Pipelines and Workflows
Pipelines and workflows automate asset processing in VAMS. A pipeline defines a single processing step (such as converting a file format, extracting metadata, or generating preview thumbnails), while a workflow chains one or more pipelines together in sequence and can be triggered automatically on file upload.
Concepts
Pipelines
A pipeline represents a discrete processing operation. Pipelines can be built-in (deployed with VAMS) or user-created. Each pipeline has an execution type that determines how it processes data:
| Execution type | Description |
|---|---|
| Lambda | Invokes an AWS Lambda function directly. Supports both synchronous execution and callback mode. If no Lambda function name is provided, VAMS deploys a template function on your behalf. |
| SQS | Sends a message to an Amazon SQS queue. The downstream consumer processes the message asynchronously. |
| EventBridge | Publishes an event to an Amazon EventBridge event bus. The downstream consumer processes the event asynchronously. |
SQS and EventBridge pipelines without callback mode enabled operate as fire-and-forget integrations. They push data to the downstream service but do not return output files, preview images, or metadata back to VAMS.
Workflows
A workflow orchestrates one or more pipeline steps in sequence using AWS Step Functions. When a workflow executes, it runs each pipeline step in order, passing the output context from one step to the next.
Workflows can be:
- Database-specific -- Scoped to a particular database, using pipelines from that database.
- GLOBAL -- Available across all databases, using GLOBAL pipelines.
Viewing available pipelines
- Navigate to Pipelines from the left navigation menu.
- Select a database from the database selector, or view all pipelines across databases.
- The pipeline list displays all pipelines you have permission to access, showing the pipeline name, database, type, execution type, description, and associated actions.
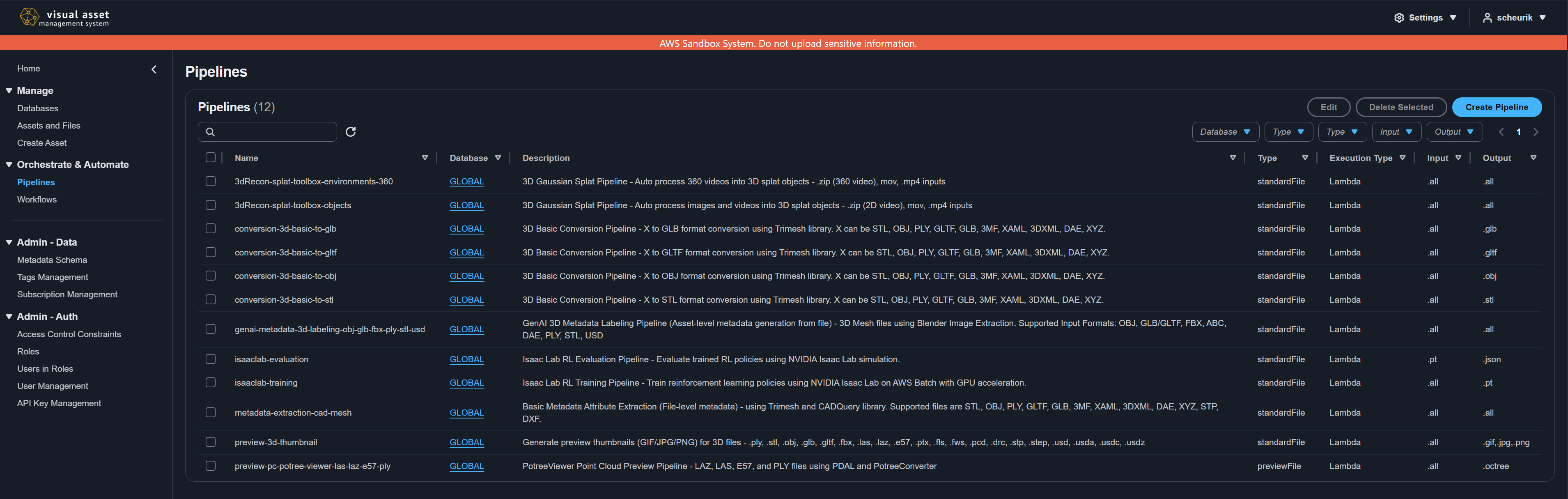
To view details of a specific pipeline, click its name in the list. The detail view shows the full pipeline configuration including execution settings and input parameters.
