EKS에서 ML 모델을 배포하려면 GPU 또는 Neuron 인스턴스에 대한 접근이 필요합니다. 배포가 작동하지 않는 경우, 이러한 리소스에 대한 접근 권한이 없기 때문인 경우가 많습니다. 또한 일부 배포 패턴은 Karpenter 자동 스케일링과 정적 노드 그룹에 의존합니다. 노드가 초기화되지 않으면 Karpenter 또는 노드 그룹의 로그를 확인하여 문제를 해결하세요.
Meta-llama/Llama-2-7b-chat-hf 및 Mistralai/Mistral-7B-Instruct-v0.2 모델을 사용하려면 Hugging Face 계정을 통한 접근이 필요합니다.
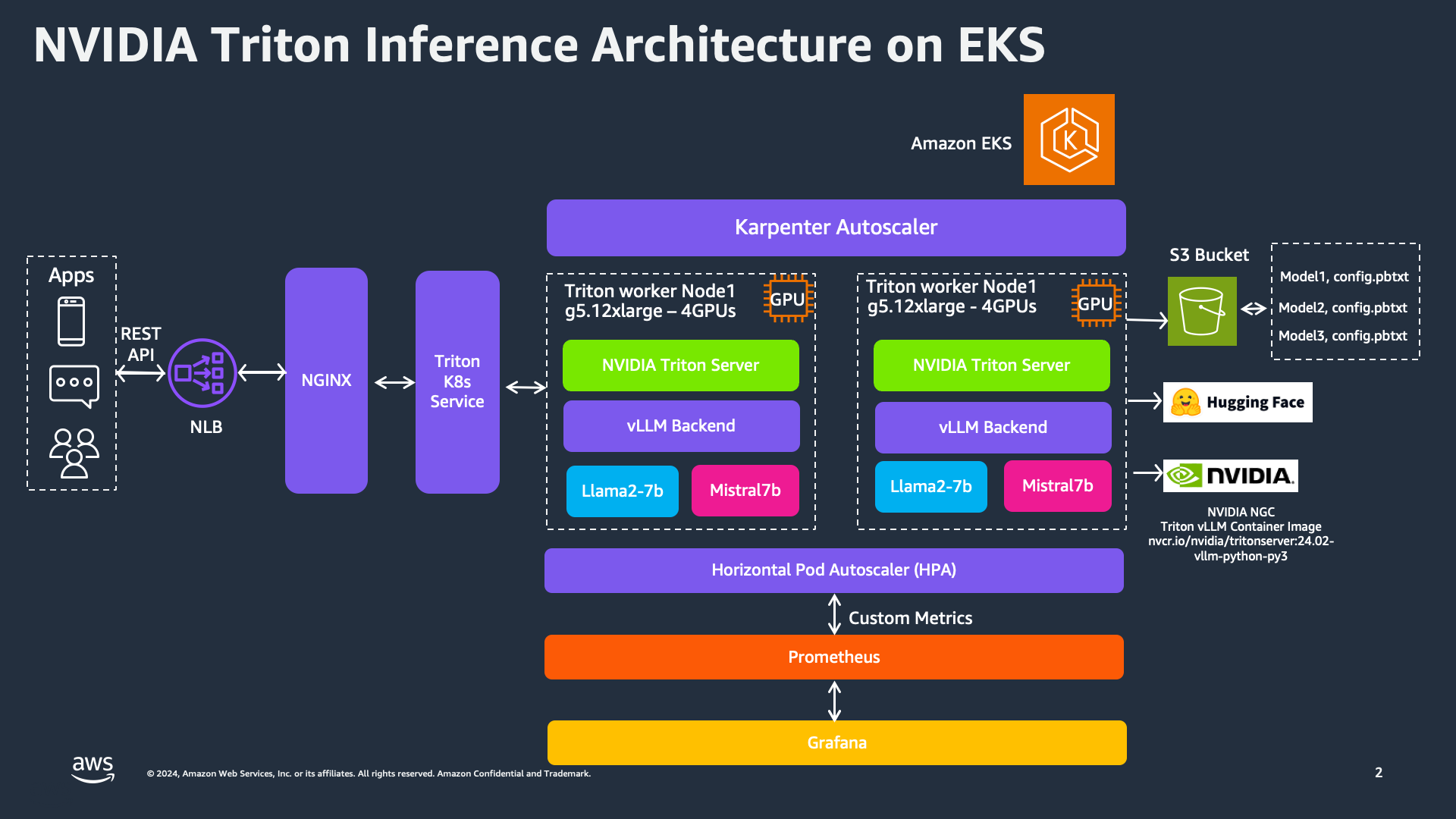
NVIDIA Triton Server와 vLLM을 사용한 여러 대규모 언어 모델 배포
이 패턴에서는 Triton Inference Server와 vLLM 백엔드/엔진을 사용하여 여러 대규모 언어 모델(LLM)을 배포하는 방법을 살펴봅니다. mistralai/Mistral-7B-Instruct-v0.2와 meta-llama/Llama-2-7b-chat-hf 두 가지 모델로 이 프로세스를 시연합니다. 이 모델들은 4개의 GPU가 장착된 g5.24xlarge 멀티 GPU 인스턴스에서 호스팅되며, 각 모델은 최대 1개의 GPU를 사용합니다.
