Ray Serve 고가용성
EKS에 ML 모델을 배포하려면 GPU 또는 Neuron 인스턴스에 대한 액세스가 필요합니다. 배포가 작동하지 않는 경우 이러한 리소스에 대한 액세스가 누락되어 있기 때문인 경우가 많습니다. 또한 일부 배포 패턴은 Karpenter 오토스케일링 및 정적 노드 그룹에 의존합니다. 노드가 초기화되지 않으면 Karpenter 또는 노드 그룹의 로그를 확인하여 문제를 해결하십시오.
참고: Mistral-7B-Instruct-v0.2는 Huggingface 리포지토리의 제한 모델입니다. 이 모델을 사용하려면 HuggingFace 토큰이 필요합니다.
HuggingFace에서 토큰을 생성하려면 HuggingFace 계정으로 로그인하고 설정 페이지의 Access Tokens 메뉴 항목을 클릭하십시오.
Elastic Cache for Redis를 사용한 Ray Head 노드 고가용성(HA)
Ray 클러스터의 핵심 구성 요소는 작업 스케줄링, 상태 동기화 및 노드 조정을 관리하여 전체 클러스터를 오케스트레이션하는 헤드 노드입니다. 그러나 기본적으로 Ray head Pod는 단일 장애 지점을 나타냅니다. 실패하면 Ray 워커 Pod를 포함한 전체 클러스터를 다시 시작해야 합니다.
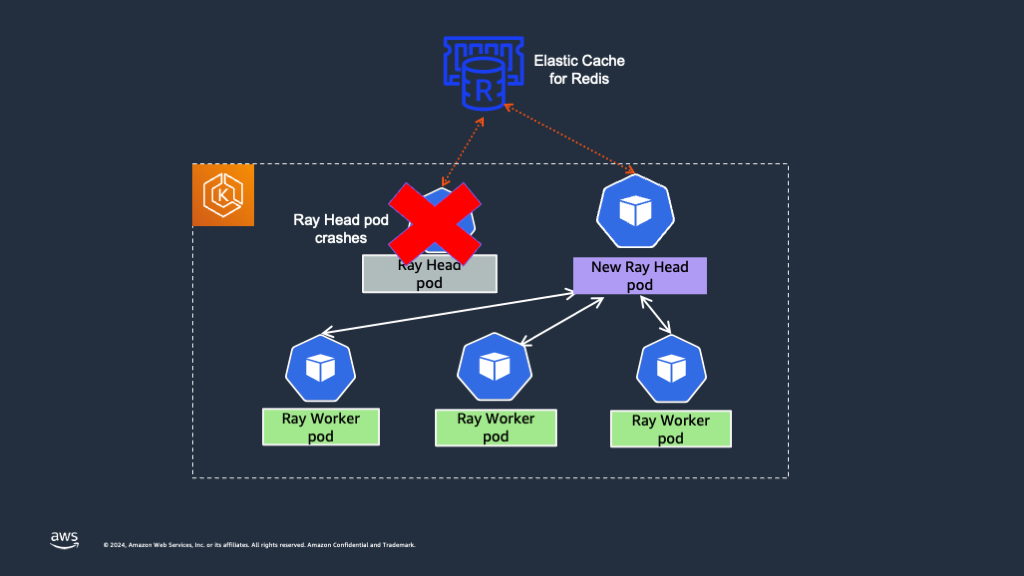
이를 해결하기 위해 Ray head 노드의 고가용성(HA)이 필수적입니다. Global Control Service (GCS)는 RayCluster에서 클러스터 수준 메타데이터를 관리합니다. 기본적으로 GCS는 모든 데이터를 메모리에 저장하므로 장애 허용이 없으며, 실패 시 전체 Ray 클러스터가 실패할 수 있습니다. 이를 방지하려면 Ray의 Global Control Store (GCS)에 장애 허용을 추가해야 하며, 이를 통해 head 노드가 충돌해도 Ray Serve 애플리케이션이 트래픽을 서빙할 수 있습니다. GCS가 재시작되면 Redis 인스턴스에서 모든 데이터를 검색하고 정상 기능을 재개합니다.
