Amazon EKS의 NVIDIA NIM Operator
NVIDIA NIM이란?
NVIDIA NIM (NVIDIA Inference Microservices)은 자체 환경에서 대규모 언어 모델(LLM) 및 기타 AI 모델을 더 쉽게 배포하고 호스팅할 수 있게 해주는 컨테이너화된 마이크로서비스 집합입니다. NIM은 챗봇 및 AI 어시스턴트와 같은 애플리케이션을 구축하기 위한 표준 API(OpenAI 또는 기타 AI 서비스와 유사)를 개발자에게 제공하면서, 고성능 추론(Inference)을 위해 NVIDIA의 GPU 가속을 활용합니다. 본질적으로 NIM은 모델 런타임 및 최적화의 복잡성을 �추상화하여, 내부적으로 최적화된 백엔드(예: TensorRT-LLM, FasterTransformer 등)를 통해 빠른 추론 경로를 제공합니다.
Kubernetes용 NVIDIA NIM Operator
NVIDIA NIM Operator는 Kubernetes 클러스터에서 NVIDIA NIM 마이크로서비스의 배포, 확장 및 관리를 자동화하는 Kubernetes 오퍼레이터입니다.
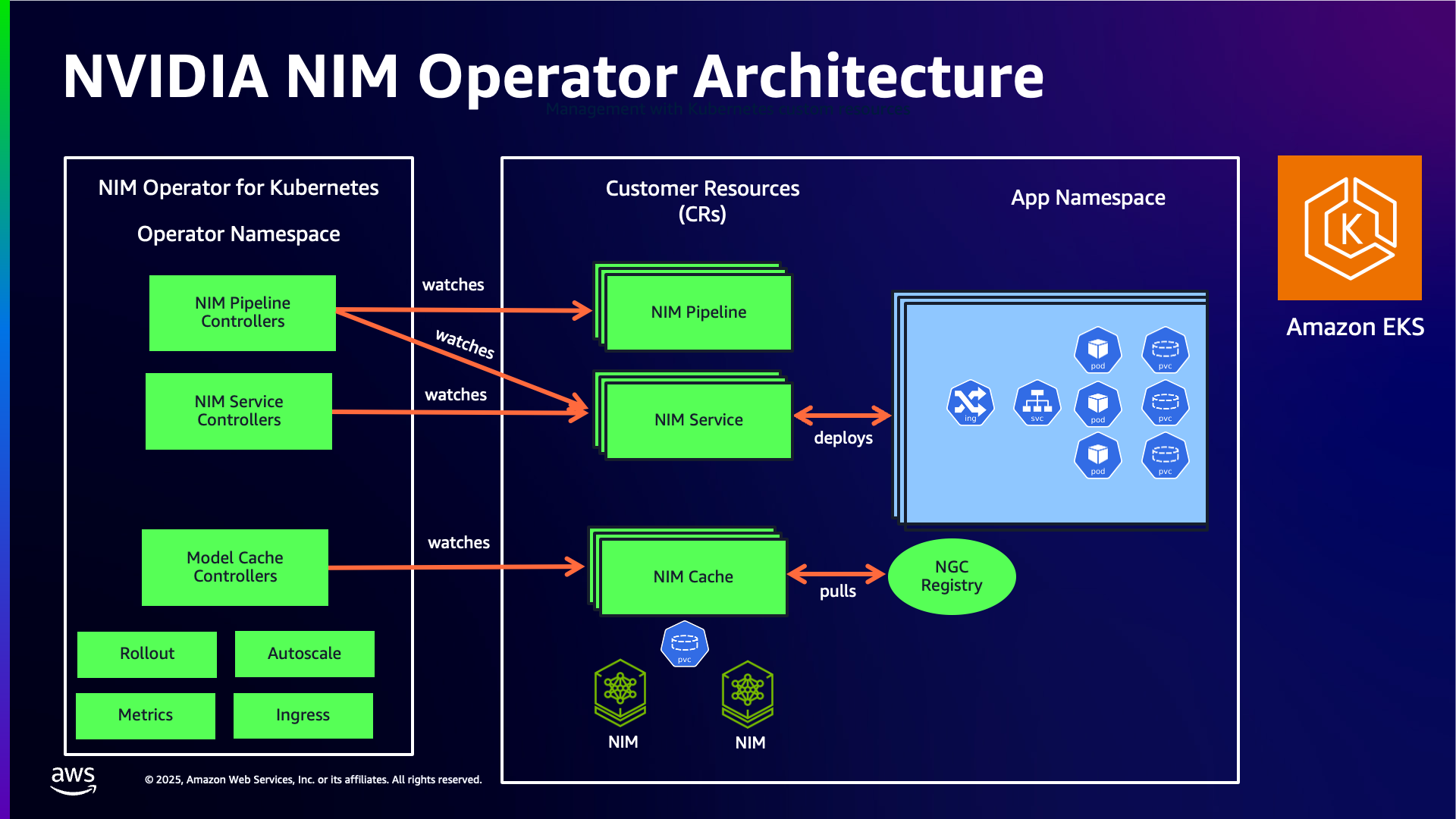
컨테이너를 수동으로 가져오거나, GPU 노드를 프로비저닝하거나, 모든 모델에 대해 YAML을 작성하는 대신, NIM Operator는 세 가지 주요 Custom Resource Definition(CRD)을 도입합니다:
이러한 CRD를 통해 네이티브 Kubernetes 구문을 사용하여 모델 배포를 선언적으로 정의할 수 있습니다.