Creating a custom pipeline
To create a new pipeline:
- Navigate to Pipelines and click Create Pipeline.
- Fill in the pipeline configuration form:
| Field | Required | Description |
|---|---|---|
| Pipeline Name | Yes | Unique identifier. 4-64 characters, letters, numbers, hyphens, and underscores only. |
| Database | Yes | The database this pipeline belongs to. Select GLOBAL for cross-database pipelines. |
| Pipeline Type | Yes | Classification of what the pipeline does (for example, conversion, metadata extraction). |
| Execution Type | Yes | Lambda, SQS, or EventBridge. Determines the integration method. |
| Wait for Callback | Yes | When enabled, VAMS waits for the downstream service to call back with results using an AWS Step Functions Task Token. |
| Task Timeout | Conditional | Required when callback is enabled. Maximum seconds the task can run (up to 604,800 seconds / 1 week). |
| Task Heartbeat Timeout | No | Optional. When set, the downstream service must send periodic heartbeats within this interval. Must be less than Task Timeout. |
| Description | Yes | 4-256 character description of the pipeline's purpose. |
| Asset Type | Yes | The asset type this pipeline is designed for (for example, .all for any asset type, .jpg for JPEG-specific processing). |
| Output Type | Yes | The output type produced by the pipeline (for example, .all, .glb). |
| Input Parameters | No | Optional parameters passed to the pipeline at execution time. |
Execution-type-specific fields
Depending on the selected execution type, additional fields appear:
Lambda execution type:
| Field | Required | Description |
|---|---|---|
| Lambda Function Name | No | The name of an existing AWS Lambda function. If omitted, VAMS creates a template function. |
SQS execution type:
| Field | Required | Description |
|---|---|---|
| SQS Queue URL | Yes | The full URL of the Amazon SQS queue (for example, https://sqs.us-east-1.amazonaws.com/123456789012/my-queue). |
EventBridge execution type:
| Field | Required | Description |
|---|---|---|
| EventBridge Bus ARN | No | The ARN of the event bus. Leave empty to use the default event bus. |
| EventBridge Source | No | The event source string. Defaults to vams.pipeline. |
| EventBridge Detail Type | No | The event detail type. Defaults to the pipeline ID. |
- Click Create Pipeline to save.
A pipeline cannot be deleted if it is currently used by any workflow. You must remove the pipeline from all workflows before deleting it.
Updating a pipeline
When you update an existing pipeline, VAMS prompts you to choose whether to also update all workflows that reference this pipeline. This ensures workflow definitions stay in sync with pipeline changes.
Viewing available workflows
- Navigate to Workflows from the left navigation menu.
- Select a database or view all workflows across databases.
- The workflow list displays workflow names, databases, descriptions, and associated actions.
