EKS에 Enterprise RAG 및 AI-Q를 배포하려면 GPU 인스턴스(g5, p4 또는 p5 제품군)에 대한 액세스가 필요합니다. 이 블루프린트는 동적 GPU 프로비저닝을 위해 Karpenter 오토스케일링에 의존합니다.
이 블루프린트는 두 가지 배포 옵션을 제공합니다: Enterprise RAG Blueprint (NVIDIA Nemotron 및 NeMo Retriever 모델을 사용한 멀티모달 문서 처리) 또는 전체 AI-Q Research Assistant (웹 검색을 통한 자동화된 연구 보고서 추가). 둘 다 동적 GPU 오토스케일링과 함께 Amazon EKS에서 실행됩니다.
Amazon EKS의 NVIDIA Enterprise RAG 및 AI-Q Research Assistant
NVIDIA AI-Q Research Assistant란?
NVIDIA AI-Q Research Assistant는 어디서나 작동할 수 있고, 자체 데이터 소스로 정보를 제공받으며, 몇 시간 분량의 연구를 몇 분 만에 종합할 수 있는 맞춤형 AI 연구원을 생성하는 AI 기반 연구 어시스턴트입니다. AI-Q NVIDIA Blueprint를 통해 개발자는 AI 에이전트를 엔터프라이즈 데이터에 연결하고 추론 및 도구를 사용하여 효율성과 정밀도로 심층적인 소스 자료를 추출할 수 있습니다.
주요 기능
고급 연구 자동화:
- 빠른 보고서 합성을 위한 5배 빠른 토큰 생성
- 더 나은 의미론적 정확도로 15배 빠른 데이터 수집
- 효율성과 정밀도로 다양한 데이터 세트 요약
- 자동으로 포괄적인 연구 보고서 생성
NVIDIA NeMo Agent Toolkit:
- 에이전트 워크플로우 개발 및 최적화 용이
- 다양한 프레임워크에 걸쳐 워크플로우 통합, 평가, 감사 및 디버그
- 최적화 기회 식별
- 각 작업에 가장 적합한 에이전트와 도구를 유연하게 선택하고 연결
NVIDIA NeMo Retriever를 통한 고급 의미론적 쿼리:
- 멀티모달 PDF 데이터 추출 및 검색 (텍스트, 표, 차트, 인포그래픽)
- 15배 빠른 엔터프라이즈 데이터 수집
- 3배 낮은 검색 지연 시간
- 다국어 및 교차 언어 지원
- 정확도 향상을 위한 리랭킹
- GPU 가속 인덱스 생성 및 검색
Llama Nemotron을 통한 빠른 추론:
- 최고의 정확도와 최저 지연 시간 추론 기능
- Llama-3.3-Nemotron-Super-49B-v1.5 추론 모델 사용
- 데이터 소스 분석 및 패턴 식별
- 포괄적인 연구를 기반으로 솔루션 제안
- 엔터프라이즈 데이터로 지원되는 컨텍스트 인식 생성
웹 검색 통합:
- Tavily API로 구동되는 실시간 웹 검색
- 현재 정보로 온프레미스 소스 보완
- 내부 문서를 넘어 연구 확장
AI-Q 구성 요소
공식 AI-Q 아키텍처에 따르면:
1. NVIDIA AI Workbench
- 에이전트 워크플로우를 위한 간소화된 개발 환경
- 로컬 테스트 및 사용자 정의
- 다양한 LLM의 손쉬운 구성
- NVIDIA NeMo Agent Toolkit 통합
2. NVIDIA RAG Blueprint
- 대규모 온프레미스 멀티모달 문서 세트 쿼리를 위한 솔루션
- 텍스트, 이미지, 표 및 차트 추출 지원
- GPU 가속을 통한 의미론적 검색 및 검색
- AI-Q의 연구 기능을 위한 기반
3. NVIDIA NeMo Retriever Microservices
- 멀티모달 문서 수집
- 그래픽 요소 감지
- 표 구조 추출
- 텍스트 인식을 위한 PaddleOCR
- 15배 빠른 데이터 수집
4. NVIDIA NIM Microservices
- LLM 및 비전 모델을 위한 최적화된 추론 컨테이너
- Llama-3.3-Nemotron-Super-49B-v1.5 추론 모델
- 보고서 생성을 위한 Llama-3.3-70B-Instruct 모델
- GPU 가속 추론
5. 웹 검색 (Tavily)
- 실시간 웹 검색으로 온프레미스 소스 보완
- 내부 문서를 넘어 연구 확장
- 웹 보강 연구 보고서 지원
NVIDIA Enterprise RAG Blueprint란?
