컨테이너 이미지에서 모델 아티팩트 분리
모델 아티팩트를 추출하는 주요 목적은 컨테이너 이미지 크기를 줄이는 것이지만, 이 접근 방식은 추가적인 운영 및 기능적 이점도 제공합니다. 운영 개선에는 모델 아티팩트에 대한 별도의 버전 관리, 간소화된 감사 및 라이프사이클 제어가 포함되며, 지연 로딩, 핫 스와핑 및 다양한 애플리케이션 간 재사용은 추가적인 기능적 유연성과 성능을 제공합니다. 사용 사례에 따라 이러한 장점은 이 섹션에 설명된 솔루션 중에서 선택할 때 결정적인 요소가 될 수 있습니다.
init 컨테이너를 사용하여 Amazon S3에서 모델 아티팩트 다운로드
이 솔루션은 모델 파일이나 관련 아티팩트를 외부 스토리지로 추출하는 간단한 접근 방식을 제공합니다. 아티팩트는 개발 또는 CI/CD 단계에서 태그가 지정되고 버전이 관리되며 Amazon S3 버킷에 배치되고 보존을 제어하기 위한 적절한 라이프사이클 정책이 적용됩니다. 애플리케이션에서 참조되면 메인 애플리케이션 컨테이너 전에 순차적으로 실행되는 Kubernetes 네이티브 init 컨테이너를 사용하여 애플리케이션 Pod 초기화 중에 공유 볼륨으로 다운로드됩니다.
아키텍처 개요
그림 1의 다이어그램은 데이터 흐름의 일부로 생성, 저장 및 검색되는 페르소나, AWS 서비스, Kubernetes 구성 요소 및 아티팩트를 포함한 솔루션 아키텍처를 보여줍니다.
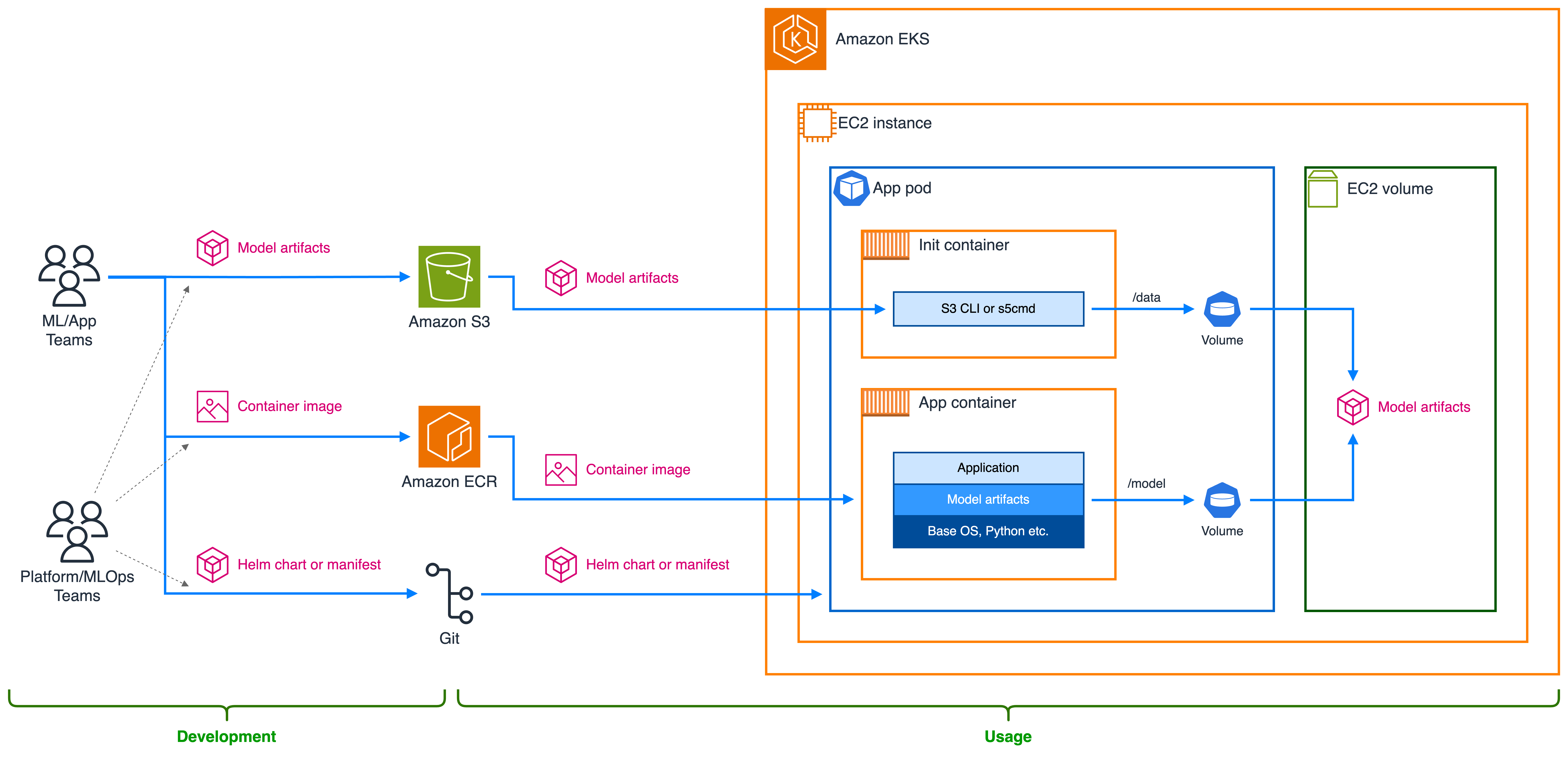 그림 1: Amazon S3에서 모델 아티팩트를 검색하기 위한 init 컨테이너 아키텍처
그림 1: Amazon S3에서 모델 아티팩트를 검색하기 위한 init 컨테이너 아키텍처
구현 가이드
위의 아키텍처 �다이어그램에 따라 각 팀의 주요 고수준 단계는 다음과 같습니다.
DevOps/MLOps/플랫폼 팀:
- init 컨테이너를 포함하도록 Kubernetes 배포 매니페스트(예: YAML 파일, Helm 차트)를 변경합니다.
- 먼저 실행되는 init 컨테이너를 사용하여 모델 아티팩트를 EC2 볼륨에 다운로드하는 단계를 구현합니다.
- Kubernetes 배포 매니페스트를 변경하여:
- init 컨테이너와 애플리케이션 컨테이너 간에 공유되는 볼륨을 정의합니다.
- 애플리케이션 컨테이너의 예상 경로 아래에 볼륨을 마운트합니다.
- init 컨테이너가 버킷의 적절한 접두사에 접근할 수 있도록 Pod IAM 권한을 조정합니다.
- 모델 아티팩트를 저장할 Amazon S3 버킷을 생성합니다.
- 빌드 스테이지 동안 모델 아티팩트를 제외하도록 컨테이너 이미지 정의를 변경합니다.
