Deployment of Enterprise RAG and AI-Q on EKS requires access to GPU instances (g5, p4, or p5 families). This blueprint relies on Karpenter autoscaling for dynamic GPU provisioning.
This blueprint provides two deployment options: Enterprise RAG Blueprint (multi-modal document processing with NVIDIA Nemotron and NeMo Retriever Models) or the full AI-Q Research Assistant (adds automated research reports with web search). Both run on Amazon EKS with dynamic GPU autoscaling.
Sources: NVIDIA RAG Blueprint | NVIDIA AI-Q Research Assistant
NVIDIA Enterprise RAG & AI-Q Research Assistant on Amazon EKS
What is NVIDIA AI-Q Research Assistant?
NVIDIA AI-Q Research Assistant is an AI-powered research assistant that creates custom AI researchers capable of operating anywhere, informed by your own data sources, synthesizing hours of research in minutes. The AI-Q NVIDIA Blueprint enables developers to connect AI agents to enterprise data and use reasoning and tools to distill in-depth source materials with efficiency and precision.
Key Capabilities
Advanced Research Automation:
- 5x faster token generation for rapid report synthesis
- 15x faster data ingestion with better semantic accuracy
- Summarize diverse data sets with efficiency and precision
- Generate comprehensive research reports automatically
NVIDIA NeMo Agent Toolkit:
- Ease development and optimization of agentic workflows
- Unify, evaluate, audit, and debug workflows across different frameworks
- Identify opportunities for optimization
- Flexibly choose and connect agents and tools best suited for each task
Advanced Semantic Query with NVIDIA NeMo Retriever:
- Multimodal PDF data extraction and retrieval (text, tables, charts, infographics)
- 15x faster ingestion of enterprise data
- 3x lower retrieval latency
- Multilingual and cross-lingual support
- Reranking to further improve accuracy
- GPU-accelerated index creation and search
Fast Reasoning with Llama Nemotron:
- Highest accuracy and lowest latency reasoning capabilities
- Uses Llama-3.3-Nemotron-Super-49B-v1.5 reasoning model
- Analyze data sources and identify patterns
- Propose solutions based on comprehensive research
- Context-aware generation backed by enterprise data
Web Search Integration:
- Real-time web search powered by Tavily API
- Supplements on-premise sources with current information
- Expands research beyond internal documents
AI-Q Components
Per the official AI-Q architecture:
1. NVIDIA AI Workbench
- Simplified development environment for agentic workflows
- Local testing and customization
- Easy configuration of different LLMs
- NVIDIA NeMo Agent Toolkit integration
2. NVIDIA RAG Blueprint
- Solution for querying large sets of on-premise multi-modal documents
- Supports text, images, tables, and charts extraction
- Semantic search and retrieval with GPU acceleration
- Foundation for AI-Q's research capabilities
3. NVIDIA NeMo Retriever Microservices
- Multi-modal document ingestion
- Graphic elements detection
- Table structure extraction
- PaddleOCR for text recognition
- 15x faster data ingestion
4. NVIDIA NIM Microservices
- Optimized inference containers for LLMs and vision models
- Llama-3.3-Nemotron-Super-49B-v1.5 reasoning model
- Llama-3.3-70B-Instruct model for report generation
- GPU-accelerated inference
5. Web Search (Tavily)
- Supplements on-premise sources with real-time web search
- Expands research beyond internal documents
- Powers web-augmented research reports
What is NVIDIA Enterprise RAG Blueprint?
The NVIDIA Enterprise RAG Blueprint is a production-ready reference workflow that provides a complete foundation for building scalable, customizable pipelines for both retrieval and generation. Powered by NVIDIA NeMo Retriever models and NVIDIA Llama Nemotron models, the blueprint is optimized for high accuracy, strong reasoning, and enterprise-scale throughput.