NVIDIA Enterprise RAG Blueprint는 검색과 생성 모두를 위한 확장 가능하고 사용자 정의 가능한 파이프라인을 구축하기 위한 완전한 기반을 제공하는 프로덕션 준비 참조 워크플로우입니다. NVIDIA NeMo Retriever 모델과 NVIDIA Llama Nemotron 모델로 구동되는 이 블루프린트는 높은 정확도, 강력한 추론 및 엔터프라이즈 규모의 처리량에 최적화되어 있습니다.
멀티모달 데이터 수집, 고급 검색, 리랭킹 및 반영 기술에 대한 내장 지원과 LLM 기반 워크플로우와의 원활한 통합을 통해 수백만 개의 문서에서 텍스트, 표, 차트, 오디오 및 인포그래픽에 걸쳐 언어 모델을 엔터프라이즈 데이터에 연결하여 진정한 컨텍스트 인식 및 생성적 응답을 가능하게 합니다.
주요 기능
데이터 수집 및 처리:
- 텍스트, 표, 차트 및 인포그래픽이 포함된 멀티모달 PDF 데이터 추출
- 오디오 파일 수집 지원
- 사용자 정의 메타데이터 지원
- 문서 요약
- 엔터프라이즈 규모로 수백만 개의 문서 지원
벡터 데이터베이스 및 검색:
- 문서 세트에 걸친 다중 컬렉션 검색 가능
- 밀집 및 희소 검색을 통한 하이브리드 검색
- 정확도 향상을 위한 리랭킹
- GPU 가속 인덱스 생성 및 검색
- 플러그 가능 벡터 데이터베이스 아키텍처:
- ElasticSearch 지원
- Milvus 지원
- OpenSearch Serverless 지원 (이 배포에서 사용)
- 복잡한 쿼리를 위한 쿼리 분해
- 동적 메타데이터 필터 생성
멀티모달 및 고급 생성:
- 답변 생성에서 선택적 Vision Language Model (VLM) 지원
- VLM을 통한 옵트인 이미지 캡션
- 대화형 Q&A를 위한 다중 턴 대화
- 동시 사용자를 위한 다중 세션 지원
- 선택적 반영으로 정확도 향상
거버넌스 및 안전:
- 선택적 프로그래밍 가능 가드레일로 콘텐츠 안전 개선
- 엔터프라이즈급 보안 기능
- 데이터 프라이버시 및 규정 준수 제어
관측성 및 텔레메트리:
- 평가 스크립트 포함 (RAGAS 프레임워크)
- 분산 추적을 위한 OpenTelemetry 지원
- 추적 시각화를 위한 Zipkin 통합
- 메트릭 및 모니터링을 위한 Grafana 대시보드
- 성능 프로파일링 및 최적화 도구
개발자 기능:
- 테스트 및 데모용 사용자 인터페이스 포함
- DRA를 사용한 GPU 공유를 위한 NIM Operator 지원
- 네이티브 Python 라이브러리 지원
- 쉬운 통합을 위한 OpenAI 호환 API
- 분해 가능하고 사용자 정의 가능한 아키텍처
- 기능 확장을 위한 플러그인 시스템
Enterprise RAG 사용 사례
Enterprise RAG Blueprint는 독립적으로 또는 대규모 시스템의 구성 요소로 사용할 수 있습니다:
- 문서 저장소 전반의 엔터프라이즈 검색
- 조직 지식 베이스용 지식 어시스턴트
- 도메인별 애플리케이션용 생성형 코파일럿
- 특정 산업에 맞춤화된 수직 AI 워크플로우
- 에이전트 워크플로우의 기반 구성 요소 (AI-Q Research Assistant처럼)
- 컨텍스트 인식 응답을 통한 고객 지원 자동화
- 대규모 문서 분석 및 요약
엔터프라이즈 검색, 지식 어시스턴트, 생성형 코파일럿 또는 수직 AI 워크플로우를 구축하든, RAG용 NVIDIA AI Blueprint는 프로토타입에서 프로덕션으로 자신 있게 이동하는 데 필요한 모든 것을 제공합니다. 독립적으로 사용하거나, 다른 NVIDIA Blueprint와 결합하거나, 더 고급 추론 기반 애플리케이션을 지원하기 위해 에이전트 워크플로우에 통합할 수 있습니다.
