General NLU
Support a variety of Chinese text understanding tasks, such as text classification, sentiment analysis, extraction, and customizable labeling systems.
Applicable scenarios
Used in scenarios such as text classification, sentiment analysis, text matching, and entity recognition.
Note
In version 1.4.0, General NLU API only supports Chinese language processing.
API reference
Text classification
-
HTTP request method:
POST -
Request body parameters
| Name | Type | Required | Description |
|---|---|---|---|
| subtask_type | String | Yes | Has the fixed value of "Text Classification". |
| text | String | Yes | Indicates the text to be classified. |
| choices | List | Yes | Indicates the candidate labels. For more information, please refer to the Request Body Example. |
| question | String | Yes | Used to prompt the model for guidance. |
- Example Request
Example 1
{
"subtask_type": "文本分类",
"text": "待分类的文本",
"choices": [{
"entity_type": "投资",
"label": 0,
"entity_list": []
}, {
"entity_type": "科技",
"label": 0,
"entity_list": []
}, {
"entity_type": "体育",
"label": 0,
"entity_list": []
}, {
"entity_type": "美食",
"label": 0,
"entity_list": []
}, {
"entity_type": "旅游",
"label": 0,
"entity_list": []
}],
"question": "这是篇什么类型的新闻"
}
Example 2
{
"subtask_type": "文本分类",
"text": "待分类的文本",
"choices": [{
"entity_type": "农业工程",
"label": 0,
"entity_list": []
}, {
"entity_type": "哲学",
"label": 0,
"entity_list": []
}, {
"entity_type": "教育学",
"label": 0,
"entity_list": []
}, {
"entity_type": "理学",
"label": 0,
"entity_list": []
}, {
"entity_type": "农学",
"label": 0,
"entity_list": []
}],
"question": "这篇文章属于哪个学科"
}
- Response parameters
| Name | Type | Description |
|---|---|---|
| result | Dict | Same format as the request parameters, with the label of the corresponding option set to 1 and an added score. Please refer to the Response Example for details. |
- Example JSON response
Example 1 Response
Assume the model returns the category of the "unclassified text" as "sports."
{
"subtask_type": "文本分类",
"text": "待分类的文本",
"choices": [{
"entity_type": "投资",
"label": 0,
"entity_list": []
}, {
"entity_type": "科技",
"label": 0,
"entity_list": []
}, {
"entity_type": "体育",
"label": 1,
"entity_list": [],
"score": 0.91592306
}, {
"entity_type": "美食",
"label": 0,
"entity_list": []
}, {
"entity_type": "旅游",
"label": 0,
"entity_list": []
}],
"question": "这是篇什么类型的新闻"
}
Example 2 Response
{
"subtask_type": "文本分类",
"text": "待分类的文本",
"choices": [{
"entity_type": "农业工程",
"label": 0,
"entity_list": []
}, {
"entity_type": "哲学",
"label": 0,
"entity_list": []
}, {
"entity_type": "教育学",
"label":1,
"entity_list": [],
"score": 0.91592306
}, {
"entity_type": "理学",
"label": 0,
"entity_list": []
}, {
"entity_type": "农学",
"label": 0,
"entity_list": []
}],
"question": "这篇文章属于哪个学科"
}
Sentiment analysis
-
HTTP request method:
POST -
Request body parameters
| Name | Type | Required | Description |
|---|---|---|---|
| subtask_type | String | Yes | Fixed as "Sentiment Classification" |
| text | String | Yes | The text to be classified |
| choices | List | Yes | Candidate sentiment labels, please refer to the Request Body Example |
| question | String | Yes | Used to prompt the model for guidance |
- Example Request
{
"subtask_type": "情感分类",
"text": "待分类的用户评论",
"choices": [{
"entity_type": "积极",
"label": 0,
"entity_list": []
}, {
"entity_type": "中性",
"label": 0,
"entity_list": []
}, {
"entity_type": "消极",
"label": 0,
"entity_list": []
}],
"question": "这句话的情感极性是什么"
}
- Response parameters
| Name | Type | Description |
|---|---|---|
| result | Dict | Same format as the request parameters, with the label of the corresponding option set to 1 and an added score. Please refer to the Response Example for details. |
- Example JSON response
Assume the model returns the sentiment polarity of the "unclassified user comment" as "neutral."