NVIDIA Triton Inference Server는 vLLM 백엔드와 결합되어 여러 대규모 언어 모델(LLM)을 배포하기 위한 강력한 프레임워크를 제공합니다. 사용자 애플리케이션은 REST API 또는 gRPC를 통해 추론 서비스와 상호 작용하며, 이는 NGINX와 Network Load Balancer(NLB)에 의해 관리되어 수신 요청을 Triton K8s Service로 효율적으로 분배합니다. Triton K8s Service는 배포의 핵심으로, Triton Server가 추론 요청을 처리합니다. 이 배포에서는 4개의 GPU가 장착된 g5.24xlarge 인스턴스를 사용하여 Llama2-7b와 Mistral7b와 같은 여러 모델을 실행합니다. Horizontal Pod Autoscaler(HPA)는 사용자 정의 메트릭을 모니터링하고 수요에 따라 Triton 파드를 동적으로 스케일링하여 다양한 부하를 효율적으로 처리합니다. Prometheus와 Grafana는 메트릭을 수집하고 시각화하는 데 사용되어 성능에 대한 통찰력을 제공하고 자동 스케일링 결정을 지원합니다.
예상 결과
설명된 대로 모든 것을 배포하면 추론 요청에 대한 빠른 응답 시간을 기대할 수 있습니다. 아래는 Llama-2-7b-chat-hf와 Mistral-7B-Instruct-v0.2 모델로 triton-client.py 스크립트를 실행한 예제 출력입니다.
클릭하여 비교 결과 확장
| 실행 1: Llama2 | 실행 2: Mistral7b |
|---|---|
| python3 triton-client.py --model-name llama2 --input-prompts prompts.txt --results-file llama2_results.txt | python3 triton-client.py --model-name mistral7b --input-prompts prompts.txt --results-file mistral_results.txt |
prompts.txt에서 입력 로딩 중... | prompts.txt에서 입력 로딩 중... |
| Model llama2 - Request 11: 0.00 ms | Model mistral7b - Request 3: 0.00 ms |
| Model llama2 - Request 15: 0.02 ms | Model mistral7b - Request 14: 0.00 ms |
| Model llama2 - Request 3: 0.00 ms | Model mistral7b - Request 11: 0.00 ms |
| Model llama2 - Request 8: 0.01 ms | Model mistral7b - Request 15: 0.00 ms |
| Model llama2 - Request 0: 0.01 ms | Model mistral7b - Request 5: 0.00 ms |
| Model llama2 - Request 9: 0.01 ms | Model mistral7b - Request 0: 0.01 ms |
| Model llama2 - Request 14: 0.01 ms | Model mistral7b - Request 7: 0.01 ms |
| Model llama2 - Request 16: 0.00 ms | Model mistral7b - Request 13: 0.00 ms |
| Model llama2 - Request 19: 0.02 ms | Model mistral7b - Request 9: 0.00 ms |
| Model llama2 - Request 4: 0.02 ms | Model mistral7b - Request 16: 0.01 ms |
| Model llama2 - Request 10: 0.02 ms | Model mistral7b - Request 18: 0.01 ms |
| Model llama2 - Request 6: 0.01 ms | Model mistral7b - Request 4: 0.01 ms |
| Model llama2 - Request 1: 0.02 ms | Model mistral7b - Request 8: 0.01 ms |