Operator가 처리하는 작업:
- NVIDIA GPU Cloud (NGC)에서 모델 이미지 가져오기
- 모델 가중치 및 최적화된 런타임 프로파일 캐싱
- GPU 할당을 포함한 모델 서빙 Pod 실행
- Kubernetes Services를 통한 추론 엔드포인트 노출
- 오토스케일링 통합 (예: HPA + Karpenter)
- NIMPipeline을 사용하여 여러 모델을 추론 파이프라인으로 체이닝
NIMCache - 더 빠른 로드 시간을 위한 모델 캐싱
NIMCache (nimcaches.apps.nvidia.com)는 모델의 가중치, 토크나이저 및 런타임 최적화 엔진 파일(예: TensorRT-LLM 프로파일)을 공유 영구 볼륨에 미리 다운로드하고 저장하는 커스텀 리소스입니다.
이를 통해 보장되는 사항:
- 더 빠른 콜드 스타트 시간: NGC에서 반복 다운로드 없음
- 노드와 레플리카 간 스토리지 재사용
- 중앙 집중식 공유 모델 저장소 (일반적으로 EKS에서 EFS 또는 FSx for Lustre 사용)
모델 프로파일은 특정 GPU(예: A10G, L4) 및 정밀도(예: FP16)에 최적화됩니다. NIMCache가 생성되면 Operator가 사용 가능한 모델 프로파일을 검색하고 클러스터에 가장 적합한 프로파일을 선택합니다.
팁: 프로덕션 환경에서는
NIMCache사용을 적극 권장합니다. 특히 여러 레플리카를 실행하거나 모델을 자주 재시작하는 �경우에 유용합니다.
NIMService - 모델 서버 배포 및 관리
NIMService (nimservices.apps.nvidia.com)는 클러스터에서 실행 중인 NIM 모델 서버 인스턴스를 나타냅니다. 컨테이너 이미지, GPU 리소스, 레플리카 수 및 선택적으로 NIMCache 이름을 지정합니다.
주요 이점:
- Kubernetes YAML을 사용한 선언적 모델 배포
- GPU 노드에 대한 자동 노드 스케줄링
NIMCache를 사용한 공유 캐시 지원- HPA 또는 외부 트리거를 통한 오토스케일링
- API 노출을 위한 ClusterIP 또는 Ingress 지원
예를 들어, Meta Llama 3.1 8B Instruct 모델을 배포하려면 다음이 필요합니다:
- 모델을 저장할
NIMCache(선택 사항이지만 권장) - 캐시된 모델을 가리키고 GPU를 할당하는
NIMService
NIMCache를 사용하지 않으면 Pod가 시작될 때마다 모델이 다운로드되어 시작 지연 시간이 증가할 수 있습니다.
NIMPipeline
NIMPipeline은 여러 NIMService 리소스를 순서가 있는 추론 파이프라인으로 그룹화할 수 있는 또 다른 CRD입니다. 다음과 같은 다중 모델 워크플로우에 유용합니다:
- Retrieval-Augmented Generation (RAG)
- 임베딩 + LLM 체이닝
- 전처리 + 분류 파이프라인
이 튜토리얼에서는
NIMCache와NIMService를 사용한 단일 모델 배포에 초점을 맞춥니다.
Amazon EKS에서의 배포 패턴 개요
이 배포 블루프린트는 NVIDIA NIM Operator를 사용하여 Amazon EKS에서 다중 GPU 지원과 빠른 시작 시간을 위한 최적화된 모델 캐싱을 통해 Meta Llama 3.1 8B Instruct 모델을 실행하는 방법을 보여줍니다.
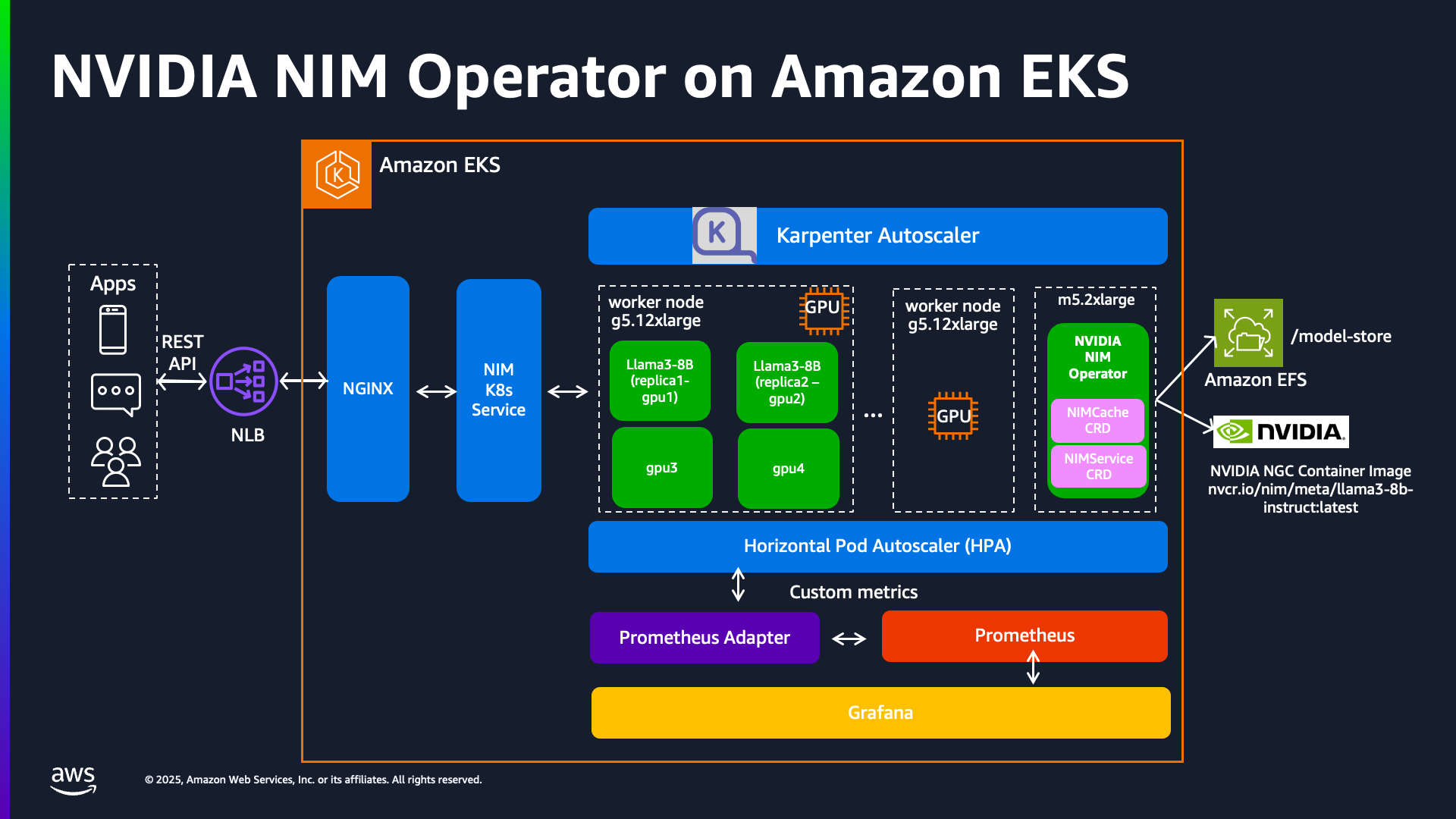
모델은 다음을 사용하여 서빙됩니다:
- G5 인스턴스 (g5.12xlarge): 4개의 NVIDIA A10G GPU가 장착된 인스턴스
- Tensor Parallelism (TP):
2로 설정되어 모델이 2개의 GPU에서 병렬로 실행됨 - 영구 공유 캐시: 이전에 생성된 엔진 파일을 재사용하여 모델 시작 속도를 높이기 위해 Amazon EFS로 지원