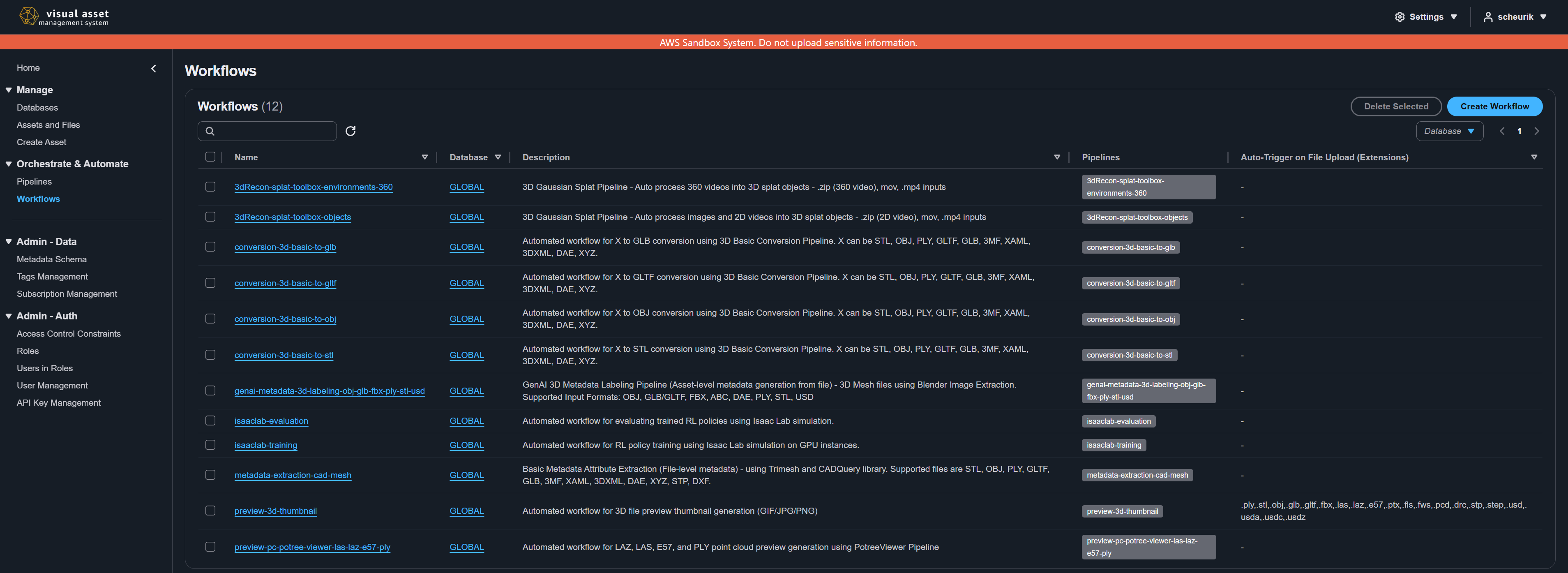
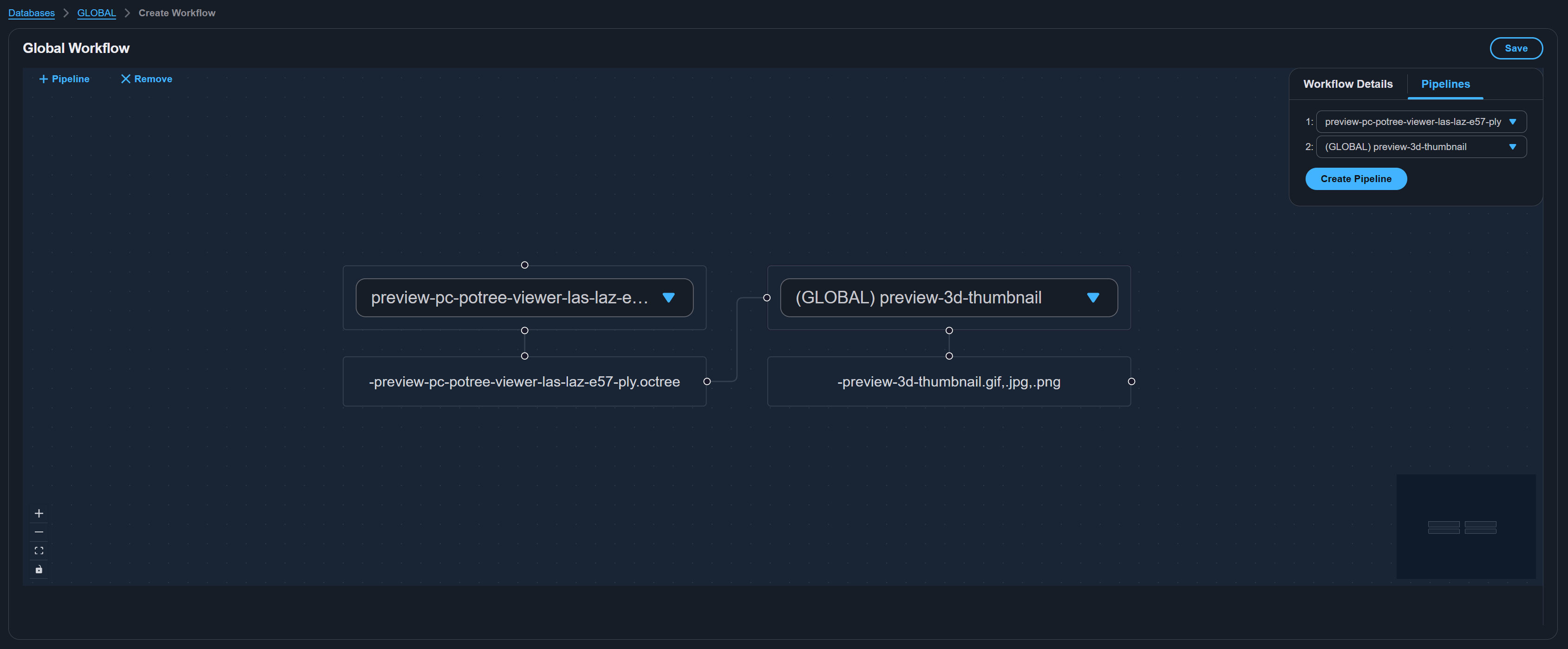
Creating a workflow
- Navigate to Workflows and click Create Workflow.
