EKS에 ML 모델을 배포하려면 GPU 또는 Neuron 인스턴스에 대한 액세스가 필요합니다. 배포가 작동하지 않는 경우 이러한 리소스에 대한 액세스가 누락되어 있기 때문인 경우가 많습니다. 또한 일부 배포 패턴은 Karpenter 오토스케일링 및 정적 노드 그룹에 의존합니다. 노드가 초기화되지 않으면 Karpenter 또는 노드 그룹의 로그를 확인하여 문제를 해결하십시오.
참고: 이 Llama-2 모델의 사용은 Meta 라이선스의 적용을 받습니다. 모델 가중치와 토크나이저를 다운로드하려면 웹사이트를 방문하여 액세스를 요청하기 전에 라이선스에 동의해 주십시오.
관측성, 로깅 및 확장성 측면의 개선 사항을 포함하기 위해 이 블루프린트를 적극적으로 개선하고 있습니다.
Inferentia, Ray Serve 및 Gradio를 사용한 Llama-2-13b Chat 모델 서빙
Ray Serve를 사용하여 Amazon Elastic Kubernetes Service (EKS)에 Meta Llama-2-13b chat 모델을 배포하는 포괄적인 가이드에 오신 것을 환영합니다.
이 튜토리얼에서는 Llama-2의 강력한 기능을 활용하는 방법뿐만 아니라 대규모 언어 모델(LLM)을 효율적으로 배포하는 복잡한 과정에 대한 통찰력을 얻을 수 있습니다. 특히 대규모 언어 모델 배포 및 확장에 최적화된 inf2.24xlarge 및 inf2.48xlarge와 같은 trn1/inf2 (AWS Trainium 및 Inferentia 기반) 인스턴스에서의 배포를 다룹니다.
Llama-2란?
Llama-2는 2조 개의 텍스트 및 코드 토큰으로 훈련된 사전 훈련된 대규모 언어 모델(LLM)입니다. 현재 사용 가능한 가장 크고 강력한 LLM 중 하나입니다. Llama-2는 자연어 처리, 텍스트 생성 및 번역을 포함한 다양한 작업에 사용할 수 있습니다.
Llama-2-chat
Llama-2는 엄격한 훈련 과정을 거친 뛰어난 언어 모델입니다. 공개적으로 사용 가능한 온라인 데이터를 사용한 사전 훈련으로 시작합니다. 그런 다음 지도 미세 조정을 통해 초기 버전의 Llama-2-chat이 생성됩니다.
이후 Llama-2-chat은 거부 샘플링 및 근접 정책 최적화(PPO)와 같은 기술을 포함하는 인간 피드백을 통한 강화 학습(RLHF)을 사용하여 반복적으로 정제됩니다.
이 프로세스를 통해 Amazon EKS와 Ray Serve에서 효과적으로 배포하고 활용할 수 있도록 안내하는 고도로 유능하고 미세 조정된 언어 모델이 생성됩니다.
Llama-2는 세 가지 모델 크기로 제공됩니다:
- Llama-2-70b: 700억 개의 파라미터를 가진 가장 큰 Llama-2 모델입니다. 가장 강력한 Llama-2 모델이며 가장 까다로운 작업에 사용할 수 있습니다.
- Llama-2-13b: 130억 개의 파라미터를 가진 중간 크기의 Llama-2 모델입니다. 성능과 효율성 사이의 좋은 균형을 제공하며 다양한 작업에 사용할 수 있습니다.
- Llama-2-7b: 70억 개의 파라미터를 가진 가장 작은 Llama-2 모델입니다. 가장 효율적인 Llama-2 모델이며 최고 수준의 성능이 �필요하지 않은 작업에 사용할 수 있습니다.
어떤 Llama-2 모델 크기를 사용해야 하나요?