ML 또는 애플리케이션 팀:
- SDLC의 일부로 모델 아티팩트를 Amazon S3 버킷에 업로드합니다.
- 이전과 같이 컨테이너 이미지 변경 사항을 Amazon ECR로 계속 푸시합니다.
- 이전과 같이 Kubernetes 배포 매니페스트를 사용하여 애플리케이션 Kubernetes 배포를 계속 정의합니다.
다음 코드는 이미 조정된 Kubernetes 배포 매니페스트를 보여줍니다:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-inference-app
namespace: apps
spec:
selector:
matchLabels:
app.kubernetes.io/name: my-inference-app
replicas: 1
template:
metadata:
labels:
app.kubernetes.io/name: my-inference-app
spec:
serviceAccountName: my-inference-app
initContainers:
- name: download
image: peakcom/s5cmd
command:
- /bin/sh
- -c
- '/s5cmd sync s3://my-ml-bucket/model-artifacts/my-model-1.2.3/* /model-artifacts/my-model-1.2.3'
resources:
...
volumeMounts:
- mountPath: /model-artifacts
name: model-artifacts
containers:
- name: app
image: <account-id>.dkr.ecr.<region>.amazonaws.com/my-inference-app:3.5.0
ports:
- name: app-port
containerPort: 6060
resources:
...
volumeMounts:
- mountPath: /app/model-artifacts
name: model-artifacts
volumes:
- emptyDir: {}
name: model-artifacts
위의 예는 위에서 설명한 단계를 따르며 Amazon S3에서 파일을 다운로드하는 데 탁월한 성능을 제공하는 오픈 소스 도구인 s5cmd를 사용합니다. 구현은 현재 모든 것이 이미지에 포함된 솔루션이 my-model-1.2.3 모델 아티팩트를 /app/model-artifacts 아래의 컨테이너 이미지에 번들하고 동일한 위치에 배치하여 해당 동작을 모방한다는 사실에 의존합니다.