{
"subtask_type": "情感分类",
"text": "待分类的用户评论",
"choices": [{
"entity_type": "积极",
"label": 0,
"entity_list": []
}, {
"entity_type": "中性",
"label": 1,
"entity_list": [],
"score": 0.91592306
}, {
"entity_type": "消极",
"label": 0,
"entity_list": []
}],
"question": "这句话的情感极性是什么"
}
Text matching
-
HTTP request method:
POST -
Request body parameters
| Name | Type | Required | Description |
|---|---|---|---|
| subtask_type | String | Yes | Has the fixed value of "Text Matching" |
| text | String | Yes | Indicates the first text |
| choices | List | Yes | The entity_type of each element is the concatenation of the prompt word with the second text, for example, "can be inferred: second text" or "can be understood as: second text". Please refer to the Request Body Example for details. |
| question | String | Yes | Prompts the model for guidance |
- Example Request
Example 1
{
"subtask_type": "文本匹配",
"text": "在白云的蓝天下,一个孩子伸手摸着停在草地上的一架飞机的螺旋桨。",
"choices": [{
"entity_type": "可以推断出:一个孩子正伸手摸飞机的螺旋桨。",
"label": 0,
"entity_list": []
}, {
"entity_type": "不能推断出:一个孩子正伸手摸飞机的螺旋桨。",
"label": 0,
"entity_list": []
}, {
"entity_type": "很难推断出:一个孩子正伸手摸飞机的螺旋桨。",
"label": 0,
"entity_list": []
}],
"question": "同义文本"
}
Example 2
{
"subtask_type": "文本匹配",
"text": "您好,我还款了怎么还没扣款",
"choices": [{
"entity_type": "可以理解为:今天一直没有扣款",
"label": 0,
"entity_list": []
}, {
"entity_type": "不能理解为:今天一直没有扣款",
"label": 0,
"entity_list": []
}],
"question": "同义文本"
}
- Response parameters
| Name | Type | Description |
|---|---|---|
| result | Dict | Same format as the request parameters, with the label of the corresponding option set to 1 and an added score. Please refer to the Response Example for details. |
- Example JSON response
Example 1 response
{
"subtask_type": "文本匹配",
"text": "在白云的蓝天下,一个孩子伸手摸着停在草地上的一架飞机的螺旋桨。",
"choices": [{
"entity_type": "可以推断出:一个孩子正伸手摸飞机的螺旋桨。",
"label": 0,
"entity_list": []
}, {
"entity_type": "不能推断出:一个孩子正伸手摸飞机的螺旋桨。",
"label": 1,
"entity_list": [],
"score": 0.91592306
}, {
"entity_type": "很难推断出:一个孩子正伸手摸飞机的螺旋桨。",
"label": 0,
"entity_list": []
}],
"question": "同义文本"
}
Example 2 response
{
"subtask_type": "文本匹配",
"text": "您好,我还款了怎么还没扣款",
"choices": [{
"entity_type": "可以理解为:今天一直没有扣款",
"label": 1,
"entity_list": [],
"score": 0.91592306
}, {
"entity_type": "不能理解为:今天一直没有扣款",
"label": 0,
"entity_list": []
}],
"question": "同义文本"
}
Entity recognition
-
HTTP request method:
POST -
Request body parameters
| Name | Type | Required | Description |
|---|---|---|---|
| subtask_type | String | Yes | Fixed as "Entity Recognition" |
| text | String | Yes | The text to be classified |
| choices | List | Yes | The entity_type of each element represents the desired entity type to extract. Please refer to the Request Body Example for details. |
- Example Request
{
"subtask_type": "实体识别",
"text": "我们是首家支持英特尔、AMD 和 Arm 处理器的主要云提供商",
"choices": [{
"entity_type": "地址",
"label": 0,
"entity_list": []
}, {
"entity_type": "公司名",
"label": 0,
"entity_list": []
}, {
"entity_type": "人物姓名",
"label": 0,
"entity_list": []
}]
}
- Response parameters
| Name | Type | Description |
|---|---|---|
| result | Dict | Same format as the request parameters, with the entity_list corresponding to the extracted entities added with their content and position. Please refer to the Response Example for details. |
- Example JSON response
Assume the model returns the sentiment polarity of the "unclassified user comment" as "neutral."