가장 적합한 Llama-2 모델 크기는 특정 요구 사항에 따라 달라지며, 최고의 성능을 달성하기 위해 항상 가장 큰 모델이 필요한 것은 아닙니다. 적절한 Llama-2 모델 크기를 선택할 때 컴퓨팅 리소스, 응답 시간 및 비용 효율성과 같은 요소를 고려하여 요구 사항을 평가하는 것이 좋습니다. 결정은 애플리케이션의 목표와 제약 조건에 대한 포괄적인 평가를 기반으로 해야 합니다.
Trn1/Inf2 인스턴스에서의 추론: Llama-2의 잠재력 극대화
Llama-2는 다양한 하드웨어 플랫폼에 배포할 수 있으며, 각각 고유한 장점이 있습니다. 그러나 Llama-2의 효율성, 확장성 및 비용 효율성을 최대화하는 데 있어 AWS Trn1/Inf2 인스턴스가 최적의 선택입니다.
확장성 및 가용성
Llama-2와 같은 대규모 언어 모델(LLM)을 배포할 때 주요 과제 중 하나는 적절한 하드웨어의 확장성과 가용성입니다. 기존 GPU 인스턴스는 높은 수요로 인해 부족한 경우가 많아 리소스를 효과적으로 프로비저닝하고 확장하기가 어렵습니다.
반면 trn1.32xlarge, trn1n.32xlarge, inf2.24xlarge 및 inf2.48xlarge와 같은 Trn1/Inf2 인스턴스는 LLM을 포함한 생성형 AI 모델의 고성능 딥러닝(DL) 훈련 및 추론을 위해 특별히 구축되었습니다. 확장성과 가용성을 모두 제공하여 리소스 병목 현상이나 지연 없이 필요에 따라 Llama-2 모델을 배포하고 확장할 수 있습니다.
비용 최적화: 기존 GPU 인스턴스에서 LLM을 실행하면 GPU의 부족과 경쟁적인 가격으로 인해 비용이 많이 들 수 있습니다. Trn1/Inf2 인스턴스는 비용 효율적인 대안을 제공합니다. AI 및 기계 학습 작업에 최적화된 전용 하드웨어를 제공함으로써 Trn1/Inf2 인스턴스를 통해 비용의 일부로 최고 수준의 성능을 달성할 수 있습니다. 이러한 비용 최적화를 통해 예산을 효율적으로 할당하여 LLM 배포를 접근 가능하고 지속 가능하게 만들 수 있습니다.
성능 향상 Llama-2는 GPU에서 고성능 추론을 달성할 수 있지만, Neuron 가속기는 성능을 한 단계 더 끌어올립니다. Neuron 가속기는 기계 학습 워크로드를 위해 특별히 구축되어 Llama-2의 추론 속도를 크게 향상시키는 하드웨어 가속을 제공합니다. 이는 Trn1/Inf2 인스턴스에 Llama-2를 배포할 때 더 빠른 응답 시간과 개선된 사용자 경험으로 이어집니다.
모델 사양
아래 표는 다양한 크기의 Llama-2 모델, 가중치 및 배포를 위한 하드웨어 요구 사항에 대한 정보를 제공합니다. 이 정보를 사용하여 모든 크기의 Llama-2 모델을 배포하는 데 필요한 인프라를 설계할 수 있습니다. 예를 들어 Llama-2-13b-chat 모델을 배포하려면 총 가속기 메모리가 최소 26 GB인 인스턴스 유형을 사용해야 합니다.
| 모델 | 가중치 | 바이트 | 파라미터 크기 (10억) | 총 가속기 메모리 (GB) | NeuronCore당 가속기 메모리 크기 (GB) | 필요한 Neuron 코어 | 필요한 Neuron 가속기 | 인스턴스 유형 | tp_degree |
|---|---|---|---|---|---|---|---|---|---|
| Meta/Llama-2-70b | float16 | 2 | 70 | 140 | 16 | 9 | 5 | inf2.48x | 24 |
| Meta/Llama-2-13b | float16 | 2 | 13 | 26 | 16 | 2 | 1 | inf2.24x | 12 |
| Meta/Llama-2-7b | float16 | 2 | 7 | 14 | 16 | 1 | 1 | inf2.24x | 12 |
예제 사용 사례
회사가 고객 지원을 제공하기 위해 Llama-2 챗봇을 배포하려고 합니다. 회사는 대규모 고객 기반을 보유하고 있으며 피크 시간에 많은 양의 채팅 요청을 받을 것으로 예상합니다. 회사는 높은 요청량을 처리하고 빠른 응답 시간을 제공할 수 있는 인프라를 설계해야 합니다.