위의 매니페스트에 나열된 my-inference-app 서비스 계정은 my-ml-bucket 버킷의 해당 접두사에서 읽을 수 있는 적절한 IAM 권한이 필요합니다. Amazon EKS에서 이를 달성하기 위해 권장되는 방법은 Amazon EKS Pod Identity 애드온을 사용하는 것입니다. Amazon EKS Pod Identity는 AWS API를 통해 Kubernetes 서비스 계정과 AWS IAM 역할 간의 연결을 생성하는 방법을 제공합니다. 배포되면 Pod Identity 애드온은 클러스터��의 모든 노드에 에이전트(DaemonSet을 통해)를 배치하고 해당 서비스 계정이 있는 Pod가 런타임에 해당 에이전트에서 필요한 자격 증명을 추출할 수 있도록 합니다.
주요 이점
이 솔루션은 컨테이너 이미지 크기를 줄여 AI/ML 추론 애플리케이션 컨테이너 시작 성능을 개선하는 고수준 접근 방식을 구현합니다. 네트워킹 조건과 s5cmd의 우수한 성능에 따라 이미지 풀을 직접 개선할 수도 있습니다.
추가 이점
주요 이점 외에도 솔루션은 다음과 같은 잠재적인 추가 이점을 도입합니다:
- 컨테이너 이미지를 다시 빌드하지 않고 애플리케이션과 별도로 모델 버전을 업데이트하는 기능
- 컨테이너 이미지를 다시 빌드하거나 크기를 늘리지 않고 모델을 A/B 테스트, 핫 스와프 또는 롤백하는 기능
- 모든 컨테이너 이미지에 패키징하지 않고 다른 애플리케이션 간에 모델을 공유하는 기능
- 스토리지 비용 절감 및 Intelligent-Tiering을 포함한 Amazon S3 스토리지 클래스 활용 기능
- Amazon EKS Pod Identity 세션 태그를 사용하여 모델에 대한 세분화된 접근 제어 기능
- 실험 및 테스트를 지원하는 더 빠른 컨테이너 빌드
- ML 또는 애플리케이션 팀 워크플로우의 최소 변경
- 간단한 교차 리전 복제
트레이드오프
트레이드오프는 다음을 포함합니다:
- 필요한 CI/CD 변경을 수행하고 재시도, 오류 처리, 백오프 등을 포함한 다운로드 프로세스를 처리하는 추가적인 운영 복잡성
- 본질적으로 ECR 기능을 복제하는 추가 스토리지 및 정리 관리
- 애플리케이션의 추가 복제본이 종종 동일한 EC2 인스턴스에 착륙하는 경우, 호스트의 컨테이너 런타임 캐시에 이미지가 저장되어 있으면 컨테이너 시작 시간에 더 유익할 수 있습니다.
변형 및 하이브리드 솔루션
이 솔루션은 풀 프로세스 가속화 솔루션 그룹과 잘 통합되어 컨테이너 이미지 크기와 풀 시간을 모두 개선합니다.
아티팩트를 메모리로 직접 읽어 로컬 디스크에 저장하는 중간 단계를 건너뛰는 AI/ML 추론 애플리케이션의 경우 "Mountpoint CSI 드라이버를 사용하여 Amazon S3에서 직접 모델 아티팩트를 메모리로 읽기" 솔루션이 다운로드 성능을 더욱 개선하기 위해 대체하거나 추가로 사용될 수 있습니다.