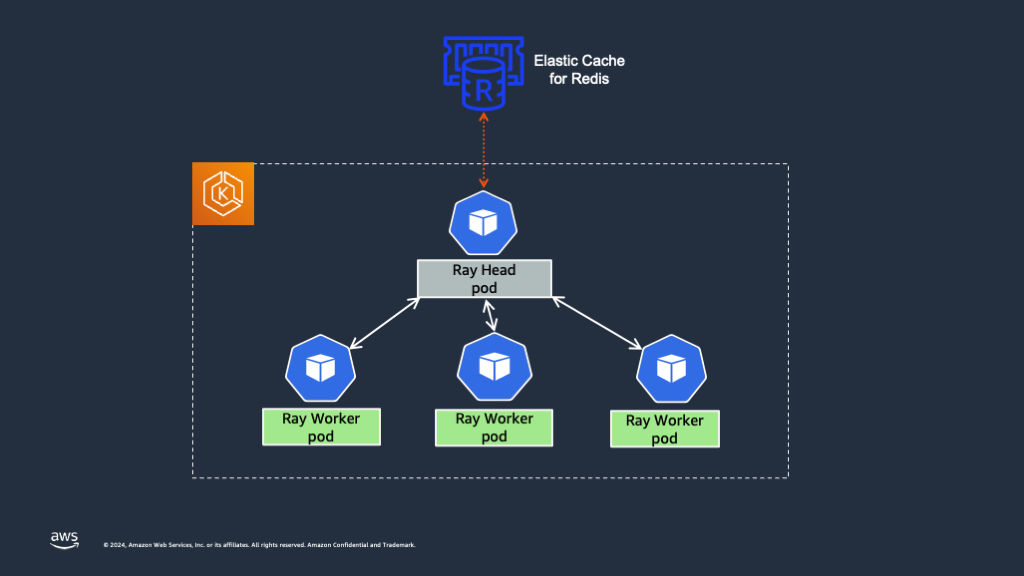
다음 섹션에서는 GCS 장애 허용을 활성화하고 Ray head Pod의 고가용성을 보장하는 방법에 대한 단계를 제공합니다. Mistral-7B-Instruct-v0.2 모델을 사용하여 Ray head 고가용성을 시연합니다.
외부 Redis 서버 추가
GCS 장애 허용에는 외부 Redis 데이터베이스가 필요합니다. 자체 Redis 데이터베이스를 호스팅하거나 타사 벤더를 통해 사용할 수 있습니다.
개발 및 테스트 목적으로 Ray 클러스터와 동일한 EKS 클러스터에 컨테이너화된 Redis 데이터베이스를 호스팅할 수도 있습니다. 그러나 프로덕션 설정의 경우 고가용성 외부 Redis 클러스터를 사용하는 것이 좋습니다. 이 패턴에서는 Amazon ElasticCache for Redis를 사용하여 외부 Redis 클러스터를 생성했습니다. Redis 클러스터 설정에 Amazon memoryDB를 사용할 수도 있습니다.
현재 블루프린트의 일부로 AWS에서 Elastic Cache Redis 클러스터를 생성하는 elasticache라는 terraform 모듈을 추가했습니다. Redis 클러스터는 클러스터 모드가 비활성화되어 있으며 하나의 노드를 포함합니다. 이 클러스터 노드의 엔드포인트는 읽기와 쓰기 모두에 사용할 수 있습니다.
이 모듈에서 주목할 주요 사항은 다음과 같습니다:
- Redis 클러스터는 EKS 클러스터와 동일한 VPC에 있습니다. Redis 클러스터가 별도의 VPC에 생성된 경우 네트워크 연결을 활성화하려면 EKS 클러스터 VPC와 Elastic Cache Redis 클러스터 VPC 간에 VPC 피어링을 설정해야 합니다.
