Ray on EKS
The AI on EKS content is being migrated to a new repository. 🔗 👉 Read the full migration announcement »
DEPRECATION NOTICE
This blueprint will be deprecated and eventually removed from this GitHub repository on October 27, 2024, in favor of the JARK stack. Please use the JARK stack blueprint instead.
Introduction
Ray is an open-source framework for building scalable and distributed applications. It is designed to make it easy to write parallel and distributed Python applications by providing a simple and intuitive API for distributed computing. It has a growing community of users and contributors, and is actively maintained and developed by the Ray team at Anyscale, Inc.
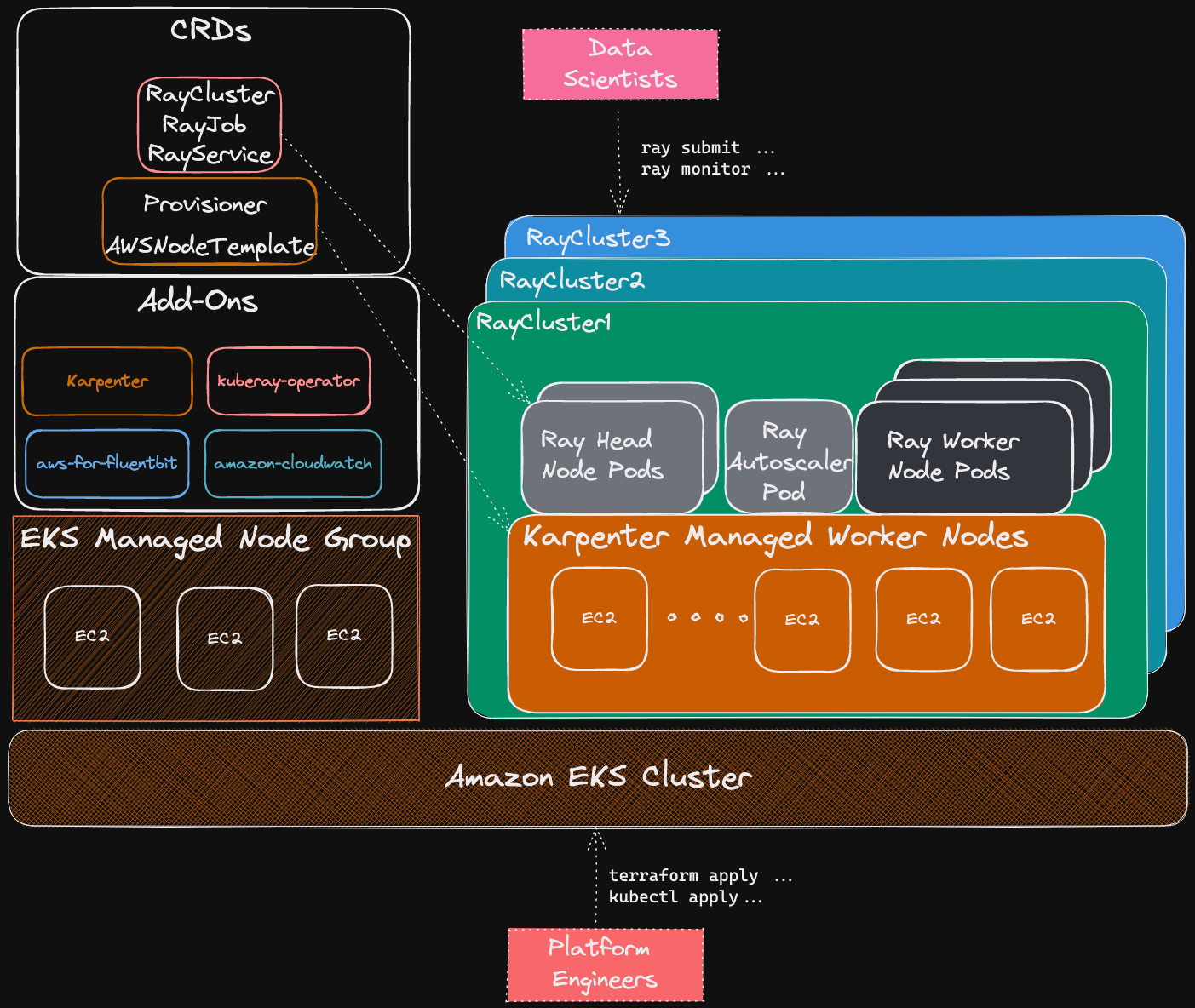
To deploy Ray in production across multiple machines users must first deploy Ray Cluster. A Ray Cluster consists of head nodes and worker nodes which can be autoscaled using the built-in Ray Autoscaler.

