EKS에 ML 모델을 배포하려면 GPU 또는 Neuron 인스턴스에 대한 액세스가 필요합니다. 배포가 작동하지 않는 경우 이러한 리소스에 대한 액세스가 누락되어 있기 때문인 경우가 많습니다. 또한 일부 배포 패턴은 Karpenter 오토스케일링 및 정적 노드 그룹에 의존합니다. 노드가 초기화되지 않으면 Karpenter 또는 노드 그룹의 로그를 확인하여 문제를 해결하십시오.
참고: 이 Llama-3 Instruct 모델의 사용은 Meta 라이선스의 적용을 받습니다. 모델 가중��치와 토크나이저를 다운로드하려면 웹사이트를 방문하여 액세스를 요청하기 전에 라이선스에 동의해 주십시오.
관측성, 로깅 및 확장성 측면의 개선 사항을 포함하기 위해 이 블루프린트를 적극적으로 개선하고 있습니다.
AWS Neuron에서 RayServe와 vLLM을 사용한 LLM 서빙
Ray Serve와 AWS Neuron을 사용하여 Amazon Elastic Kubernetes Service (EKS)에 LLM을 배포하는 포괄적인 가이드에 오신 것을 환영합니다.
AWS Neuron이란?
이 튜토리얼에서는 AWS Inferentia 및 Trainium 가속기에서 딥러닝 성능을 최적화하는 강력한 SDK인 AWS Neuron을 활용합니다. Neuron은 PyTorch 및 TensorFlow와 같은 프레임워크와 원활하게 통합되어 Inf1, Inf2, Trn1 및 Trn1n과 같은 특수 EC2 인스턴스에서 고성능 기계 학습 모델을 개발, 프로파일링 및 배포하기 위한 포괄적인 툴킷을 제공합니��다.
vLLM이란?
vLLM은 처리량을 극대화하고 지연 시간을 최소화하도록 설계된 LLM 추론 및 서빙을 위한 고성능 라이브러리입니다. 핵심적으로 vLLM은 GPU 리소스의 최적 활용을 가능하게 하여 메모리 효율성을 크게 개선하는 혁신적인 어텐션 알고리즘인 PagedAttention을 활용합니다. 이 오픈 소스 솔루션은 Python API 및 OpenAI 호환 서버를 통한 원활한 통합을 제공하여 개발자가 프로덕션 환경에서 Llama 3와 같은 대규모 언어 모델을 전례 없는 효율성으로 배포하고 확장할 수 있게 합니다.
RayServe란?
Ray Serve는 Ray 위에 구축된 확장 가능한 모델 서빙 라이브러리로, 프레임워크 불가지론적 배포, 모델 구성 및 내장 확장과 같은 기능을 갖춘 기계 학습 모델 및 AI 애플리케이션을 배포하도록 설계되었습니다. KubeRay 프로젝트의 일부인 Kubernetes 사용자 정의 리소스인 RayService도 접하게 되며, 이는 Kubernetes 클러스터에서 Ray Serve 애플리케이션을 배포하고 관리하는 데 사용됩니다.
Llama-3-8B Instruct란?
Meta는 8B 및 70B 크기의 사전 훈련 및 명령어 조정 생성 텍스트 모델 컬렉션인 Meta Llama 3 대규모 언어 모델(LLM) 제품군을 개발하고 출시했습니다. Llama 3 명령어 조정 모델은 대화 사용 사례에 최적화되어 있으며 일반적인 업계 벤치마크에서 사용 가능한 많은 오픈 소스 채팅 모델을 능가합니다. 또한 이러한 모델을 개발할 때 유용성과 안전성을 최적화하는 데 세심한 주의를 기울였습니다.
Llama3 크기 및 모델 아키텍처에 대한 자세한 정보는 여기에서 확인할 수 있습니다.
왜 AWS 가속기인가?
확장성 및 가용성
Llama-3와 같은 대규모 언어 모델(LLM)을 배포할 때 주요 과제 중 하나는 적절한 하드웨어의 확장성과 가용성입니다. 기존 GPU 인스턴스는 높은 수요로 인해 부족한 경우가 많아 리소스를 효과적으로 프로비저닝하고 확장하기가 어렵습니다.
반면 trn1.32xlarge, trn1n.32xlarge, inf2.24xlarge 및 inf2.48xlarge와 같은 Trn1/Inf2 인스턴스는 LLM을 포함한 생성형 AI 모델의 고성능 딥러닝(DL) 훈련 및 추론을 위해 특별히 구축되었습니다. 확장성과 가용성을 모두 제공하여 리소스 병목 현상이나 지연 없이 필요에 따라 Llama-3 모델을 배포하고 확장할 수 있습니다.
비용 최적화
기존 GPU 인�스턴스에서 LLM을 실행하면 GPU의 부족과 경쟁적인 가격으로 인해 비용이 많이 들 수 있습니다. Trn1/Inf2 인스턴스는 비용 효율적인 대안을 제공합니다. AI 및 기계 학습 작업에 최적화된 전용 하드웨어를 제공함으로써 Trn1/Inf2 인스턴스를 통해 비용의 일부로 최고 수준의 성능을 달성할 수 있습니다. 이러한 비용 최적화를 통해 예산을 효율적으로 할당하여 LLM 배포를 접근 가능하고 지속 가능하게 만들 수 있습니다.