이러한 구성 요소를 결합하여 모델은 다음을 지원하는 확장 가능한 Kubernetes 워크로드로 배포됩니다:
- Karpenter를 통한 효율적인 GPU 스케줄링
NIMCache를 사용한 빠른 모델 로드NIMService를 통한 확장 가능한 서빙 엔드포인트
참고: 성능 및 비용 요구 사항에 따라
tensorParallelism설정을 수정하거나 다른 인스턴스 유형(예: L4 GPU가 있는 G6)을 선택할 수 있습니다.
참고: NVIDIA NIM을 구현하기 전에 NVIDIA AI Enterprise의 일부이므로 프로덕션 사용 시 잠재적인 비용 및 라이선스가 발생할 수 있음을 인지하십시오.
평가를 위해 NVIDIA는 90일간 NVIDIA AI Enterprise를 사용해 볼 수 있는 무료 평가 라이선스를 제공하며, 회사 이메일로 등록할 수 있습니다.
솔루션 배포
이 튜토리얼에서는 Terraform을 사용하여 다음을 포함한 전체 AWS 인프라를 프로비저닝합니다:
- 퍼블릭 및 프라이빗 서브넷이 있는 Amazon VPC
- Amazon EKS 클러스터
- Karpenter를 사용한 GPU 노드풀
- 다음과 같은 애드온:
- NVIDIA device plugin
- EFS CSI driver
- NVIDIA NIM Operator
데모로서 Meta Llama-3.1 8B Instruct 모델이 NIMService를 사용하여 배포되며, 선택적으로 콜드 스타트 성능 개선을 위해 NIMCache로 지원됩니다.
사전 요구 사항
NVIDIA NIM을 시작하기 전에 다음을 확인하십시오:
NVIDIA NIM 계정 설정 세부 정보를 보려면 클릭하십시오
NVIDIA AI Enterprise 계정
- NVIDIA AI Enterprise 계정에 등록하십시오. 계정이 없으면 이 링크를 사용하여 평가판 계정에 가입할 수 있습니다.
NGC API 키
-
NVIDIA AI Enterprise 계정에 로그인합니다
-
NGC (NVIDIA GPU Cloud) 포털로 이동합니다
-
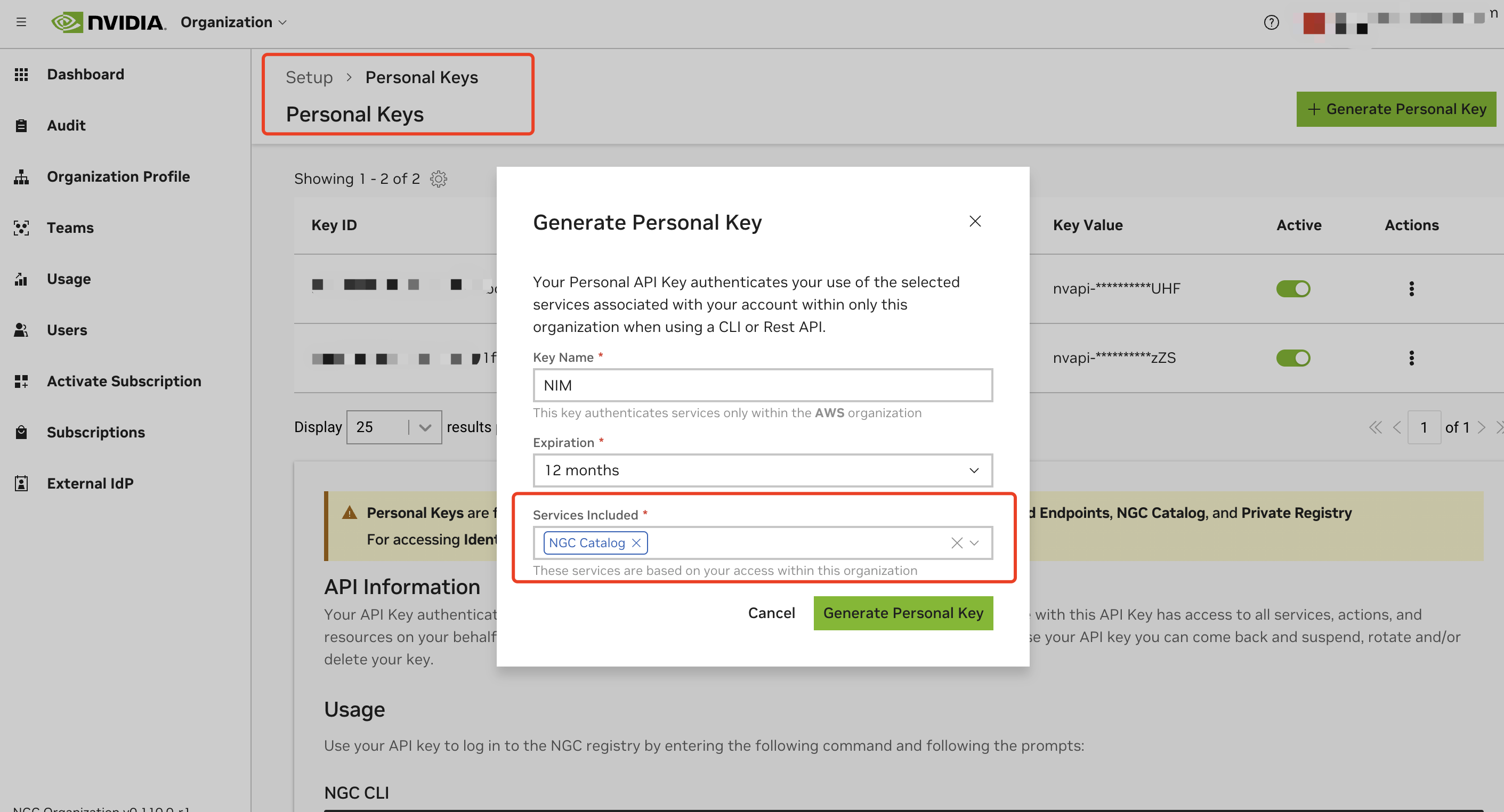
개인 API 키를 생성합니다:
- 계정 설정으로 이동하거나 직접 https://org.ngc.nvidia.com/setup/personal-keys로 이동합니다
- "Generate Personal Key"를 클릭합니다
- "Services Included" 드롭다운에서 최소한 "NGC Catalog"가 선택되어 있는지 확인합니다
- API 키를 복사하고 안전하게 저장합니다. 키는
nvapi-접두사가 있어야 합니다
NGC API 키 검증 및 이미지 풀 테스트
API 키가 유효하고 올바르게 작동하는지 확인하려면:
- NGC API 키를 환경 변수로 설정합니다:
export NGC_API_KEY=<your_api_key_here>
- NVIDIA Container Registry에 Docker 인증:
echo "$NGC_API_KEY" | docker login nvcr.io --username '$oauthtoken' --password-stdin
- NGC에서 이미지 풀 테스트:
docker pull nvcr.io/nim/meta/llama3-8b-instruct:latest
완료될 때까지 기다릴 필요 없이, API 키가 이미지를 가져오는 데 유효한지만 확인하면 됩니다.
이 튜토리얼을 실행하려면 다음이 필요합니다
배포
ai-on-eks 저장소를 클론합니다. 이 저장소에는 이 배포 패턴을 위한 Terraform 코드가 포함되어 있습니다:
git clone https://github.com/awslabs/ai-on-eks.git
