Bark
The Bark synthesizer middleware synthesizes input text documents into voices using the Bark generative audio model. The synthesizer deploys a cluster of GPU-enabled containers in a VPC to automate the synthesis process, and keep all data within the boundaries of the AWS account.
🐶 Synthesizing Text
To use this middleware, you import it in your CDK stack and instantiate it as part of a pipeline and connect it to a data source that provides input documents, such as the S3 Trigger.
import { BarkSynthesizer } from '@project-lakechain/bark-synthesizer';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { // Sample VPC. const vpc = new ec2.Vpc(this, 'Vpc', {});
// The cache storage. const cache = new CacheStorage(this, 'Cache');
// Convert the text to speech using the Bark model. const synthesizer = new BarkSynthesizer.Builder() .withScope(this) .withIdentifier('BarkTextToSpeech') .withCacheStorage(cache) .withVpc(vpc) .withSource(source) // 👈 Specify a data source .build(); }}Input Language
The Bark synthesizer needs to know what is the source language of the text to be able to select the appropriate voice for the text-to-speech synthesis. The first location used by the middleware to infer the source language is the document metadata. If a previous middleware, such as the NLP Text Processor, has already detected the language of the document, the synthesizer will use that information. If no language was specified, the Bark synthesizer will assume the input document language to be english.
ℹ️ Below is an example showcasing how to use the NLP Text processor to detect the language of input text documents to enrich their metadata before the Bark synthesizer is invoked.
import { NlpTextProcessor, dsl as l } from '@project-lakechain/nlp-text-processor';import { BarkSynthesizer } from '@project-lakechain/bark-synthesizer';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { // Sample VPC. const vpc = new ec2.Vpc(this, 'Vpc', {});
// The cache storage. const cache = new CacheStorage(this, 'Cache');
// Detects the language of input text documents. const nlp = new NlpTextProcessor.Builder() .withScope(this) .withIdentifier('Nlp') .withCacheStorage(cache) .withSource(source) .withIntent( l.nlp().language() ) .build();
// Convert the text to speech using the Bark model. const synthesizer = new BarkSynthesizer.Builder() .withScope(this) .withIdentifier('BarkTextToSpeech') .withCacheStorage(cache) .withVpc(vpc) .withSource(nlp) .build(); }}Language Override
It is also possible to override the input language of text documents. In this case, developers can force the Bark synthesizer to assume a specific input language.
const synthesizer = new BarkSynthesizer.Builder() .withScope(this) .withIdentifier('BarkTextToSpeech') .withCacheStorage(cache) .withVpc(vpc) .withSource(source) .withLanguageOverride('fr') .build();Voice Mapping
By default, the Bark synthesizer will randomly select a suitable voice from the input language associated with a document. You can however specify a list of specific voices that you would like to associate with each language to better control which voice gets used during the synthesis process.
ℹ️ Check the Bark documentation to learn more about available voices.
const synthesizer = new BarkSynthesizer.Builder() .withScope(this) .withIdentifier('BarkTextToSpeech') .withCacheStorage(cache) .withVpc(vpc) .withSource(source) .withVoiceMapping('en', 'v2/en_speaker_0', 'v2/en_speaker_1') .withVoiceMapping('fr', 'v2/fr_speaker_0') .build();Temperature
Since the Bark Synthesizer uses a generative model, it is possible to control the amount of randomness in the generated audio by specifying a temperature value. The temperature value is a floating point number between 0 and 1. The higher the temperature, the more random the generated audio will be.
const synthesizer = new BarkSynthesizer.Builder() .withScope(this) .withIdentifier('BarkTextToSpeech') .withCacheStorage(cache) .withVpc(vpc) .withSource(source) .withTemperature(0.5) // 👈 Specify a temperature value .build();Auto-Scaling
The cluster of containers deployed by this middleware will auto-scale based on the number of documents that need to be processed. The cluster scales up to a maximum of 5 instances by default, and scales down to zero when there are no images to process.
