: default
spec:
submissionMode: K8sJobMode
entrypoint: "python3 get_dataset.py"
runtimeEnvYAML: |
working_dir: /llama2_pretrain
env_vars:
PYTHONUNBUFFERED: '0'
resources:
requests:
cpu: "6"
memory: "30Gi"
clusterSelector:
ray.io/cluster: kuberay-trn1
rayClusterNamespace: default # RayCluster가 배포된 네임스페이스로 대체
ttlSecondsAfterFinished: 60 # 완료 후 파드의 생존 시간(초)
다음 명령을 실행하여 테스트 데이터 생성 Ray 작업을 실행합니다:
kubectl apply -f 1-llama2-pretrain-trn1-rayjob-create-test-data.yaml
내부에서 일어나는 일:
작업 시작: kubectl을 사용하여 KubeRay 작업 사양을 제출합니다. kuberay-trn1 클러스터의 Ray 헤드 파드가 이 작업을 수신하고 실행합니다.
데이터 생성: 작업이 ai/training/raytrain-llama2-pretrain-trn1/llama2_pretrain/get_dataset.py 스크립트를 실행하며, Hugging Face datasets 라이브러리의 기능을 활용하여 원시 영어 Wikipedia 데이터셋("wikicorpus")을 가져오고 처리합니다.
토큰화: 스크립트는 Hugging Face transformers의 사전 훈련된 토크나이저를 사용하여 텍스트를 토큰화합니다. 토큰화는 모델이 이해할 수 있도록 텍스트를 더 작은 단위(단어 또는 하위 단어)로 분해합니다.
데이터 저장: 토큰화된 데이터는 깔끔하게 정리되어 FSx for Lustre 공유 파일 시스템 내의 특정 디렉토리(/shared/wikicorpus_llama2_7B_tokenized_4k/)에 저장됩니다. 이를 통해 클러스터의 모든 워커 노드가 사전 훈련 중에 이 표준화된 데이터에 쉽게 접근할 수 있습니다.