개요
이 블루프린트는 **NVIDIA AI-Q Research Assistant**를 Amazon EKS에 구현하며, 포괄적인 연구 기능을 위해 NVIDIA RAG Blueprint와 AI-Q 구성 요소를 결합합니다.
배포 옵션
이 블루프린트는 사용 사례에 따라 두 가지 배포 모드를 지원합니다:
옵션 1: Enterprise RAG Blueprint
- 멀티모달 문서 처리와 함께 NVIDIA Enterprise RAG Blueprint 배포
- NeMo Retriever 마이크로서비스 및 OpenSearch 통합 포함
- 적합 용도: 사용자 정의 RAG 애플리케이션, 문서 Q&A 시스템, 지식 베이스 구축
옵션 2: 전체 AI-Q Research Assistant
- 옵션 1의 모든 것에 AI-Q 구성 요소 추가
- Tavily API를 통한 웹 검색 기능으로 자동화된 연구 보고서 생성 추가
- 적합 용도: 포괄적인 연구 작업, 자동화된 보고서 생성, 웹 보강 연구
두 배포 모두 Karpenter 오토스케일링과 엔터프라이즈 보안 기능을 포함합니다. 옵션 1로 시작하여 필요에 따라 나중에 AI-Q 구성 요소를 추가할 수 있습니다.
배포 접근 방식
이 설정 프로세스의 이유는? 이 구현은 여러 단계를 포함하지만 여러 가지 이점을 제공합니다:
- 완전한 인프라: VPC, EKS 클러스터, OpenSearch Serverless 및 모니터링 스택을 자동으로 프로비저닝