- Redis 클러스터 생성 시 캐시 서브넷 그룹을 생성해야 합니다. 서브넷 그룹은 VPC의 캐시에 지정할 수 있는 서브넷 모음입니다. ElastiCache는 해당 캐시 서브넷 그룹을 사용하여 해당 서브넷 내의 각 캐시 노드에 IP 주소를 할당합니다. 블루프린트는 Elastic cache Redis 클러스터의 서브넷 그룹에 EKS 클러스터가 사용하는 모든 서브넷을 자동으로 추가합니다.
- 보안 그룹 - Redis 캐시에 할당된 보안 그룹에는 EKS 클러스터의 워커 노드 보안 그룹에서 포트 6379를 통해 Redis 클러스터 보안 그룹으로의 TCP 트래픽을 허용하는 인바운드 규칙이 있어야 합니다. Ray head Pod가 포트 6379를 통해 Elastic cache Redis 클러스터에 연결을 설정해야 하기 때문입니다. 블루프린트는 인바운드 규칙으로 보안 그룹을 자동으로 설정합니다.
Amazon Elastic Cache를 사용하여 Redis 클러스터를 생성하려면 아래 단계를 따르십시오.
이 Mistral7b 배포는 고가용성과 함께 Ray Serve를 사용합니다. 이전 단계에서 이미 mistral7b를 배포한 경우 배포를 삭제하고 아래 단계를 실행할 수 있습니다.
사전 요구 사항:
먼저 아래 명령을 실행하여 enable_rayserve_ha_elastic_cache_redis 변수를 true로 설정하여 Redis 클러스터 생성을 활성화합니다. 기본값은 false입니다.
export TF_VAR_enable_rayserve_ha_elastic_cache_redis=true
그런 다음 install.sh 스크립트를 실행하여 KubeRay operator 및 기타 애드온이 있는 EKS 클러스터를 설치합니다.
cd ai-on-eks/infra/trainium-inferentia
./install.sh
EKS 클러스터 외에도 이 블루프린트는 AWS Elastic Cache Redis 클러스터를 생성합니다. 샘플 출력은 아래와 같습니다
Apply complete! Resources: 8 added, 1 changed, 0 destroyed.
Outputs:
configure_kubectl = "aws eks --region us-west-2 update-kubeconfig --name trainium-inferentia"
elastic_cache_redis_cluster_arn = "arn:aws:elasticache:us-west-2:11111111111:cluster:trainium-inferentia"
RayService에 외부 Redis 정보 추가
elastic cache Redis 클러스터가 생성되면 mistral-7b 모델 추론을 위한 RayService 구성을 수정해야 합니다.
먼저 AWS CLI와 jq를 사용하여 아래와 같이 Elastic Cache Redis 클러스터 엔드포인트를 가져와야 합니다.
export EXT_REDIS_ENDPOINT=$(aws elasticache describe-cache-clusters \
--cache-cluster-id "trainium-inferentia" \
--show-cache-node-info | jq -r '.CacheClusters[0].CacheNodes[0].Endpoint.Address')
이제 RayService CRD 아래에 ray.io/ft-enabled: "true" 어노테이션을 추가합니다. ray.io/ft-enabled 어노테이션은 true로 설정하면 GCS 장애 허용을 활성화합니다.
apiVersion: ray.io/v1
kind: RayService
metadata:
name: mistral
namespace: mistral
annotations:
ray.io/ft-enabled: "true"
headGroupSpec에 외부 Redis 클러스터 정보를 RAY_REDIS_ADDRESS 환경 변수로 추가합니다.
headGroupSpec:
headService:
metadata:
name: mistral
namespace: mistral
rayStartParams:
dashboard-host: '0.0.0.0'
num-cpus: "0"
template:
spec:
containers:
- name: head
....
env:
- name: RAY_REDIS_ADDRESS
value: $EXT_REDIS_ENDPOINT:6379
RAY_REDIS_ADDRESS의 값은 Redis 데이터베이스의 주소여야 합니다. Redis 클러스터 엔드포인트와 포트를 포함해야 합니다.
ai/inference/mistral-7b-rayserve-inf2/ray-service-mistral-ft.yaml 파일에서 GCS 장애 허용이 활성화된 전체 RayService 구성을 찾을 수 있습니다.