ℹ️ You can configure the maximum amount of instances that the cluster can auto-scale to by using the
withMaxInstancesmethod.
const synthesizer = new BarkSynthesizer.Builder() .withScope(this) .withIdentifier('BarkTextToSpeech') .withCacheStorage(cache) .withVpc(vpc) .withSource(source) .withMaxInstances(10) // 👈 Maximum amount of instances .build();🏗️ Architecture
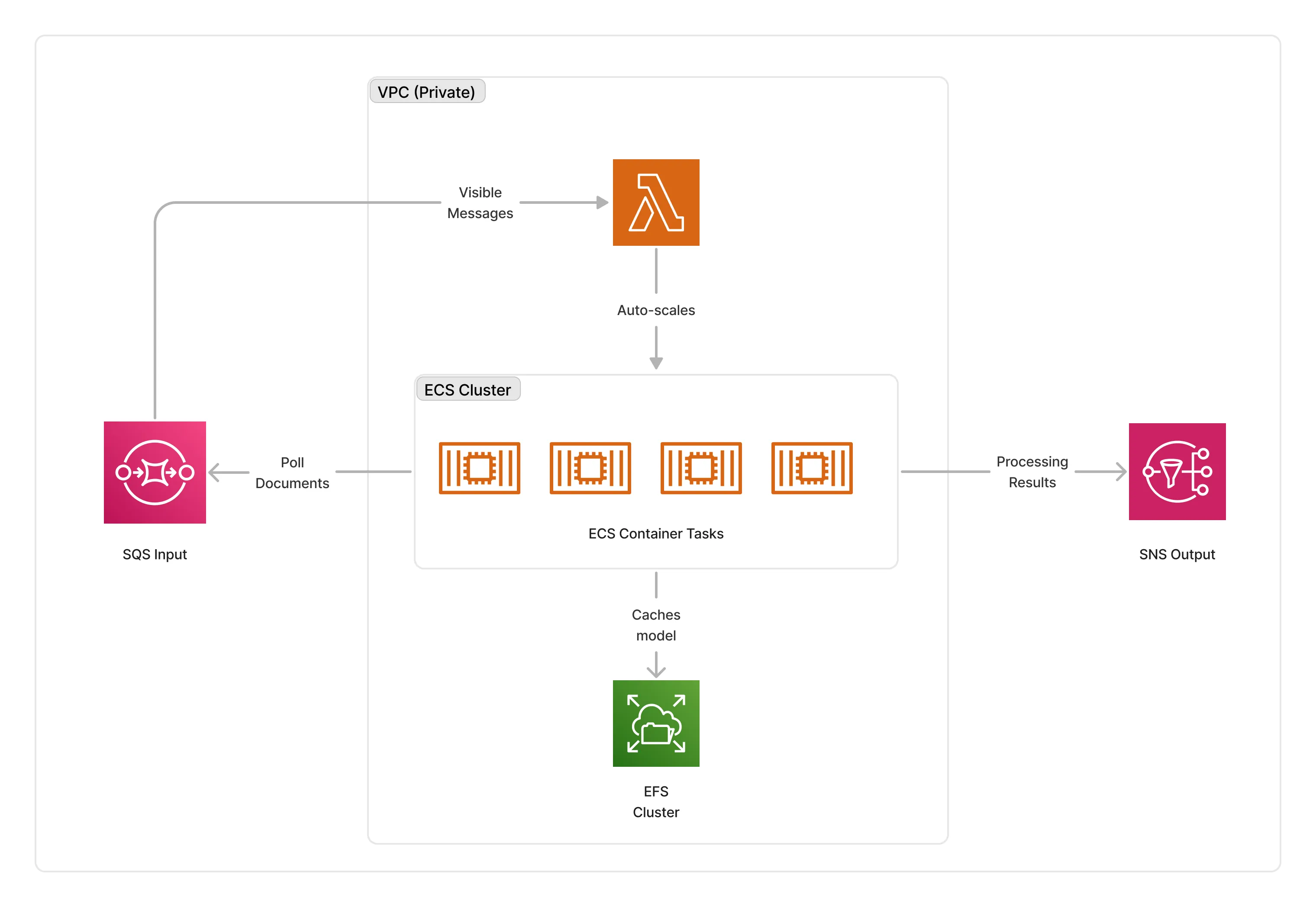
The Bark synthesizer requires GPU-enabled instances (g5.xlarge) to run the Bark audio model. To orchestrate deployments, it deploys an ECS auto-scaled cluster of containers that consume documents from the middleware input queue. The cluster is deployed in the private subnet of the given VPC, and caches the model on an EFS storage to optimize cold-starts.
ℹ️ The average cold-start for the Bark synthesizer is around 3 minutes when no instances are running.
🏷️ Properties
Supported Inputs
| Mime Type | Description |
|---|---|
text/plain | UTF-8 text documents. |
Supported Outputs
| Mime Type | Description |
|---|---|
audio/mpeg | MP3 audio documents. |
Supported Compute Types
| Type | Description |
|---|---|
GPU | This middleware only supports GPU compute. |
📖 Examples
- Bark Synthesizer Pipeline - Builds a pipeline for synthesizing text to speech using the Bark model.