Amazon 파일 스토리지 서비스를 사용하여 모델 아티팩트 호스팅
이 섹션에서는 모델 아티팩트를 컨테이너 이미지에서 분리하는 데 사용할 수 있는 다양한 Amazon FSx 서비스를 다룹니다. Amazon FSx는 FSx for OpenZFS, FSx for Lustre, FSx for NetApp ONTAP과 같은 다양한 서비스를 제공합니다. 이러한 서비스는 기반 기술이 다르며 성능과 확장 특성이 다릅니다. 이러한 서비스에 대해 자세히 알아보려면 문서를 참조하십시오.
적절한 Amazon FSx 서비스를 선택하는 것은 사용 사례의 특성에 따라 다릅니다. 모델 크기, 모델 수, 업데이트 빈도 및 모델을 가져오는 클라이언트 수와 같은 요소가 선택한 서비스에 영향을 미칠 수 있습니다.
이 섹션은 진행 중이며 향후 더 많은 FSx 서비스별 가이드가 추가될 예정입니다.
Trident CSI 드라이버를 사용하여 Amazon FSx for NetApp ONTAP의 모델 아티팩트에 대한 접근 제공
아키텍처 개요
그림 2의 다이어그램은 데이터 흐름의 일부로 생성, 저장 및 검색되는 페르소나, AWS 서비스, Kubernetes 구성 요소 및 아티팩트를 포함한 솔루션 아키텍처를 보여줍니다.
 그림 2: Trident CSI 드라이버를 사용하여 FSx for NetApp ONTAP에서 모델 아티팩트 저장 및 접근
그림 2: Trident CSI 드라이버를 사용하여 FSx for NetApp ONTAP에서 모델 아티팩트 저장 및 접근
구현 가이드
위의 아키텍처 다이어그램에 따라 각 팀의 주요 고수준 단계는 다음과 같습니다.
DevOps/MLOps/플랫폼 팀:
- FSx for NetApp ONTAP 파일 시스템, 스토리지 가상 머신(SVM) 및 자격 증명 시크릿을 생성합니다.
- Trident CSI 드라이버를 설치하고 필요한 IAM 권한을 제공하며 Trident CSI 스토리지 클래스를 정의합니다.
- 파일 시스템, SVM 및 자격 증명을 사용하여 Trident NAS 백엔드를 정의합니다.
- 위의 스토리지 클래스를 사용하여 애플리케이션 네임스페이스에 공유되는 동적 프로비전 PVC를 정의하고 배포합니다.
- PVC를 마운트하고 해당 볼륨에 모델을 다운로드하는 Kubernetes 작업을 구현합니다.
- S3에 업로드되고 게시됨으로 "표시"된(예: 태그를 통해) 각 모델에 대해 작업을 트리거합니다.
- 빌드 스테이지 동안 모델 아티팩트를 제외하도록 컨테이너 이미지 정의를 변경합니다.
- 애플리케이션 매니페스트를 변경하여:
- 공유 PVC를 가져오는 PVC를 포함합니다.
- 애플리케이션 Pod에 대한 볼륨을 정의합니다.
- 애플리케이션 컨테이너의 예상 경로 아래에 볼륨을 마운트합니다.
ML 또는 애플리케이션 팀:
- SDLC의 일부로 모델 아티팩트를 Amazon S3 버킷 또는 Git LFS에 업로드합니다.
- 이전과 같이 컨테이너 이미지 변경 사항을 Amazon ECR로 계속 푸시합니다.
- 이전과 같이 Kubernetes 배포 매니페스트를 사용하여 애플리케이션 Kubernetes 배포를 계속 정의합니다.
위의 단계를 더 설명하기 위해 구현의 가장 중요한 부분에 대한 관련 코드 예제 모음이 아래에 있습니다.
