FSx for Lustre performance
In this section you'll run IOPS and throughput performance tests agains the FSx for Lustre file system using IOR framework.
IOR
IOR is a parallel IO benchmark that can be used to test the performance of parallel storage systems using various interfaces and access patterns. The IOR repository also includes the mdtest benchmark which specifically tests the peak metadata rates of storage systems under different directory structures. Both benchmarks use a common parallel I/O abstraction backend and rely on MPI for synchronization. This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License (as published by the Free Software Foundation) version 2, dated June 1991.
Complete these steps from the shell window connected to the head node.
- Install ior.
cd
wget https://github.com/hpc/ior/releases/download/4.0.0rc1/ior-4.0.0rc1.tar.gz
tar xvzf ior-4.0.0rc1.tar.gz
cd ior-4.0.0rc1
sudo ldconfig
./configure --with-lustre
make all
sudo make install
cd
Making install in contrib
make[2]: Nothing to be done for `install-exec-am'.
make[2]: Nothing to be done for `install-data-am'.
make[2]: Nothing to be done for `install-exec-am'.
make[2]: Nothing to be done for `install-data-am'.
[ec2-user@ip-172-31-55-225 ior-4.0.0rc1]$ cd
[ec2-user@ip-172-31-55-225 ~]$
- Use ior to generate 32 GiB of data with one file per thread using one thread.
_job_name=ior
_segment_count=32768
_threads=1
_path=/fsx/${_job_name}
mkdir -p ${_path}
time mpirun --npernode ${_threads} ior --posix.odirect -t 1m -b 1m -s ${_segment_count} -g -v -w -i 1 -F -k -D 0 -o ${_path}/ior.bin
IOR-4.0.0rc1: MPI Coordinated Test of Parallel I/O
Began : Mon Jan 22 12:02:00 2025
Command line : ior --posix.odirect -t 1m -b 1m -s 32768 -g -v -w -i 1 -F -k -D 0 -o /fsx/ior/ior.bin
Machine : Linux ip-172-31-55-225
TestID : 0
StartTime : Mon Jan 22 12:02:00 2025
Path : /fsx/ior/ior.bin.00000000
FS : 6.7 TiB Used FS: 0.5% Inodes: 27.1 Mi Used Inodes: 1.5%
Participating tasks : 1
Options:
api : POSIX
apiVersion :
test filename : /fsx/ior/ior.bin
access : file-per-process
type : independent
segments : 32768
ordering in a file : sequential
ordering inter file : no tasks offsets
nodes : 1
tasks : 1
clients per node : 1
repetitions : 1
xfersize : 1 MiB
blocksize : 1 MiB
aggregate filesize : 32 GiB
verbose : 1
Results:
access bw(MiB/s) IOPS Latency(s) block(KiB) xfer(KiB) open(s) wr/rd(s) close(s) total(s) iter
------ --------- ---- ---------- ---------- --------- -------- -------- -------- -------- ----
Commencing write performance test: Mon Jan 20 12:02:00 2025
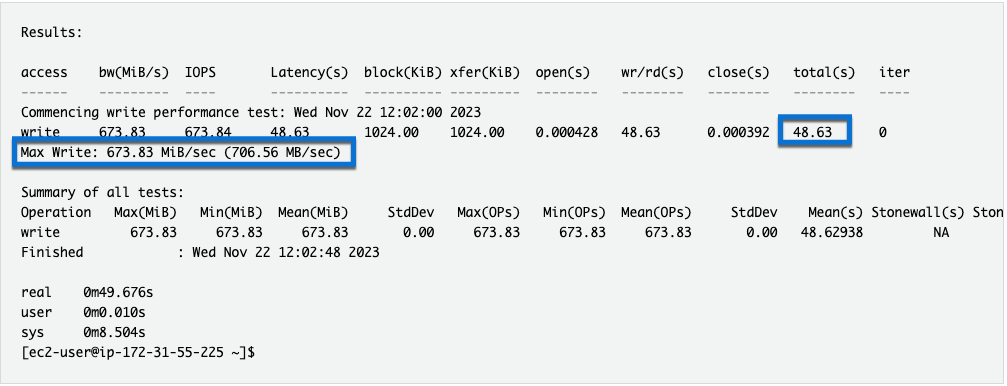
- Wait until the ior job completes.