- 엔터프라이즈 기능: 보안, 모니터링 및 확장성 기능 포함
- AWS 통합: Karpenter 오토스케일링, EKS Pod Identity 인증 및 관리형 AWS 서비스 활용
- 재현 가능: Infrastructure as Code로 환경 전반에 걸쳐 일관된 배포 보장
주요 기능
성능 최적화:
- Karpenter 오토스케일링: 워크로드 요구에 따른 동적 GPU 노드 프로비저닝
- 지능형 인스턴스 선택: 최적의 GPU 인스턴스 유형(G5, P4, P5) 자동 선택
- 빈 패킹: 여러 워크로드에 걸친 효율적인 GPU 활용
엔터프라이즈 준비:
- OpenSearch Serverless: 자동 확장을 통한 관리형 벡터 데이터베이스
- Pod Identity 인증: Pod에서 안전한 AWS IAM 액세스를 위한 EKS Pod Identity
- 관측성 스택: GPU 모니터링을 위한 Prometheus, Grafana 및 DCGM
- 보안 액세스: 제어된 서비스 액세스를 위한 Kubernetes 포트 포워딩
아키텍처
AI-Q Research Assistant 아키텍처
배포는 Karpenter 기반 동적 프로비저닝과 함께 Amazon EKS를 사용��합니다:
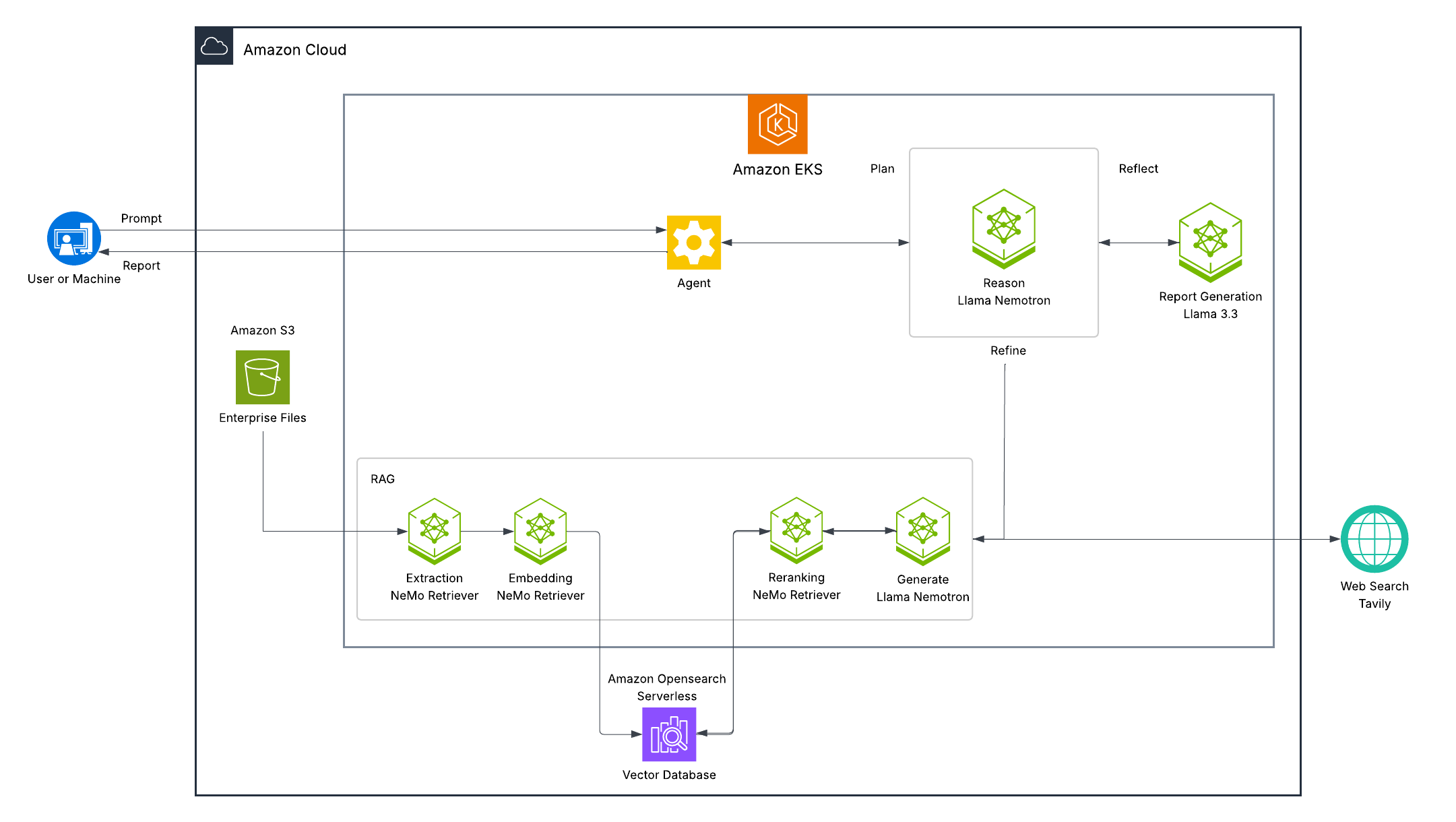
