DataLakeStorage
Data Lake based on medallion architecture and AWS best-practices.
Overview
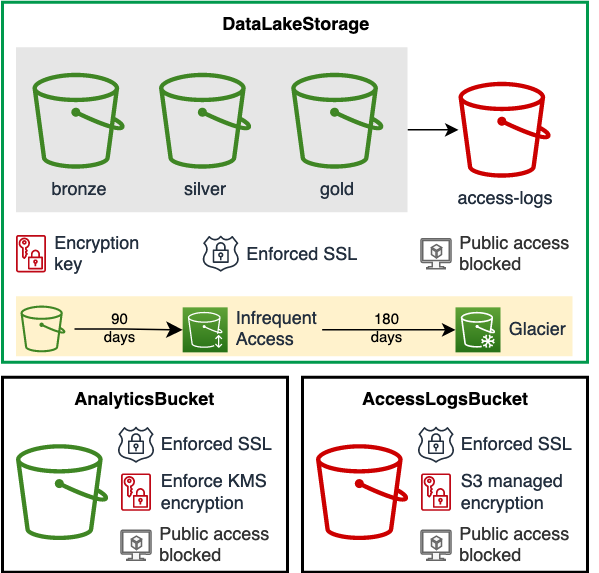
At the high level, DataLakeStorage creates three Amazon S3 buckets configured specifically for data lake on AWS. By default these buckets are named Bronze, Silver, and Gold to represent different data layers. You can customize bucket names according to your needs.
DataLakeStorage uses AnalyticsBucket and AccessLogsBucket constructs from DSF on AWS, to create storage and access logs buckets respectively. Your data lake storage is encrypted using AWS KMS a default customer managed key. You can also provide your own KMS Key. We provide data lifecycle management that you can customize to your needs.
Here is the overview of DataLakeStorage features:
- Medalion design with S3 buckets for Bronze, Silver, and Gold data.
- Server-side encryption using a single KMS customer key for all S3 buckets.
- Enforced SSL in-transit encryption.
- Logs data lake access in a dedicated bucket within a prefix matching the bucket name.
- Buckets, objects and encryption keys can be retained when the CDK resource is destroyed (default).
- All public access blocked.
Usage
- TypeScript
- Python
class ExampleDefaultDataLakeStorageStack extends cdk.Stack {
constructor(scope: Construct, id: string) {
super(scope, id);
new dsf.storage.DataLakeStorage(this, 'MyDataLakeStorage');
}
}
class ExampleDefaultDataLakeStorageStack(cdk.Stack):
def __init__(self, scope, id):
super().__init__(scope, id)
dsf.storage.DataLakeStorage(self, "MyDataLakeStorage")
Bucket naming
The construct ensures the default bucket names uniqueness which is a pre-requisite to create Amazon S3 buckets.
To achieve this, the construct is creating the default bucket names like <LAYER>-<AWS_ACCOUNT_ID>-<AWS_REGION>-<UNIQUEID> where:
<LAYER>is the layer in the medallion architecture (bronze, silver or gold).<AWS_ACCOUNT_ID>and<AWS_REGION>are the account ID and region where you deploy the construct.<UNIQUEID>is an 8 characters unique ID calculated based on the CDK path.
If you provide the bucketName parameter, you need to ensure the name is globaly unique.
Alternatively, you can use the BucketUtils.generateUniqueBucketName() utility method to create unique names.
This method generates a unique name based on the provided name, the construct ID and the CDK scope:
- The bucket name is suffixed the AWS account ID, the AWS region and an 8 character hash of the CDK path.
- The maximum length for the bucket name is 26 characters.
- TypeScript
- Python
new dsf.storage.DataLakeStorage(this, 'MyDataLakeStorage', {
bronzeBucketName: dsf.utils.BucketUtils.generateUniqueBucketName(this, 'MyDataLakeStorage', 'custom-bronze-name')
});
dsf.storage.DataLakeStorage(self, "MyDataLakeStorage",
bronze_bucket_name=dsf.utils.BucketUtils.generate_unique_bucket_name(self, "MyDataLakeStorage", "custom-bronze-name")
)
Objects removal
You can specify if buckets, objects and encryption keys should be deleted when the CDK resource is destroyed using removalPolicy. To have an additional layer of protection, we require users to set a global context value for data removal in their CDK applications.
Buckets, objects and encryption keys can be destroyed when the CDK resource is destroyed only if both data lake removal policy and DSF on AWS global removal policy are set to remove objects.
You can set @data-solutions-framework-on-aws/removeDataOnDestroy (true or false) global data removal policy in cdk.json:
{
"context": {
"@data-solutions-framework-on-aws/removeDataOnDestroy": true
}
}
Or programmatically in your CDK app:
- TypeScript
- Python
// Set context value for global data removal policy
this.node.setContext('@data-solutions-framework-on-aws/removeDataOnDestroy', true);
new dsf.storage.DataLakeStorage(this, 'DataLakeStorage', {
removalPolicy: RemovalPolicy.DESTROY
});
# Set context value for global data removal policy
self.node.set_context("@data-solutions-framework-on-aws/removeDataOnDestroy", True)
dsf.storage.DataLakeStorage(self, "DataLakeStorage",
removal_policy=RemovalPolicy.DESTROY
)
Data lifecycle management
We provide a simple data lifecycle management for data lake storage, that you can customize to your needs. By default:
- Bronze data is moved to Infrequent Access after 30 days and archived to Glacier after 90 days.
- Silver and Gold data is moved to Infrequent Access after 90 days and is not archived.
Change the data lifecycle rules using the DataLakeStorage properties:
- TypeScript
- Python
new dsf.storage.DataLakeStorage(this, 'MyDataLakeStorage', {
bronzeBucketInfrequentAccessDelay: 90,
bronzeBucketArchiveDelay: 180,
silverBucketInfrequentAccessDelay: 180,
silverBucketArchiveDelay: 360,
goldBucketInfrequentAccessDelay: 180,
goldBucketArchiveDelay: 360,
});
dsf.storage.DataLakeStorage(self, "MyDataLakeStorage",
bronze_bucket_infrequent_access_delay=90,
bronze_bucket_archive_delay=180,
silver_bucket_infrequent_access_delay=180,
silver_bucket_archive_delay=360,
gold_bucket_infrequent_access_delay=180,
gold_bucket_archive_delay=360
)