{
"subtask_type": "实体识别",
"text": "我们是首家支持英特尔、AMD 和 Arm 处理器的主要云提供商",
"choices": [{
"entity_type": "地址",
"label": 0,
"entity_list": []
}, {
"entity_type": "公司名",
"label": 0,
"entity_list": [{
"entity_name":"英特尔",
"entity_type":"公司名",
"entity_idx":[
[7, 9]
]
},{
"entity_name":"AMD",
"entity_type":"公司名",
"entity_idx":[
[11, 13]
]
}]
}, {
"entity_type": "人物姓名",
"label": 0,
"entity_list": []
}]
}
API test
You can use the following tools (API explorer, Postman, cURL, Python, Java) to test calling APIs.
API Explorer
Prerequisites
When deploying the solution, you need to:
- set the parameter API Explorer to
yes. - set the parameter API Gateway Authorization to
NONE.
Otherwise, you can only view the API definitions in the API explorer, but cannot test calling API online.
Steps
- Sign in to the AWS CloudFormation console.
-
On the Stacks page, select the solution’s root stack. Do not select the NESTED stack.
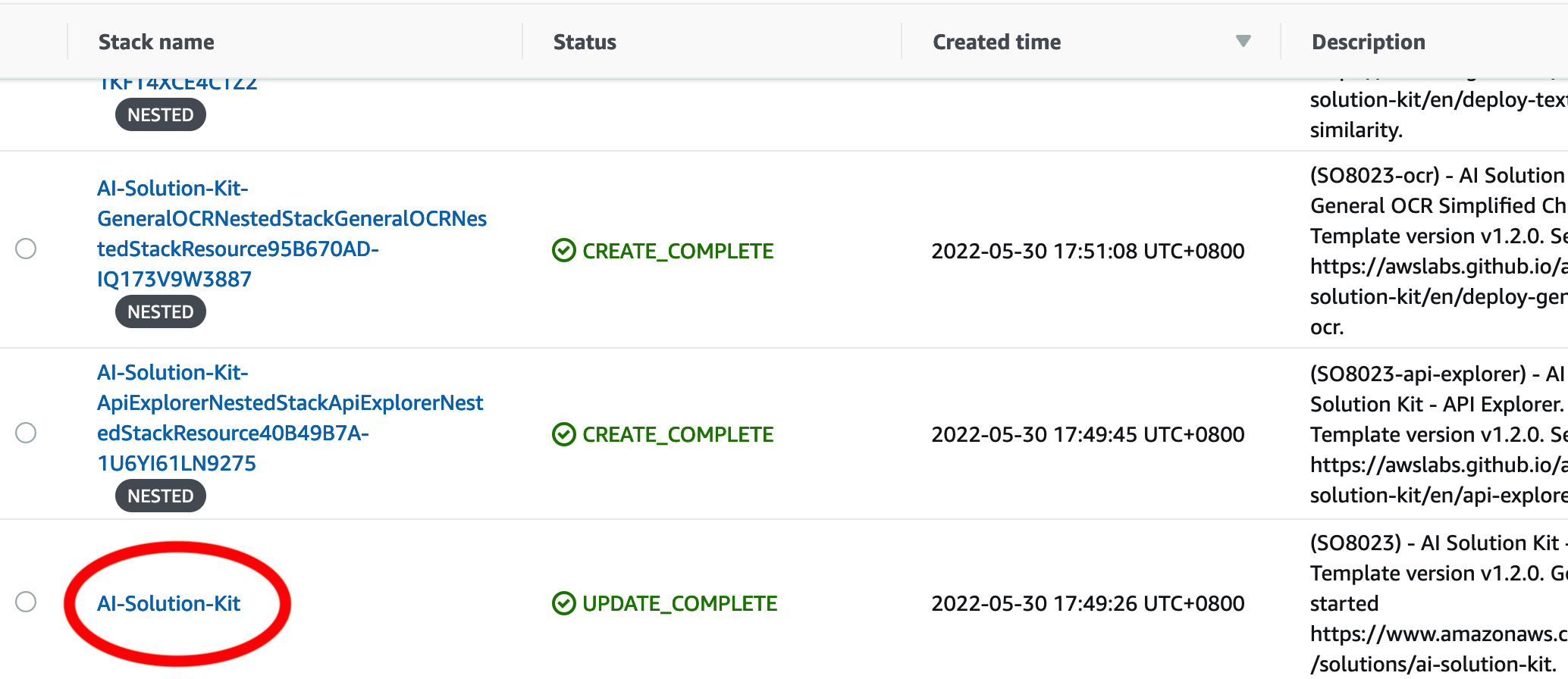
-
Choose the Outputs tab, and find the URL for APIExplorer.