With built-in support for multimodal data ingestion, advanced retrieval, reranking, and reflection techniques, and seamless integration into LLM-powered workflows, it connects language models to enterprise data across text, tables, charts, audio, and infographics from millions of documents—enabling truly context-aware and generative responses.
Key Features
Data Ingestion and Processing:
- Multimodal PDF data extraction with text, tables, charts and infographics
- Audio file ingestion support
- Custom metadata support
- Document summarization
- Support for millions of documents at enterprise scale
Vector Database and Retrieval:
- Multi-collection searchability across document sets
- Hybrid search with dense and sparse search
- Reranking to further improve accuracy
- GPU-accelerated index creation and search
- Pluggable vector database architecture:
- ElasticSearch support
- Milvus support
- OpenSearch Serverless support (used in this deployment)
- Query decomposition for complex queries
- Dynamic metadata filter generation
Multimodal and Advanced Generation:
- Optional Vision Language Model (VLM) support in answer generation
- Opt-in image captioning with VLMs
- Multi-turn conversations for interactive Q&A
- Multi-session support for concurrent users
- Improve accuracy with optional reflection
Governance and Safety:
- Improve content safety with optional programmable guardrails
- Enterprise-grade security features
- Data privacy and compliance controls
Observability and Telemetry:
- Evaluation scripts included (RAGAS framework)
- OpenTelemetry support for distributed tracing
- Zipkin integration for trace visualization
- Grafana dashboards for metrics and monitoring
- Performance profiling and optimization tools
Developer Features:
- User interface included for testing and demos
- NIM Operator support for GPU sharing using DRA
- Native Python library support
- OpenAI-compatible APIs for easy integration
- Decomposable and customizable architecture
- Plug-in system for extending functionality
Enterprise RAG Use Cases
The Enterprise RAG Blueprint can be used standalone or as a component in larger systems:
- Enterprise search across document repositories
- Knowledge assistants for organizational knowledge bases
- Generative copilots for domain-specific applications
- Vertical AI workflows customized for specific industries
- Foundational component in agentic workflows (like AI-Q Research Assistant)
- Customer support automation with context-aware responses
- Document analysis and summarization at scale
Whether you're building enterprise search, knowledge assistants, generative copilots, or vertical AI workflows, the NVIDIA AI Blueprint for RAG delivers everything needed to move from prototype to production with confidence. It can be used standalone, combined with other NVIDIA Blueprints, or integrated into an agentic workflow to support more advanced reasoning-driven applications.
Overview
This blueprint implements the NVIDIA AI-Q Research Assistant on Amazon EKS, combining the NVIDIA RAG Blueprint with AI-Q components for comprehensive research capabilities.
Deployment Options
This blueprint supports two deployment modes based on your use case:
Option 1: Enterprise RAG Blueprint
- Deploy NVIDIA Enterprise RAG Blueprint with multi-modal document processing
- Includes NeMo Retriever microservices and OpenSearch integration
- Best for: Building custom RAG applications, document Q&A systems, knowledge bases
Option 2: Full AI-Q Research Assistant
- Includes everything from Option 1 plus AI-Q components
- Adds automated research report generation with web search capabilities via Tavily API
- Best for: Comprehensive research tasks, automated report generation, web-augmented research
Both deployments include Karpenter autoscaling and enterprise security features. You can start with Option 1 and add AI-Q components later as your needs evolve.