| Model llama2 - Request 7: 0.02 ms | Model mistral7b - Request 1: 0.01 ms |
| Model llama2 - Request 18: 0.01 ms | Model mistral7b - Request 6: 0.00 ms |
| Model llama2 - Request 12: 0.01 ms | Model mistral7b - Request 12: 0.00 ms |
| Model llama2 - Request 2: 0.01 ms | Model mistral7b - Request 17: 0.00 ms |
| Model llama2 - Request 17: 0.02 ms | Model mistral7b - Request 2: 0.01 ms |
| Model llama2 - Request 13: 0.01 ms | Model mistral7b - Request 19: 0.01 ms |
| Model llama2 - Request 5: 0.02 ms | Model mistral7b - Request 10: 0.02 ms |
결과를 llama2_results.txt에 저장 중... | 결과를 mistral_results.txt에 저장 중... |
| ��모든 요청 총 시간: 0.00초 (0.18 밀리초) | 모든 요청 총 시간: 0.00초 (0.11 밀리초) |
| PASS: vLLM 예제 | PASS: vLLM 예제 |
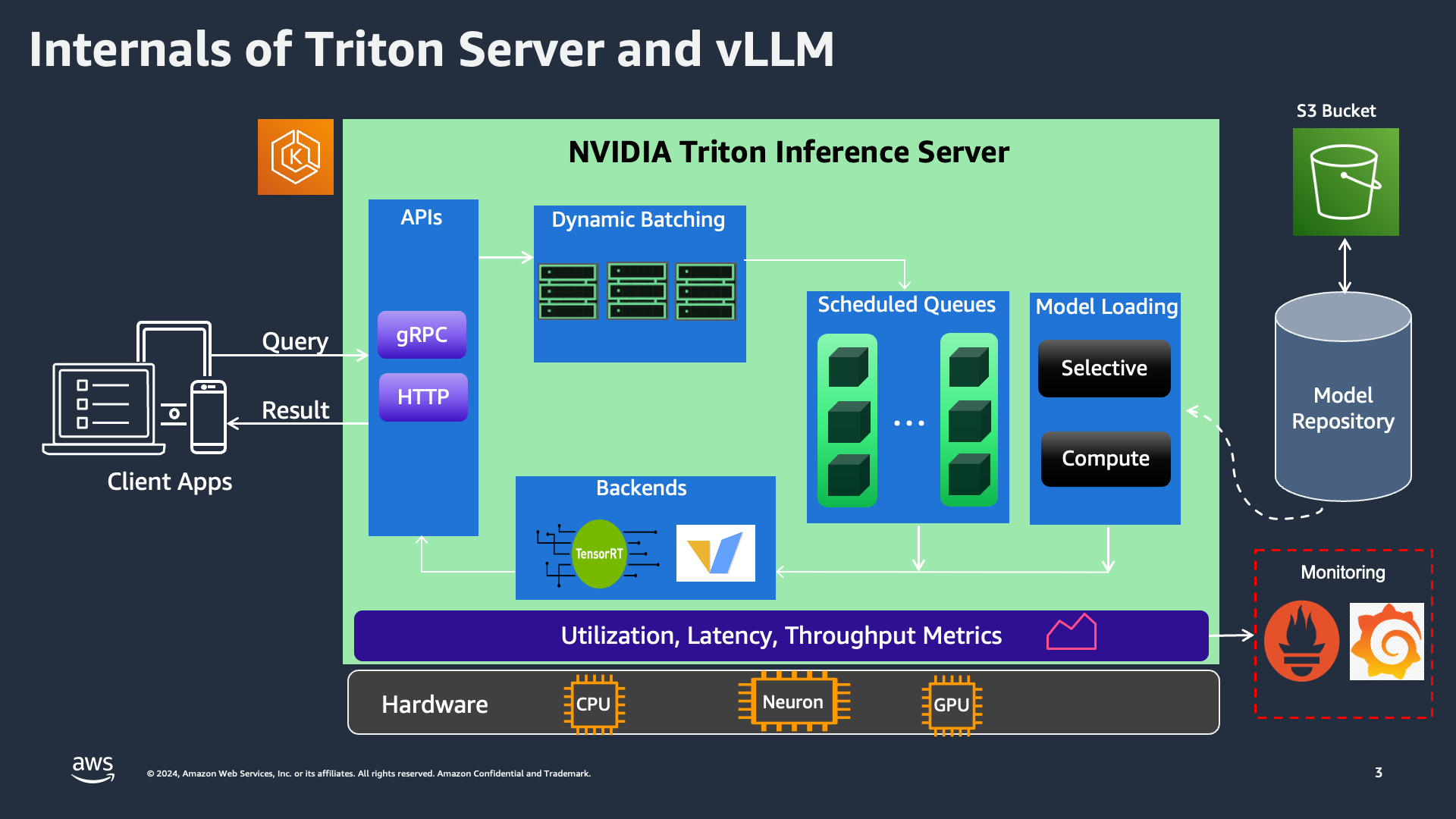
Triton Server 내부 구조 및 백엔드 통합
NVIDIA Triton Inference Server는 다양한 모델 유형과 배포 시나리오에서 고성능 추론을 위해 설계되었습니다. Triton의 핵심 강점은 다양한 백엔드 지원에 있으며, 이를 통해 다양한 유형의 모델과 워크로드를 효과적으로 처리할 수 있는 유연성과 성능을 제공합니다.
요청이 Triton K8s Service에 도달하면 Triton Server에서 처리됩니다. 서버는 동적 배칭을 지원하여 여러 추론 요청을 그룹화하여 처리를 최적화합니다. 이는 높은 처리량 요구 사항이 있는 시나리오에서 특히 유용하며, 지연 시간을 줄이고 전체 성능을 향상시키는 데 도움이 됩니다.
그런 다음 요청은 예약된 큐에 의해 관리되어 각 모델의 추론 요청이 순서대로 처리됩니다. Triton Server는 선택적 및 계산 모델 로딩을 지원하므로 현재 워크로드와 리소스 가용성에 따라 동적으로 모델을 로드할 수 있습니다. 이 기능은 다중 모델 배포에서 리소스를 효율적으로 관리하는 데 중요합니다.
Triton의 추론 기능의 핵심은 TensorRT-LLM 및 vLLM을 포함한 다양한 백엔드입니다:
TensorRT-LLM: TensorRT-LLM 백엔드는 NVIDIA GPU에서 대규모 언어 모델(LLM) 추론을 최적화합니다. TensorRT의 고성능 기능을 활용하여 추론을 가속화하고 낮은 지연 시간과 높은 처리량 성능을 제공합니다. TensorRT는 집중적인 계산 리소스가 필요한 딥러닝 모델에 특히 적합하여 실시간 AI 애플리케이션에 이상적입니다.
vLLM: vLLM 백엔드는 다양한 LLM 워크로드를 처리하도록 특별히 설계되었습니다. 대규모 모델에 맞춤화된 효율적인 메모리 관리와 실행 파이프라인을 제공합니다. 이 백엔드는 메모리 리소스가 최적으로 사용되도록 보장하여 메모리 병목 현상 없이 매우 큰 모델을 배포할 수 있게 합니다. vLLM은 여러 대규모 모델을 동시에 서빙해야 하는 애플리케이션에 중요하며, 강력하고 확장 가능한 솔루션을 제공합니다.
Mistralai/Mistral-7B-Instruct-v0.2
Mistralai/Mistral-7B-Instruct-v0.2는 고품질의 교육적 응답을 제공하도록 설계된 최첨단 대규모 언어 모델입니다. 다양한 데이터셋으로 훈련되어 다양한 주제에 대해 인간과 같은 텍스트를 이해하고 생성하는 데 뛰어납니다. 이 모델의 기능은 자세한 설명, 복잡한 쿼리, 자연어 이해가 필요한 애플리케이션에 적합합니다.