성능 향상
Llama-3는 GPU에서 고성능 추론을 달성할 수 있지만, Neuron 가속기는 성능을 한 단계 더 끌어올립니다. Neuron 가속기는 기계 학습 워크로드를 위해 특별히 구축되어 Llama-3의 추론 속도를 크게 향상시키는 하드웨어 가속을 제공합니다. 이는 Trn1/Inf2 인스턴스에 Llama-3를 배포할 때 더 빠른 응답 시간과 개선된 사용자 경험으로 이어집니다.
솔루션 아키텍처
이 섹션에서는 Amazon EKS에서 Llama-3 모델, Ray Serve 및 Inferentia2를 결합한 솔루션의 아키텍처를 자세히 살펴봅니다.
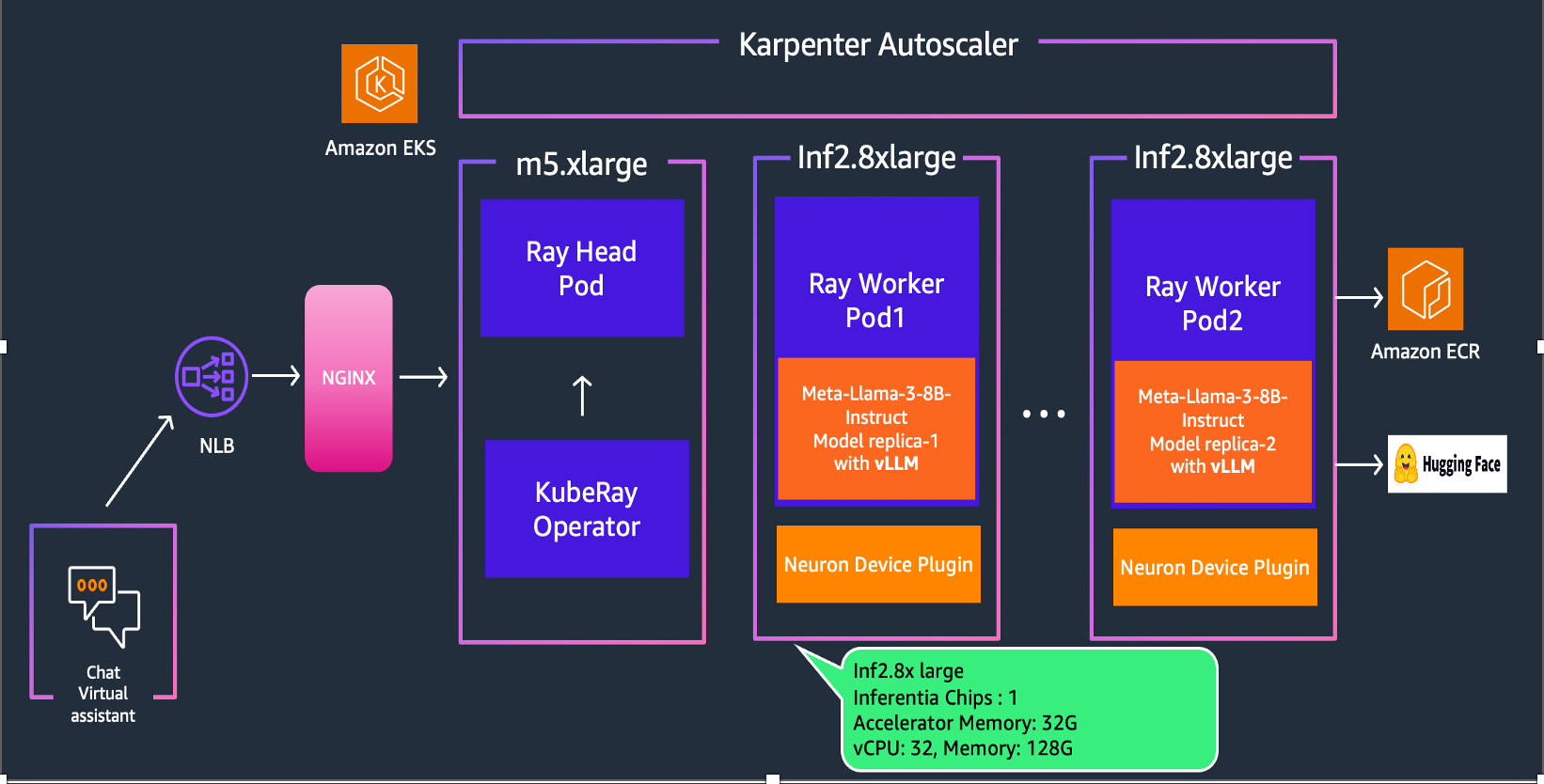
솔루션 배포
Amazon EKS에 Llama-3-8B-instruct를 배포하려면 필요한 사전 요구 사항을 다루고 배포 프로세스를 단계별로 안내합니다.