Deployment Approach
Why This Setup Process? While this implementation involves multiple steps, it provides several advantages:
- Complete Infrastructure: Automatically provisions VPC, EKS cluster, OpenSearch Serverless, and monitoring stack
- Enterprise Features: Includes security, monitoring, and scalability features
- AWS Integration: Leverages Karpenter autoscaling, EKS Pod Identity authentication, and managed AWS services
- Reproducible: Infrastructure as Code ensures consistent deployments across environments
Key Features
Performance Optimizations:
- Karpenter Autoscaling: Dynamic GPU node provisioning based on workload demands
- Intelligent Instance Selection: Automatically chooses optimal GPU instance types (G5, P4, P5)
- Bin-Packing: Efficient GPU utilization across multiple workloads
Enterprise Ready:
- OpenSearch Serverless: Managed vector database with automatic scaling
- Pod Identity Authentication: EKS Pod Identity for secure AWS IAM access from pods
- Observability Stack: Prometheus, Grafana, and DCGM for GPU monitoring
- Secure Access: Kubernetes port-forwarding for controlled service access
Architecture
AI-Q Research Assistant Architecture
The deployment uses Amazon EKS with Karpenter-based dynamic provisioning:
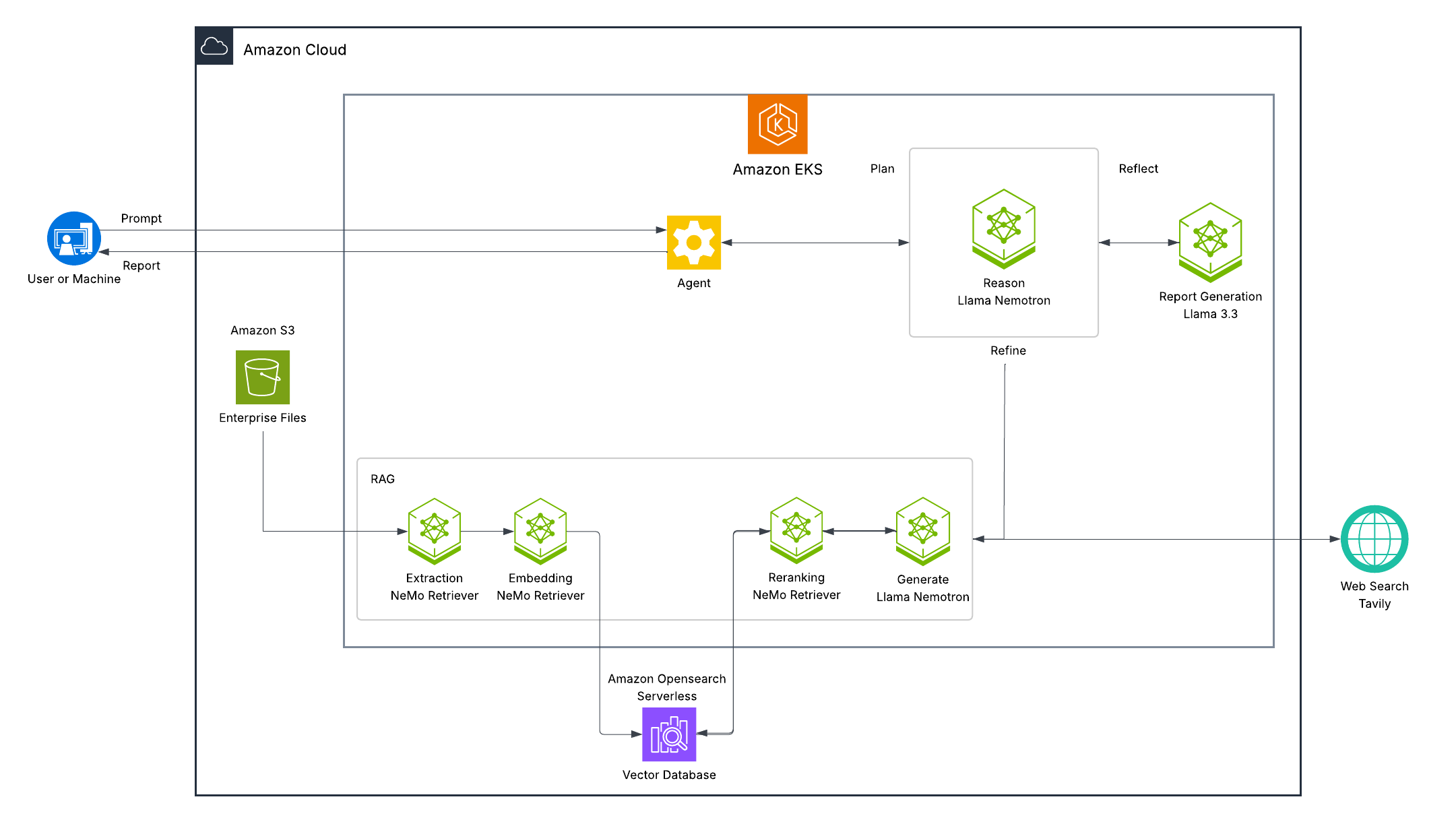
Enterprise RAG Blueprint Architecture
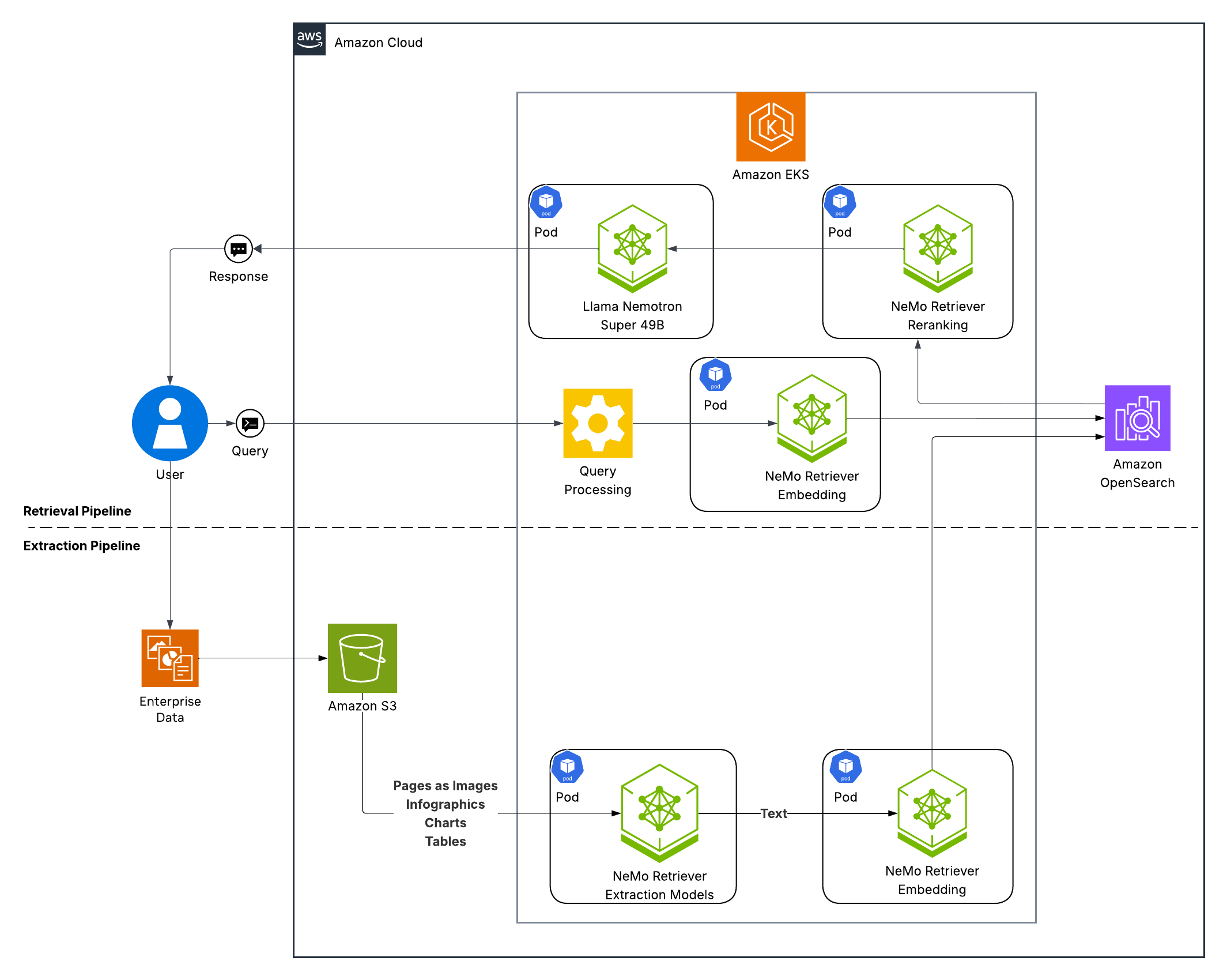
The RAG pipeline processes documents through multiple specialized NIM microservices:
1. Llama-3.3-Nemotron-Super-49B-v1.5
- Advanced reasoning model
- Primary reasoning and generation for both RAG and report writing