Meta-llama/Llama-2-7b-chat-hf
Meta-llama/Llama-2-7b-chat-hf는 Meta에서 개발한 고급 대화형 AI 모델입니다. 채팅 애플리케이션에 최적화되어 일관되고 문맥적으로 관련성 있는 응답을 제공합니다. 광범위한 대화 데이터셋으로 강력하게 훈련되어 이 모델은 참여적이고 동적인 대화를 유지하는 데 뛰어나며, 고객 서비스 봇, 대화형 에이전트 및 기타 채팅 기반 애플리케이션에 이상적입니다.
솔루션 배포
Amazon EKS에서 mistralai/Mistral-7B-Instruct-v0.2와 meta-llama/Llama-2-7b-chat-hf를 배포하기 위해 필요한 사전 요구 사항을 다루고 단계별로 배포 과정을 안내합니다. 이 과정에는 인프라 설정, NVIDIA Triton Inference Server 배포, 추론을 위해 Triton 서버에 gRPC 요청을 보내는 Triton 클라이언트 Python 애플리케이션 생성이 포함됩니다.
중요: 여러 GPU가 장착된 g5.24xlarge 인스턴스에 배포하면 비용이 많이 들 수 있습니다. 예상치 못한 비용을 피하기 위해 사용량을 신중하게 모니터링하고 관리하�세요. 지출을 추적하기 위해 예산 알림과 사용 제한을 설정하는 것을 고려하세요.
사전 요구 사항
👈vLLM 백엔드가 포함된 NVIDIA Triton Server
이 블루프린트는 Triton helm chart를 사용하여 Amazon EKS에 Triton 서버를 설치하고 구성합니다. 배포는 블루프린트의 다음 Terraform 코드를 사용하여 구성됩니다.
클릭하여 배포 코드 확장
module "triton_server_vllm" {
depends_on = [module.eks_blueprints_addons.kube_prometheus_stack]
source = "aws-ia/eks-data-addons/aws"
version = "~> 1.32.0" # 최신/원하는 버전으로 업데이트하세요
oidc_provider_arn = module.eks.oidc_provider_arn
enable_nvidia_triton_server = false
nvidia_triton_server_helm_config = {
version = "1.0.0"
timeout = 120
wait = false
namespace = kubernetes_namespace_v1.triton.metadata[0].name
values = [
<<-EOT
replicaCount: 1
image:
repository: nvcr.io/nvidia/tritonserver
tag: "24.06-vllm-python-py3"
serviceAccount:
create: false
name: ${kubernetes_service_account_v1.triton.metadata[0].name}
modelRepositoryPath: s3://${module.s3_bucket.s3_bucket_id}/model_repository
environment:
- name: model_name
value: ${local.default_model_name}
- name: "LD_PRELOAD"
value: ""
- name: "TRANSFORMERS_CACHE"
value: "/home/triton-server/.cache"
- name: "shm-size"
value: "5g"
- name: "NCCL_IGNORE_DISABLED_P2P"
value: "1"
- name: tensor_parallel_size
value: "1"
- name: gpu_memory_utilization
value: "0.9"
- name: dtype
value: "auto"
secretEnvironment:
- name: "HUGGING_FACE_TOKEN"
secretName: ${kubernetes_secret_v1.huggingface_token.metadata[0].name}
key: "HF_TOKEN"
resources:
limits:
cpu: 6
memory: 25Gi
nvidia.com/gpu: 4
requests:
cpu: 6
memory: 25Gi
nvidia.com/gpu: 4
nodeSelector:
NodeGroupType: g5-gpu-karpenter
type: karpenter
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
EOT
]
}
}
참고: Triton 서버에 사용되는 컨테이너 이미지는 nvcr.io/nvidia/tritonserver:24.02-vllm-python-py3이며 vLLM 백엔드가 활성화되어 있습니다. NGC Catalog에서 적절한 태그를 선택할 수 있습니다.
모델 저장소: Triton Inference Server는 서버 시작 시 지정된 하나 이상의 모델 저장소에서 모델을 서빙합니다. Triton은 로컬에서 접근 가능한 파일 경로와 Amazon S3와 같은 클라우드 스토리지 위치에서 모델에 접근할 수 있습니다.
모델 저장소를 구성하는 디렉토리와 파일은 필수 레이아웃을 따라야 합니다. 저장소 레이아웃은 다음과 같이 구성되어야 합니다:
클릭하여 모델 디렉토리 계층 구조 확장
<model-repository-path>/
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
-------------
예:
-------------
model-repository/
mistral-7b/
config.pbtxt
1/
model.py
llama-2/
config.pbtxt
1/
model.py
vLLM 활성화된 Triton 모델의 경우 model_repository는 ai/inference/vllm-nvidia-triton-server-gpu/model_repository 위치에서 찾을 수 있습니다. 배포 중에 블루프린트는 S3 버킷을 생성하고 로컬 model_repository 내용을 S3 버킷에 동기화합니다.
model.py: 이 스크립트는 vLLM 라이브러리를 Triton 백엔드 프레임워크로 사용하고 모델 구성을 로드하고 vLLM 엔진을 구성하여 TritonPythonModel 클래스를 초기화합니다. huggingface_hub 라이브러리의 로그인 함수는 모델 접근을 위해 hugging face 저장소에 대한 접근을 설정하는 데 사용됩니다. 그런 다음 수신된 요청을 비동기적으로 처리하기 위해 asyncio 이벤트 루프를 시작합니다. 스크립트에는 추론 요청을 처리하고 vLLM 백엔드에 요청을 발행하고 응답을 반환하는 여러 함수가 있습니다.
config.pbtxt: 다음과 같은 파라미터를 지정하는 모델 구성 파일입니다
- Name - 모델의 이름은 모델을 포함하는 모델 저장소 디렉토리의
name과 일치해야 합니다. - max_batch_size -
max_batch_size값은 Triton이 활용할 수 있는 배칭 유형에 대해 모델이 지원하는 최대 배치 크기를 나타냅니다 - Inputs and Outputs - 각 모델 입력 및 출력은 이름, 데이터 유형, 모양을 지정해야 합니다. 입력 모양은 모델과 추론 요청에서 Triton이 예상하는 입력 텐서의 모양을 나타냅니다. 출력 모양은 모델이 생성하고 추론 요청에 대한 응답으로 Triton이 반환하는 출력 텐서의 모양을 나타냅니다. 입력 및 출력 모양은
max_batch_size와input dims또는output dims로 지정된 차원의 조합으로 지정됩니다.