NVIDIA NIM 배포 디렉토리로 이동하고 인프라를 배포하는 설치 스크립트를 실행합니다:
cd ai-on-eks/infra/nvidia-nim
./install.sh
이 배포는 약 ~20분이 소요됩니다.
설치가 완료되면 출력에서 configure_kubectl 명령을 찾을 수 있습니다. EKS 클러스터 액세스를 구성하려면 다음을 실행합니다
# EKS 인증을 위한 k8s 구성 파일 생성
aws eks --region us-west-2 update-kubeconfig --name nvidia-nim-eks
배포 확인 - 배포 세부 정보를 보려면 클릭하십시오
$ kubectl get all -n nim-operator
kubectl get all -n nim-operator
NAME READY STATUS RESTARTS AGE
pod/nim-operator-k8s-nim-operator-6fdffdf97f-56fxc 1/1 Running 0 26h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/k8s-nim-operator-metrics-service ClusterIP 172.20.148.6 <none> 8080/TCP 26h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nim-operator-k8s-nim-operator 1/1 1 1 26h
NAME DESIRED CURRENT READY AGE
replicaset.apps/nim-operator-k8s-nim-operator-6fdffdf97f 1 1 1 26h
$ kubectl get crds | grep nim
nimcaches.apps.nvidia.com 2025-03-27T17:39:00Z
nimpipelines.apps.nvidia.com 2025-03-27T17:39:00Z
nimservices.apps.nvidia.com 2025-03-27T17:39:01Z
$ kubectl get crds | grep nemo
nemocustomizers.apps.nvidia.com 2025-03-27T17:38:59Z
nemodatastores.apps.nvidia.com 2025-03-27T17:38:59Z
nemoentitystores.apps.nvidia.com 2025-03-27T17:38:59Z
nemoevaluators.apps.nvidia.com 2025-03-27T17:39:00Z
nemoguardrails.apps.nvidia.com 2025-03-27T17:39:00Z
Karpenter 오토스케일링 Nodepool 목록 보기
$ kubectl get nodepools
NAME NODECLASS NODES READY AGE
g5-gpu-karpenter g5-gpu-karpenter 1 True 47h
g6-gpu-karpenter g6-gpu-karpenter 0 True 7h56m
inferentia-inf2 inferentia-inf2 0 False 47h
trainium-trn1 trainium-trn1 0 False 47h
x86-cpu-karpenter x86-cpu-karpenter 0 True 47h
NIM Operator로 llama-3.1-8b-instruct 배포
1단계: 인증을 위한 Secret 생성
NVIDIA 컨테이너 레지스트리와 모델 아티팩트에 액세스하려면 NGC API 키를 제공해야 합니다. 이 스크립트는 두 개의 Kubernetes Secret을 생성�합니다: Docker 이미지 풀을 위한 ngc-secret과 모델 인증을 위한 ngc-api-secret.