- Query rewriting and decomposition
- Filter expression generation
2. Embedding & Reranking
- LLama 3.2 NV-EmbedQA: 2048-dim embeddings
- LLama 3.2 NV-RerankQA: Relevance scoring
3. NV-Ingest Pipeline
- PaddleOCR: Text extraction from images
- Page Elements: Document layout understanding
- Graphic Elements: Chart and diagram detection
- Table Structure: Tabular data extraction
4. AI-Q Research Assistant Components
- Llama-3.3-70B-Instruct model for report generation (optional, 2 GPUs)
- Web search via Tavily API
- Backend orchestration for research workflows
Prerequisites
This deployment uses GPU instances which can incur significant costs. See Cost Considerations at the end of this guide for detailed cost estimates. Always clean up resources when not in use.
System Requirements: Any Linux/macOS system with AWS CLI access
Install the following tools:
- AWS CLI: Configured with appropriate permissions (installation guide)
- kubectl: Kubernetes command-line tool (installation guide)
- helm: Kubernetes package manager (installation guide)
- terraform: Infrastructure as code tool (installation guide)
- git: Version control (installation guide)
Required API Tokens
- NGC API Token: Required for accessing NVIDIA NIM containers and AI Foundation models
- First, sign up through one of these options (your API key will only work if you have one of these accounts):
- Option 1 - NVIDIA Developer Program (Quick Start):
- Sign up here
- Free account for POCs and development workloads
- Ideal for testing and evaluation
- Option 2 - NVIDIA AI Enterprise (Production):
- Subscribe via AWS Marketplace