여기에는 AWS Inferentia 인스턴스를 사용한 인프라 설정 및 Ray 클러스터 배포가 포함됩니다.
사전 요구 사항
👈Llama3 모델이 있는 Ray 클러스터 배포
이 튜토리얼에서는 RayCluster, RayJob 및 RayService와 같은 Ray 특정 구성에 대한 사용자 정의 리소스 정의로 Kubernetes를 확장하는 KubeRay operator를 활용합니다. operator는 이러한 리소스와 관련된 사용자 이벤트를 감시하고, Ray 클러스터를 형성하는 데 필요한 Kubernetes 아티팩트를 자동으로 생성하며, 원하는 구성이 실제 상태와 일치하도록 클러스터 상태를 지속적으로 모니터링합니다. 설정, 워커 그룹의 동적 확장 및 해제를 포함한 수명 주기 관리를 처리하여 Kubernetes에서 Ray 애플리케이션을 관리하는 복잡성을 추상화합니다.
각 Ray 클러스터는 헤드 노드 pod와 워커 노드 pod 모음으로 구성되며, 워크로드 요구 사항에 따라 클러스터 크기를 조정하는 선택적 오토스케일링 지원이 있습니다. KubeRay는 이기종 컴퓨팅 노드(GPU 포함) 및 동일한 Kubernetes 클러스터에서 다른 Ray 버전으로 여러 Ray 클러스터 실행을 지원합니다. 또한 KubeRay는 AWS Inferentia 가속기와 통합되어 특수 하드웨어에서 Llama 3와 같은 대규모 언어 모델을 효율적으로 배포하여 기계 학습 추론 작업의 성능과 비용 효율성을 잠재적으로 개선할 수 있습니다.
필요한 모든 구성 요소와 함께 EKS 클러스터를 배포했으므로 이제 AWS 가속기에서 RayServe 및 vLLM을 사용하여 NousResearch/Meta-Llama-3-8B-Instruct를 배포하는 단계를 진행할 수 있습니다.
1단계: RayService 클러스터를 배포하려면 vllm-rayserve-deployment.yaml 파일이 있는 디렉토리로 이동하고 터미널에서 kubectl apply 명령을 실행합니다.
이렇게 하면 RayService 구성이 적용되고 EKS 설정에 클러스터가 배포됩니다.
cd ai-on-eks/blueprints/inference/vllm-rayserve-inf2
kubectl apply -f vllm-rayserve-deployment.yaml
선택적 구성
기본적으로 inf2.8xlarge 인스턴스가 프로비저닝됩니다. inf2.48xlarge를 사용하려면 vllm-rayserve-deployment.yaml 파일을 수정하여 worker 컨테이너 아래의 resources 섹션을 변경합니다.
limits:
cpu: "30"
memory: "110G"
aws.amazon.com/neuron: "1"
requests:
cpu: "30"
memory: "110G"
aws.amazon.com/neuron: "1"
다음으로 변경:
limits:
cpu: "90"
memory: "360G"
aws.amazon.com/neuron: "12"
requests:
cpu: "90"
memory: "360G"
aws.amazon.com/neuron: "12"
선택 사항: 70B 모델 배포
inf2.48xlarge에서 llama-70B 모델을 배포하려면 ai-on-eks/blueprints/inference/vllm-rayserve-inf2/vllm-rayserve-deployment-70B.yaml을 참조하십시오. 이 배포는 대형 모델을 다운로드하고 Neuron 코�어에서 실행하기 위해 컴파일하는 데 약 60분이 소요됩니다.
2단계: 다음 명령을 실행하여 배포 확인
배포가 성공적으로 완료되었는지 확인하려면 다음 명령을 실행합니다:
배포 프로세스는 최대 10분이 소요될 수 있습니다. Head Pod는 5~6분 내에 준비되고, Ray Serve 워커 Pod는 Huggingface에서 이미지 검색 및 모델 배포에 최대 10분이 소요될 수 있습니다.
RayServe 구성에 따라 x86 인스턴스에서 실행되는 Ray head pod 하나와 inf2 인스턴스에서 실행되는 워커 pod 하나가 있습니다. RayServe YAML 파일을 수정하여 여러 레플리카를 실행할 수 있습니다. 그러나 각 추가 레플리카는 잠재적으로 새 인스턴스를 생성할 수 있음에 유의하십시오.
kubectl get pods -n vllm
NAME READY STATUS RESTARTS AGE
lm-llama3-inf2-raycluster-ksh7w-worker-inf2-group-dcs5n 1/1 Running 0 2d4h
vllm-llama3-inf2-raycluster-ksh7w-head-4ck8f 2/2 Running 0 2d4h
이 배포는 또한 여러 포트가 구성된 서비스를 구성합니다. 포트 8265는 Ray 대시보드용이고 포트 8000은 vLLM 추론 서버 엔드포인트용입니다.