작업 모니터링:
작업 진행 상황을 추적하려면:
Ray 대시보드: Ray 헤드 파드의 IP 주소와 포트 8265를 통해 접근할 수 있는 Ray 대시보드로 이동합니다. 작업 상태에 대한 실시간 업데이트를 확인할 수 있습니다.
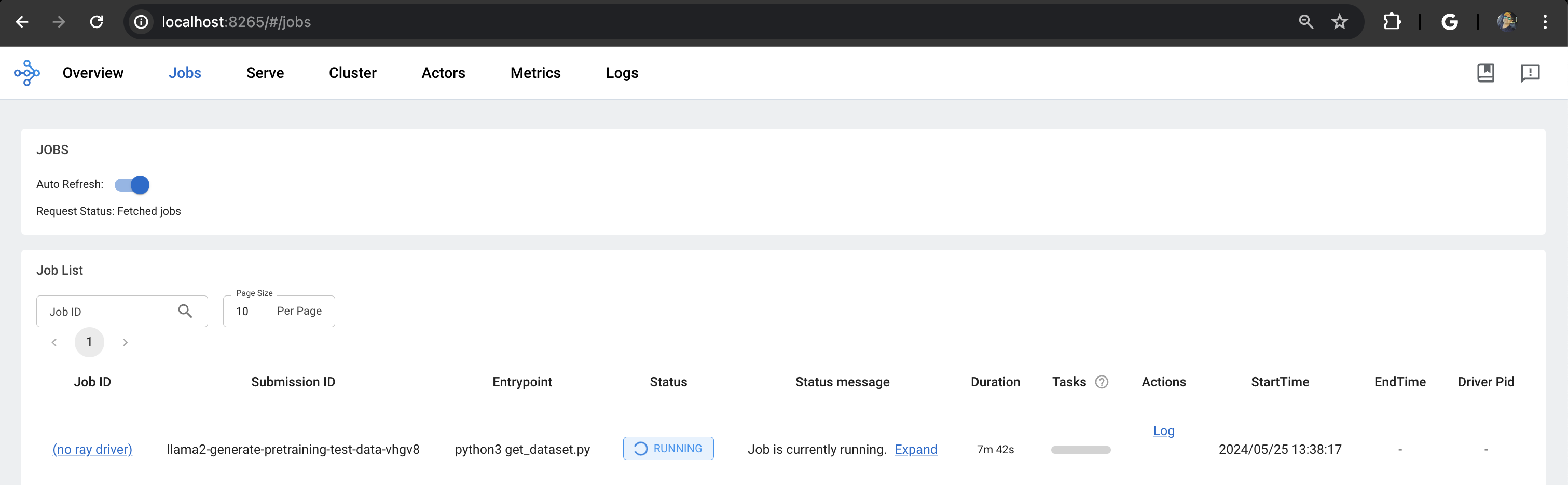
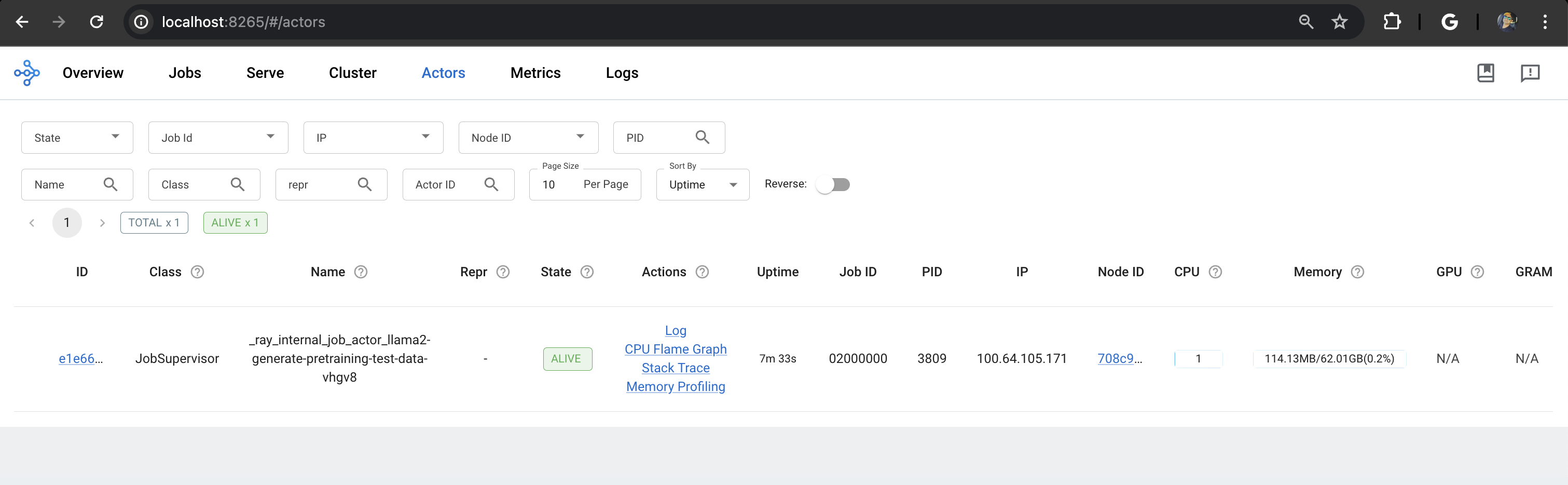
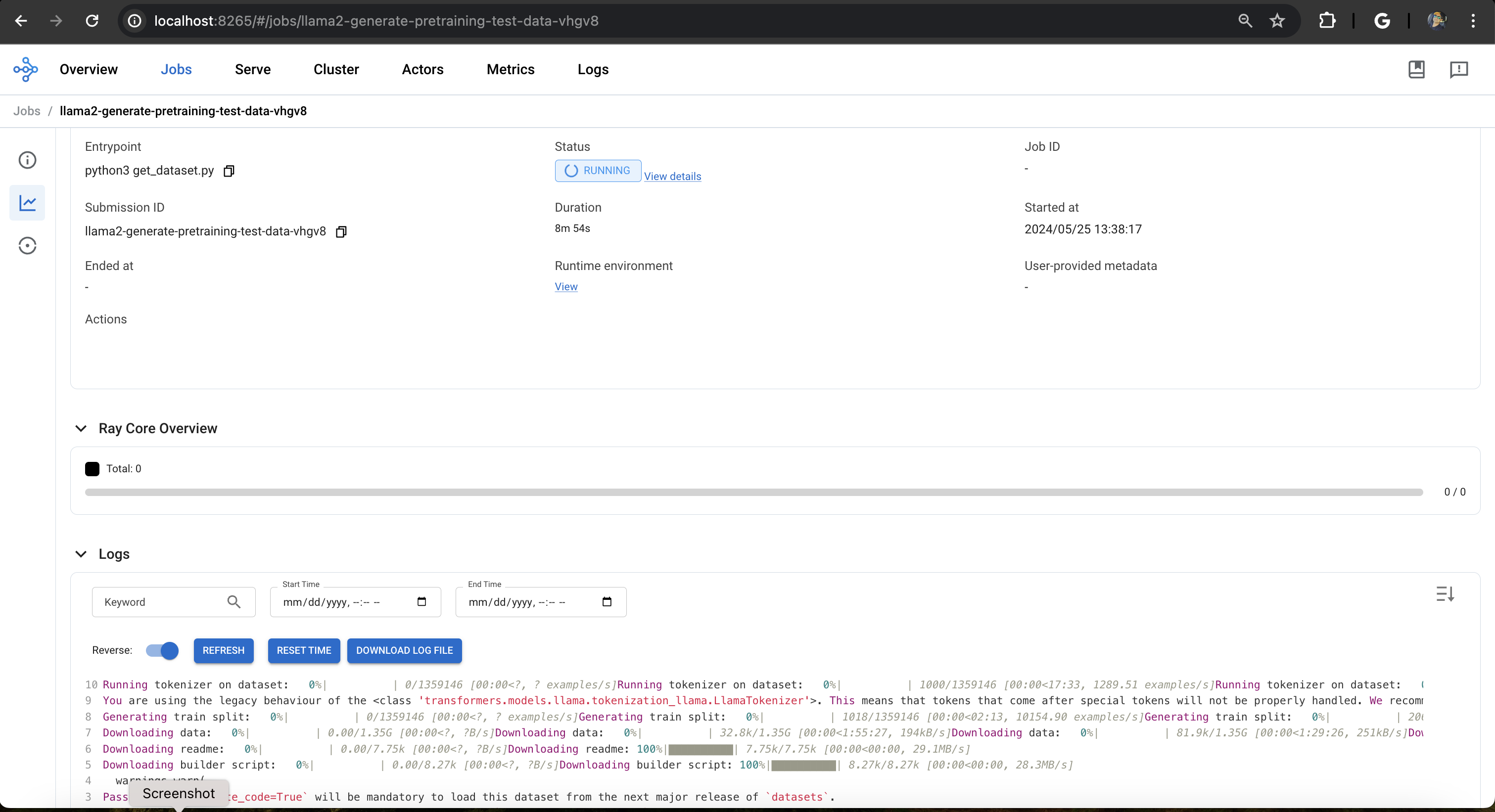
또는 터미널에서 다음 명령을 사용할 수 있습니다:
kubectl get pods | grep llama2
출력:
llama2-generate-pretraining-test-data-g6ccl 1/1 Running 0 5m5s
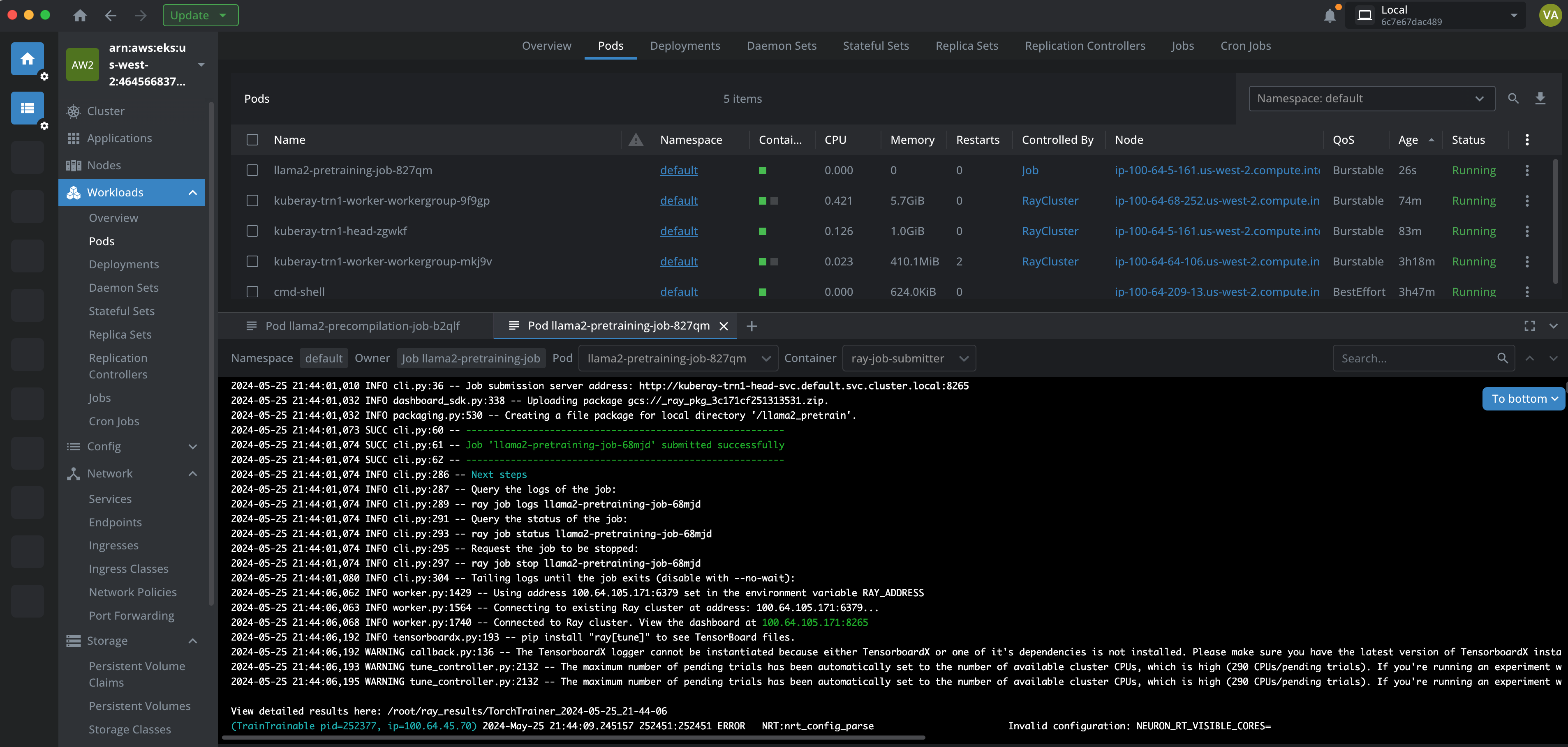
다음 스크린샷은 Lens K8s IDE에서 파드의 로그를 보여줍니다.