배포 확인
Triton Inference Server가 성공적으로 배포되었는지 확�인하려면 다음 명령을 실행하세요:
kubectl get all -n triton-vllm
아래 출력은 두 모델을 호스팅하는 Triton 서버를 실행하는 하나의 파드가 있음을 보여줍니다. 모델과 상호 작용하기 위한 하나의 서비스와 Triton 서버를 위한 하나의 ReplicaSet이 있습니다. 배포는 사용자 정의 메트릭과 HPA 객체를 기반으로 수평 스케일링됩니다.
NAME READY STATUS RESTARTS AGE
pod/nvidia-triton-server-triton-inference-server-c49bd559d-szlpf 1/1 Running 0 13m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/nvidia-triton-server-triton-inference-server ClusterIP 172.20.193.97 <none> 8000/TCP,8001/TCP,8002/TCP 13m
service/nvidia-triton-server-triton-inference-server-metrics ClusterIP 172.20.5.247 <none> 8080/TCP 13m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nvidia-triton-server-triton-inference-server 1/1 1 1 13m
NAME DESIRED CURRENT READY AGE
replicaset.apps/nvidia-triton-server-triton-inference-server-c49bd559d 1 1 1 13m
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/nvidia-triton-server-triton-inference-server Deployment/nvidia-triton-server-triton-inference-server <unknown>/80%, <unknown>/80% 1 5 1 13m
이 출력은 Triton 서버 파드가 실행 중이고 서비스가 올바르게 설정되었으며 배포가 예상대로 작동하고 있음을 나타냅니다. Horizontal Pod Autoscaler도 활성화되어 지정된 메트릭에 따라 파드 수가 스케일링됩니다.
Llama-2-7b Chat 및 Mistral-7b Chat 모델 테스트
이제 Llama-2-7b chat과 Mistral-7b chat 모델을 테스트할 차례입니다. 동일한 프롬프트로 다음 명령을 실행하여 두 모델이 생성한 출력을 확인합니다.
먼저 kubectl을 사용하여 Triton-inference-server 서비스로 포트 포워드를 실행합니다:
kubectl -n triton-vllm port-forward svc/nvidia-triton-server-triton-inference-server 8001:8001
다음으로 동일한 프롬프트를 사용하여 각 모델에 대해 Triton 클라이언트를 실행합니다:
cd ai-on-eks/blueprints/inference/vllm-nvidia-triton-server-gpu/triton-client
python3 -m venv .venv
source .venv/bin/activate
pip install tritonclient[all]
python3 triton-client.py --model-name mistral7b --input-prompts prompts.txt --results-file mistral_results.txt
다음과 같은 출력이 표시됩니다:
python3 triton-client.py --model-name mistral7b --input-prompts prompts.txt --results-file mistral_results.txt
`prompts.txt`에서 입력 로딩 중...
Model mistral7b - Request 3: 0.00 ms
Model mistral7b - Request 14: 0.00 ms
Model mistral7b - Request 11: 0.00 ms
Model mistral7b - Request 15: 0.00 ms
Model mistral7b - Request 5: 0.00 ms
Model mistral7b - Request 0: 0.01 ms
Model mistral7b - Request 7: 0.01 ms
Model mistral7b - Request 13: 0.00 ms
Model mistral7b - Request 9: 0.00 ms
Model mistral7b - Request 16: 0.01 ms
Model mistral7b - Request 18: 0.01 ms
Model mistral7b - Request 4: 0.01 ms
Model mistral7b - Request 8: 0.01 ms
Model mistral7b - Request 1: 0.01 ms
Model mistral7b - Request 6: 0.00 ms
Model mistral7b - Request 12: 0.00 ms
Model mistral7b - Request 17: 0.00 ms
Model mistral7b - Request 2: 0.01 ms
Model mistral7b - Request 19: 0.01 ms
Model mistral7b - Request 10: 0.02 ms
결과를 `mistral_results.txt`에 저장 중...
모든 요청 총 시간: 0.00초 (0.11 밀리초)
PASS: vLLM 예제
mistral_results.txt의 출력은 아래와 같아야 합니다:
클릭하여 Mistral 결과 부분 출력 확장
<s>[INST]<<SYS>>
100문장 이하의 짧은 답변을 유지하세요.
<</SYS>>
전통적인 머신러닝 모델과 초대형 언어 모델(vLLM)의 주요 차이점은 무엇인가요?
[/INST] 전통적인 머신러닝 모델(MLM)은 특정 데이터셋과 특성으로 훈련되어 해당 데이터를 기반으로 패턴을 학습하고 예측합니다. 훈련을 위해 레이블이 지정된 데이터가 필요하며 훈련 데이터의 크기와 다양성에 의해 제한됩니다. MLM은 이미지 인식이나 음성 인식과 같은 구조화된 문제를 해결하는 데 효과적일 수 있습니다.