Enterprise RAG Blueprint 아키텍처
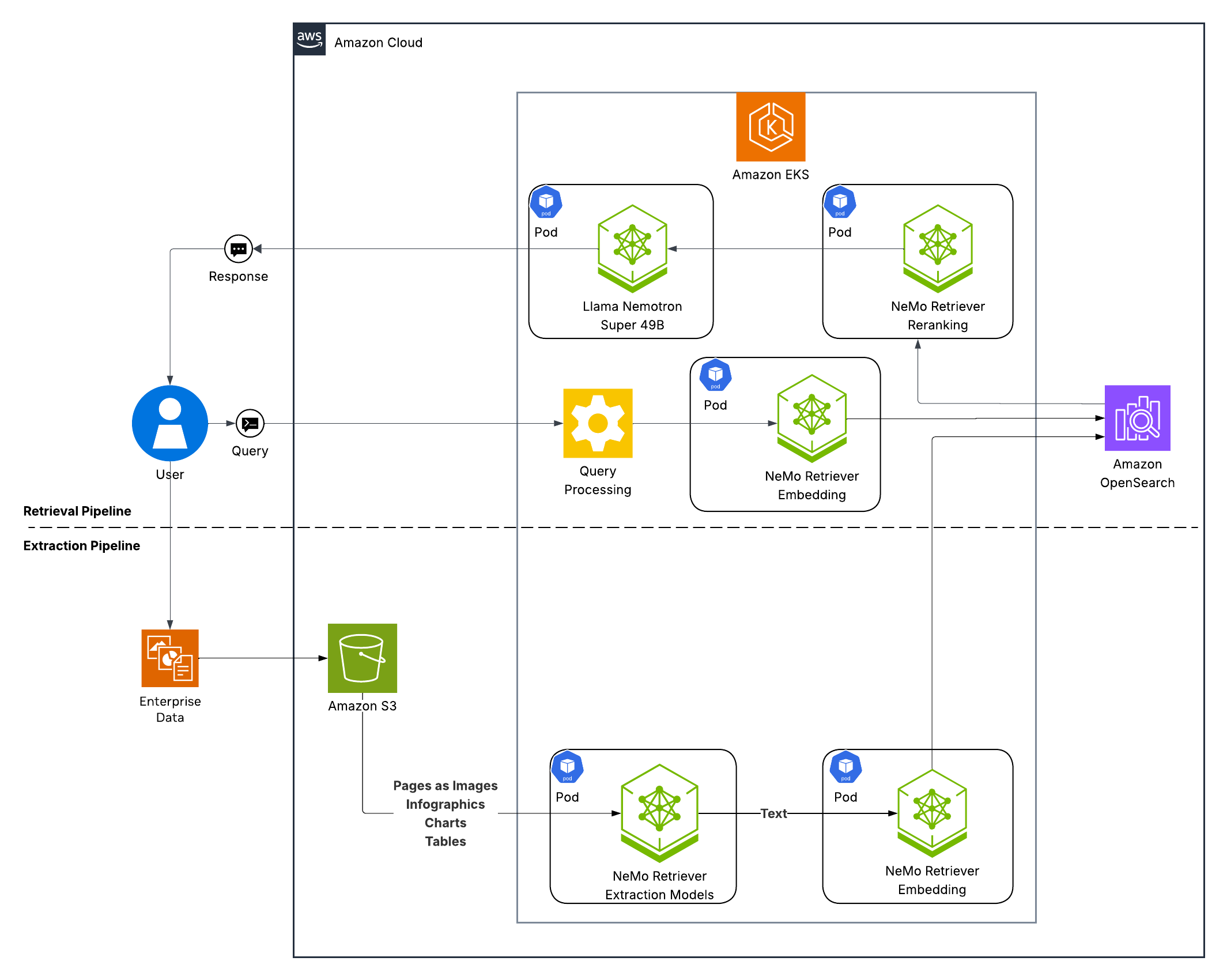
RAG 파이프라인은 여러 특수 NIM 마이크로서비스를 통해 문서를 처리합니다:
1. Llama-3.3-Nemotron-Super-49B-v1.5
- 고급 추론 모델
- RAG 및 보고서 작성 모두를 위한 기본 추론 및 생성
- 쿼리 재작성 및 분해
- 필터 표현식 생성
2. 임베딩 및 리랭킹
- LLama 3.2 NV-EmbedQA: 2048차원 임베딩
- LLama 3.2 NV-RerankQA: 관련성 점수 매기기
3. NV-Ingest 파이프라인
- PaddleOCR: 이미지에서 텍스트 추출
- Page Elements: 문서 레이아웃 이해
- Graphic Elements: 차트 및 다이어그램 감지
- Table Structure: 표 형식 데이터 추출
4. AI-Q Research Assistant 구성 요소
- 보고서 생성을 위한 Llama-3.3-70B-Instruct 모델 (선택 사항, 2 GPU)
- Tavily API를 통한 웹 검색
- 연구 워크플로우를 위한 백엔드 오케스트레이션
사전 요구 사항
이 배포는 상당한 비용이 발생할 수 있는 GPU 인스턴스를 사용합니다. 자세한 비용 추정은 이 가이드 끝의 비용 고려 사항을 참조하십시오. 사용하지 않을 때는 항상 리소스를 정리하십시오.