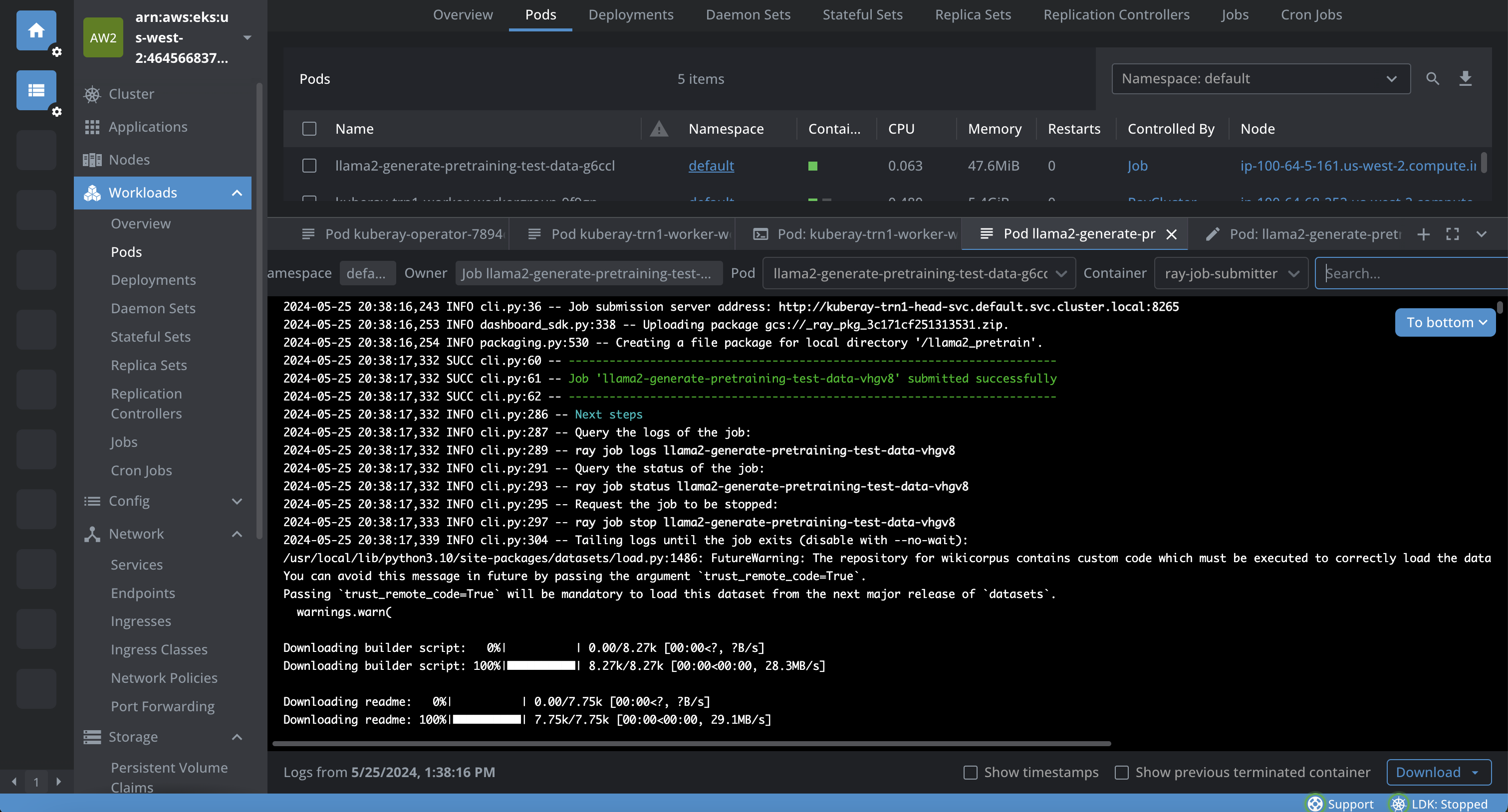
5. 사전 컴파일 작업 실행 (최적화 단계)
사전 컴파일 작업은 최대 6분이 소요될 수 있습니다
실제 훈련을 시작하기 전에 Neuron SDK에 맞게 모델을 최적화하기 위한 사전 컴파일 단계를 수행합니다. 이를 통해 모델이 Trn1 인스턴스에서 더 효율적으로 실행됩니다. 이 스크립트는 Neuron SDK를 사용하여 모델의 연산 그래프를 컴파일하고 최적화하여 Trn1 프로세서에서 효율적인 훈련을 위해 준비합니다.
이 단계에서는 Neuron SDK가 Llama2 사전 훈련과 관련된 연산 그래프를 식별, 컴파일 및 캐시하는 사전 컴파일 작업을 실행합니다.
사전 컴파일 작업을 실행하기 위한 아래 RayJob 정의 사양을 확인하세요:
# ----------------------------------------------------------------------------
# RayJob: llama2-precompilation-job
#
# 설명:
# 이 RayJob은 Llama2 모델 훈련에 필요한 사전 컴파일 단계를 담당합니다.
# AWS Neuron 장치를 사용하여 모델을 병렬로 컴파일하기 위해 `--neuron_parallel_compile`
# 옵션과 함께 Python 스크립트(`ray_train_llama2.py`)를 실행합니다. 이 단계는
# AWS 인프라에서 효율적인 훈련을 위해 모델을 최적화하는 데 중요합니다.
# 사용법:
# `kubectl apply -f 2-llama2-pretrain-trn1-rayjob-precompilation.yaml`을 사용하여
# Kubernetes 클러스터에 이 구성을 적용합니다.
# Ray 클러스터(`kuberay-trn1`)가 지정된 네임스페이스에서 실행 중이고 접근 가능한지 확인하세요.
# ----------------------------------------------------------------------------
---
apiVersion: ray.io/v1
kind: RayJob
metadata:
name: llama2-precompilation-job
namespace: default
spec:
submissionMode: K8sJobMode
entrypoint: "NEURON_NUM_DEVICES=32 python3 /llama2_pretrain/ray_train_llama2.py --neuron_parallel_compile"
runtimeEnvYAML: |
working_dir: /llama2_pretrain
env_vars:
PYTHONUNBUFFERED: '0'
clusterSelector:
ray.io/cluster: kuberay-trn1
rayClusterNamespace: default # RayCluster가 배포된 네임스페이스로 대체
ttlSecondsAfterFinished: 60 # 완료 후 파드의 생존 시간(초)
다음 명령을 실행하여 사전 컴파일 작업을 실행합니다:
kubectl apply -f 2-llama2-pretrain-trn1-rayjob-precompilation.yaml
확인 단계:
작업 진행 상황을 모니터링하고 올바르게 실행되고 있는지 확인하려면 다음 명령과 도구를 사용하세요:
Ray 대시보드: Ray 헤드 파드의 IP 주소와 포트 8265를 통해 Ray 대시보드에 접근하여 작업 상태에 대한 실시간 업데이트를 확인합니다.