회사는 Inferentia2 인스턴스를 사용하여 Llama-2 챗봇을 효율적으로 확장할 수 있습니다. Inferentia2 인스턴스는 기계 학습 작업을 위한 특수 하드웨어 가속기입니다. 기계 학습 워크로드에 대해 GPU보다 최대 20배 더 나은 성능과 최대 7배 더 낮은 비용을 제공할 수 있습니다.
회사는 또한 Ray Serve를 사용하여 Llama-2 챗봇을 수평으로 확장할 수 있습니다. Ray Serve는 기계 학습 모델을 서빙하기 위한 분산 프레임워크입니다. 수요에 따라 모델을 자동으로 확장하거나 축소할 수 있습니다.
Llama-2 챗봇을 확장하기 위해 회사는 여러 Inferentia2 인스턴스를 배포하고 Ray Serve를 사용하여 인스턴스 간에 트래픽을 분산할 수 있습니다. 이를 통해 회사는 높은 요청량을 처리하고 빠른 응답 시간을 제공할 수 있습니다.
솔루션 아키텍처
이 섹션에서는 Amazon EKS에서 Llama-2 모델, Ray Serve 및 Inferentia2를 결합한 솔루션의 아키텍처를 자세히 살펴봅니다.
솔루션 배포
Amazon EKS에 Llama-2-13b chat을 배포하려면 필요한 사전 요구 사항을 다루고 배포 프로세스를 단계별로 안내합니다.
여기에는 인프라 설정, Ray 클러스터 배포 및 Gradio WebUI 앱 생성이 포함됩니다.
사전 요구 사항
👈Llama-2-Chat 모델이 있는 Ray 클러스터 배포
Trainium on EKS 클러스터가 배포되면 kubectl을 사용하여 ray-service-Llama-2.yaml을 배포할 수 있습니다.
이 단계에서는 Karpenter 오토스케일링을 사용하는 x86 CPU 인스턴스의 Head Pod 하나와 Karpenter에 의해 오토스케일링되는 Inf2.48xlarge 인스턴스의 Ray 워커로 구성된 Ray Serve 클러스터를 배포합니다.
배포를 진행하기 전에 이 배포에서 사용되는 주요 파일을 자세히 살펴보고 기능을 이해해 봅시다:
-
ray_serve_Llama-2.py: 이 스크립트는 FastAPI, Ray Serve 및 PyTorch 기반 Hugging Face Transformers를 사용하여 NousResearch/Llama-2-13b-chat-hf 언어 모델을 사용한 효율적인 텍스트 생성 API를 생성합니다. 또는 사용자는 meta-llama/Llama-2-13b-chat-hf 모델로 유연하게 전환할 수 있습니다. 스크립트는 입력 문장을 수락하고 향상된 성능을 위한 Neuron 가속의 이점을 활용하여 텍스트 출력을 효율적으로 생성하는 엔드포인트를 설정합니다. 높은 구성 가능성으로 사용자는 챗봇 및 텍스트 생성 작업을 포함한 다양한 자연어 처리 애플리케이션에 맞게 모델 파라미터를 미세 조정할 수 있습니다.
-
ray-service-Llama-2.yaml: 이 Ray Serve YAML 파일은
Llama-2-13b-chat모델을 사용한 효율적인 텍스트 생성을 용이하게 하는 Ray Serve 서비스를 배포하기 위한 Kubernetes 구성 역할을 합니다. 리소스를 분리하기 위해Llama-2라는 Kubernetes 네임스페이스를 정의합니다. 구성 내에서Llama-2-service라는RayService사양이 생성되고Llama-2네임스페이스 내에 호스팅됩니다.RayService사양은 Ray Serve 서비스를 생성하기 위해 Python 스크립트ray_serve_Llama-2.py(같은 폴더 내의 Dockerfile에 복사됨)를 활용합니다. 이 예제에서 사용된 Docker 이미지는 배포 용이성을 위해 Amazon Elastic Container Registry (ECR)에 공개적으로 제공됩니다. 사용자는 특정 요구 사항에 맞게 Dockerfile을 수정하고 자체 ECR 리포지토리에 푸시하여 YAML 파일에서 참조할 수도 있습니다.