반면 초대형 언어 모델(vLLM)은 딥러닝 기술을 사용하여 방대한 양의 텍스트 데이터로 훈련됩니다. 수신하는 입력을 기반으로 인간과 같은 텍스트를 생성하는 방법을 학습합니다. vLLM은 MLM보다 더 문맥을 인식하고 미묘한 방식으로 텍스트를 이해하고 생성할 수 있습니다. 텍스트 요약, 번역, 질문 응답과 같은 더 넓은 범위의 작업도 수행할 수 있습니다. 그러나 vLLM은 계산 비용이 더 많이 들고 훈련에 대량의 데이터와 전력이 필요합니다. 적절하게 관리되지 않으면 부정확하거나 편향된 응답을 생성할 가능성도 있습니다.
=========
이제 동일한 프롬프트로 Llama-2-7b-chat 모델에서 추론을 실행하고 llama2_results.txt라는 새 파일에서 출력을 확인해 보세요.
python3 triton-client.py --model-name llama2 --input-prompts prompts.txt --results-file llama2_results.txt
출력은 다음과 같아야 합니다:
python3 triton-client.py --model-name llama2 --input-prompts prompts.txt --results-file llama2_results.txt
`prompts.txt`에서 입력 로딩 중...
Model llama2 - Request 11: 0.00 ms
Model llama2 - Request 15: 0.02 ms
Model llama2 - Request 3: 0.00 ms
Model llama2 - Request 8: 0.03 ms
Model llama2 - Request 5: 0.02 ms
Model llama2 - Request 0: 0.00 ms
Model llama2 - Request 14: 0.00 ms
Model llama2 - Request 16: 0.01 ms
Model llama2 - Request 19: 0.02 ms
Model llama2 - Request 4: 0.01 ms
Model llama2 - Request 1: 0.01 ms
Model llama2 - Request 10: 0.01 ms
Model llama2 - Request 9: 0.01 ms
Model llama2 - Request 7: 0.01 ms
Model llama2 - Request 18: 0.01 ms
Model llama2 - Request 12: 0.00 ms
Model llama2 - Request 2: 0.00 ms
Model llama2 - Request 6: 0.00 ms
Model llama2 - Request 17: 0.01 ms
Model llama2 - Request 13: 0.01 ms
결과를 `llama2_results.txt`에 저장 중...
모든 요청 총 시간: 0.00초 (0.18 밀리초)
PASS: vLLM 예제
관측성
AWS CloudWatch와 Neuron Monitor를 사용한 관측성
이 블루프린트는 관리형 애드온으로 CloudWatch Observability Agent를 배포하여 컨테이너화된 워크로드에 대한 포괄적인 모니터링을 제공합니다. CPU 및 메모리 활용률과 같은 주요 성능 메트릭을 추적하기 위한 컨테이너 인사이트가 포함됩니다. 또한 블루프린트는 NVIDIA의 DCGM 플러그인을 사용한 GPU 메트릭을 통합하며, 이는 고성능 GPU 워크로드를 모니터링하는 데 필수적입니다. AWS Inferentia 또는 Trainium에서 실행되는 머신러닝 모델의 경우 Neuron Monitor 플러그인이 추가되어 Neuron 특정 메트릭을 캡처하고 보고합니다.
컨테이너 인사이트, GPU 성능, Neuron 메트릭을 포함한 모든 메트릭은 Amazon CloudWatch로 전송되며, 여기서 실시간으로 모니터링하고 분석할 수 있습니다. 배포가 완료되면 CloudWatch 콘솔에서 직접 이러한 메트릭에 접근할 수 있어 워크로드를 효과적으로 관리하고 최적화할 수 있습니다.
CloudWatch EKS 애드온 배포 외에도 모니터링 및 관측성을 위한 Prometheus 서버와 Grafana 배포를 제공하는 Kube Prometheus 스택도 배포했습니다.
먼저 Kube Prometheus 스택에서 배포한 서비스를 확인하겠습니다:
kubectl get svc -n kube-prometheus-stack
다음과 유사한 출력이 표시됩니다:
kubectl get svc -n kube-prometheus-stack
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-prometheus-stack-grafana ClusterIP 172.20.252.10 <none> 80/TCP 11d
kube-prometheus-stack-kube-state-metrics ClusterIP 172.20.34.181 <none> 8080/TCP 11d
kube-prometheus-stack-operator ClusterIP 172.20.186.93 <none> 443/TCP 11d
kube-prometheus-stack-prometheus ClusterIP 172.20.147.64 <none> 9090/TCP,8080/TCP 11d
kube-prometheus-stack-prometheus-node-exporter ClusterIP 172.20.171.165 <none> 9100/TCP 11d
prometheus-operated ClusterIP None <none> 9090/TCP 11d
NVIDIA Triton 서버 메트릭을 노출하기 위해 포트 8080에서 메트릭 서비스(nvidia-triton-server-triton-inference-server-metrics)를 배포했습니다. 다음을 실행하여 확인하세요
kubectl get svc -n triton-vllm
출력��은 다음과 같아야 합니다:
kubectl get svc -n triton-vllm
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nvidia-triton-server-triton-inference-server ClusterIP 172.20.193.97 <none> 8000/TCP,8001/TCP,8002/TCP 34m
nvidia-triton-server-triton-inference-server-metrics ClusterIP 172.20.5.247 <none> 8080/TCP 34m
이는 NVIDIA Triton 서버 메트릭이 Prometheus 서버에 의해 스크랩되고 있음을 확인합니다. Grafana 대시보드를 사용하여 이러한 메트릭을 시각화할 수 있습니다.