위의 RayService 구성으로 Ray head Pod에 대한 GCS 장애 허용을 활성화했으며, Ray 클러스터는 모든 Ray 워커를 재시작하지 않고 head Pod 충돌에서 복구할 수 있습니다.
위의 RayService 구성을 적용하고 동작을 확인해 봅시다.
cd ai-on-eks/blueprints/inference/
envsubst < mistral-7b-rayserve-inf2/ray-service-mistral-ft.yaml| kubectl apply -f -
출력은 아래와 같아야 합니다
namespace/mistral created
secret/hf-token created
rayservice.ray.io/mistral created
ingress.networking.k8s.io/mistral created
클러스터의 Ray Pod 상태를 확인합니다.
kubectl get po -n mistral
Ray head 및 워커 Pod는 아래와 같이 Running 상태여야 합니다.
NAME READY STATUS RESTARTS AGE
mistral-raycluster-rf6l9-head-hc8ch 2/2 Running 0 31m
mistral-raycluster-rf6l9-worker-inf2-tdrs6 1/1 Running 0 31m
Ray Head Pod 충돌 시뮬레이션
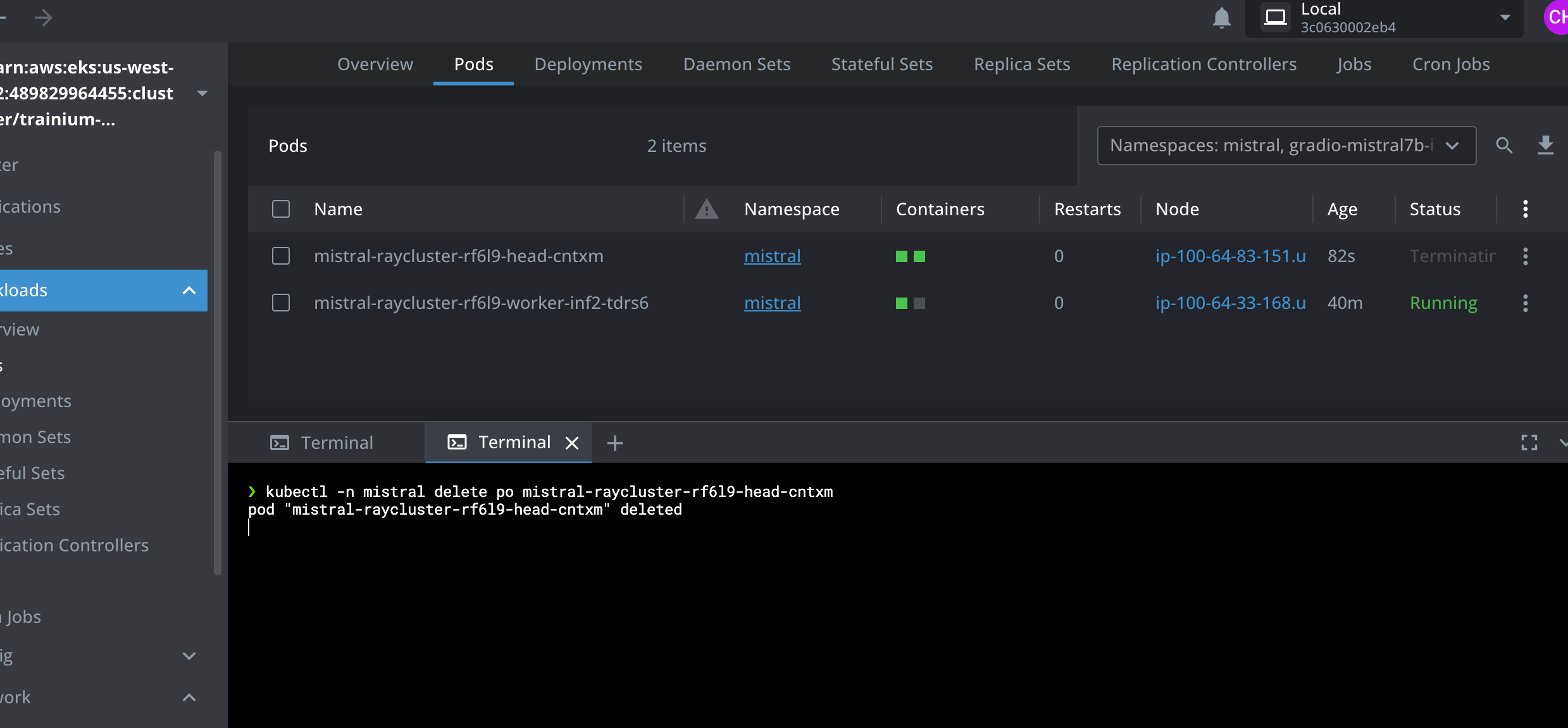
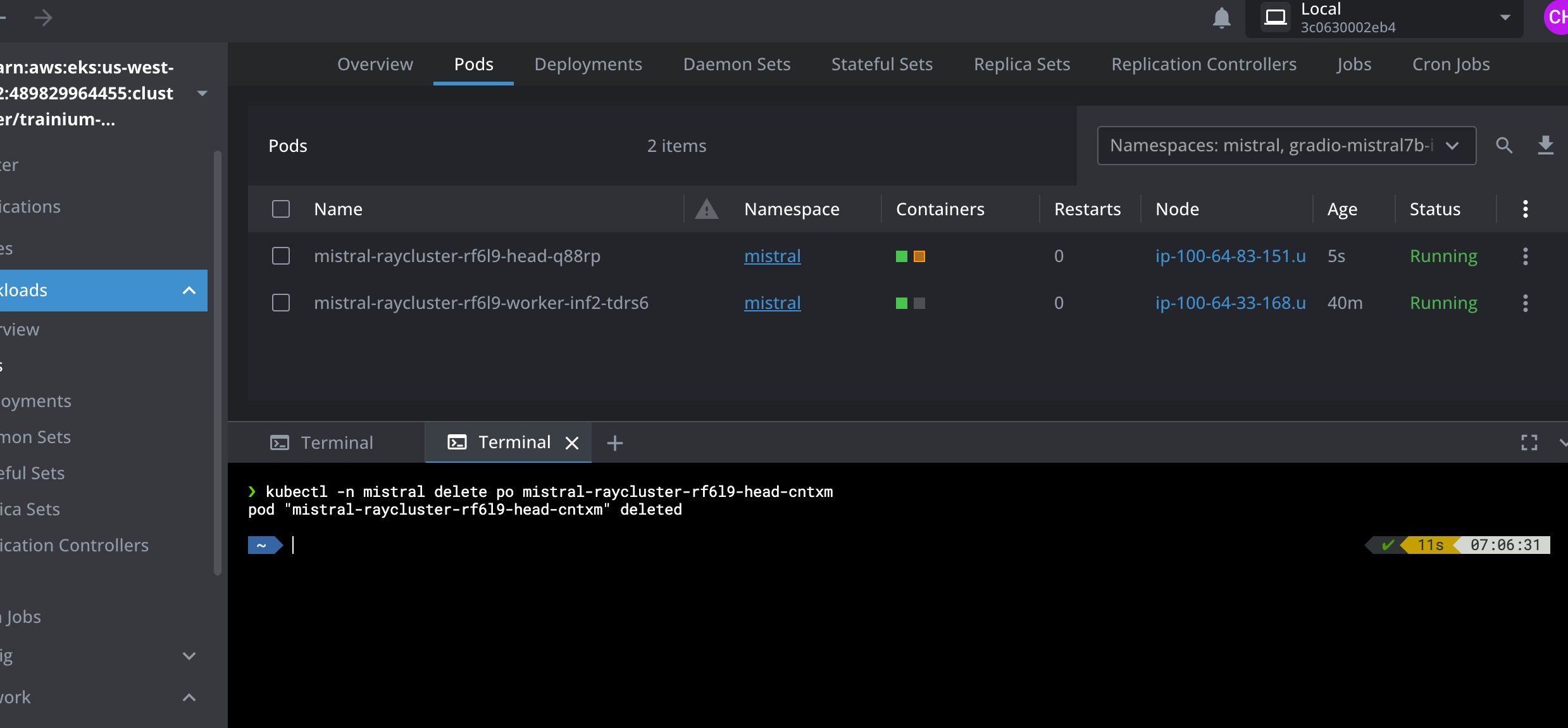
Pod를 삭제하여 Ray head Pod 충돌을 시뮬레이션합니다
kubectl -n mistral delete po mistral-raycluster-rf6l9-head-xxxxx
pod "mistral-raycluster-rf6l9-head-xxxxx" deleted
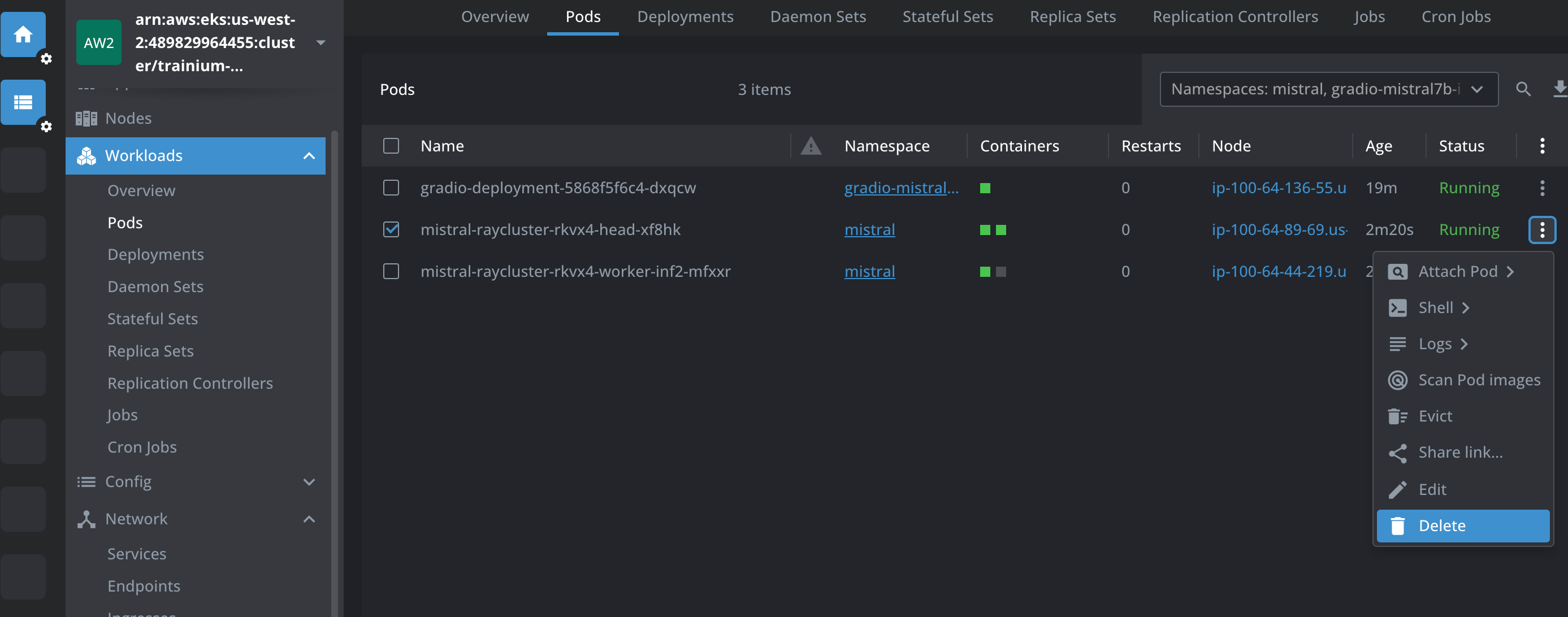
Ray head Pod가 종료되고 자동 재시작될 때 Ray 워커 Pod가 계속 실행되는 것을 볼 수 있습니다. Lens IDE의 아래 스크린샷을 참조하십시오.