cd blueprints/inference/gpu/nvidia-nim-operator-llama3-8b
NGC_API_KEY="your-real-ngc-key" ./deploy-nim-auth.sh
2단계: NIMCache CRD를 사용하여 EFS에 모델 캐시
NIMCache 커스텀 리소스는 모델을 가져오고 최적화된 엔진 프로파일을 EFS에 캐시합니다. 이렇게 하면 나중에 NIMService를 통해 모델을 실행할 때 시작 시간이 크게 단축됩니다.
cd blueprints/inference/gpu/nvidia-nim-operator-llama3-8b
kubectl apply -f nim-cache-llama3-8b-instruct.yaml
상태 확인:
kubectl get nimcaches.apps.nvidia.com -n nim-service
예상 출력:
NAME STATUS PVC AGE
meta-llama3-8b-instruct Ready meta-llama3-8b-instruct-pvc 21h
캐시된 모델 프로파일 표시:
kubectl get nimcaches.apps.nvidia.com -n nim-service \
meta-llama3-8b-instruct -o=jsonpath="{.status.profiles}" | jq .
샘플 출력:
[
{
"config": {
"feat_lora": "false",
"gpu": "A10G",
"llm_engine": "tensorrt_llm",
"precision": "fp16",
"profile": "throughput",
"tp": "2"
}
}
]
3단계: NIMService CRD를 사용하여 모델 배포
이제 캐시된 엔진 프로파일을 사용하여 모델 서비스를 실행합니다.
cd blueprints/inference/gpu/nvidia-nim-operator-llama3-8b
kubectl apply -f nim-service-llama3-8b-instruct.yaml
배포된 리소스 확인:
kubectl get all -n nim-service
예상 출력:
NAME READY STATUS RESTARTS AGE
pod/meta-llama3-8b-instruct-6cdf47d6f6-hlbnf 1/1 Running 0 6h35m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/meta-llama3-8b-instruct ClusterIP 172.20.85.8 <none> 8000/TCP 6h35m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/meta-llama3-8b-instruct 1/1 1 1 6h35m
NAME DESIRED CURRENT READY AGE
replicaset.apps/meta-llama3-8b-instruct-6cdf47d6f6 1 1 1 6h35m
모델 시작 타임라인
다음 샘플은 pod/meta-llama3-8b-instruct-6cdf47d6f6-hlbnf 로그에서 캡처되었습니다
| 단계 | 타��임스탬프 | 설명 |
|---|---|---|
| 시작 | ~20:00:50 | Pod 시작, NIM 컨테이너 로그 시작 |
| 프로파일 매칭 | 20:00:50.100 | 캐시된 프로파일 감지 및 선택 (tp=2) |
| 워크스페이스 준비 | 20:00:50.132 | 0.126초 만에 EFS를 통해 모델 워크스페이스 초기화 |
| TensorRT 초기화 | 20:00:51.168 | TensorRT-LLM 엔진 설정 시작 |
| 엔진 준비 | 20:01:06 | 엔진 로드 및 프로파일 활성화 (~2개 GPU에 걸쳐 16.6 GiB) |
| API 서버 준비 | 20:02:11.036 | FastAPI + Uvicorn 시작 |
| 헬스 체크 OK | 20:02:18.781 | /v1/health/ready 엔드포인트가 200 OK 반환 |
시작 시간 (콜드 부팅에서 준비까지): EFS의 캐시된 엔진 덕분에 ~81초.
프롬프트로 모델 테스트
1단계: 모델 서비스 포트 포워딩
포트 포워딩을 사용하여 모델을 로컬로 노출합니다:
kubectl port-forward -n nim-service service/meta-llama3-8b-instruct 8001:8000
2단계: curl을 사용하여 샘플 프롬프트 전송
다음 명령을 실행하여 채팅 프롬프트로 모델을 테스트합니다:
curl -X POST \
http://localhost:8001/v1/chat/completions \
-H 'Accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta/llama-3.1-8b-instruct",
"messages": [
{
"role": "user",
"content": "What should I do for a 4 day vacation at Cape Hatteras National Seashore?"
}
],
"top_p": 1,
"n": 1,
"max_tokens": 1024,
"stream": false,
"frequency_penalty": 0.0,
"stop": ["STOP"]
}'
샘플 응답 (요약):
{"id":"chat-061a9dba9179437fa24cab7f7c767f19","object":"chat.completion","created":1743215809,"model":"meta/llama-3.1-8b-instruct","choices":[{"index":0,"message":{"role":"assistant","content":"Cape Hatteras National Seashore is a beautiful coastal destination with a rich history, pristine beaches,
...
exploration of the area's natural beauty and history. Feel free to modify it to suit your interests and preferences. Safe travels!"},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":30,"total_tokens":773,"completion_tokens":743},"prompt_logprobs":null}%
모델은 이제 두 개의 A10G GPU에서 Tensor Parallelism = 2로 실행되며, 각각 약 21.4 GiB의 메모리를 사용합니다. EFS로 지원되는 NIMCache 덕분에 모델이 빠르게 로드되어 저지연 추론을 수행할 준비가 되었습니다.