1단계: Llama-2-Chat 모델 배포
클러스터가 �로컬에서 구성되었는지 확인
aws eks --region us-west-2 update-kubeconfig --name trainium-inferentia
RayServe 클러스터 배포
cd ai-on-eks/blueprints/inference/llama2-13b-chat-rayserve-inf2
kubectl apply -f ray-service-llama2.yaml
다음 명령을 실행하여 배포 확인
배포 프로세스는 최대 10분이 소요될 수 있습니다. Head Pod는 2~3분 내에 준비되고, Ray Serve 워커 Pod는 Huggingface에서 이미지 검색 및 모델 배포에 최대 10분이 소요될 수 있습니다.
kubectl get all -n llama2
출력:
NAME READY STATUS RESTARTS AGE
pod/llama2-raycluster-fcmtr-head-bf58d 1/1 Running 0 67m
pod/llama2-raycluster-fcmtr-worker-inf2-lgnb2 1/1 Running 0 5m30s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/llama2 ClusterIP 172.20.118.243 <none> 10001/TCP,8000/TCP,8080/TCP,6379/TCP,8265/TCP 67m
service/llama2-head-svc ClusterIP 172.20.168.94 <none> 8080/TCP,6379/TCP,8265/TCP,10001/TCP,8000/TCP 57m
service/llama2-serve-svc ClusterIP 172.20.61.167 <none> 8000/TCP 57m
NAME DESIRED WORKERS AVAILABLE WORKERS CPUS MEMORY GPUS STATUS AGE
raycluster.ray.io/llama2-raycluster-fcmtr 1 1 184 704565270Ki 0 ready 67m
NAME SERVICE STATUS NUM SERVE ENDPOINTS
rayservice.ray.io/llama2 Running 2
kubectl get ingress -n llama2
출력:
NAME CLASS HOSTS ADDRESS PORTS AGE
llama2 nginx * k8s-ingressn-ingressn-aca7f16a80-1223456666.elb.us-west-2.amazonaws.com 80 69m
이 블루프린트는 보안상의 이유로 내부 로드 밸런서를 배포하므로 동일한 VPC에 있지 않으면 브라우저에서 액세스할 수 없을 수 있습니다. 여기의 지침에 따라 NLB를 공개로 설정하도록 블루프린트를 수정할 수 있습니다.
또는 로드 밸런서를 사용하지 않고 서비스를 테스트하기 위해 포트 포워딩을 사용할 수 있습니다.