-
Click the URL to access the API explorer. The APIs that you have selected during deployment will be displayed.
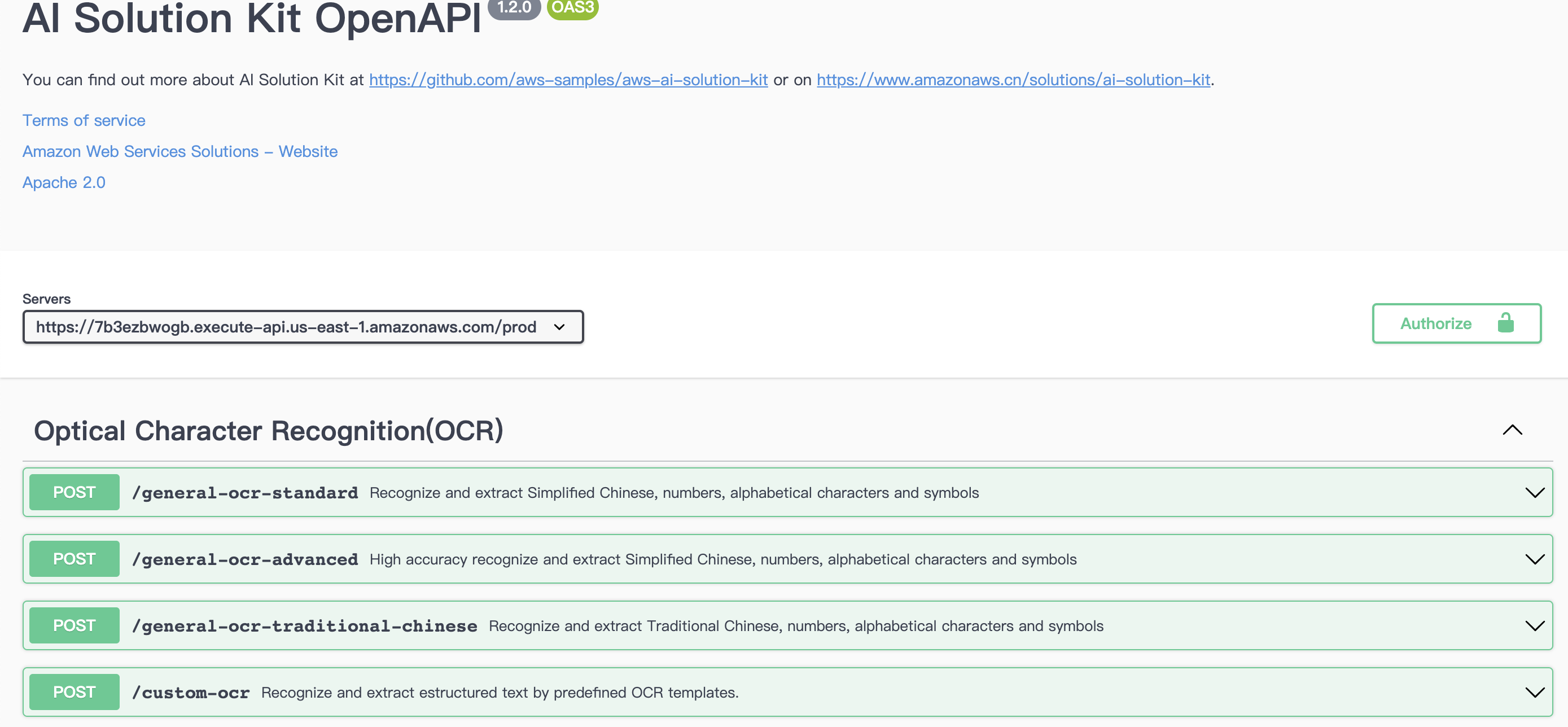
-
For the API you want to test, click the down arrow to display the request method.