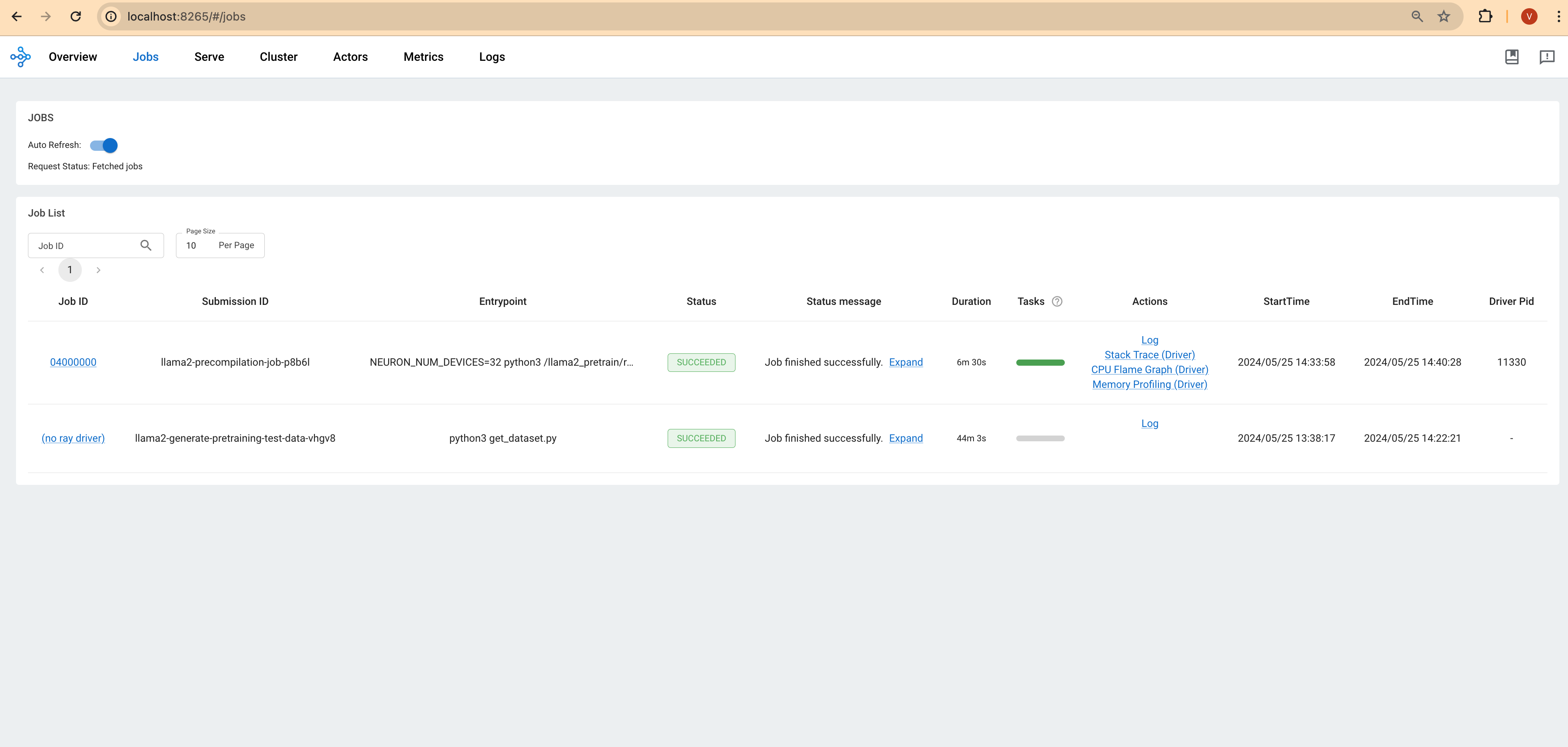
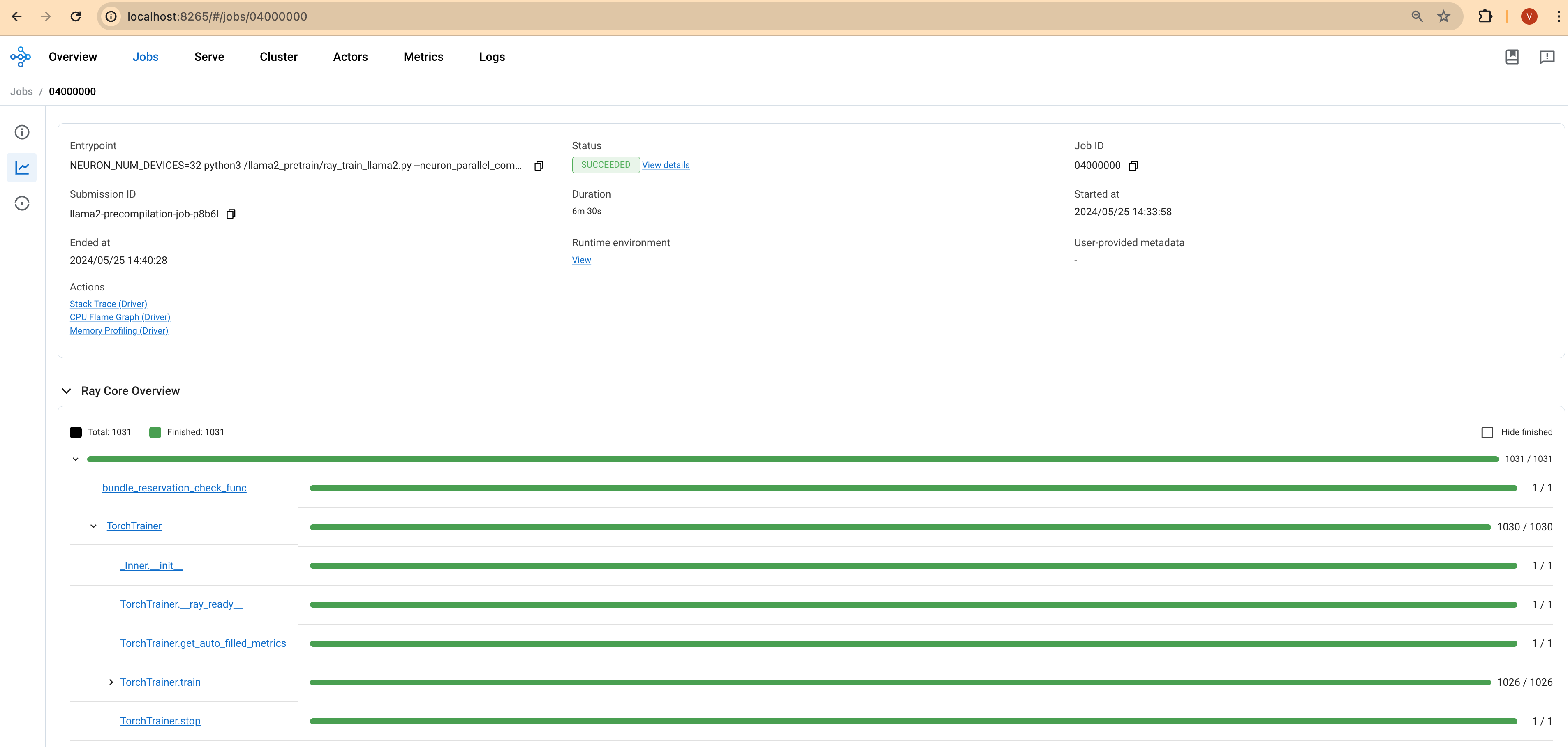