다음은 Trident CSI 드라이버에 의해 처리될 스토리지 클래스입니다:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ontap-nas
provisioner: csi.trident.netapp.io
volumeBindingMode: WaitForFirstConsumer
parameters:
backendType: ontap-nas
fsType: ext4
allowVolumeExpansion: True
reclaimPolicy: Delete
다음은 FSx for NetApp ONTAP과의 백엔드 통합을 위한 Trident ��백엔드 구성입니다:
apiVersion: trident.netapp.io/v1
kind: TridentBackendConfig
metadata:
name: svm1-nas
namespace: kube-system
spec:
version: 1
backendName: svm1-nas
storageDriverName: ontap-nas
managementLIF: ${SVM_MGMT_DNS}
svm: svm1
aws:
fsxFilesystemID: ${FSXN_ID}
apiRegion: ${AWS_REGION}
credentials:
name: ${SVM_ADMIN_CREDS_SECRET_ARN}
type: awsarn
다음은 Trident에 의해 처리되고 네임스페이스 간에 공유될 수 있는 PVC의 예입니다:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: some-model
namespace: kube-system
annotations:
trident.netapp.io/shareToNamespace: apps
spec:
storageClassName: ontap-nas
accessModes:
- ReadWriteMany
resources:
requests:
storage: 20Gi
그런 다음 PVC를 마운트하고 S3의 데이터로 동적 PV 뒤의 FSx for NetApp ONTAP 볼륨을 채우는 Job을 사용할 수 있습니다:
apiVersion: batch/v1
kind: Job
metadata:
name: fsxn-loader-some-model
namespace: kube-system
labels:
job-type: fsxn-loader
pvc: some-model
spec:
backoffLimit: 1
ttlSecondsAfterFinished: 30
template:
metadata:
labels:
job-type: fsxn-loader
pvc: some-model
spec:
restartPolicy: Never
containers:
- name: loader
image: peakcom/s5cmd
command:
- /bin/sh
- -c
- '/s5cmd sync --delete s3://${MODELS_BUCKET}/${MODELS_FOLDER}/some-model/* /model'
resources:
...
volumeMounts:
- name: model
mountPath: /model
volumes:
- name: model
persistentVolumeClaim:
claimName: some-model
이제 PVC가 클러스터에 존재하며 TridentVolumeReference CR에 의해 정의된 Trident PVC 공유를 통해 apps 네임스페이스의 애플리케이션에서 사용될 수 있습니다:
apiVersion: trident.netapp.io/v1
kind: TridentVolumeReference
metadata:
name: some-model
namespace:apps
spec:
pvcName: some-model
pvcNamespace: kube-system
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: some-model
namespace: apps
annotations:
trident.netapp.io/shareFromPVC: kube-system/some-model
spec:
storageClassName: ontap-nas
accessModes:
- ReadOnlyMany
resources:
requests:
storage: 20Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: some-app
namespace: apps
spec:
selector:
matchLabels:
app.kubernetes.io/name: some-app
replicas: 1
template:
metadata:
labels:
app.kubernetes.io/name: some-app
spec:
containers:
- name: app
image: some-app:1.2.3
...
volumeMounts:
- name: data-volume
mountPath: /app/models/some-model
volumes:
- name: data-volume
persistentVolumeClaim:
claimName: some-model
주요 이점
이 솔루션은 컨테이너 이미지 크기를 줄여 AI/ML 추론 애플리케이션 컨테이너 시작 성능을 개선하는 고수준 접근 방식을 구현합니다. 모델 아티팩트를 애플리케이션에서 사용할 수 있게 되는 시간을 개선합니다(더 이상 다운로드할 필요가 없으므로).
추가 이점
주요 이점 외에도 솔루션은 다음과 같은 잠재적인 추가 이점을 도입합니다:
- 컨테이너 이미지를 다시 빌드하지 않고 애플리케이션과 별도로 모델 버전을 업데이트하는 기능
- 컨테이너 이미지를 다시 빌드하거나 크기를 늘리지 않고 모델을 A/B 테스트, 핫 스와프 또는 롤백하는 기능
- 모든 컨테이너 이미지에 패키징하지 않고 다른 애플리케이션 간에 모델을 공유하는 기능
- 모델 복사 필요성을 줄이고 새로운 작업을 생성하는 Trident 클론, 공유 및 스냅샷 관련 기능을 통한 Kubernetes 기반 프로비저닝 및 접근 제어
- 모델에 대한 POSIX 기반 접근 제어 기능
- 실험 및 테스트를 지원하는 더 빠른 컨테이너 빌드
- ML 또는 애플리케이션 팀 워크플로우의 최소 변경
트레이드오프
트레이드오프는 다음을 포함합니다:
- 필요한 CI/CD 변경을 수행하고 로더 프로��세스를 유지하는 추가적인 운영 복잡성
- 운영 및 유지 관리해야 할 추가 소프트웨어(Trident)
- 스토리지 비용을 줄이기 위해 사용자 정의 S3/FSx for NetApp ONTAP TTL/보존 관련 메커니즘을 구현해야 할 필요성
- 모델 아티팩트의 읽기 성능을 컨테이너 이미지 다운로드 시간과 비교하여 측정해야 함
- 더 복잡한 교차 리전 복제
변형 및 하이브리드 솔루션
이 솔루션은 풀 프로세스 가속화 솔루션 그룹과 잘 통합되어 컨테이너 이미지 크기와 풀 시간을 모두 개선합니다.