- Enterprise license with full support and SLAs
- Required for production deployments
- Option 1 - NVIDIA Developer Program (Quick Start):
- Then, generate your API key:
- After signing up through Option 1 or 2, generate your API key at NGC Personal Keys
- Keep this key handy - it will be needed at deployment time
- First, sign up through one of these options (your API key will only work if you have one of these accounts):
- Tavily API Key: Optional for AI-Q Research Assistant
- Enables web search capabilities in AI-Q
- AI-Q can work in RAG-only mode without it
- Not needed for Enterprise RAG only deployment
- Create account at Tavily
- Generate API key from dashboard
- Keep this key handy - it will be needed at deployment time if you want web search in AI-Q
GPU Instance Access
Ensure your AWS account has access to GPU instances. This blueprint supports multiple instance families through Karpenter NodePools:
Supported GPU Instance Families:
| Instance Family | GPU Type | Performance Profile | Use Case |
|---|---|---|---|
| G5 (default) | NVIDIA A10G | Cost-effective, 24GB VRAM | General workloads, development |
| G6e | NVIDIA L40S | Balanced, 48GB VRAM | High-memory models |
| P4d/P4de | NVIDIA A100 | High-performance, 40/80GB VRAM | Large-scale deployments |
| P5/P5e/P5en | NVIDIA H100 | Ultra-high performance, 80GB VRAM | Maximum performance |
Note: G5 instances are pre-configured in the Helm values to provide an accessible starting point. You can switch to P4/P5/G6e instances by editing the
nodeSelectorin the Helm values files - no infrastructure changes required.