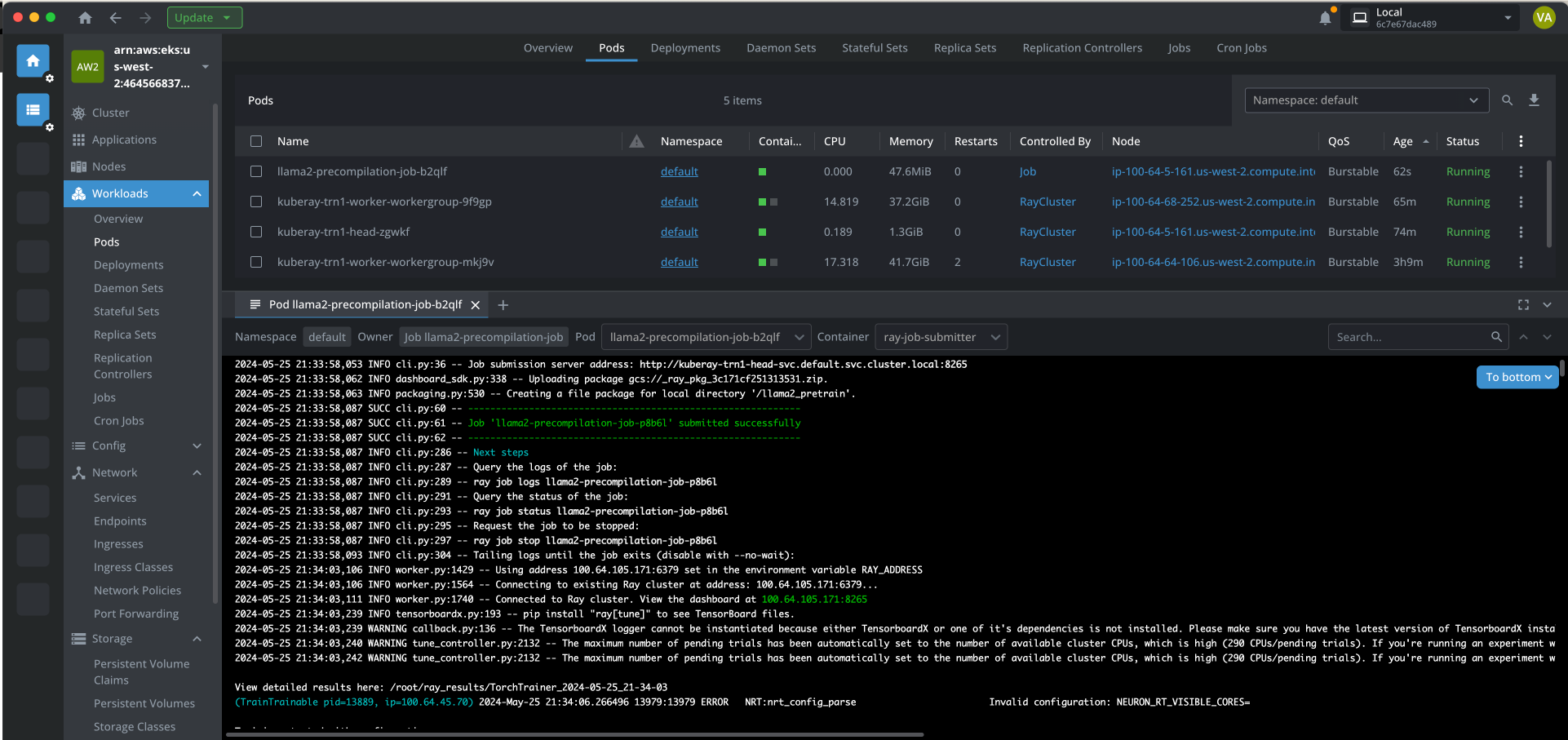
다음 스크린샷은 Lens K8s IDE에서 파드의 로그를 보여줍니다.
