How it works
The Multi-Agent Orchestrator framework is a powerful tool for implementing sophisticated AI systems comprising multiple specialized agents. Its primary purpose is to intelligently route user queries to the most appropriate agents while maintaining contextual awareness throughout interactions.
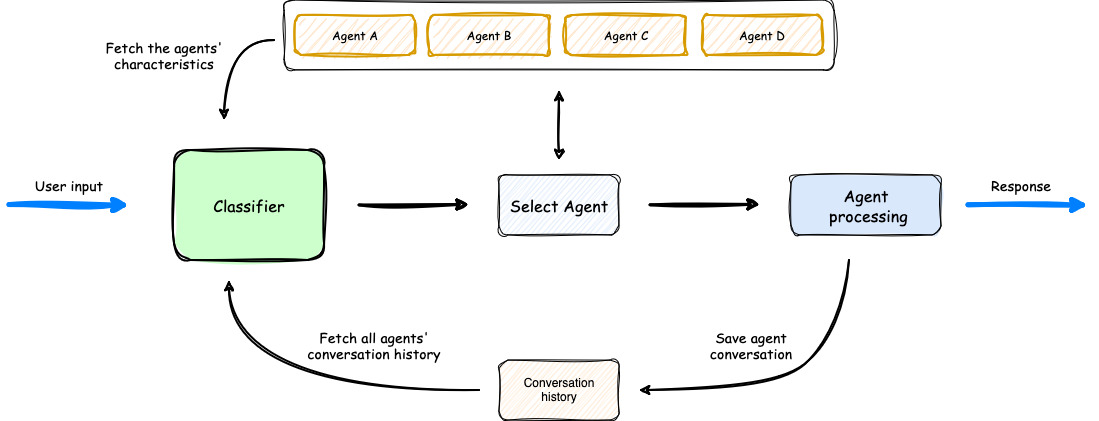
Orchestrator Logic
The Multi-Agent Orchestrator follows a specific process for each user request:
-
Request Initiation: The user sends a request to the orchestrator.
-
Classification: The Classifier uses an LLM to analyze the user’s request, agent descriptions, and conversation history from all agents for the current user ID and session ID. This comprehensive view allows the classifier to understand ongoing conversations and context across all agents.
- The framework includes two built-in classifier implementations, with one used by default.
- Users can customize many options for these built-in classifiers.
- There’s also the option to create your own custom classifier, potentially using models different from those in the built-in implementations.
The classifier determines the most appropriate agent for:
- A new query requiring a specific agent (e.g., “I want to book a flight” or “What is the base rate interest for a 20-year loan?”)
- A follow-up to a previous interaction, where the user might provide a short answer like “Tell me more”, “Again”, or “12”. In this case, the LLM identifies the last agent that responded and is waiting for this answer.
-
Agent Selection: The Classifier responds with the name of the selected agent.
-
Request Routing: The user’s input is sent to the chosen agent.
-
Agent Processing: The selected agent processes the request. It automatically retrieves its own conversation history for the current user ID and session ID. This ensures that each agent maintains its context without access to other agents’ conversations.
- The framework provides several built-in agents for common tasks.
- Users have the option to customize a wide range of properties for these built-in agents.
- There’s also the flexibility to quickly create your own custom agents for specific needs.
-
Response Generation: The agent generates a response, which may be sent in a standard response mode or via streaming, depending on the agent’s capabilities and initialization settings.
-
Conversation Storage: The orchestrator automatically handles saving the user’s input and the agent’s response into the storage for that specific user ID and session ID. This step is crucial for maintaining context and enabling coherent multi-turn conversations. Key points about storage:
- The framework provides two built-in storage options: in-memory and DynamoDB.
- You have the flexibility to quickly create and implement your own custom storage solution and pass it to the orchestrator.
- Conversation saving can be disabled for individual agents that don’t require follow-up interactions.
- The number of messages kept in the history can be configured for each agent.
-
Response Delivery: The orchestrator delivers the agent’s response back to the user.
