SageMaker HyperPod Recipes Overview
Amazon SageMaker HyperPod recipes help you get started with training and fine-tuning publicly available foundation models. The recipes provide a pre-packaged set of training stack configurations that enable state-of-art training performance on SageMaker HyperPod. You can also easily switch between GPU-based instances and TRN-based instances with a simple recipe change.
The recipes are pre-configured training configurations for the following model families:
- Llama 3.1
- Llama 3.2
- Mistral
- Mixtral
To run the recipes within SageMaker HyperPod you use the Amazon SageMaker HyperPod training adapter as the framework to help you run end-to-end training workflows. The training adapter is built on NVIDIA NeMo framework and Neuronx Distributed Training package. If you’re familiar with using NeMo, the process of using the training adapter is the same. The training adapter runs the recipe on your cluster.
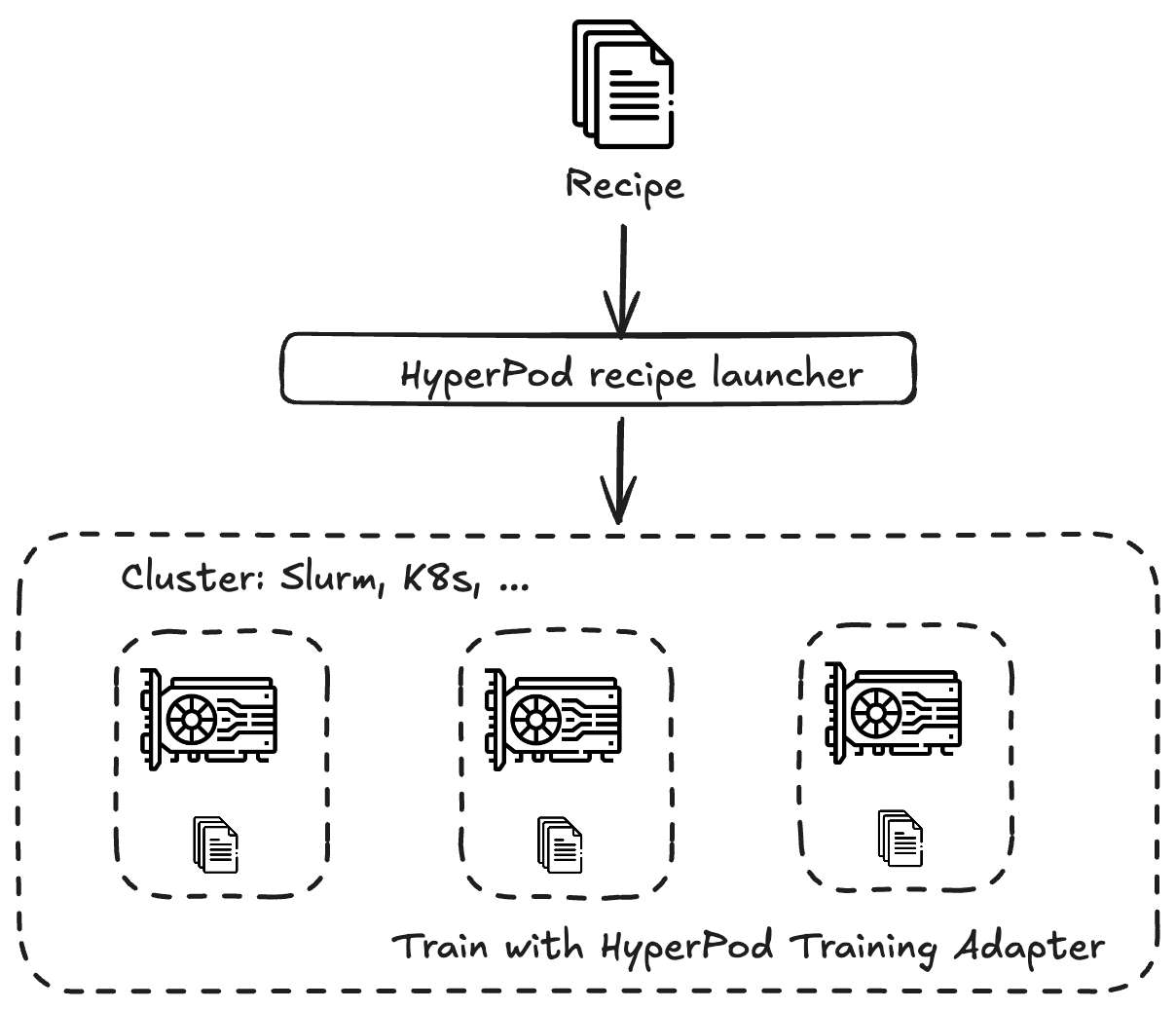
You can also train your own model by defining your own custom recipe.
Verified instance types, instance counts
P5.48xlarge
Supported Models
Pre-Training
Please refer to the link here for the list of supported model configs for Pre training.
Fine-Tuning
Please refer to the link here for the list of supported model configs for fine tuning.