Hybrid Deployment
Topics
Section titled “Topics”Overview
Section titled “Overview”Hybrid deployment enables flexible deployment: high-throughput LLM inference via SageMaker and Bedrock, and cost-effective local development using containerized graph/vector stores.
Stores and model providers
Section titled “Stores and model providers”The lexical-graph library depends on three backend systems: a graph store, a vector store, and a foundation model provider. The graph store enables storage and querying of a lexical graph built from unstructured, text-based sources. The vector store contains one or more indexes with embeddings for selected graph elements, which help identify starting points for graph queries. The foundation model provider hosts the Large Language Models (LLMs) used for extraction and embedding.
The library provides built-in support for:
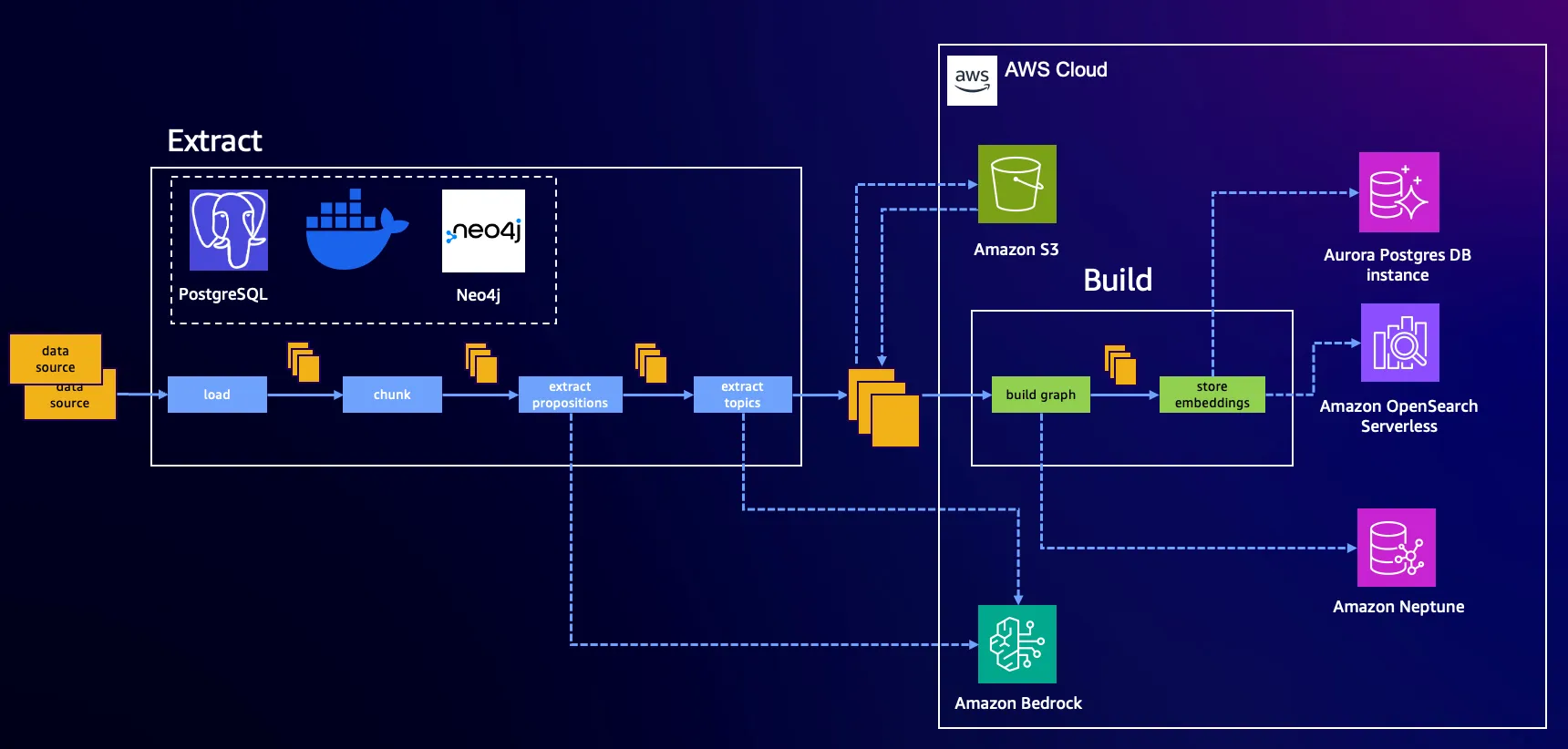
- Graph stores: Amazon Neptune Database, Amazon Neptune Analytics, and local FalkorDB (via Docker)
- Vector stores: Amazon OpenSearch Serverless, PostgreSQL with
pgvector, Neptune Analytics, and local PostgreSQL withpgvector - Foundation model provider: Amazon Bedrock
This hybrid configuration enables flexible deployment: high-throughput LLM inference via SageMaker and Bedrock, and cost-effective local development using containerized graph/vector stores.
Indexing and querying
Section titled “Indexing and querying”The lexical-graph library implements two high-level processes: indexing and querying. The indexing process ingests and extracts information from unstuctured, text-based source documents and then builds a graph and accompanying vector indexes. The query process retrieves content from the graph and vector indexes, and then supplies this content as context to an LLM to answer a user question.
Indexing
Section titled “Indexing”Indexing is split into two pipeline stages: Extract and Build.
The Extract stage runs locally using Docker:
-
Loads and chunks documents
-
Performs two LLM-based extraction steps:
- Proposition extraction: Converts chunked text into well-formed statements
- Topic/entity/fact extraction: Identifies relations and concepts
-
Stores the extracted results in an AWS S3 bucket, serving as the transport medium between stages
The Build stage remains unchanged.