시스템 요구 사항: AWS CLI 액세스가 있는 모든 Linux/macOS 시스템
다음 도구를 설치하십시오:
- AWS CLI: 적절한 권한으로 구성됨 (설치 가이드)
- kubectl: Kubernetes 명령줄 도구 (설치 가이드)
- helm: Kubernetes 패키지 관리자 (설치 가이드)
- terraform: Infrastructure as code 도구 (설치 가이드)
- git: 버전 제어 (설치 가이드)
필수 API 토큰
- NGC API 토큰: NVIDIA NIM 컨테이너 및 AI Foundation 모델에 액세스하는 데 필요
- 먼저 다음 옵션 중 하나를 통해 가입하십시오 (API 키는 이러한 계정 중 하나가 있어야만 작동합니다):
- 옵션 1 - NVIDIA Developer Program (빠른 시작):
- 여기에서 가입
- POC 및 개발 워크로드용 무료 계정
- 테스트 및 평가에 이상적
- 옵션 2 - NVIDIA AI Enterprise (프로덕션):
- AWS Marketplace를 통해 구독
- 전체 지원 및 SLA가 포함된 엔터프라이즈 라이선스
- 프로덕션 배포에 필요
- 옵션 1 - NVIDIA Developer Program (빠른 시작):
- 그런 다음 API 키를 생성하십시오:
- 옵션 1 또는 2를 통해 가입한 후 NGC Personal Keys에서 API 키를 생성합니다
- 이 키를 잘 보관하십시오 - 배포 시 필요합니다
- 먼저 다음 옵션 중 하나를 통해 가입하십시오 (API 키는 이러한 계정 중 하나가 있어야만 작동합니다):
- Tavily API 키: AI-Q Research Assistant에 선택 사항
- AI-Q에서 웹 검색 기능 활성화
- AI-Q는 이 키 없이도 RAG 전용 모드로 작동 가능
- Enterprise RAG 전용 배포에는 필요 없음
- Tavily에서 계정 생성
- 대시보드에서 API 키 생성
- 이 키를 잘 보관하십시오 - AI-Q에서 웹 검색을 원하면 배포 시 필요합니다
GPU 인스턴스 액세스
AWS 계정이 GPU 인스턴스에 액세스할 수 있는지 확인하십시오. 이 블루프린트는 Karpenter NodePool을 통해 여러 인스턴스 제품군을 지원합니다:
지원되는 GPU 인스턴스 제품군:
| 인스턴스 제품군 | GPU 유형 | 성능 프로파일 | 사용 사례 |
|---|---|---|---|
| G5 (기본) | NVIDIA A10G | 비용 효율적, 24GB VRAM | 일반 워크로드, 개발 |
| G6e | NVIDIA L40S | 균형 잡힌, 48GB VRAM | 고메모리 모델 |
| P4d/P4de | NVIDIA A100 | 고성능, 40/80GB VRAM | 대규모 배포 |
| P5/P5e/P5en | NVIDIA H100 | 초고성능, 80GB VRAM | 최대 성능 |
참고: G5 인스턴스는 접근 가능한 시작점을 제공하기 위해 Helm 값에 미리 구성되어 있습니다. Helm 값 파일의
nodeSelector를 편집하여 P4/P5/G6e 인스턴스로 전환할 수 있습니다 - 인프라 변경은 필요 없습니다.
GPU 인스턴스 유형 사용자 정의 (선택 사항)
👈시작하기
시작하려면 저장소를 클론하십시오:
git clone https://github.com/awslabs/ai-on-eks.git
cd ai-on-eks
배포
이 블루프린트는 두 가지 배포 방법을 제공합니다:
옵션 A: 자동화된 배포 (권장)
👈옵션 B: 수동 배포
👈서비스 액세스
배포가 완료되면 포트 포워딩을 사용하여 로컬로 서비스에 액세스합니다.
포트 포워딩 명령
👈애플리케이션 사용
RAG 프론트엔드 (http://localhost:3001):
- UI를 통해 직접 문서 업로드
- 수집된 문서에 대해 질문
- 다중 턴 대화 테스트
- 인용 및 소스 보기
AI-Q Research Assistant (http://localhost:3000):
- 연구 주제 및 질문 정의
- 업로드된 문서와 웹 검색 모두 활용
- 자동으로 포괄적인 연구 보고서 생성
- 다양한 형식으로 보고서 내보내기
Ingestor API (http://localhost:8082/docs):
- 프로그래매틱 문서 수집
- 배치 업로드 기능
- 컬렉션 관리
- OpenAPI 문서 보기
데이터 수집
RAG(및 선택적으로 AI-Q)를 배포한 후 OpenSearch 벡터 데이터베이스에 문서를 수집할 수 있습니다.