Open WebUI 배포
Open WebUI는 OpenAI API 서버 및 Ollama와 호환되는 모델에서만 작동합니다.
1. WebUI 배포
다음 명령을 실행하여 Open WebUI를 배포합�니다:
kubectl apply -f ai-on-eks/blueprints/inference/gpu/nvidia-nim-operator-llama3-8b/openai-webui-deployment.yaml
2. WebUI 접근을 위한 포트 포워딩
kubectl 포트 포워딩을 사용하여 로컬에서 WebUI에 접근합니다:
kubectl port-forward svc/open-webui 8081:80 -n openai-webui
3. WebUI 접근
브라우저를 열고 http://localhost:8081 로 이동합니다
4. 가입
이름, 이메일 및 임의의 비밀번호를 사용하여 가입합니다.
5. 새 채팅 시작
아래 스크린샷과 같이 드롭다운 메뉴에서 모델을 선택하고 New Chat을 클릭합니다:
6. 테스트 프롬프트 입력
프롬프트를 입력하면 아래와 같이 스트리밍 결과를 볼 수 있습니다:

NVIDIA GenAI-Perf 도구를 사용한 성능 테스트
GenAI-Perf는 추론 서버를 통해 제공되는 생성형 AI 모델의 처리량과 지연 시간을 측정하기 위한 명령줄 도구입니다.
GenAI-Perf는 추론 서버에 배포된 다른 모델과 벤치마크하는 표준 도구로 사용할 수 있습니다. 그러나 이 도구에는 GPU가 필요합니다. 더 쉽게 하기 위해 도구를 실행하는 미리 구성된 매니페스트 genaiperf-deploy.yaml을 제공합니다.
cd ai-on-eks/blueprints/inference/gpu/nvidia-nim-operator-llama3-8b
kubectl apply -f genaiperf-deploy.yaml
Pod가 1/1 Running 상태가 되면 Pod에 접속할 수 있습니다.
export POD_NAME=$(kubectl get po -l app=genai-perf -ojsonpath='{.items[0].metadata.name}')
kubectl exec -it $POD_NAME -- bash
배포된 NIM Llama3 모델에 대한 테스트 실행
genai-perf profile -m meta/llama-3.1-8b-instruct \
--url meta-llama3-8b-instruct.nim-service:8000 \
--service-kind openai \
--endpoint-type chat \
--num-prompts 100 \
--synthetic-input-tokens-mean 200 \
--synthetic-input-tokens-stddev 0 \
--output-tokens-mean 100 \
--output-tokens-stddev 0 \
--concurrency 20 \
--streaming \
--tokenizer hf-internal-testing/llama-tokenizer
다음과 유사한 출력이 표시됩니다
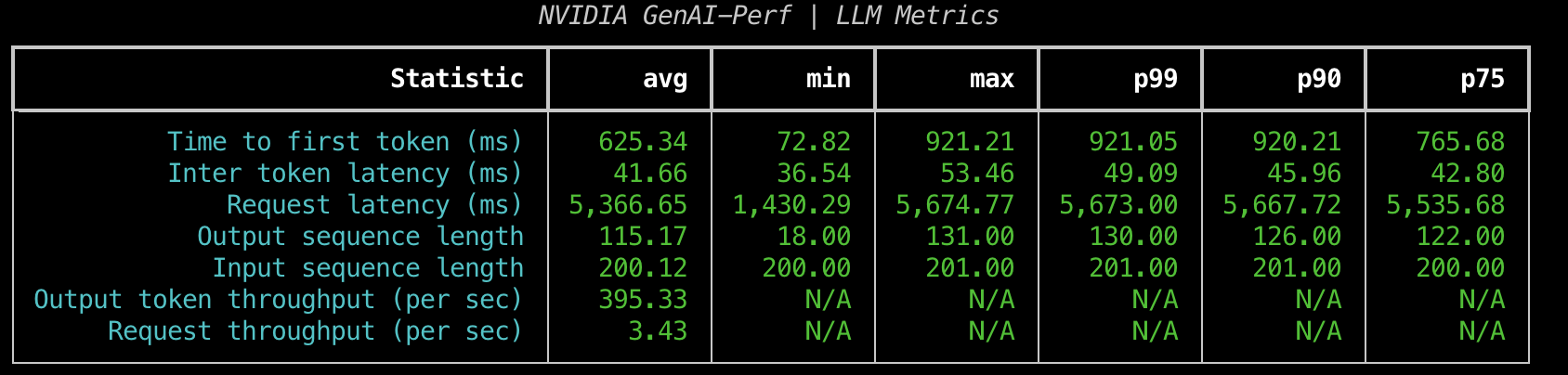
genai-perf가 수집하는 메트릭(Request latency, Output token throughput, Request throughput 포함)을 볼 수 있습니다.
명령줄 옵션을 이해하려면 이 문서를 참조하십시오.
Grafana 대시보드
NVIDIA는 NIM 상태를 더 잘 시각화하기 위한 Grafana 대시보드를 제공합니다. Grafana 대시보드에는 몇 가지 중요한 메트릭이 포함되어 있습니다:
- Time to First Token (TTFT): 모델에 대한 초기 추론 요청과 첫 번째 토큰 반환 사이의 지연 시간입니다.
- Inter-Token Latency (ITL): 첫 번째 토큰 이후 각 토큰 사이의 지연 시간입니다.
- Total Throughput: NIM이 초당 생성하는 총 토큰 수입니다.
더 많은 메트릭 설명은 이 문서에서 찾을 수 있습니다.
