Installing SkyPilot and integrating SLURM and EKS
Setup SkyPilot
Install SkyPilot with Kubernetes Support
Start by installing SkyPilot with Kubernetes support using pip:
pip install skypilot-nightly[kubernetes]
This installs the latest nightly build of SkyPilot, which includes the necessary Kubernetes integrations.
Connect to Your SageMaker HyperPod EKS Cluster
First, configure your kubectl to connect to your EKS cluster:
aws eks update-kubeconfig --name $EKS_CLUSTER_NAME --region $EKS_REGION
Replace $EKS_CLUSTER_NAME and $EKS_REGION with your specific EKS cluster name and AWS region.
Verify SkyPilot's Connection to the Kubernetes Cluster
Check if SkyPilot can connect to your Kubernetes cluster:
sky check k8s
The output should look similar to:

If this is your first time using SkyPilot with this Kubernetes cluster, you may see a hint to create GPU labels for your nodes. Follow the instructions by running:
python -m sky.utils.kubernetes.gpu_labeler --context <your-eks-context>
This script helps SkyPilot identify what GPU resources are available on each node in your cluster.
Discover Available GPUs in the Cluster
To see what GPU resources are available in your SageMaker HyperPod cluster:
sky show-gpus --cloud k8s
This will list all available GPU types and their counts:

Using SkyPilot interactively
Launch an Interactive Development Environment
You can also launch a SkyPilot cluster for interactive development:
sky launch -c dev --gpus H100
This command creates a development environment named "dev" with a single H100 GPU. SkyPilot handles the pod creation, resource allocation, and setup of the development environment.
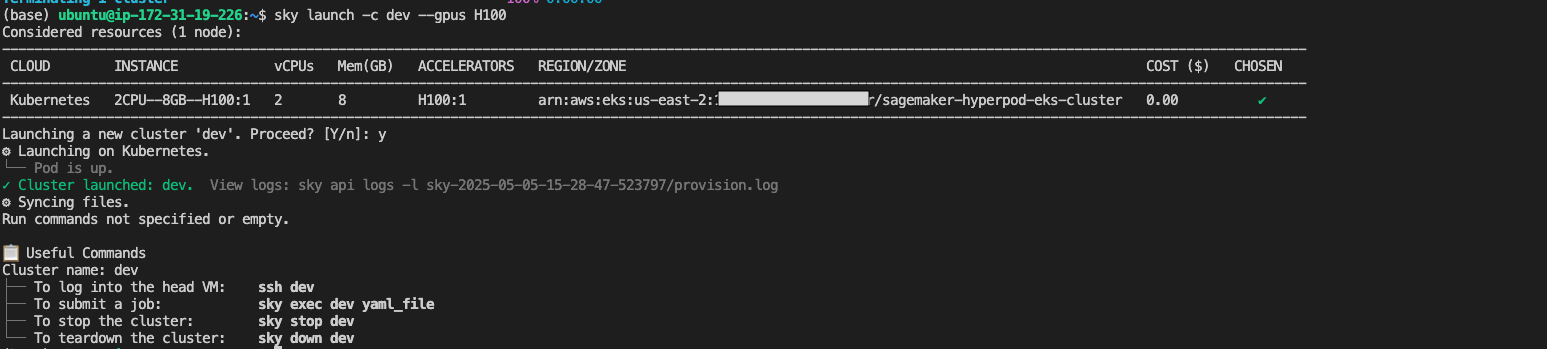
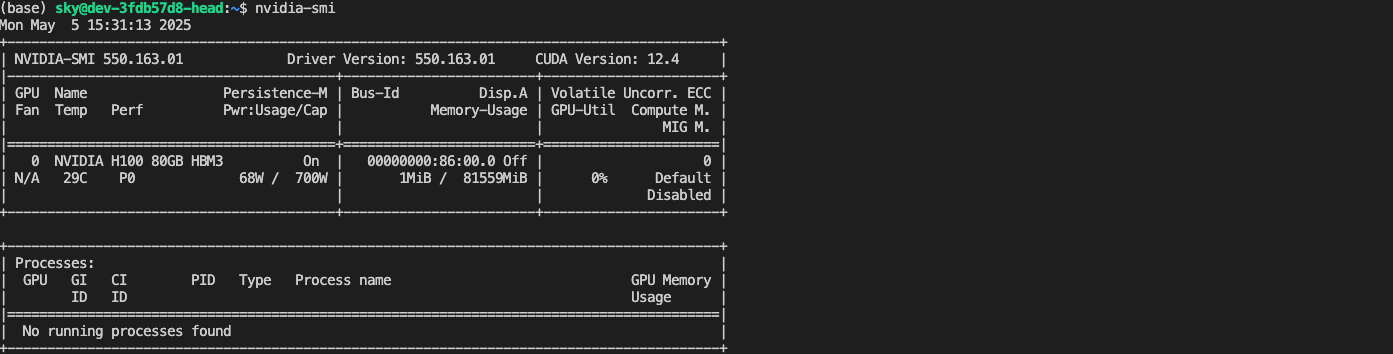
Once launched, you can connect to your development environment:
ssh dev
This gives you an interactive shell in your development environment, where you can run your code, install packages, and perform ML experiments.