This process ensures that each request is handled by the most appropriate agent while maintaining context across the entire conversation. The classifier has a global view of all agent conversations, while individual agents only have access to their own conversation history. This architecture allows for intelligent routing and context-aware responses while maintaining separation between agent functionalities.
The orchestrator’s automatic handling of conversation saving and fetching, combined with flexible storage options, provides a powerful and customizable system for managing conversation context in multi-agent scenarios. The ability to customize or replace classifiers and agents offers further flexibility to tailor the system to specific needs.
The Multi-Agent Orchestrator framework empowers you to leverage multiple agents for handling diverse tasks.
In the framework context, an agent can be any of the following (or a combination of one or more):
- LLMs (through Amazon Bedrock or any other cloud-hosted or on-premises LLM)
- API calls
- AWS Lambda functions
- Local processing
- Amazon Lex Bot
- Amazon Bedrock Agent
- Any other specific task or process
This flexible architecture allows you to incorporate as many agents as your application requires, and combine them in ways that best suit your needs.
Each agent needs a name and a description (plus other properties specific to the type of agent you use).
The agent description plays a crucial role in the orchestration process.
It should be detailed and comprehensive, as the orchestrator relies on this description, along with the current user input and the conversation history of all agents, to determine the most appropriate routing for each request.
While the framework’s flexibility is a strength, it’s important to be mindful of potential overlaps between agents, which could lead to incorrect routing. To help you analyze and prevent such overlaps, we recommend reviewing our agent overlap analysis section for a deeper understanding.
Agent abstraction: unified processing across platforms
One of the key strengths of the Multi-Agent Orchestrator framework lies in its agents’ standard implementation. This standardization allows for remarkable flexibility and consistency across diverse environments. Whether you’re working with different cloud providers, various LLM models, or a mix of cloud-based and local solutions, agents provide a uniform interface for task execution.
This means you can seamlessly switch between, for example, an Amazon Lex Bot Agent and a Amazon Bedrock Agent with tools, or transition from a cloud-hosted LLM to a locally running one, all while maintaining the same code structure.
Also, if your application needs to use different models with a Bedrock LLM Agent and/or a Amazon Lex Bot Agent in sequence or in parallel, you can easily do so as the code implementation is already in place. This standardized approach means you don’t need to write new code for each model; instead, you can simply use the agents as they are.
To leverage this flexibility, simply install the framework and import the needed agents. You can then call them directly using the processRequest method, regardless of the underlying technology. This standardization not only simplifies development and maintenance but also facilitates easy experimentation and optimization across multiple platforms and technologies without the need for extensive code refactoring.
This standardization empowers you to experiment with various agent types and configurations while maintaining the integrity of their core application code.
Main Components of the Orchestrator
The main components that are composing the orchestrator:
-
- Acts as the central coordinator for all other components
- Manages the flow of information between Classifier, Agents, Storage, and Retrievers
- Processes user input and orchestrates the generation of appropriate responses
- Handles error scenarios and fallback mechanisms
-
- Examines user input, agent descriptions, and conversation history
- Identifies the most appropriate agent for each request
- Custom Classifiers: Create entirely new classifiers for specific tasks or domains
-
- Prebuilt Agents: Ready-to-use agents for common tasks
- Customizable Agents: Extend or override prebuilt agents to tailor functionality
- Custom Agents: Create entirely new agents for specific tasks or domains
-
- Maintains conversation history
- Supports flexible storage options (in-memory and DynamoDB)
- Custom storage solutions
- Operates on two levels: Classifier context and Agent context
-
- Enhance LLM-based agents performance by providing context and relevant information
- Improve efficiency by pulling necessary information on-demand, rather than relying solely on the model’s training data
- Prebuilt Retrievers: Ready-to-use retrievers for common data sources
- Custom Retrievers: Create specialized retrievers for specific data stores or formats
Each component of the orchestrator can be customized or replaced with custom implementations, providing unparalleled flexibility and making the framework adaptable to a wide variety of scenarios and specific requirements.