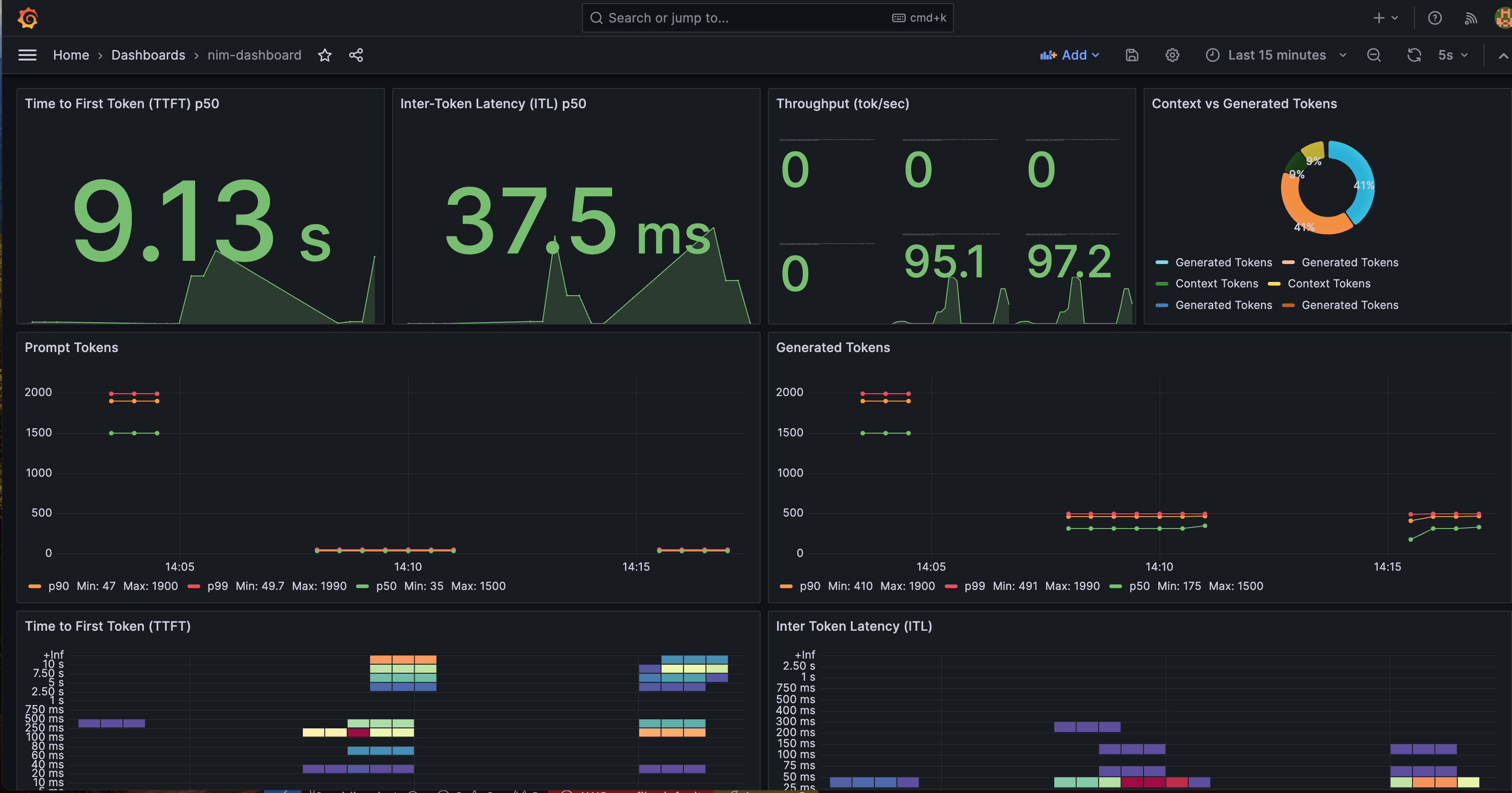
Time-to-First-Token, Inter-Token-Latency, KV Cache Utilization 메트릭과 같은 지표를 모니터링할 수 있습니다.
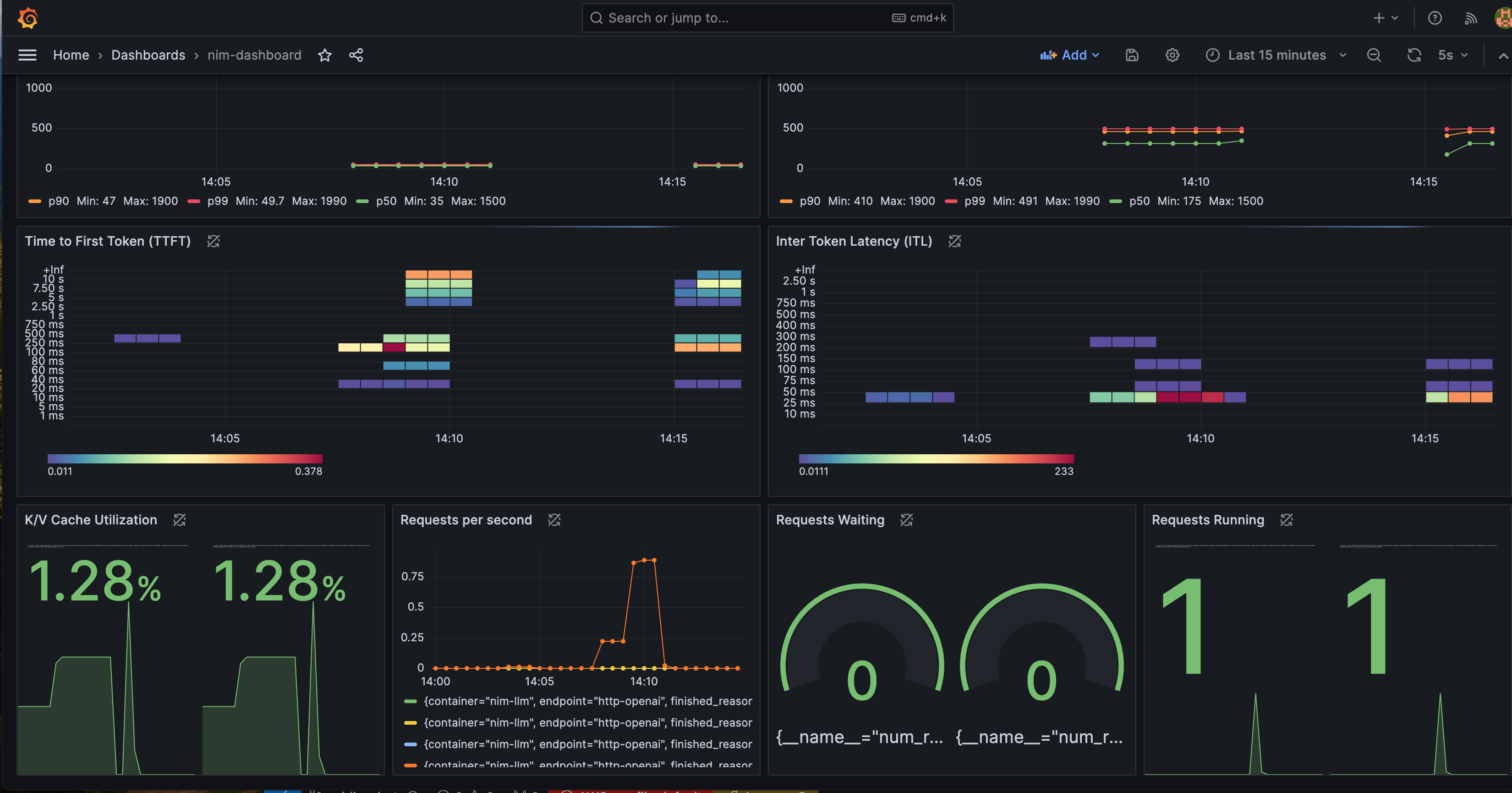
이러한 메트릭을 모니터링하기 위한 Grafana 대시보드를 보려면 아래 단계를 따르십시오:
세부 정보를 보려면 클릭하십시오
1. Grafana 비밀번호 검색.
비밀번호는 AWS Secret Manager에 저장되어 있습니다. 아래 Terraform 명령은 시크릿 이름을 표시합니다.
terraform output grafana_secret_name
그런 다음 출력된 시크릿 이름을 사용하여 아래 명령을 실행합니다,
aws secretsmanager get-secret-value --secret-id <grafana_secret_name_output> --region $AWS_REGION --query "SecretString" --output text
2. Grafana 서비스 노출
포트 포워딩을 사용하여 Grafana 서비스를 노출합니다.
kubectl port-forward svc/kube-prometheus-stack-grafana 3000:80 -n monitoring
3. Grafana 로그인:
- 웹 브라우저를 열고 http://localhost:3000으로 이동합니다.
- 사용자 이름
admin과 AWS Secrets Manager에서 검색한 비밀번호로 로그인합니다.
4. NIM 모니터링 대시보드 열기:
- 로그인 후 왼쪽 사이드바에서 "Dashboards"를 클릭하고 "nim"을 검색합니다
- 목록에서
NVIDIA NIM Monitoring대시보드를 찾을 수 있습니다 - 클릭하여 대시보드로 들어갑니다.
이제 Grafana 대시보드에 표시된 메트릭을 볼 수 있으며, NVIDIA NIM 서비스 배포의 성능을 모니터링할 수 있습니다.
이 가이드 작성 시점에 NVIDIA도 예제 Grafana 대시보드를 제공합니다. 여기에서 확인할 수 있습니다.