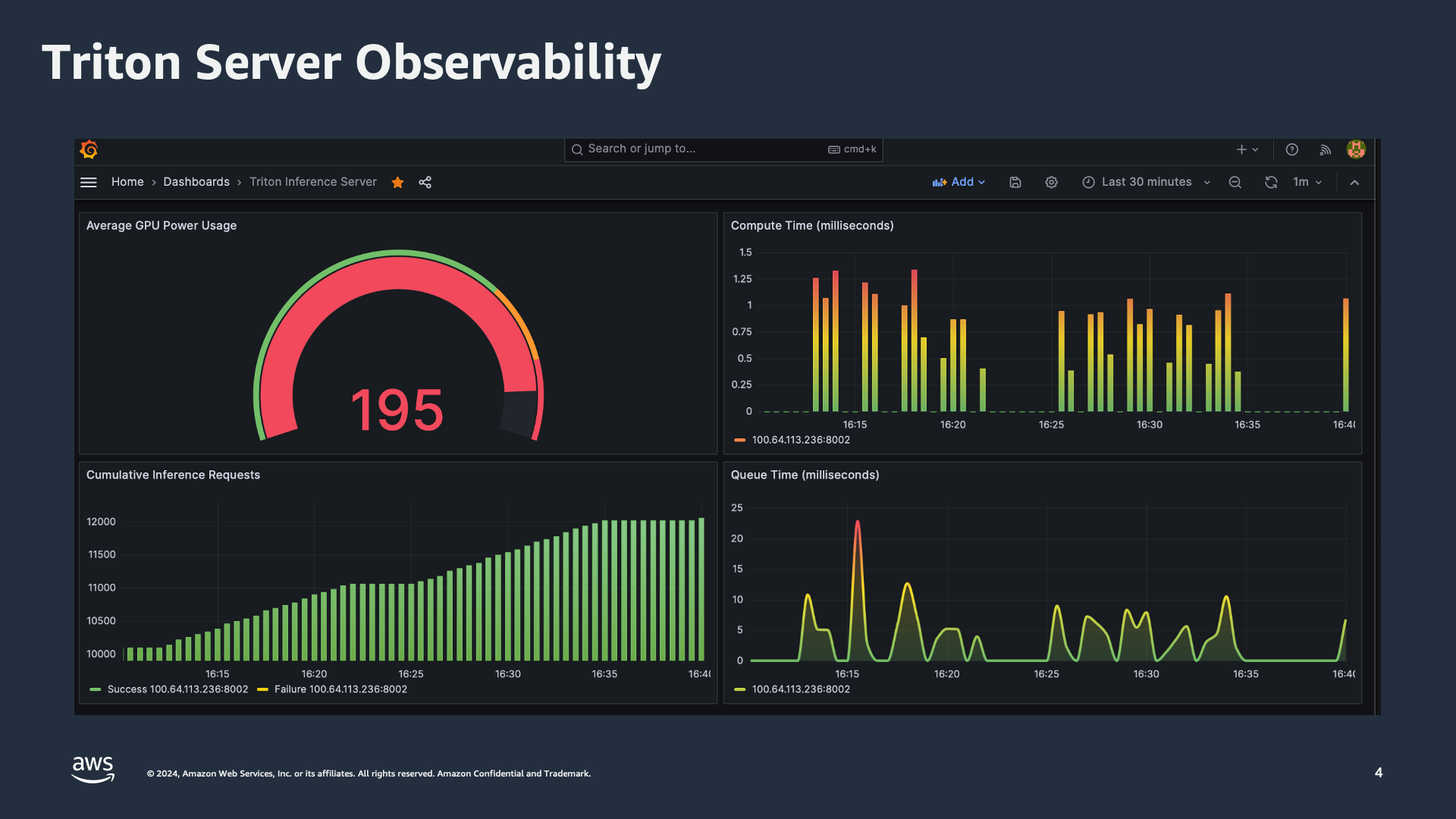
아래 Grafana 대시보드에서 여러 중요한 메트릭을 볼 수 있습니다:
- Average GPU Power Usage: 이 게이지는 GPU의 현재 전력 사용량을 보여주며, 추론 작업의 효율성과 성능을 모니터링하는 데 중요합니다.
- Compute Time (밀리초): 이 막대 그래프는 추론 요청을 계산하는 데 걸리는 시간을 표시하여 지연 문제를 식별하는 데 도움이 됩니다.
- Cumulative Inference Requests: 이 그래프는 시간 경과에 따라 처리된 총 추론 요청 수를 보여주어 워크로드와 성능 추세에 대한 통찰력을 제공합니다.
- Queue Time (밀리초): 이 라인 그래프는 요청이 처리되기 전에 큐에서 보내는 시간을 나타내며, 시스템의 잠재적 병목 현상을 강조합니다.
이러한 메트릭을 모니터링하기 위한 새 Grafana 대시보드를 만들려면 아래 단계를 따르세요:
- Grafana 서비스 포트 포워딩:
kubectl port-forward svc/kube-prometheus-stack-grafana 8080:80 -n kube-prometheus-stack
- Grafana 관리자 사용자
admin
- Terraform 출력에서 시크릿 이름 가져오기
terraform output grafana_secret_name
- 관리자 사용자 비밀번호 가져오기
aws secretsmanager get-secret-value --secret-id <grafana_secret_name_output> --region $AWS_REGION --query "SecretString" --output text
Grafana에 로그인:
- 웹 브라우저를 열고 http://localhost:8080으로 이동합니다.