다음 명령을 실행하여 서비스를 확인합니다:
kubectl get svc -n vllm
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
vllm ClusterIP 172.20.23.54 <none> 8080/TCP,6379/TCP,8265/TCP,10001/TCP,8000/TCP 2d4h
vllm-llama3-inf2-head-svc ClusterIP 172.20.18.130 <none> 6379/TCP,8265/TCP,10001/TCP,8000/TCP,8080/TCP 2d4h
vllm-llama3-inf2-serve-svc ClusterIP 172.20.153.10 <none> 8000/TCP 2d4h
Ray 대시보드에 액세스하려면 관련 포트를 로컬 머신으로 포트 포워딩할 수 있습니다:
kubectl -n vllm port-forward svc/vllm 8265:8265
그런 다음 Ray 에코시스템 내의 작업 및 액터 배포를 표시하는 http://localhost:8265에서 웹 UI에 액세스할 수 있습니다.
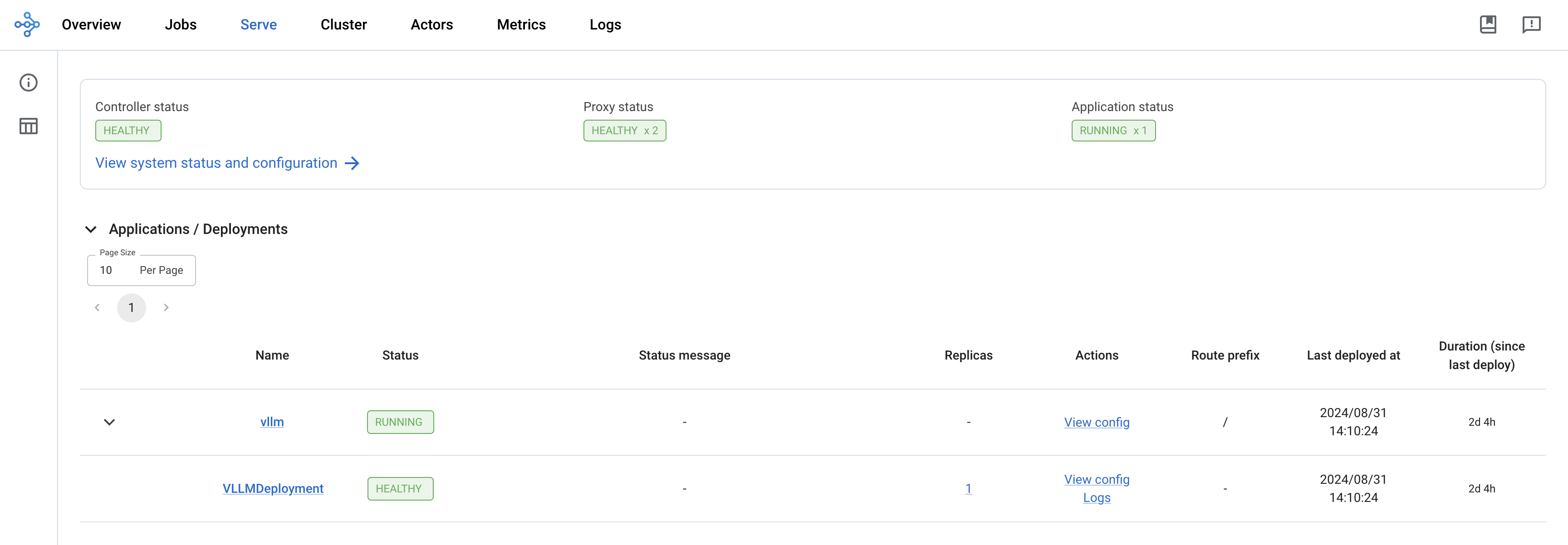
배포가 완료되면 Controller 및 Proxy 상태가 HEALTHY이고 Application 상태가 RUNNING이어야 합니다
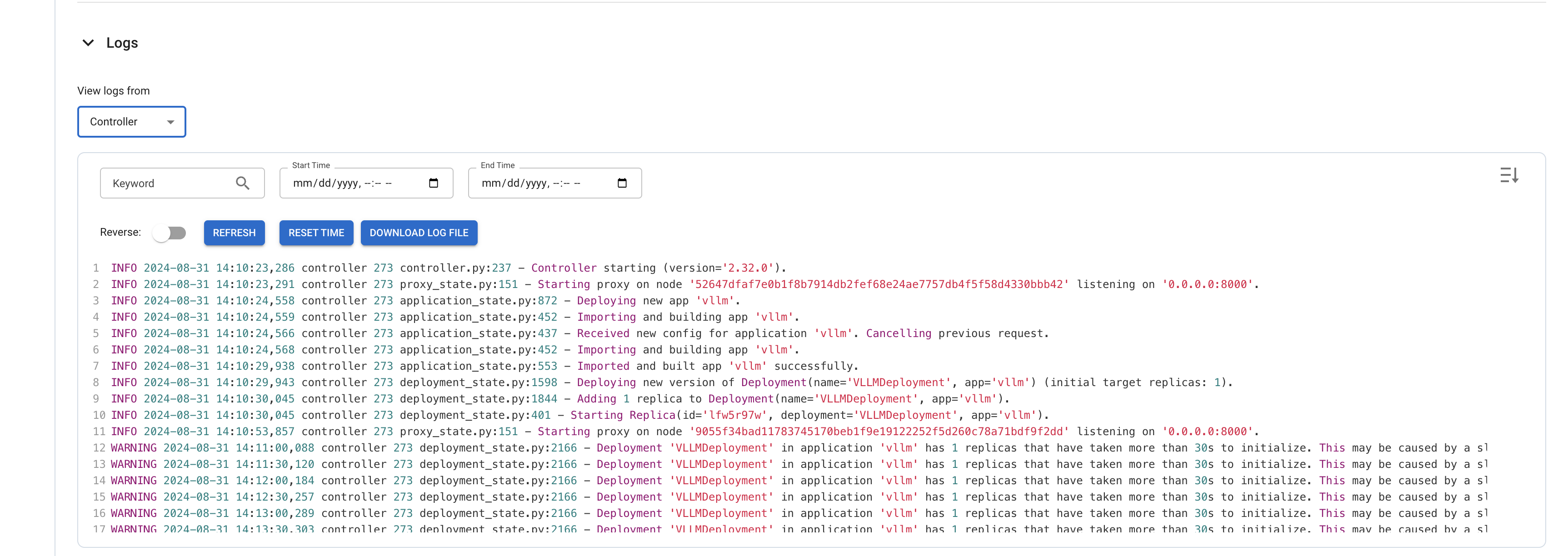
Llama3 모델 테스트
이제 Meta-Llama-3-8B-Instruct 채팅 모델을 테스트할 시간입니다. Python 클라이언트 스크립트를 사용하여 RayServe 추론 엔드포인트에 프롬프트를 보내고 모델이 생성한 출력을 확인합니다.