Customizing GPU Instance Types (Optional)
👈Getting Started
Clone the repository to begin:
git clone https://github.com/awslabs/ai-on-eks.git
cd ai-on-eks
Deployment
This blueprint provides two deployment methods:
Option A: Automated Deployment (Recommended)
👈Option B: Manual Deployment
👈Access Services
Once deployment is complete, access the services locally using port-forwarding.
Port Forwarding Commands
👈Using the Applications
RAG Frontend (http://localhost:3001):
- Upload documents directly through the UI
- Ask questions about your ingested documents
- Test multi-turn conversations
- View citations and sources
AI-Q Research Assistant (http://localhost:3000):
- Define research topics and questions
- Leverage both uploaded documents and web search
- Generate comprehensive research reports automatically
- Export reports in various formats
Ingestor API (http://localhost:8082/docs):
- Programmatic document ingestion
- Batch upload capabilities
- Collection management
- View OpenAPI documentation
Data Ingestion
After deploying RAG (and optionally AI-Q), you can ingest documents into the OpenSearch vector database.
Supported File Types
The RAG pipeline supports multi-modal document ingestion including:
- PDF documents
- Text files (.txt, .md)
- Images (.jpg, .png)
- Office documents (.docx, .pptx)
- HTML files
The NeMo Retriever microservices will automatically extract text, tables, charts, and images from these documents.
Ingestion Methods
You have two options for ingesting documents:
Method 1: UI Upload (Testing/Small Datasets)
Upload individual documents directly through the frontend interfaces:
- RAG Frontend (http://localhost:3001) - Ideal for testing individual documents
- AIRA Frontend (http://localhost:3000) - Upload documents for research tasks
This method is perfect for:
- Testing the RAG pipeline
- Small document collections (< 100 documents)
- Quick experimentation
- Ad-hoc document uploads
Method 2: S3 Batch Ingestion (Production/Large Datasets)
S3 Batch Ingestion Commands
👈Verifying Ingestion
After ingestion, verify your documents are available:
- Via RAG Frontend: Navigate to http://localhost:3001 and ask a question about your documents
- Via Ingestor API: Check http://localhost:8082/docs for collection statistics
- Via OpenSearch: Query the OpenSearch collection directly using the AWS Console
Observability
The RAG and AI-Q deployments include built-in observability tools for monitoring performance, tracing requests, and viewing metrics.
Access Monitoring Services
Automated Approach (Recommended):
Navigate to the blueprints directory and start port-forwarding:
cd ../../blueprints/inference/nvidia-deep-research
./app.sh port start observability
This automatically port-forwards:
- Zipkin: http://localhost:9411 - RAG distributed tracing
- Grafana: http://localhost:8080 - RAG metrics and dashboards
- Phoenix: http://localhost:6006 - AI-Q workflow tracing (if deployed)
Check status:
./app.sh port status
Stop observability port-forwards:
./app.sh port stop observability
Manual kubectl Commands
👈Monitoring UIs
Once port-forwarding is active:
-
Zipkin UI (RAG tracing): http://localhost:9411
- View end-to-end request traces
- Analyze latency bottlenecks
- Debug multi-service interactions
-
Grafana UI (RAG metrics): http://localhost:8080
- Default credentials: admin/admin
- Pre-built dashboards for RAG metrics
- GPU utilization and throughput monitoring
-
Phoenix UI (AI-Q tracing): http://localhost:6006
- Agent workflow visualization
- LLM call tracing
- Research report generation analysis
Note: For detailed information on using these observability tools, refer to:
Alternative: If you need to expose monitoring services publicly, you can create an Ingress resource with appropriate authentication and security controls.