Source: https://docs.ray.io/en/latest/cluster/key-concepts.html
Ray on Kubernetes
Deploying Ray Cluster on Kubernetes including on Amazon EKS is supported via the KubeRay Operator. The operator provides a Kubernetes-native way to manage Ray clusters. The installation of KubeRay Operator involves deploying the operator and the CRDs for RayCluster, RayJob and RayService as documented here.
Deploying Ray on Kubernetes can provide several benefits:
-
Scalability: Kubernetes allows you to scale your Ray cluster up or down based on your workload requirements, making it easy to manage large-scale distributed applications.
-
Fault tolerance: Kubernetes provides built-in mechanisms for handling node failures and ensuring high availability of your Ray cluster.
-
Resource allocation: With Kubernetes, you can easily allocate and manage resources for your Ray workloads, ensuring that they have access to the necessary resources for optimal performance.
-
Portability: By deploying Ray on Kubernetes, you can run your workloads across multiple clouds and on-premises data centers, making it easy to move your applications as needed.
-
Monitoring: Kubernetes provides rich monitoring capabilities, including metrics and logging, making it easy to troubleshoot issues and optimize performance.
Overall, deploying Ray on Kubernetes can simplify the deployment and management of distributed applications, making it a popular choice for many organizations that need to run large-scale machine learning workloads.
Before moving forward with the deployment please make sure you have read the pertinent sections of the official documentation.
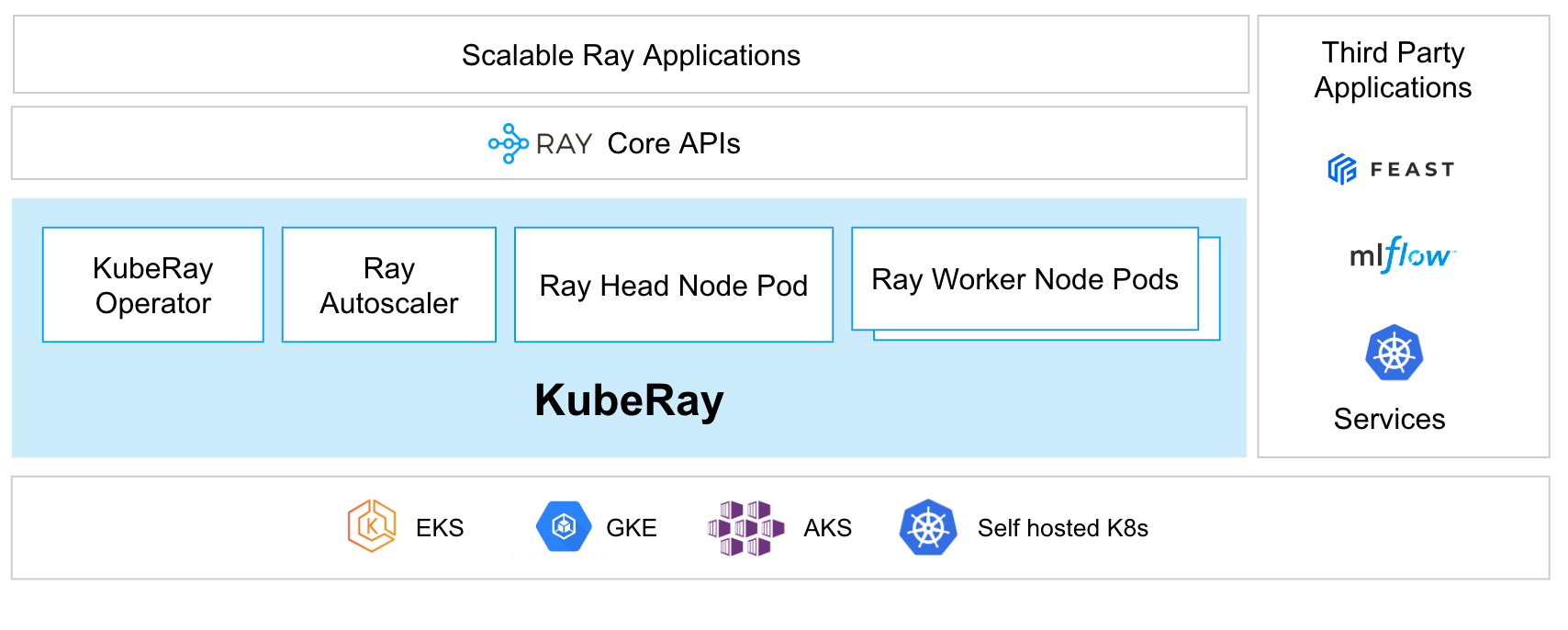
Source: https://docs.ray.io/en/latest/cluster/kubernetes/index.html
Deploying the Example
In this example, you will provision Ray Cluster on Amazon EKS using the KubeRay Operator. The example also demonstrates the use of Karpenter of autoscaling of worker nodes for job specific Ray Clusters.