먼저 kubectl을 사용�하여 vllm-llama3-inf2-serve-svc 서비스로 포트 포워딩을 실행합니다:
kubectl -n vllm port-forward svc/vllm-llama3-inf2-serve-svc 8000:8000
openai-client.py는 HTTP POST 메서드를 사용하여 vllm 서버를 대상으로 텍스트 완성 및 Q&A를 위해 추론 엔드포인트에 프롬프트 목록을 보냅니다.
가상 환경에서 Python 클라이언트 애플리케이션을 실행하려면 다음 단계를 따르십시오:
cd ai-on-eks/blueprints/inference/vllm-rayserve-inf2
python3 -m venv .venv
source .venv/bin/activate
pip3 install openai
python3 openai-client.py
터미널에서 다음과 유사한 출력을 볼 수 있습니다:
Python 클라이언트 터미널 출력을 보려면 클릭하십시오
Example 1 - Simple chat completion:
Handling connection for 8000
The capital of India is New Delhi.
Example 2 - Chat completion with different parameters:
The twin suns of Tatooine set slowly in the horizon, casting a warm orange glow over the bustling spaceport of Anchorhead. Amidst the hustle and bustle, a young farm boy named Anakin Skywalker sat atop a dusty speeder, his eyes fixed on the horizon as he dreamed of adventure beyond the desert planet.
As the suns dipped below the dunes, Anakin's uncle, Owen Lars, called out to him from the doorway of their humble moisture farm. "Anakin, it's time to head back! Your aunt and I have prepared a special dinner in your honor."
But Anakin was torn. He had received a strange message from an unknown sender, hinting at a great destiny waiting for him. Against his uncle's warnings, Anakin decided to investigate further, sneaking away into the night to follow the mysterious clues.
As he rode his speeder through the desert, the darkness seemed to grow thicker, and the silence was broken only by the distant
Example 3 - Streaming chat completion:
I'd be happy to help you with that. Here we go:
1...
(Pause)
2...
(Pause)
3...
(Pause)
4...
(Pause)
5...
(Pause)
6...
(Pause)
7...
(Pause)
8...
(Pause)
9...
(Pause)
10!
Let me know if you have any other requests!