- Choose the Try it out button, and enter the correct Body data to test API and check the test result.
- Make sure the format is correct, and choose Execute.
- Check the returned result in JSON format in the Responses body. If needed, copy or download the result.
- Check the Response headers.
- (Optional) Choose Clear next to the Execute button to clear the request body and responses.
Postman (AWS_IAM Authentication)
- Sign in to the AWS CloudFormation console.
- On the Stacks page, select the solution’s root stack.
- Choose the Outputs tab, and find the URL with the prefix
GeneralOCR. -
Create a new tab in Postman. Paste the URL into the address bar, and select POST as the HTTP call method.

-
Open the Authorization configuration, select Amazon Web Service Signature from the drop-down list, and enter the AccessKey, SecretKey and Amazon Web Service Region of the corresponding account (such as cn-north-1 or cn-northwest-1 ).
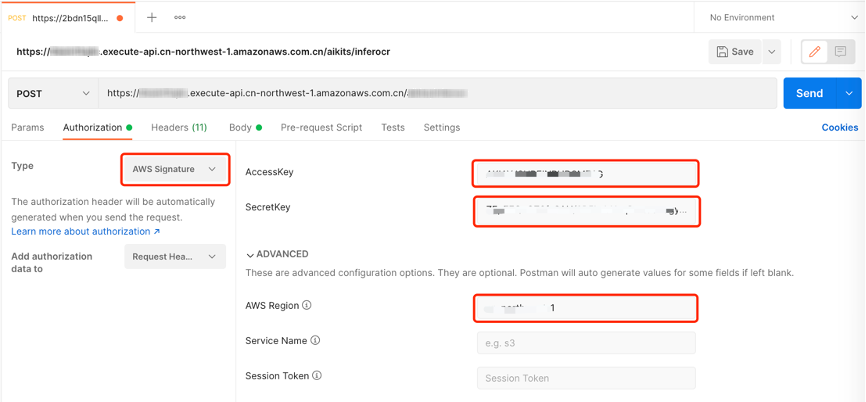
-
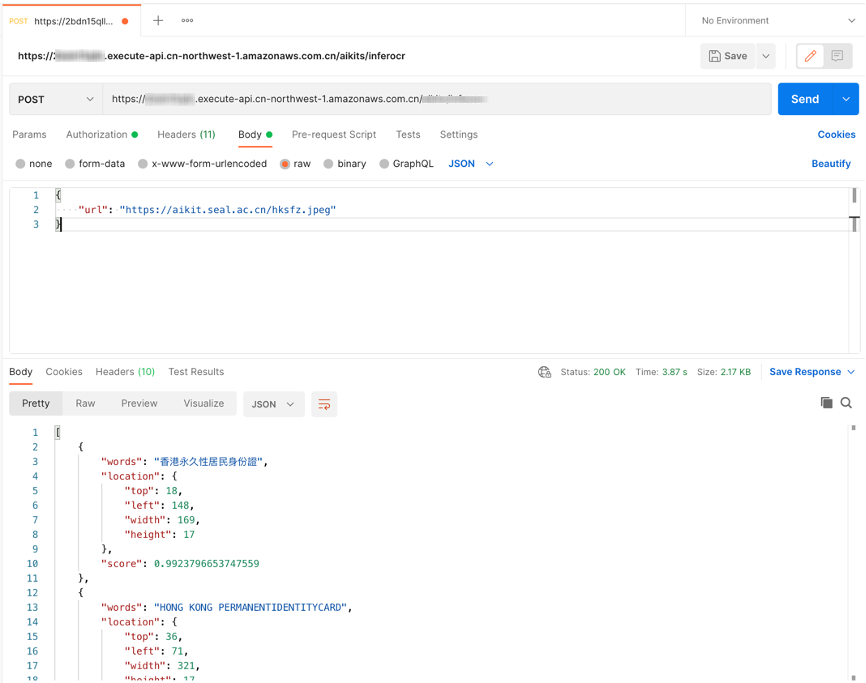
Open the Body configuration item and select the raw and JSON data types.
- Enter the test data in the Body, and click the Send button to see the corresponding return results.