- If you are not already viewing a specific database, select the database for this workflow from the database selector. Select GLOBAL for a cross-database workflow.
- The workflow editor opens with a visual editor on the left and a configuration panel on the right.
Workflow details tab
| Field | Required | Description |
|---|---|---|
| Workflow Name | Yes | Unique identifier. 4-64 characters, letters, numbers, hyphens, and underscores only. No spaces. |
| Description | Yes | 4-256 character description of the workflow's purpose. |
| Auto-Trigger - File Upload | No | When enabled, the workflow runs automatically when files matching the specified extensions are uploaded to any asset in the database. |
| File Extensions | Conditional | Required when auto-trigger is enabled. Comma-delimited list of file extensions to trigger on (for example, jpg,png,pdf). Use .all to trigger on all file uploads. |
Auto-trigger is a powerful feature for automating processing. For example, you can set up a workflow that automatically generates preview thumbnails and extracts metadata whenever a .e57 point cloud file is uploaded.
Pipelines tab
- Click [+ Pipeline] on the visual workflow editor to add a pipeline step.
- Select a pipeline from the dropdown for each step. Available pipelines include those from the workflow's database and all GLOBAL pipelines.
- Pipeline steps execute in the order they are listed.
- To add additional steps, click [+ Pipeline] again on the workflow editor.
You can also click Create Pipeline at the bottom of the pipelines tab to create a new pipeline inline without leaving the workflow editor.
Saving the workflow
Click Save to persist the workflow. The workflow definition is stored and an AWS Step Functions state machine is created or updated.
Executing workflows
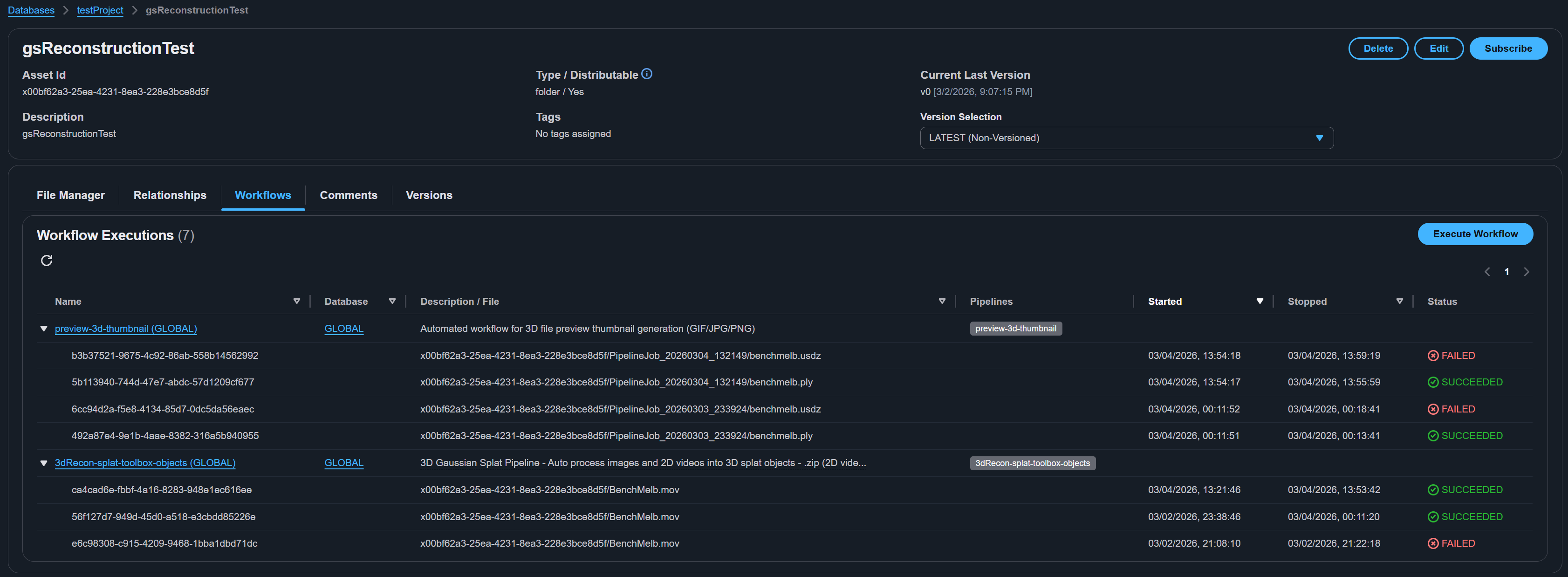
Workflows can be executed in two ways:
Manual execution
- Navigate to an asset's detail page.
- Select the files you want to process.
- Choose the workflow to execute.
- The workflow runs asynchronously, processing the selected files through each pipeline step in sequence.
Automatic execution
When a workflow has auto-trigger enabled, it runs automatically whenever a file matching the configured extensions is uploaded to an asset within the workflow's database. The uploaded file is passed as the input to the workflow.
Monitoring execution