Launching training jobs using SkyPilot
Creating and submitting your training job
SkyPilot makes it easy to run distributed training jobs on your SageMaker HyperPod cluster. Here's an example of launching a distributed training job on a single p5.48xlarge instance using a YAML configuration file:
First, create a file named train.yaml with your training job configuration:
resources:
accelerators: H100:8
num_nodes: 1
setup: |
git clone --depth 1 https://github.com/pytorch/examples || true
cd examples
git filter-branch --prune-empty --subdirectory-filter distributed/minGPT-ddp
uv venv --python 3.10
source .venv/bin/activate
uv pip install -r requirements.txt "numpy<2" "torch==1.12.1+cu113" --extra-index-url https://download.pytorch.org/whl/cu113
run: |
cd examples
source .venv/bin/activate
cd mingpt
export LOGLEVEL=INFO
MASTER_ADDR=$(echo "$SKYPILOT_NODE_IPS" | head -n1)
echo "Starting distributed training, head node: $MASTER_ADDR"
torchrun \
--nnodes=$SKYPILOT_NUM_NODES \
--nproc_per_node=$SKYPILOT_NUM_GPUS_PER_NODE \
--master_addr=$MASTER_ADDR \
--master_port=8008 \
--node_rank=${SKYPILOT_NODE_RANK} \
main.py
Then launch your training job:
sky launch -c train train.yaml
This will create a distributed training job that using 1 p5.48xlarge nodes, each with 8 H100 NVIDIA GPUs. You can monitor the output with:
sky logs train
Running Multi-node Training Jobs with EFA
For multi-node training, we leverage the Elastic Fabric Adapter (EFA). Elastic Fabric Adapter (EFA) is a network interface for Amazon EC2 instances that enables you to run applications requiring high levels of inter-node communications at scale on AWS. Its custom-built operating system bypass hardware interface enhances the performance of inter-instance communications, which is critical to scaling these applications. With EFA, High Performance Computing (HPC) applications using the Message Passing Interface (MPI) and Machine Learning (ML) applications using NVIDIA Collective Communications Library (NCCL) can scale to thousands of CPUs or GPUs. As a result, you get the application performance of on-premises HPC clusters with the on-demand elasticity and flexibility of the AWS cloud. Integrating EFA with applications running on Amazon EKS clusters can reduce the time to complete large scale distributed training workloads without having to add additional instances to your cluster.
Below is a code snippet showcasing how to run the NCCL tests across 2 p5.48xlarge nodes with EFA configuration in SkyPilot job:
name: nccl-test-efa
resources:
cloud: kubernetes
accelerators: H100:8
image_id: docker:public.ecr.aws/hpc-cloud/nccl-tests:latest
num_nodes: 2
envs:
USE_EFA: "true"
run: |
if [ "${SKYPILOT_NODE_RANK}" == "0" ]; then
echo "Head node"
# Total number of processes, NP should be the total number of GPUs in the cluster
NP=$(($SKYPILOT_NUM_GPUS_PER_NODE * $SKYPILOT_NUM_NODES))
# Append :${SKYPILOT_NUM_GPUS_PER_NODE} to each IP as slots
nodes=""
for ip in $SKYPILOT_NODE_IPS; do
nodes="${nodes}${ip}:${SKYPILOT_NUM_GPUS_PER_NODE},"
done
nodes=${nodes::-1}
echo "All nodes: ${nodes}"
# Set environment variables
export PATH=$PATH:/usr/local/cuda-12.2/bin:/opt/amazon/efa/bin:/usr/bin
export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64:/opt/amazon/openmpi/lib:/opt/nccl/build/lib:/opt/amazon/efa/lib:/opt/aws-ofi-nccl/install/lib:/usr/local/nvidia/lib:$LD_LIBRARY_PATH
export NCCL_HOME=/opt/nccl
export CUDA_HOME=/usr/local/cuda-12.2
export NCCL_DEBUG=INFO
export NCCL_BUFFSIZE=8388608
export NCCL_P2P_NET_CHUNKSIZE=524288
export NCCL_TUNER_PLUGIN=/opt/aws-ofi-nccl/install/lib/libnccl-ofi-tuner.so
if [ "${USE_EFA}" == "true" ]; then
export FI_PROVIDER="efa"
else
export FI_PROVIDER=""
fi
/opt/amazon/openmpi/bin/mpirun \
--allow-run-as-root \
--tag-output \
-H $nodes \
-np $NP \
-N $SKYPILOT_NUM_GPUS_PER_NODE \
--bind-to none \
-x FI_PROVIDER \
-x PATH \
-x LD_LIBRARY_PATH \
-x NCCL_DEBUG=INFO \
-x NCCL_BUFFSIZE \
-x NCCL_P2P_NET_CHUNKSIZE \
-x NCCL_TUNER_PLUGIN \
--mca pml ^cm,ucx \
--mca btl tcp,self \
--mca btl_tcp_if_exclude lo,docker0,veth_def_agent \
/opt/nccl-tests/build/all_reduce_perf \
-b 8 \
-e 2G \
-f 2 \
-g 1 \
-c 5 \
-w 5 \
-n 100
else
echo "Worker nodes"
fi
config:
kubernetes:
pod_config:
spec:
containers:
- resources:
limits:
nvidia.com/gpu: 8
vpc.amazonaws.com/efa: 32
requests:
nvidia.com/gpu: 8
vpc.amazonaws.com/efa: 32