지원되는 파일 유형
RAG 파이프라인은 다음을 포함한 멀티모달 문서 수집을 지원합니다:
- PDF 문서
- 텍스트 파일 (.txt, .md)
- 이미지 (.jpg, .png)
- Office 문서 (.docx, .pptx)
- HTML 파일
NeMo Retriever 마이크로서비스는 이러한 문서에서 텍스트, 표, 차트 및 이미지를 자동으로 추출합니다.
수집 방법
문서를 수집하는 두 가지 옵션이 있습니다:
방법 1: UI 업로드 (테스트/소규모 데이터셋)
프론트엔드 인터페이스를 통해 직접 개별 문서를 업로드합니다:
- RAG 프론트엔드 (http://localhost:3001) - 개별 문서 테스트에 이상적
- AIRA 프론트엔드 (http://localhost:3000) - 연구 작업용 문��서 업로드
이 방법은 다음에 적합합니다:
- RAG 파이프라인 테스트
- 소규모 문서 컬렉션 (100개 미만)
- 빠른 실험
- 임시 문서 업로드
방법 2: S3 배치 수집 (프로덕션/대규모 데이터셋)
S3 배치 수집 명령
👈수집 확인
수집 후 문서가 사용 가능한지 확인합니다:
- RAG 프론트엔드를 통해: http://localhost:3001 로 이동하여 문서에 대해 질문
- Ingestor API를 통해: http://localhost:8082/docs에서 컬렉션 통계 확인
- OpenSearch를 통해: AWS 콘솔을 사용하여 OpenSearch 컬렉션에 직접 쿼리
관측성
RAG 및 AI-Q 배포에는 성능 모니터링, 요청 추적 및 메트릭 보기를 위한 내�장 관측성 도구가 포함되어 있습니다.
모니터링 서비스 액세스
자동화된 접근 방식 (권장):
blueprints 디렉토리로 이동하고 포트 포워딩을 시작합니다:
cd ../../blueprints/inference/nvidia-deep-research
./app.sh port start observability
이것은 자동으로 포트 포워딩합니다:
- Zipkin: http://localhost:9411 - RAG 분산 추적
- Grafana: http://localhost:8080 - RAG 메트릭 및 대시보드
- Phoenix: http://localhost:6006 - AI-Q 워크플로우 추적 (배포된 경우)
상태 확인:
./app.sh port status
관측성 포트 포워딩 중지:
./app.sh port stop observability
수동 kubectl 명령
👈모니터링 UI
포트 포워딩이 활성화되면:
-
Zipkin UI (RAG 추적): http://localhost:9411
- 엔드투엔드 요청 추적 보기
- 지연 시간 병목 현상 분석
- 다중 서비스 상호 작용 디버그
-
Grafana UI (RAG 메트릭): http://localhost:8080
- 기본 자격 증명: admin/admin
- RAG 메트릭을 위한 사전 구축된 대시보드
- GPU 사용률 및 처리량 모니터링
-
Phoenix UI (AI-Q 추적): http://localhost:6006
- 에이전트 워크플로우 시각화
- LLM 호출 추적
- 연구 보고서 생성 분석
참고: 이러한 관측성 도구 사용에 대한 자세한 정보는 다음을 참조하십시오:
대안: 모니터링 서비스를 공개적으로 노출해야 하는 경우 적절한 인증 및 보안 제어가 있는 Ingress 리소스를 생성할 수 있습니다.
