txt2img Guide
You can open the txt2img tab to perform text-to-image inference using the combined functionality of the native region of txt2img and the newly added "Amazon SageMaker Inference" panel in the solution. This allows you to invoke cloud resources for txt2img inference tasks.
txt2img user guide
General Inference Scenario
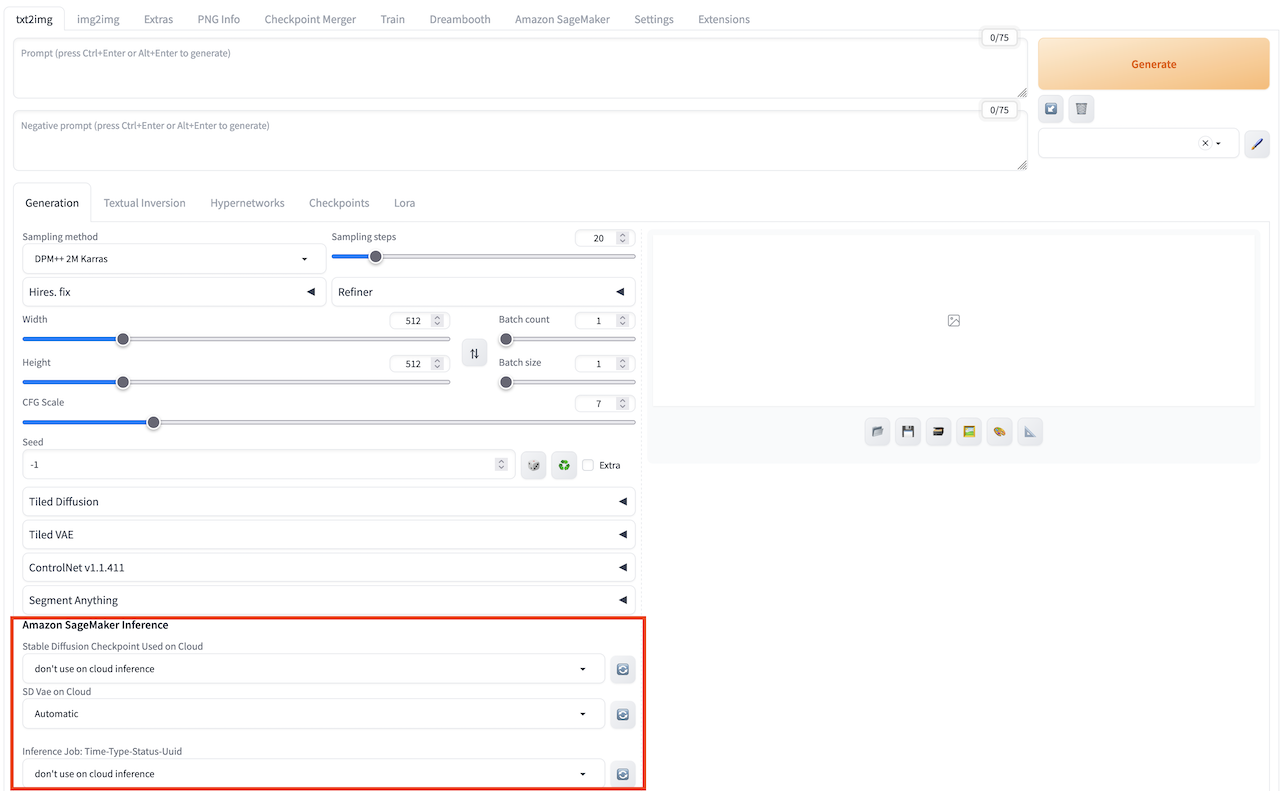
- Navigate to txt2img tab, find Amazon SageMaker Inference panel.