Cleanup
Uninstall Applications Only
To remove the RAG and AI-Q applications while keeping the infrastructure:
Using Automation Script (Recommended):
cd ../../blueprints/inference/nvidia-deep-research
./app.sh cleanup
The cleanup script will:
- Stop all port-forwarding processes
- Uninstall AIRA and RAG Helm releases
- Remove local port-forward PID files
Manual Application Cleanup:
# Navigate to blueprints directory
cd ../../blueprints/inference/nvidia-deep-research
# Stop port-forwards
./app.sh port stop all
# Uninstall AIRA (if deployed)
helm uninstall aira -n nv-aira
# Uninstall RAG
helm uninstall rag -n rag
(Optional) Clean up temporary files created during deployment:
rm /tmp/.port-forward-*.pid
Note: This only removes the applications. The EKS cluster and infrastructure will remain running. GPU nodes will be terminated by Karpenter within 5-10 minutes.
Clean Up Infrastructure
To remove the entire EKS cluster and all infrastructure components:
# Navigate to infra directory
cd ../../../infra/nvidia-deep-research
# Run cleanup script
./cleanup.sh
Warning: This will permanently delete:
- EKS cluster and all workloads
- OpenSearch Serverless collection and data
- VPC and networking resources
- All associated AWS resources
Backup important data before proceeding.
Duration: ~10-15 minutes for complete teardown
Cost Considerations
Estimated Costs for This Deployment
👈References
Official NVIDIA Resources
📚 Documentation:
- NVIDIA AI-Q Research Assistant GitHub: Official AI-Q blueprint repository
- NVIDIA AI-Q on AI Foundation: AI-Q blueprint card and hosted version
- NVIDIA RAG Blueprint: Complete RAG platform documentation
- NVIDIA NIM Documentation: NIM microservices reference
- NVIDIA AI Enterprise: Enterprise AI platform
🤖 Models:
- Llama-3.3-Nemotron-Super-49B-v1.5: Advanced reasoning model (49B parameters)
- Llama-3.3-70B-Instruct: Instruction-following model
📦 Container Images & Helm Charts:
- NVIDIA NGC Catalog: Official container registry
- RAG Blueprint Helm Chart: Kubernetes deployment
- NVIDIA NIM Containers: Optimized inference containers
AI-on-EKS Blueprint Resources
🏗️ AI-on-EKS Blueprint Resources:
- AI-on-EKS Repository: Main blueprint repository
- Infrastructure & Deployment Code: Terraform automation with Karpenter and application deployment scripts
- Usage Guide: Post-deployment usage, data ingestion, and observability
📖 Documentation:
- Infrastructure & Deployment Guide: Step-by-step infrastructure and application deployment
- Usage Guide: Accessing services, data ingestion, monitoring
- OpenSearch Integration: Pod Identity authentication setup
- Karpenter Configuration: P4/P5 GPU support
Related Technologies
☸️ Kubernetes & AWS:
- Amazon EKS: Managed Kubernetes service
- Karpenter: Kubernetes node autoscaling
- OpenSearch Serverless: Managed vector database
- EKS Pod Identity: IAM authentication for pods
🤖 AI/ML Tools:
- NVIDIA DCGM: GPU monitoring
- Prometheus: Metrics collection
- Grafana: Visualization dashboards
Next Steps
- Explore Features: Test multi-modal document processing with various file types
- Scale Deployments: Configure multi-region or multi-cluster setups
- Integrate Applications: Connect your applications to the RAG API endpoints
- Monitor Performance: Use Grafana dashboards for ongoing monitoring
- Custom Models: Swap in your own fine-tuned models
- Security Hardening: Add authentication, rate limiting, and disaster recovery
This deployment provides the NVIDIA Enterprise RAG Blueprint and NVIDIA AI-Q Research Assistant on Amazon EKS with enterprise-grade features including Karpenter automatic scaling, OpenSearch Serverless integration, and seamless AWS service integration.