- What was the Max Write: throughput?
- How long did it take?
- Use ior to read the data using one thread.
time mpirun --npernode ${_threads} ior -t 1m -b 1m -s ${_segment_count} -g -v -r -i 1 -F -k -D 0 -o ${_path}/ior.bin
IOR-4.0.0rc1: MPI Coordinated Test of Parallel I/O
Began : Mon Jan 22 12:04:38 2025
Command line : ior -t 1m -b 1m -s 32768 -g -v -r -i 1 -F -k -D 0 -o /fsx/ior/ior.bin
Machine : Linux ip-172-31-55-225
TestID : 0
StartTime : Mon Jan 22 12:04:38 2025
Path : /fsx/ior/ior.bin.00000000
FS : 6.7 TiB Used FS: 1.0% Inodes: 27.0 Mi Used Inodes: 1.5%
Participating tasks : 1
Options:
api : POSIX
apiVersion :
test filename : /fsx/ior/ior.bin
access : file-per-process
type : independent
segments : 32768
ordering in a file : sequential
ordering inter file : no tasks offsets
nodes : 1
tasks : 1
clients per node : 1
repetitions : 1
xfersize : 1 MiB
blocksize : 1 MiB
aggregate filesize : 32 GiB
verbose : 1
Results:
access bw(MiB/s) IOPS Latency(s) block(KiB) xfer(KiB) open(s) wr/rd(s) close(s) total(s) iter
------ --------- ---- ---------- ---------- --------- -------- -------- -------- -------- ----
Commencing read performance test: Mon Jan 22 12:04:38 2025
-
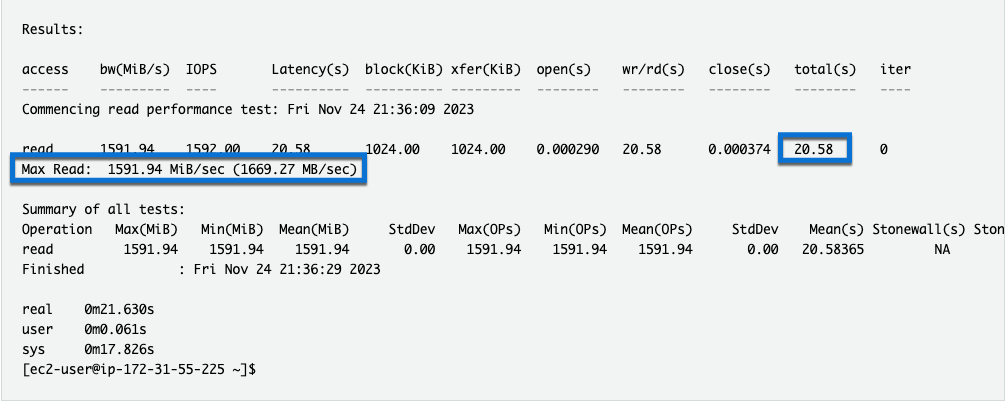
Wait for the ior job to complete.
- What was the Max Read: throughput?
- How long did it take?
- Use ior to generate 128 GiB of data with one file per thread using one thread per core. The head node is a c6gn.4xlarge Amazon EC2 instance with 16 vcpus (cores).