결론
이 블루프린트는 NVIDIA NIM Operator를 사용하여 Amazon EKS에서 Meta의 Llama 3.1 8B Instruct와 같은 대규모 언어 모델을 효율적으로 배포하고 확장하는 방법을 보여줍니다.
OpenAI 호환 API와 GPU 가속 추론, 선언적 Kubernetes CRD (NIMCache, NIMService) 및 EFS 기반 캐싱을 통한 빠른 모델 시작을 결합하여 간소화된 프로덕션급 모델 배포 경험을 얻을 수 있습니다.
주요 이점:
- 공유 영구 모델 캐시를 통한 더 빠른 콜드 스타트
- CRD를 통한 선언적이고 반복 가능한 배포
- Karpenter가 지원하는 동적 GPU 오토스케일링
- Terraform을 사용한 원클릭 인프라 프로비저닝
~20분 만에 제로에서 Kubernetes의 확장 가능한 LLM 서비스까지 - 저지연과 높은 효율성으로 실제 프롬프트를 처리할 준비가 됩니다.
정리
배포된 모델 및 관련 인프라를 해제하려면:
1단계: 모델 리소스 삭제
클러스터에서 배포된 NIMService 및 NIMCache 객체를 삭제합니다:
cd blueprints/inference/gpu/nvidia-nim-operator-llama3-8b
kubectl delete -f nim-service-llama3-8b-instruct.yaml
kubectl delete -f nim-cache-llama3-8b-instruct.yaml
삭제 확인:
kubectl get nimservices.apps.nvidia.com -n nim-service
kubectl get nimcaches.apps.nvidia.com -n nim-service
2단계: AWS 인프라 삭제
루트 Terraform 모듈로 돌아가서 정리 스크립트를 실행합니다. 이렇게 하면 VPC, EKS 클러스터, EFS 및 노드 그룹을 포함하여 이 블루프린트를 위해 생성된 모든 AWS 리소스가 삭제됩니다:
cd ai-on-eks/infra/nvidia-nim
./cleanup.sh