이제 아래의 로드 밸런서 URL을 사용하여 Ray 대시보드에 액세스할 수 있습니다. <NLB_DNS_NAME>을 NLB 엔드포인트로 바꾸십시오:
http://\<NLB_DNS_NAME\>/dashboard/#/serve
공개 로드 밸런서에 액세스할 수 없는 경우 포트 포워딩을 사용하고 다음 명령으로 localhost를 사용하여 Ray 대시보드를 탐색할 수 있습니다:
kubectl port-forward service/llama2 8265:8265 -n llama2
브라우저에서 링크 열기: http://localhost:8265/
이 웹페이지에서 아래 이미지와 같이 모델 배포 진행 상황을 모니터링할 수 있습니다:
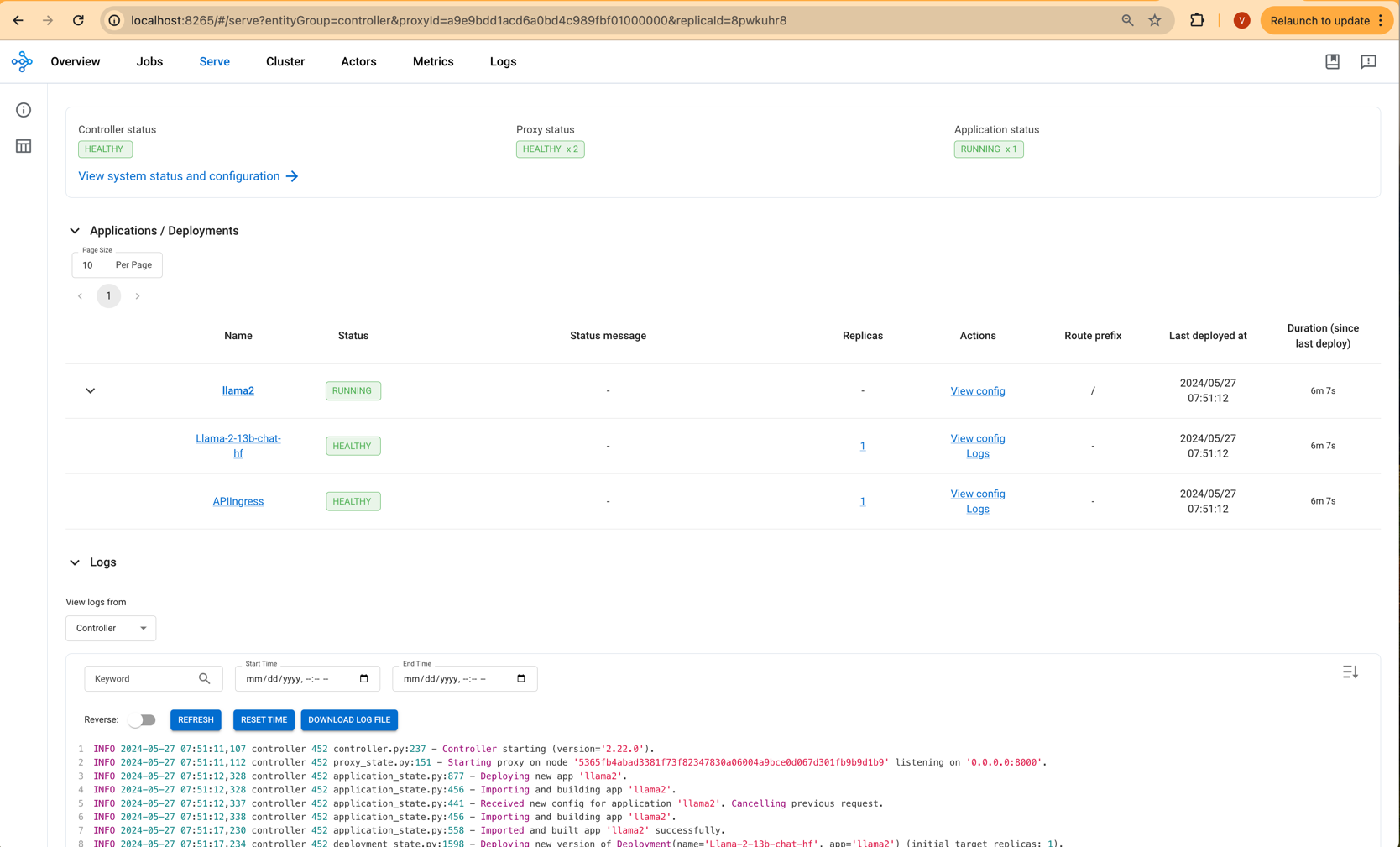
2단계: Llama-2-Chat 모델 테스트
모델 배포 상태가 running 상태가 되면 Llama-2-chat 사용을 시작할 수 있습니다.