_job_name=ior
_segment_count=8192
_path=/fsx/${_job_name}
mkdir -p ${_path}
time mpirun --map-by core ior --posix.odirect -t 1m -b 1m -s ${_segment_count} -g -v -w -i 1 -F -k -D 0 -o ${_path}/ior.bin
IOR-4.0.0rc1: MPI Coordinated Test of Parallel I/O
Began : Mon Jan 20 12:09:10 2025
Command line : ior --posix.odirect -t 1m -b 1m -s 8192 -g -v -w -i 1 -F -k -D 0 -o /fsx/ior/ior.bin
Machine : Linux ip-172-31-55-225
TestID : 0
StartTime : Mon Jan 20 12:09:10 2025
Path : /fsx/ior/ior.bin.00000000
FS : 6.7 TiB Used FS: 1.0% Inodes: 27.0 Mi Used Inodes: 1.5%
Participating tasks : 16
Options:
api : POSIX
apiVersion :
test filename : /fsx/ior/ior.bin
access : file-per-process
type : independent
segments : 8192
ordering in a file : sequential
ordering inter file : no tasks offsets
nodes : 1
tasks : 16
clients per node : 16
repetitions : 1
xfersize : 1 MiB
blocksize : 1 MiB
aggregate filesize : 128 GiB
verbose : 1
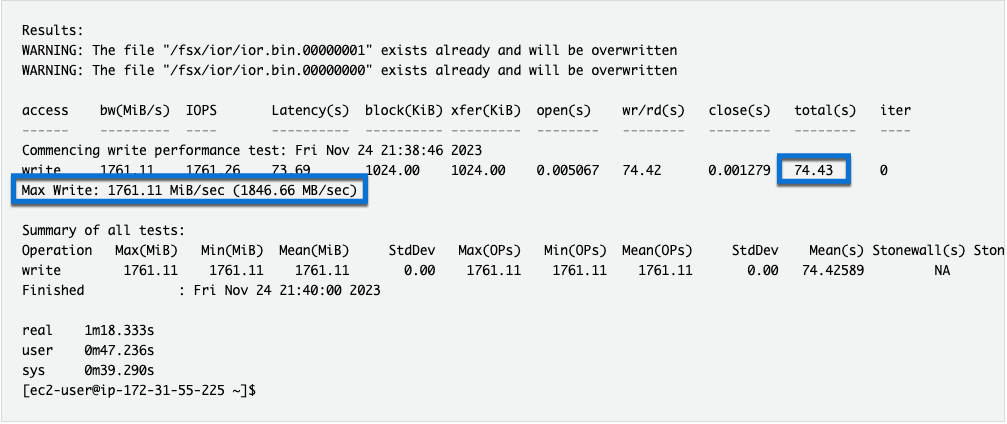
Results:
WARNING: The file "/fsx/ior/ior.bin.00000001" exists already and will be overwritten
WARNING: The file "/fsx/ior/ior.bin.00000000" exists already and will be overwritten
access bw(MiB/s) IOPS Latency(s) block(KiB) xfer(KiB) open(s) wr/rd(s) close(s) total(s) iter
------ --------- ---- ---------- ---------- --------- -------- -------- -------- -------- ----
Commencing write performance test: Mon Jan 20 12:09:10 2025
-
Wait for the ior job to complete.
- What was the Max Read: throughput?
- How long did it take?
- Use ior to read the data using one thread per core. The head node is a c6gn.4xlarge Amazon EC2 instance with 16 vcpus (cores).
time mpirun --map-by core ior -t 1m -b 1m -s ${_segment_count} -g -v -r -i 1 -F -k -D 0 -o ${_path}/ior.bin
IOR-4.0.0rc1: MPI Coordinated Test of Parallel I/O
Began : Mon Jan 20 12:15:20 2025
Command line : ior -t 1m -b 1m -s 8192 -g -v -r -i 1 -F -k -D 0 -o /fsx/ior/ior.bin
Machine : Linux ip-172-31-55-225
TestID : 0
StartTime : Mon Jan 20 12:15:20 2025
Path : /fsx/ior/ior.bin.00000000
FS : 6.7 TiB Used FS: 2.4% Inodes: 26.6 Mi Used Inodes: 1.5%
Participating tasks : 16
Options:
api : POSIX
apiVersion :
test filename : /fsx/ior/ior.bin
access : file-per-process
type : independent
segments : 8192
ordering in a file : sequential
ordering inter file : no tasks offsets
nodes : 1
tasks : 16
clients per node : 16
repetitions : 1
xfersize : 1 MiB
blocksize : 1 MiB
aggregate filesize : 128 GiB
verbose : 1
Results:
access bw(MiB/s) IOPS Latency(s) block(KiB) xfer(KiB) open(s) wr/rd(s) close(s) total(s) iter
------ --------- ---- ---------- ---------- --------- -------- -------- -------- -------- ----
Commencing read performance test: Mon Jan 20 12:15:20 2025
-
Wait for the ior job to complete.