관측성
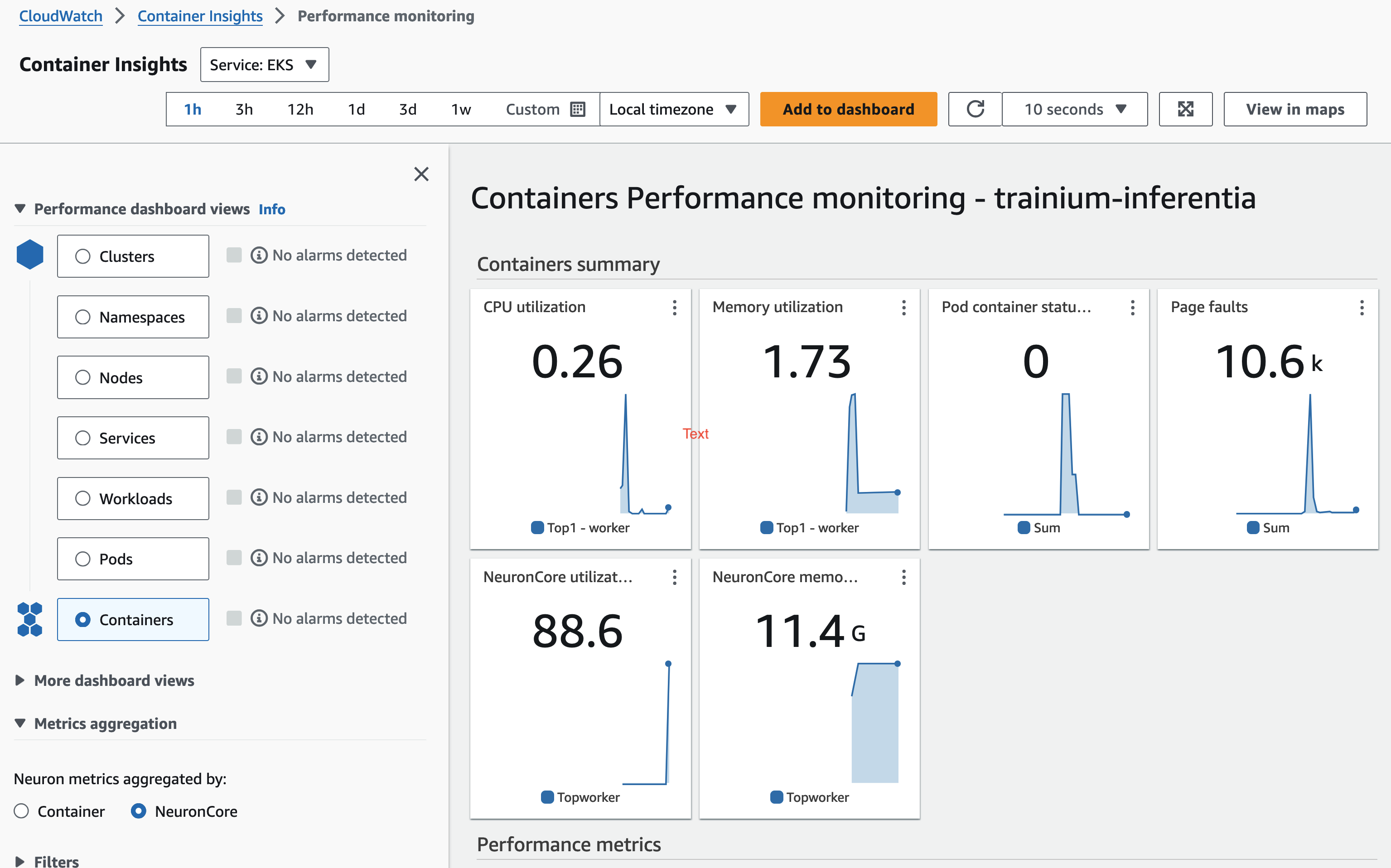
AWS CloudWatch 및 Neuron Monitor를 통한 관측성
이 블루프린트는 CloudWatch Observability Agent를 관리형 애드온으로 배포하여 컨테이너화된 워크로드에 대한 포괄적인 모니터링을 제공합니다. CPU 및 메모리 사용률과 같은 주요 성능 메트릭을 추적하기 위한 container insights가 포함됩니다. 또한 애드온은 Neuron Monitor 플러그인을 활용하여 Neuron 특정 메트릭을 캡처하고 보고합니다.
container insights 및 Neuron Core 사용률, NeuronCore 메모리 사용량과 같은 Neuron 메트릭을 포함한 모든 메트릭은 Amazon CloudWatch로 전송되어 실시간으로 모니터링하고 분석할 수 있습니다. 배포가 완료되면 CloudWatch 콘솔에서 직접 이러한 메트릭에 액세스하여 워크로드를 효과적으로 관리하고 최적화할 수 있습니다.
Open WebUI 배포
Open WebUI는 OpenAI API 서버 및 Ollama와 호환되는 모델에서만 작동합니다.
1. WebUI 배포
다음 명령을 실행하여 Open WebUI를 배포합니다:
kubectl apply -f openai-webui-deployment.yaml
2. WebUI 접근을 위한 포트 포워딩
참고 Python 클라이언트로 추론을 테스트하기 위해 이미 포트 포워딩을 실행 중인 경우 ctrl+c를 눌러 중단합니다.
kubectl 포트 ��포워딩을 사용하여 로컬에서 WebUI에 접근합니다:
kubectl port-forward svc/open-webui 8081:80 -n openai-webui
3. WebUI 접근
브라우저를 열고 http://localhost:8081 로 이동합니다
4. 가입
이름, 이메일 및 임의의 비밀번호를 사용하여 가입합니다.