-
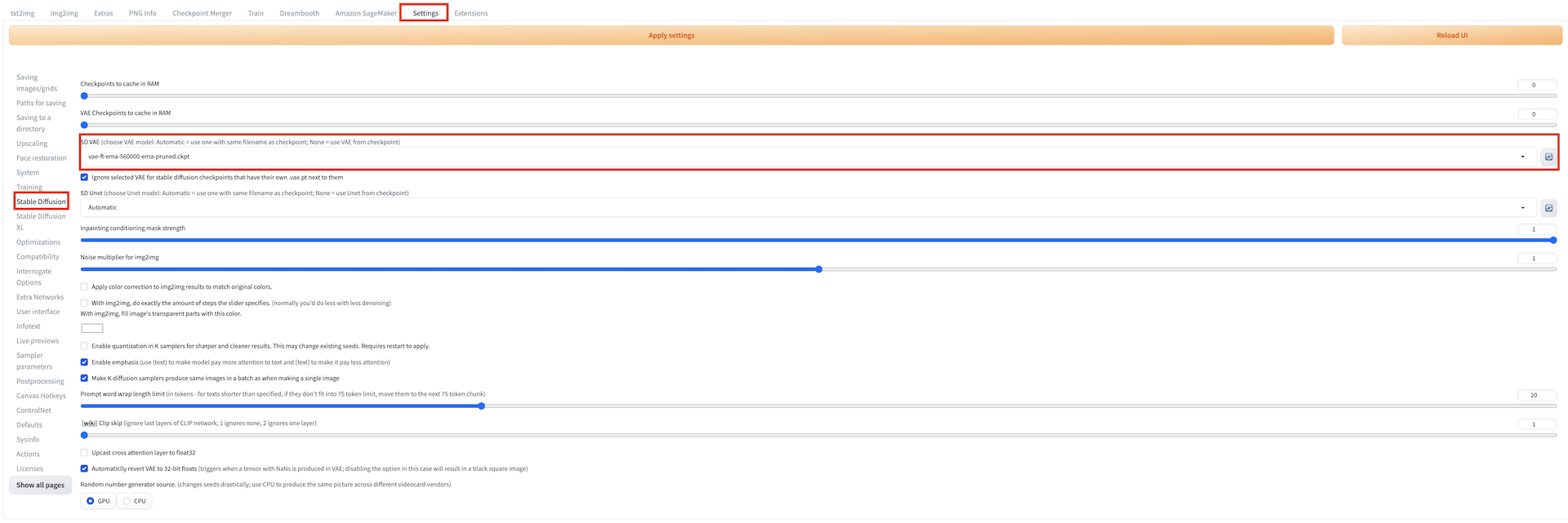
Enter the required parameters for inference. Similar to local inference, you can customize the inference parameters of the native txt2img, including model name (stable diffusion checkpoint, extra networks:Lora, Hypernetworks, Textural Inversion and VAE), prompts, negative prompts, sampling parameters, and inference parameters. For VAE model switch, navigate to Settings tab, select Stable Diffusion in the left panel, and then select VAE model in SD VAE (choose VAE model: Automatic = use one with same filename as checkpoint; None = use VAE from checkpoint).
Notice
The model files used in the inference should be uploaded to the cloud before generate, which can be referred to the introduction of chapter Cloud Assets Management. The current model list displays options for both local and cloud-based models. For cloud-based inference, it is recommended to select models with the sagemaker keyword as a suffix, indicating that they have been uploaded to the cloud for subsequent inference.
-
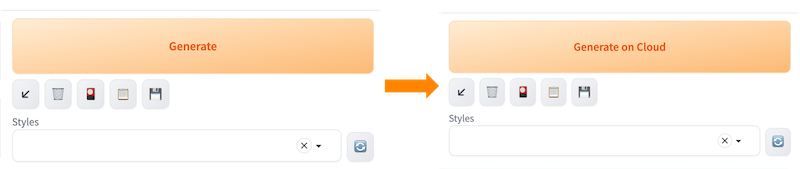
Select Stable Diffusion checkpoint model that will be used for cloud inference through Stable Diffusion Checkpoint Used on Cloud, and the button Generate will change to button Generate on Cloud.
Notice
This field is mandatory.
-
Finish setting all the parameters, and then click Generate on Cloud.
-
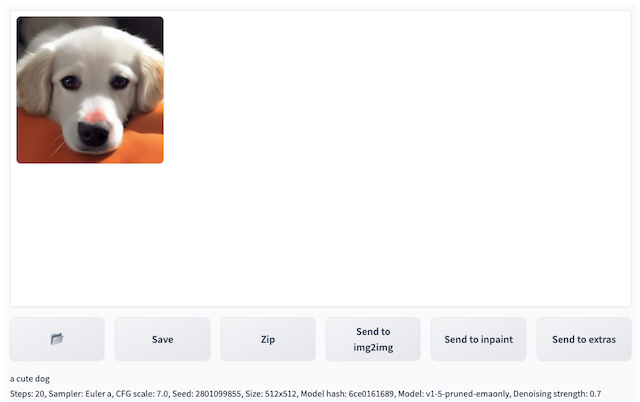
Check inference result. Fresh and select the top option among Inference Job dropdown list, the Output section in the top-right area of the txt2img tab will display the results of the inference once completed, including the generated images, prompts, and inference parameters. Based on this, you can perform subsequent workflows such as clicking Save or Send to img2img.
Note: The list is sorted in reverse chronological order based on the inference time, with the most recent inference task appearing at the top. Each record is named in the format of inference time -> inference id.
Continuous Inference Scenario
- Following the General Inference Scenario, complete the parameter inputs and click Generate on Cloud to submit the initial inference task.
- Wait for the appearance of a new Inference IDin the right-side "Output" section.
- Once the new Inference ID appears, you can proceed to click Generate on Cloud again for the next inference task.

Inference Using Extra Model(s) like Lora
- Please follow the native version of WebUI, and upload a copy of the required model (including Textual Inversion, Hypernetworks, Checkpoints or Lora models) to local machine.
- Upload corresponding models to the cloud, following Upload Models.
- Select the required model, adjust the weights of the model in prompts field, and click Generate on Cloud to inference images.
Inference Job Histories
Inference Job displays the latest 10 inference jobs by default, following naming format Time-Type-Status-UUID. Checking Show All will display all inference jobs the account has. Checking Advanced Inference Job filter and apply filters as need will provide users a customized inference job list.