Mistral AI Gradio 앱 테스트
Ray head Pod가 삭제된 동안 질문에 답할 수 있는지 Gradio UI 앱도 테스트해 봅시다.
브라우저를 localhost:7860으로 지정하여 Gradio Mistral AI Chat 애플리케이션을 엽니다.
이제 위 단계에서 보여준 것처럼 Ray head Pod를 삭제하여 Ray head Pod 충돌 시뮬레이션을 반복합니다.
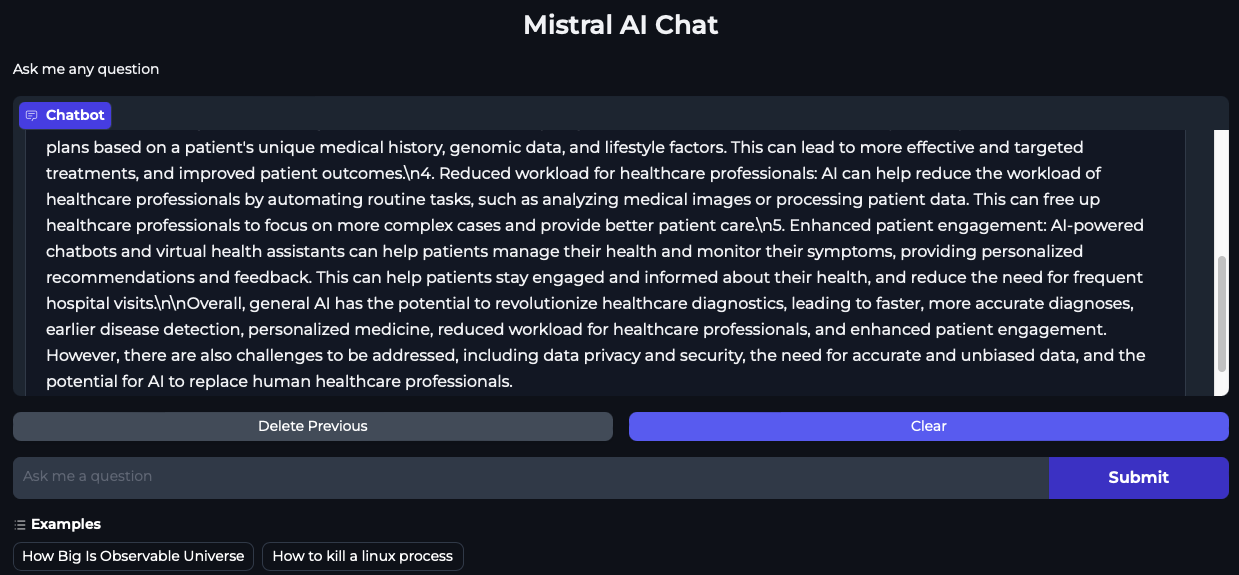
Ray head Pod가 종료되고 복구되는 동안 Mistral AI Chat 인터페이스에 질문을 제출합니다. 아래 스크린샷에서 Ray head Pod가 삭제되고 복구되는 동안 채팅 애플리케이션이 실제로 트래픽을 서빙할 수 있음을 알 수 있습니다. GCS 장애 허용으로 인해 RayServe 서비스가 이 경우 재시작되지 않는 Ray 워커 Pod를 가리키기 때문입니다.

RayServe 애플리케이션에 엔드투엔드 장애 허용을 활성화하는 전체 가이드는 Ray Guide를 참조하십시오.
정리
마지막으로 더 이상 필요하지 않은 리소스를 정리하고 프로비저닝 해제하는 방법을 안내합니다.
1단계: Gradio 앱 및 mistral 추론 배포 삭제
cd ai-on-eks/blueprints/inference/mistral-7b-rayserve-inf2
kubectl delete -f gradio-ui.yaml
kubectl delete -f ray-service-mistral-ft.yaml
2단계: EKS 클러스터 정리
이 스크립트는 -target 옵션을 사용하여 모든 리소스가 올바른 순서로 삭제되도록 환경을 정리합니다.
cd ai-on-eks/infra/trainium-inferentia/
./cleanup.sh