5. 새 채팅 시작
아래 스크린샷과 같이 드롭다운 메뉴에서 모델을 선택하고 New Chat을 클릭합니다:
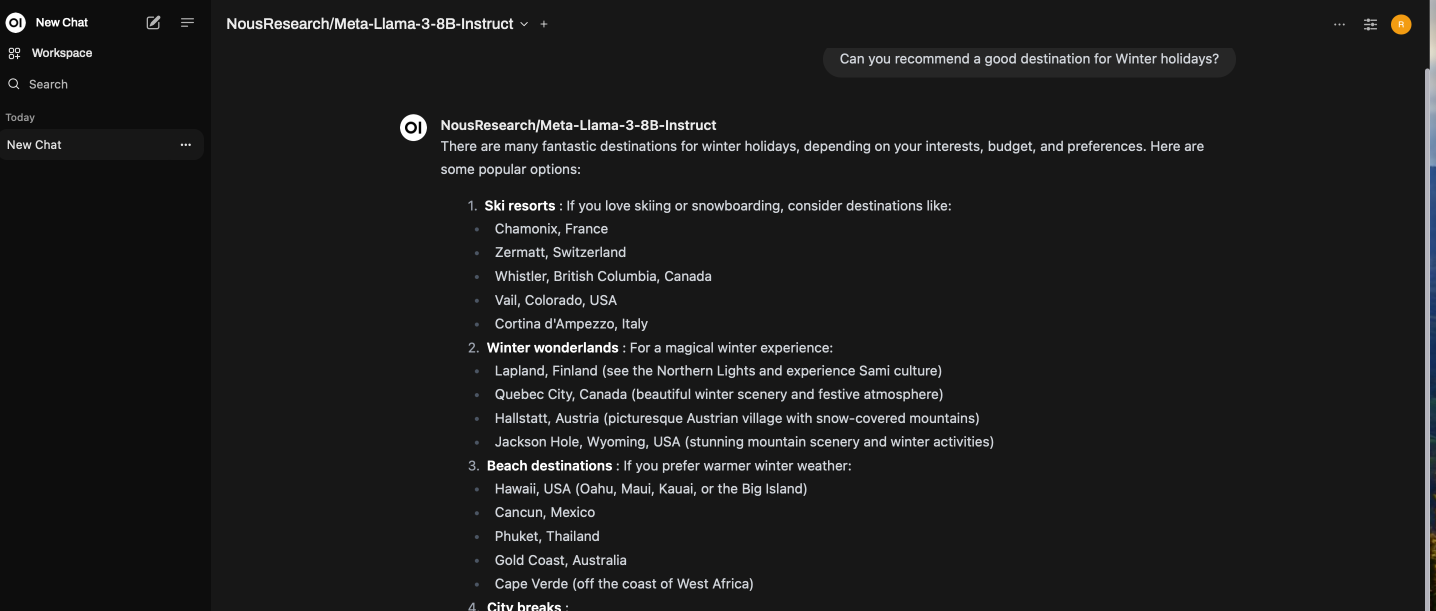
6. 테스트 프롬프트 입력
프롬프트를 입력하면 아래와 같이 스트리밍 결과를 볼 수 있습니다:
LLMPerf 도구를 사용한 성능 벤치마킹
LLMPerf는 대규모 언어 모델(LLM)의 성능을 벤치마킹하기 위해 설계된 오픈 소스 도구입니다.
LLMPerf 도구는 위에서 kubectl -n vllm port-forward svc/vllm-llama3-inf2-serve-svc 8000:8000 명령을 사용하여 설정한 포트 포워딩을 통해 포트 8000을 통해 vllm 서비스에 연결합니다.
터미널에서 아래 명령을 실행합니다.
LLMPerf 저장소 클론:
git clone https://github.com/ray-project/llmperf.git
cd llmperf
pip install -e .
pip install pandas
pip install ray
아래 명령을 사용하여 vllm_benchmark.sh 파일을 생성합니다:
cat << 'EOF' > vllm_benchmark.sh
#!/bin/bash
model=${1:-NousResearch/Meta-Llama-3-8B-Instruct}
vu=${2:-1}
export OPENAI_API_KEY=EMPTY
export OPENAI_API_BASE="http://localhost:8000/v1"
export TOKENIZERS_PARALLELISM=true
#if you have more vllm servers, append the below line to the above
#;http://localhost:8001/v1;http://localhost:8002/v1"
max_requests=$(expr ${vu} \* 8 )
date_str=$(date '+%Y-%m-%d-%H-%M-%S')
python ./token_benchmark_ray.py \
--model ${model} \
--mean-input-tokens 512 \
--stddev-input-tokens 20 \
--mean-output-tokens 245 \
--stddev-output-tokens 20 \
--max-num-completed-requests ${max_requests} \
--timeout 7200 \
--num-concurrent-requests ${vu} \
--results-dir "vllm_bench_results/${date_str}" \
--llm-api openai \
--additional-sampling-params '{}'
EOF
--mean-input-tokens: 입력 프롬프트의 평균 토큰 수 지정
--stddev-input-tokens: 더 현실적인 테스트 환경을 만들기 위한 입력 토큰 길이의 변동성 지정
--mean-output-tokens: 현실적인 응답 길이를 시뮬레이션하기 위해 모델 출력에서 예상되는 평균 토큰 수 지정
--stddev-output-tokens: 응답 크기의 다양성을 도입하는 출력 토큰 길이의 변동성 지정
--max-num-completed-requests: 처리할 최대 요청 수 설정
--num-concurrent-requests: 병렬 워크로드를 시뮬레이션하기 위한 동시 요청 수 지정
아래 명령은 지정된 모델 NousResearch/Meta-Llama-3-8B-Instruct로 벤치마킹 스크립트를 실행하고 가상 사용자 수를 2로 설정합니다. 이 결과 벤치마크는 2개의 동시 요청으로 모델 성능을 테스트하고 처리할 최대 16개의 요청을 계산합니다.