{
"url": "Image URL address"
}
cURL
- Windows
curl --location --request POST "https://[API_ID].execute-api.[AWS_REGION].amazonaws.com/[STAGE]/general_nlu" ^
--header "Content-Type: application/json" ^
--data-raw "{\"url\": \"Image URL address\"}"
- Linux/MacOS
curl --location --request POST 'https://[API_ID].execute-api.[AWS_REGION].amazonaws.com/[STAGE]/general_nlu' \
--header 'Content-Type: application/json' \
--data-raw '{
"url":"Image URL address"
}'
Python (AWS_IAM Authentication)
import requests
import json
from aws_requests_auth.boto_utils import BotoAWSRequestsAuth
auth = BotoAWSRequestsAuth(aws_host='[API_ID].execute-api.[AWS_REGION].amazonaws.com',
aws_region='[AWS_REGION]',
aws_service='execute-api')
url = 'https://[API_ID].execute-api.[AWS_REGION].amazonaws.com/[STAGE]/general_nlu'
payload = {
'url': 'Image URL address'
}
response = requests.request("POST", url, data=json.dumps(payload), auth=auth)
print(json.loads(response.text))
Python (NONE Authentication)
import requests
import json
url = "https://[API_ID].execute-api.[AWS_REGION].amazonaws.com/[STAGE]/general_nlu"
payload = json.dumps({
"url": "Image URL address"
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
Java
OkHttpClient client = new OkHttpClient().newBuilder()
.build();
MediaType mediaType = MediaType.parse("application/json");
RequestBody body = RequestBody.create(mediaType, "{\n \"url\":\"Image URL address\"\n}");
Request request = new Request.Builder()
.url("https://xxxxxxxxxxx.execute-api.xxxxxxxxx.amazonaws.com/[STAGE]/general_nlu")
.method("POST", body)
.addHeader("Content-Type", "application/json")
.build();
Response response = client.newCall(request).execute();
Cost estimation
You are responsible for the cost of using each Amazon Web Services service when running the solution. As of this revision, the main cost factors affecting the solution include.
- Amazon API Gateway calls
- Amazon API Gateway data output
- Amazon CloudWatch Logs storage
- Amazon Elastic Container Registry storage
If you choose an Amazon Lambda based deployment, the factors also include:
- Amazon Lambda invocations
- Amazon Lambda running time
If you choose an Amazon SageMaker based deployment, the factors also include:
- Amazon SageMaker endpoint node instance type
- Amazon SageMaker endpoint node data input
- Amazon SageMaker endpoint node data output
Cost estimation example 1
In AWS China (Ningxia) Region operated by NWCD (cn-northwest-1), process an image of 1MB in 1 second
The cost of using this solution to process the image is shown below:
| Service | Dimensions | Cost |
|---|---|---|
| AWS Lambda | 1 million invocations | ¥1.36 |
| AWS Lambda | 8192MB memory, 1 seconds run each time | ¥907.8 |
| Amazon API Gateway | 1 million invocations | ¥28.94 |
| Amazon API Gateway | 100KB data output each time, ¥0.933/GB | ¥93.3 |
| Amazon CloudWatch Logs | 10KB each time, ¥6.228/GB | ¥62.28 |
| Amazon Elastic Container Registry | 0.5GB storage, ¥0.69/GB each month | ¥0.35 |
| Total | ¥1010.06 |
Cost estimation example 2
In US East (Ohio) Region (us-east-2), process an image of 1MB in 1 seconds
The cost of using this solution to process this image is shown below:
| Service | Dimensions | Cost |
|---|---|---|
| AWS Lambda | 1 million invocations | $0.20 |
| AWS Lambda | 8192MB memory, 1 seconds run each time | $133.3 |
| Amazon API Gateway | 1 million invocations | $3.5 |
| Amazon API Gateway | 100KB data output each time, $0.09/GB | $9 |
| Amazon CloudWatch Logs | 10KB each time, $0.50/GB | $5 |
| Amazon Elastic Container Registry | 0.5GB存储,$0.1/GB each month | $0.05 |
| Total | $142.95 |
Uninstall the deployment
You can uninstall the General NLU feature via Amazon CloudFormation as described in Add or remove AI features and make sure the GeneralNLU parameter is set to no in the parameters section.
Note
Time to uninstall the deployment is approximately: 10 Minutes