6. 분산 사전 훈련 작업 실행
이 작업은 여러 시간 동안 실행될 수 있으므로 손실이 감소하고 모델이 학습하고 있음을 확인한 후 Ctrl+C를 사용하여 작업을 취소해도 됩니다.
이제 Llama 2 모델의 실제 훈련을 시작할 준비가 되었습니다! 이 단계는 RayJob을 사용하여 분산 사전 훈련 작업을 실행하는 것을 포함합니다. 이 작업은 AWS Neuron 장치를 활용하여 준비된 데이터셋으로 모델을 효율적으로 훈련합니다.
사전 훈련 작업을 실행하기 위한 아래 RayJob 정의 사양을 확인하세요:
# ----------------------------------------------------------------------------
# RayJob: llama2-pretraining-job
#
# 설명:
# 이 RayJob은 Llama2 모델의 주요 사전 훈련 단계를 담당합니다.
# AWS Neuron 장치를 사용하여 사전 훈련을 수행하기 위해 Python 스크립트(`ray_train_llama2.py`)를
# 실행합니다. 이 단계는 준비된 데이터셋으로 언어 모델을 훈련하는 데 중요합니다.
# 사용법:
# `kubectl apply -f 3-llama2-pretrain-trn1-rayjob.yaml`을 사용하여
# Kubernetes 클러스터에 이 구성을 적용합니다.
# Ray 클러스터(`kuberay-trn1`)가 지정된 네임스페이스에서 실행 중이고 접근 가능한지 확인하세요.
# ----------------------------------------------------------------------------
---
apiVersion: ray.io/v1
kind: RayJob
metadata:
name: llama2-pretraining-job
namespace: default
spec:
submissionMode: K8sJobMode
entrypoint: "NEURON_NUM_DEVICES=32 python3 ray_train_llama2.py"
runtimeEnvYAML: |
working_dir: /llama2_pretrain
env_vars:
PYTHONUNBUFFERED: '0'
clusterSelector:
ray.io/cluster: kuberay-trn1
rayClusterNamespace: default # RayCluster가 배포된 네임스페이스로 대체
shutdownAfterJobFinishes: true
activeDeadlineSeconds: 600 # 작업이 600초(10분)보다 오래 실행되면 종료됩니다
ttlSecondsAfterFinished: 60 # 완료 후 파드의 생존 시간(초)
다음 명령을 실행하여 사전 훈련 작업을 실행합니다:
kubectl apply -f 3-llama2-pretrain-trn1-rayjob.yaml
진행 상황 모니터링:
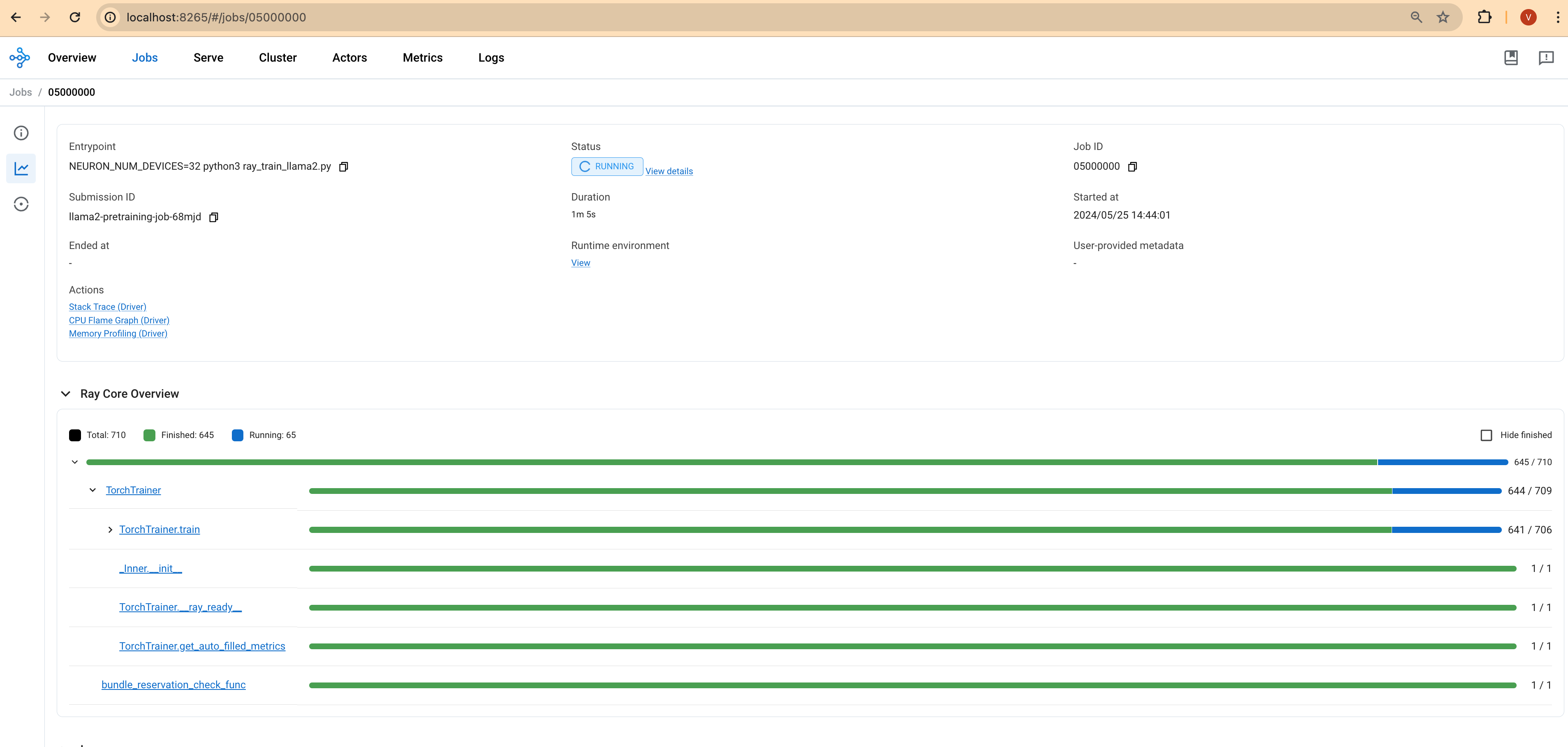
Ray 대시보드를 사용하거나 터미널에 출력되는 로그를 관찰하여 훈련 작업의 진행 상황을 모니터링할 수 있습니다. 모델이 얼마나 잘 학습하고 있는지 평가하기 위해 훈련 손실, 학습률 및 기타 메트릭과 같은 정보를 찾아보세요.