포트 포워딩 사용
먼저 포트 포워딩을 사용하여 서비스에 로컬로 액세스합니다:
kubectl port-forward service/llama2-serve-svc 8000:8000 -n llama2
그런 다음 URL 끝에 쿼리를 추가하여 다음 URL로 모델을 테스트할 수 있습니다:
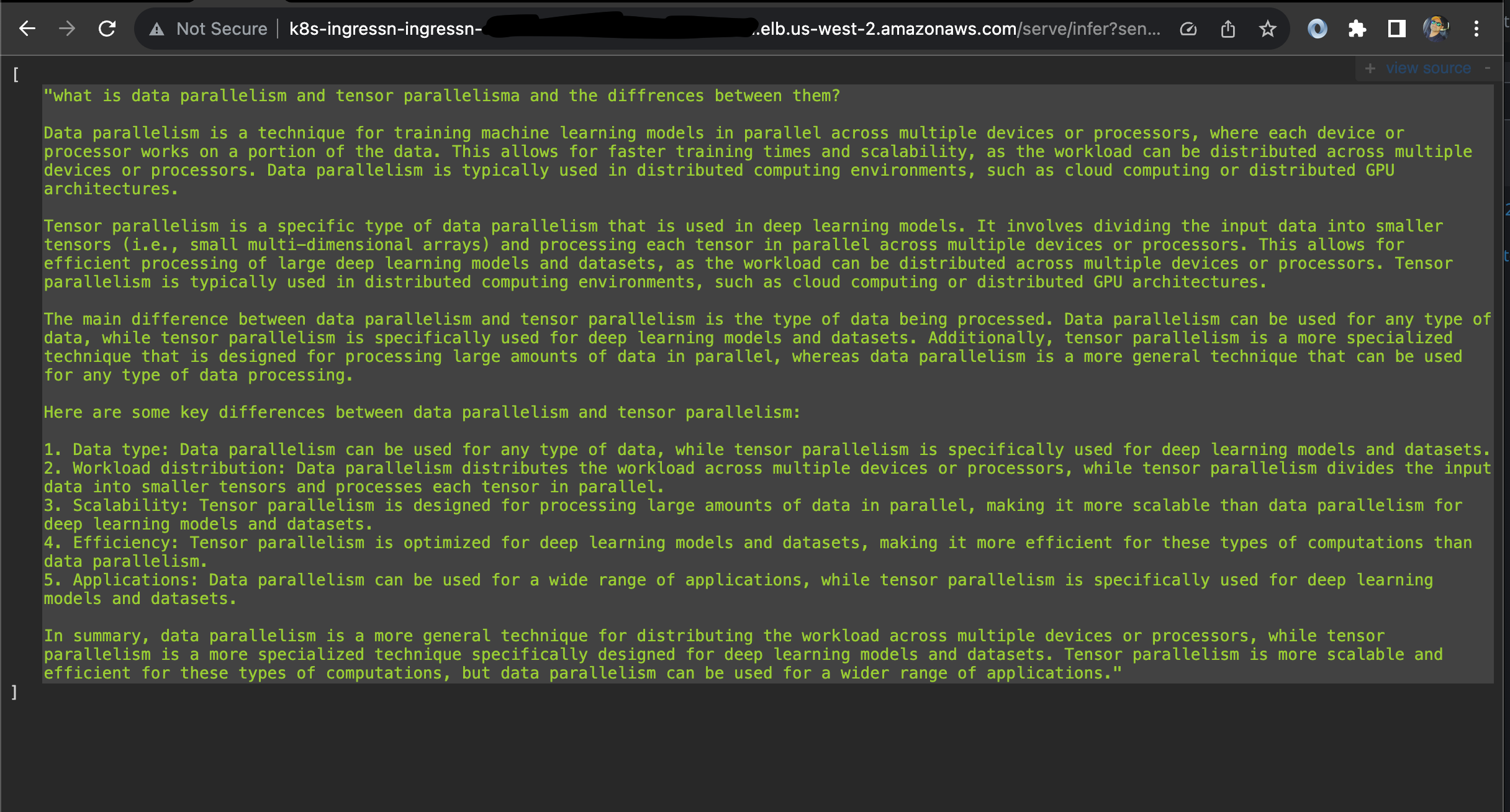
http://localhost:8000/infer?sentence=what is data parallelism and tensor parallelism and the differences
브라우저에서 다음과 같은 출력을 볼 수 있습니다.