- What was the Max Read: throughput?
- How long did it take?

-
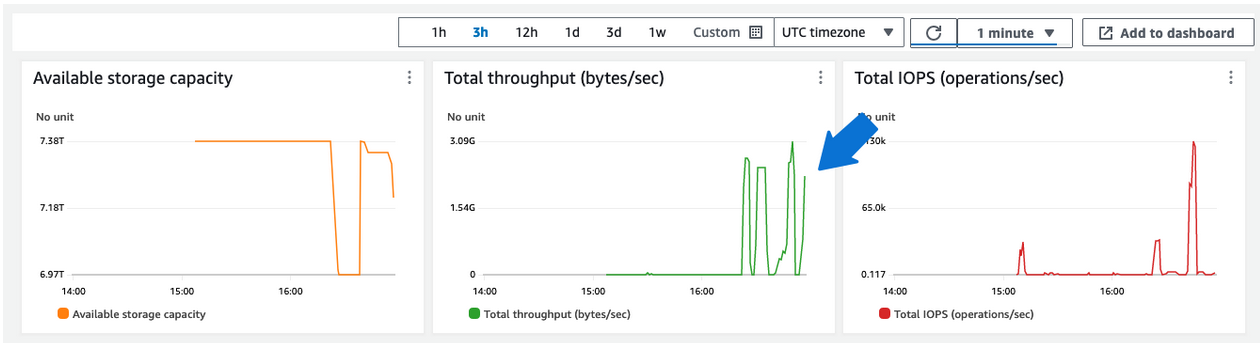
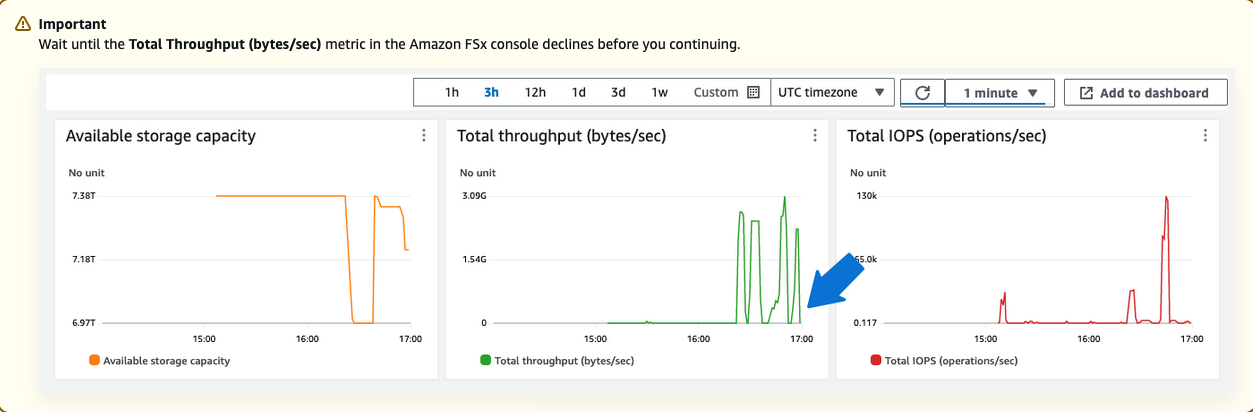
Navigate back to the Amazon FSx console. Monitor the Total throughput (bytes/sec) of the file system during the ior command. Amazon FSx publishes metrics to CloudWatch every minute, so you'll need to wait a few minutes for the graph to automatically refresh.