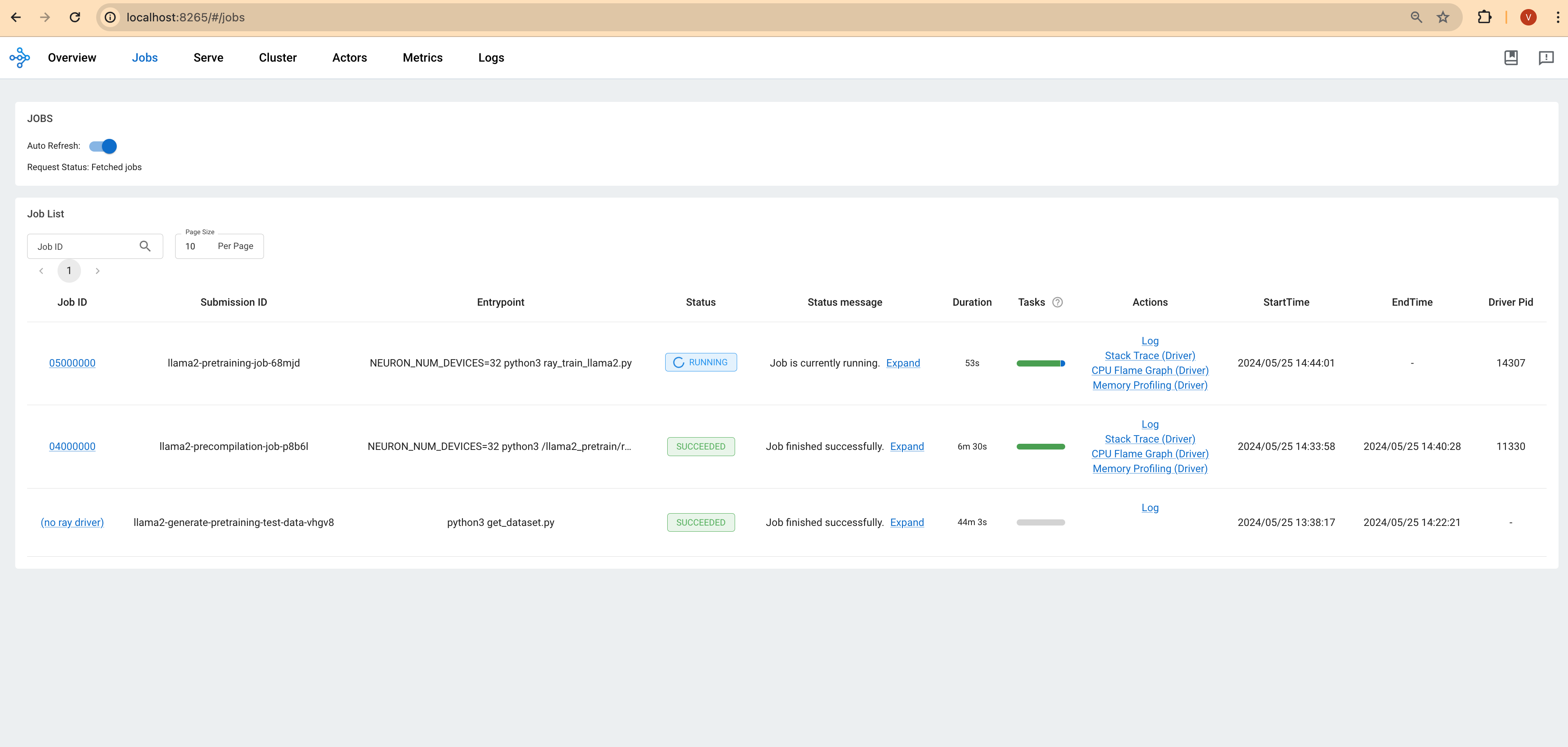
Ray 대시보드: Ray 헤드 파드의 IP 주소와 포트 8265를 통해 Ray 대시보드에 접근하여 작업 상태에 대한 실시간 업데이트를 확인합니다.
정리
이 솔루션을 사용하여 생성된 리소스를 제거하려면 정리 스크립트를 실행합니다:
# RayCluster 리소스 삭제:
cd ai/training/raytrain-llama2-pretrain-trn1
kubectl delete -f llama2-pretrain-trn1-raycluster.yaml
# EKS 클러스터 및 관련 리소스 정리:
cd ai-on-eks/infra/trainium-inferentia
./cleanup.sh