아티팩트를 메모리로 읽어 로컬 디스크에 저장하는 중간 단계를 건너뛰는 AI/ML 추론 애플리케이션의 경우 "Mountpoint CSI 드라이버를 사용하여 Amazon S3에서 직접 모델 아티팩트를 메모리로 읽기" 솔루션과 유사하게 다운로드 성능을 더욱 개선하기 위해 대체로(또는 추가로) 사용될 수 있습니다.
사용자 정의 Amazon AMI에 모델 아티팩트 베이킹
아키텍처 개요
그림 3: 사용자 정의 Amazon AMI에 모델 아티팩트 베이킹
이 솔루션은 매�우 드물게 변경되는 모델이 있고 시작 시간 지연에 매우 민감하며 네트워크 연결이 제한된 환경에 적합할 수 있습니다.
구현 가이드
위의 아키텍처 다이어그램에 따라 각 팀의 주요 고수준 단계는 다음과 같습니다.
DevOps/MLOps/플랫폼 팀:
- EC2 Image Builder 레시피 또는 Packer 템플릿을 생성하고 Git에 푸시합니다.
- AMI 베이킹 단계를 포함하도록 CI/CD 프로세스를 업데이트합니다.
- AMI를 사용하는 해당 Karpenter 노드 풀을 생성합니다.
- 매개변수로 제공될 노드 풀에 대한 노드 셀렉터를 포함하도록 애플리케이션 매니페스트를 변경합니다.
ML 또는 애플리케이션 팀:
- SDLC의 일부로 모델 아티팩트를 Amazon S3 버킷 또는 Git LFS에 업로드합니다.
- 이전과 같이 컨테이너 이미지 변경 사항을 Amazon ECR로 계속 푸시합니다.
- Kubernetes 매니페스트 배포에 대한 매개변수로 적절한 모델별 노드 풀 레이블을 제공합니다.
주요 이점
솔루션은 다음과 같은 주요 이점을 제공합니다:
- 모델이 컨테이너 시작 시 즉시 사용 가능하므로 다운로드 지연 없음
- 네트워크 종속성 없음
추가 이점
주요 이점 외에도 솔루션은 다음과 같은 잠재적인 추가 이점을 도입합니다:
- Kubernetes 아티팩트에 대한 변경 없음
- Karpenter 드리프트 감지를 통한 새 모델 버전에 대한 간소화된 롤아웃
- S3 또는 FSx와 같은 추가 서비스에 의존할 필요 없음
트레이드오프
트레이드오프는 다음을 포함합니다:
- Image Builder 또는 Packer를 CI/CD 프로세스에 통합하는 상당한 추가 운영 복잡성
- 실행 중인 인스턴스에서 AMI에 접근해야 하는 더 복잡한 설정으로 인한 느린 빌드 시간과 실험, 디버깅 및 테스트를 위한 더 긴 피드백 루프
- 모든 모델을 함께 배치하는 경우 스토리지 비용 또는 애플리케이션을 해당 AMI에 스케줄링하는 관리가 필요한 AMI별 모델 접근 방식으로 인한 극단적인 클러스터 세분화
변형 및 하이브리드 솔루션
이 솔루션은 풀 프로세스 가속화 솔루션 그룹과 잘 통합되어 컨테이너 이미지 크기와 풀 시간을 모두 개선합니다.
이것은 서빙 프레임워크와의 정확성 회귀 또는 호환성 문제를 도입할 수 있습니다.