Execution progress can be monitored from the Executions page or from the asset detail page. Each execution shows:
- The workflow and pipeline step being executed
- Current status (running, succeeded, failed)
- Start and end timestamps
- Error details for failed executions
Workflow execution is asynchronous. Results (output files, previews, metadata) appear on the asset after all pipeline steps complete. Changes may take a few minutes to propagate through the system, including search results.
GLOBAL vs. database-specific
| Scope | Pipelines | Workflows |
|---|---|---|
| Database-specific | Available only within the database they belong to | Can use pipelines from their database and GLOBAL pipelines |
| GLOBAL | Available to workflows in any database | Can only use GLOBAL pipelines |
GLOBAL pipelines are typically built-in processing pipelines deployed with VAMS (such as 3D conversion, preview generation, and metadata extraction). Database-specific pipelines are user-created for domain-specific processing needs.
Built-in pipelines
VAMS may include built-in pipelines depending on your deployment configuration. These are created during deployment and registered as GLOBAL pipelines. Common built-in pipelines include:
- 3D Conversion -- Converts 3D file formats (for example, IFC to glTF).
- Preview Generation -- Creates thumbnail preview images for assets and files.
- Point Cloud Processing -- Processes point cloud data (for example, E57, LAS) for web visualization.
- Metadata Extraction -- Extracts metadata from file headers and content.
- GenAI Labeling -- Uses generative AI to automatically generate labels and descriptions.
- Gaussian Splatting -- Generates 3D Gaussian splats from image and video media files.
- Physical AI Inference and Fine-Tuning -- GPU-accelerated pipelines for NVIDIA world foundation models, vision language models (VLMs), and vision-language-action models (VLAs) including inference, simulation training, and model fine-tuning.
For detailed pipeline documentation, see the Pipelines overview, deployment configuration reference, and custom pipelines guide.
Permissions
Access to pipelines and workflows is controlled by the VAMS permission system. Users need appropriate constraints on the pipeline and workflow object types to view, create, edit, or delete pipelines and workflows. For details, see Permissions.
Workflow operations can also be performed via the command line. See CLI Workflow Commands.