NLB 사용:
Network Load Balancer (NLB)를 사용하려는 경우 여기의 지침에 따라 NLB를 공개로 설정하도록 블루프린트를 수정할 수 있습니다.
그런 다음 URL 끝에 쿼리를 추가하여 다음 URL을 사용할 수 있습니다:
http://\<NLB_DNS_NAME\>/serve/infer?sentence=what is data parallelism and tensor parallelisma and the differences
브라우저에서 다음과 같은 출력을 볼 수 있습니다:
3단계: Gradio WebUI 앱 배포
Gradio Web UI는 inf2 인스턴스를 사용하여 EKS 클러스터에 배포된 Llama2 추론 서비스와 상호 작용하는 데 사용됩니다.
Gradio UI는 서비스 이름과 포트를 사용하여 포트 8000에서 노출되는 Llama2 서비스(llama2-serve-svc.llama2.svc.cluster.local:8000)와 내부적으로 통신합니다.
Gradio 앱을 위한 기본 Docker(ai/inference/gradio-ui/Dockerfile-gradio-base) 이미지를 생성했으며, 이는 모든 모델 추론에 사용할 수 있습니다.
이 이미지는 Public ECR에 게시되어 있습니다.
Gradio 앱 배포 단계:
다음 YAML 스크립트(ai/inference/llama2-13b-chat-rayserve-inf2/gradio-ui.yaml)는 모델 클라이언트 스크립트가 포함된 전용 네임스페이스, 배포, 서비스 및 ConfigMap을 생성합니다.
이를 배포하려면 다음을 실행합니다:
cd ai-on-eks/blueprints/inference/llama2-13b-chat-rayserve-inf2/
kubectl apply -f gradio-ui.yaml
확인 단계: 다음 명령을 실행하여 배포, 서비스 및 ConfigMap을 확인합니다:
kubectl get deployments -n gradio-llama2-inf2
kubectl get services -n gradio-llama2-inf2
kubectl get configmaps -n gradio-llama2-inf2