- 사용자 이름
admin과 AWS Secrets Manager에서 검색한 비밀번호로 로그인합니다.
오픈소스 Grafana 대시보드 가져오기:
- 로그인 후 왼쪽 사이드바의 "+" 아이콘을 클릭하고 "Import"를 선택합니다.
- 다음 URL을 입력하여 대시보드 JSON을 가져옵니다: Triton Server Grafana Dashboard
- 안내에 따라 가져오기 프로세스를 완료합니다.
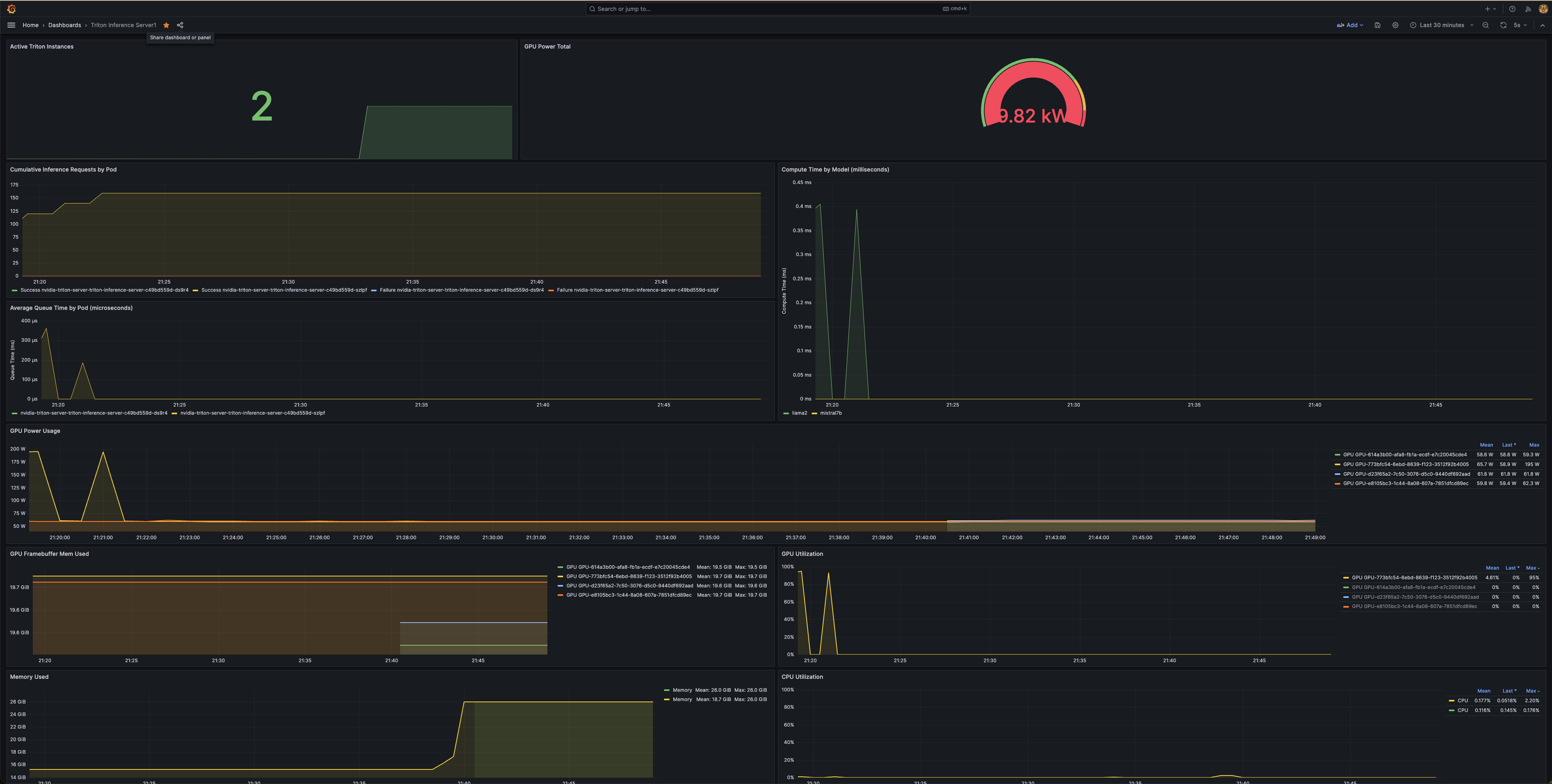
이제 새 Grafana 대시보드에 표시된 메트릭을 볼 수 있어 NVIDIA Triton Inference Server 배포의 성능과 상태를 모니터링할 수 있습니다.
결론
Amazon EKS에서 NVIDIA Triton Inference Server와 vLLM 백엔드를 사용하여 여러 대규모 언어 모델을 배포하고 관리하면 현대 AI 애플리케이션을 위한 강력하고 확장 가능한 솔루션을 제공합니다. 이 블루프린트를 따르면 필요한 인프라를 설정하고, Triton 서버를 배포하고, Kube Prometheus 스택과 Grafana를 사용하여 강력한 관측성을 구성했습니다.
정리
마지막으로 리소스가 더 이상 필요하지 않을 때 정리하고 프로비저닝을 해제하는 방법을 안내합니다.
EKS 클러스터 정리:
이 스크립트는 -target 옵션을 사용하여 모든 리소스가 올바른 순서로 삭제되도록 환경을 정리합니다.
export AWS_DEAFULT_REGION="DEPLOYED_EKS_CLUSTER_REGION>"
cd ai-on-eks/infra/nvidia-triton-server/ && chmod +x cleanup.sh
./cleanup.sh