아래 명령 실행:
./vllm_benchmark.sh NousResearch/Meta-Llama-3-8B-Instruct 2
다음과 유사한 출력이 표시됩니다:
./vllm_benchmark.sh NousResearch/Meta-Llama-3-8B-Instruct 2
None of PyTorch, TensorFlow >= 2.0, or Flax have been found. Models won't be available and only tokenizers, configuration and file/data utilities can be used.
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
2024-09-03 09:54:45,976 INFO worker.py:1783 -- Started a local Ray instance.
0%| | 0/16 [00:00<?, ?it/s]Handling connection for 8000
Handling connection for 8000
12%|█████████████████████████████▌ | 2/16 [00:17<02:00, 8.58s/it]Handling connection for 8000
...
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████��██| 16/16 [02:01<00:00, 7.58s/it]
\Results for token benchmark for NousResearch/Meta-Llama-3-8B-Instruct queried with the openai api.
inter_token_latency_s
p25 = 0.051964785839225695
p50 = 0.053331799814278796
...
mean = 0.053548951905597324
...
ttft_s
p25 = 1.5284210312238429
p50 = 1.7579061459982768
...
mean = 1.5821313202395686
...
end_to_end_latency_s
p25 = 13.74749460403109
p50 = 14.441407957987394
...
mean = 14.528114874927269
...
request_output_throughput_token_per_s
p25 = 18.111220396798153
p50 = 18.703139371912407
...
mean = 18.682678715983627
...
Number Of Errored Requests: 0
Overall Output Throughput: 35.827933968528434
Number Of Completed Requests: 16
Completed Requests Per Minute: 7.914131755588426
동시 요청 수를 늘려가며 벤치마킹 결과를 생성하여 동시 요청 수 증가에 따라 성능이 어떻게 변하는지 이해할 수 있습니다:
./vllm_benchmark.sh NousResearch/Meta-Llama-3-8B-Instruct 2
./vllm_benchmark.sh NousResearch/Meta-Llama-3-8B-Instruct 4
./vllm_benchmark.sh NousResearch/Meta-Llama-3-8B-Instruct 8
./vllm_benchmark.sh NousResearch/Meta-Llama-3-8B-Instruct 16
.
.
성능 벤치마킹 메트릭
llmperf 디렉토리의 vllm_bench_results 디렉토리에서 벤치마킹 스크립트의 결과를 찾을 수 있습니다. 결과는 날짜-시간 명명 규칙을 따르는 폴더에 저장됩니다. 벤치마킹 스크립트가 실행될 때마다 새 폴더가 생성됩니다.
벤치마킹 스크립트의 모든 실행 결과는 아래 형식의 2개 파일로 구성됩니다:
NousResearch-Meta-Llama-3-8B-Instruct_512_245_summary_32.json - 모든 요청/응답 쌍에 걸친 성능 메트릭 요약 포함.
NousResearch-Meta-Llama-3-8B-Instruct_512_245_individual_responses.json - 각 요청/응답 쌍에 대한 성능 메트릭 포함.
이러한 각 파일에는 다음 성능 벤치마킹 메트릭이 포함됩니다:
results_inter_token_latency_s_*: Token generation latency (TPOT)라고도 합니다. Inter-Token 지연 시간은 디코딩 또는 생성 단계에서 대규모 언어 모델(LLM)이 연속 출력 토큰을 생성하는 데 걸리는 평균 시간을 나타냅니다
results_ttft_s_*: 첫 번째 토큰 생성까지의 시간(Time to First Token, TTFT)
results_end_to_end_s_*: 엔드투엔드 지연 시간 - 사용자가 입력 프롬프트를 제출한 시점부터 LLM이 완전한 출력 응답을 생성하기까지 걸리는 총 시간
results_request_output_throughput_token_per_s_*: 모든 사용자 요청 또는 쿼리에서 대규모 언어 모델(LLM)이 초당 생성하는 출력 토큰 수
results_number_input_tokens_*: 요청의 입력 토큰 수(입력 길이)
results_number_output_tokens_*: 요청의 출력 토큰 수(출력 길이)
결론
요약하면, Llama-3를 배포하고 확장할 때 AWS Trn1/Inf2 인스턴스는 매력적인 이점을 제공합니다. GPU 부족과 관련된 문제를 극복하면서 대규모 언어 모델을 효율적이고 접근 가능하게 실행하는 데 필요한 확장성, 비용 최적화 및 성능 향상을 제공합니다. 챗봇, 자연어 처리 애플리케이션 또는 기타 LLM 기반 솔루션을 구축하든 Trn1/Inf2 인스턴스를 통해 AWS 클라우드에서 Llama-3의 잠재력을 최대한 활용할 수 있습니다.
정리
마지막으로 더 이상 필요하지 않은 리소스를 정리하고 프로비저닝 해제하는 방법을 안내합니다.
RayCluster 삭제
cd ai-on-eks/blueprints/inference/vllm-rayserve-inf2
kubectl delete -f vllm-rayserve-deployment.yaml
EKS 클러스터 및 리소스 삭제
cd ai-on-eks/infra/trainium-inferentia/terraform/_LOCAL
./cleanup.sh