서비스 포트 포워딩:
로컬에서 Web UI에 액세스할 수 있도록 포트 포워딩 명령을 실행합니다:
kubectl port-forward service/gradio-service 7860:7860 -n gradio-llama2-inf2
WebUI 호출
웹 브라우저를 열고 다음 URL로 이동하여 Gradio WebUI에 액세스합니다:
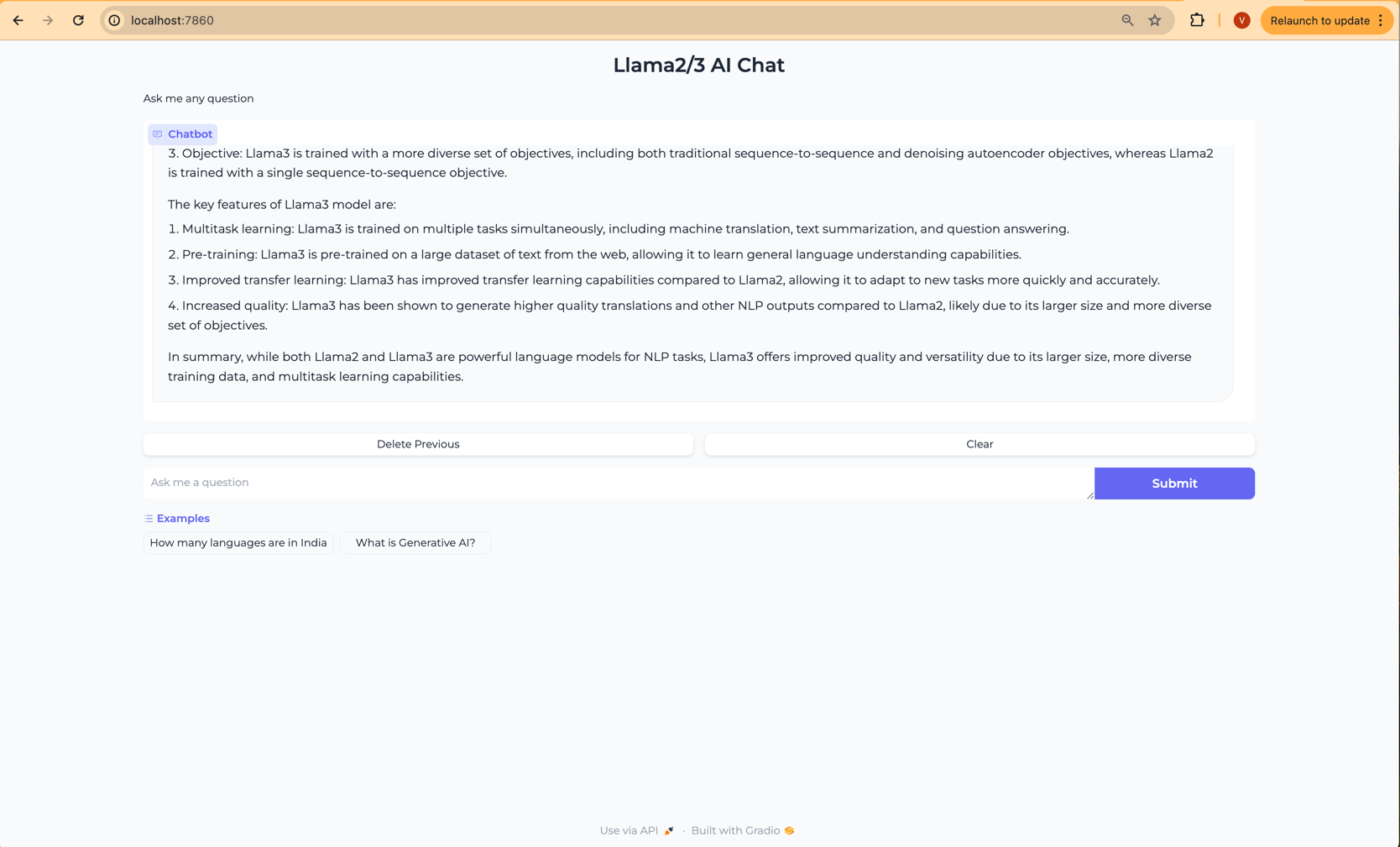
로컬 URL에서 실행 중: http://localhost:7860
이제 로컬 머신에서 Gradio 애플리케이션과 상호 작용할 수 있습니다.
결론
결론적으로, Llama-2-13b chat 모델을 Ray Serve와 함께 EKS에 성공적으로 배포하고 Gradio를 사용하여 chatGPT 스타일의 채팅 웹 UI를 생성했습니다. 이는 자연어 처리 및 챗봇 개발에 흥미로운 가능성을 열어줍니다.
요약하면, Llama-2를 배포하고 확장할 때 AWS Trn1/Inf2 인스턴스는 매력적인 이점을 제공합니다. GPU 부족과 관련된 문제를 극복하면서 대규모 언어 모델을 효율적이고 접근 가능하게 실행하는 데 필요한 확장성, 비용 최적화 및 성능 향상을 제공합니다. 챗봇, 자연어 처리 애플리케이션 또는 기타 LLM 기반 솔루션을 구축하든 Trn1/Inf2 인스턴스를 통해 AWS 클라우드에서 Llama-2의 잠재력을 최대한 활용할 수 있습니다.
정리
마지막으로 더 이상 필요하지 않은 리소스를 정리하고 프로비저닝 해제하는 방법을 안내합니다.
1단계: Gradio 앱 및 Llama2 추론 배포 삭제
cd ai-on-eks/blueprints/inference/llama2-13b-chat-rayserve-inf2
kubectl delete -f gradio-ui.yaml
kubectl delete -f ray-service-llama2.yaml
2단계: EKS 클러스터 정리
이 스크립트는 -target 옵션을 사용하여 모든 리소스가 올바른 순서로 삭제되도록 환경을 정리합니다.
cd ai-on-eks/infra/trainium-inferentia
./cleanup.sh