정리
애플리케이션만 제거
인프라를 유지하면서 RAG 및 AI-Q 애플리케이션을 제거하려면:
�자동화 스크립트 사용 (권장):
cd ../../blueprints/inference/nvidia-deep-research
./app.sh cleanup
정리 스크립트는 다음을 수행합니다:
- 모든 포트 포워딩 프로세스 중지
- AIRA 및 RAG Helm 릴리스 제거
- 로컬 포트 포워딩 PID 파일 제거
수동 애플리케이션 정리:
# blueprints 디렉토리로 이동
cd ../../blueprints/inference/nvidia-deep-research
# 포트 포워딩 중지
./app.sh port stop all
# AIRA 제거 (배포된 경우)
helm uninstall aira -n nv-aira
# RAG 제거
helm uninstall rag -n rag
(선택 사항) 배포 중에 생성된 임시 파일 정리:
rm /tmp/.port-forward-*.pid
참고: 이것은 애플리케이션만 제거합니다. EKS 클러스터와 인프라는 계속 실행됩니다. GPU 노드는 5-10분 내에 Karpenter에 의해 종료됩니다.
인프라 정리
전체 EKS 클러스터 및 모든 인프라 구성 요소를 제거하려면:
# infra 디렉토리로 이동
cd ../../../infra/nvidia-deep-research
# 정리 스크립트 실행
./cleanup.sh
경고: 이것은 영구적으로 삭제합니다:
- EKS 클러스터 및 모든 워크로드
- OpenSearch Serverless 컬렉션 및 데이터
- VPC 및 네트워킹 리소스
- 모든 관련 AWS 리소스
진행하기 전에 중요한 데이터를 백업하십시오.
소요 시간: 전체 해제에 ~10-15분
비용 고려 사항
이 배포의 예상 비용
👈참조
공식 NVIDIA 리소스
문서:
- NVIDIA AI-Q Research Assistant GitHub: 공식 AI-Q 블루프린트 저장소
- NVIDIA AI-Q on AI Foundation: AI-Q 블루프린트 카드 및 호스팅 버전
- NVIDIA RAG Blueprint: 완전한 RAG 플랫폼 문서
- NVIDIA NIM Documentation: NIM 마이크로서비스 참조
- NVIDIA AI Enterprise: 엔터프라이즈 AI 플랫폼
모델:
- Llama-3.3-Nemotron-Super-49B-v1.5: 고급 추론 모델 (490억 파라미터)
- Llama-3.3-70B-Instruct: 명령어 따르기 모델
컨테이너 이미지 및 Helm 차트:
- NVIDIA NGC Catalog: 공식 컨테이너 레지스트리
- RAG Blueprint Helm Chart: Kubernetes 배포
- NVIDIA NIM Containers: 최적화된 추론 컨테이너
AI-on-EKS 블루프린트 리소스
AI-on-EKS 블루프린트 리소스:
- AI-on-EKS Repository: 메인 블루프린트 저장소
- Infrastructure & Deployment Code: Karpenter와 애플리케이션 배포 스크립트를 포함한 Terraform 자동화
- Usage Guide: 배포 후 사용, 데이터 수집 및 관측성
문서:
- Infrastructure & Deployment Guide: 단계별 인프라 및 애플리케이션 배포
- Usage Guide: 서비스 액세스, 데이터 수집, 모니터링
- OpenSearch Integration: Pod Identity 인증 설정
- Karpenter Configuration: P4/P5 GPU 지원
관련 기술
Kubernetes 및 AWS:
- Amazon EKS: 관리형 Kubernetes 서비스
- Karpenter: Kubernetes 노드 오토스케일링
- OpenSearch Serverless: 관리형 벡터 데이터베이스
- EKS Pod Identity: Pod용 IAM 인증
AI/ML 도구:
- NVIDIA DCGM: GPU 모니터링
- Prometheus: 메트릭 수집
- Grafana: 시각화 대시보드
다음 단계
- 기능 탐색: 다양한 파일 유형으로 멀티모달 문서 처리 테스트
- 배포 확장: 다중 리전 또는 다중 클러스터 설정 구성
- 애플리케이션 통합: 애플리케이션을 RAG API 엔드포인트에 연결
- 성능 모니터링: 지속적인 모니터링을 위해 Grafana 대시보드 사용
- 사용자 정의 모델: 자체 미세 조정된 모델로 교체
- 보안 강화: 인증, 속�도 제한 및 재해 복구 추가
이 배포는 NVIDIA Enterprise RAG Blueprint 및 NVIDIA AI-Q Research Assistant를 Karpenter 자동 확장, OpenSearch Serverless 통합 및 원활한 AWS 서비스 통합을 포함한 엔터프라이즈급 기능과 함께 Amazon EKS에 제공합니다.