S3 Connector
The S3 storage connector makes it possible to capture the result of one or multiple middlewares in a pipeline and store their results in a user-defined S3 bucket destination. This connector supports storing both the CloudEvents emitted by middlewares, but also optionally copy the output document itself to the destination bucket.
🗄️ Storing Documents
To use the S3 storage connector, you import it in your CDK stack, and connect it to a data source providing documents.
import { S3StorageConnector } from '@project-lakechain/s3-storage-connector';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { // The cache storage. const cache = new CacheStorage(this, 'Cache');
// The destination bucket. const bucket = // ...
// Create the S3 storage connector. const connector = new S3StorageConnector.Builder() .withScope(this) .withIdentifier('S3StorageConnector') .withCacheStorage(cache) .withSource(source) // 👈 Specify a data source .withDestinationBucket(bucket) .build(); }}Copy Documents
By default, this connector will copy the CloudEvent emitted by middlewares, and also copy the document itself to the destination bucket. This behavior can be disabled by using the .withCopyDocuments API.
💁 This implementation uses a streaming approach for copying bytes to optimize the copy of large documents, such that it doesn’t need to load the entire document in memory. Note however that copies in general can be time and cost expensive.
const connector = new S3StorageConnector.Builder() .withScope(this) .withIdentifier('S3StorageConnector') .withCacheStorage(cache) .withSource(source) .withDestinationBucket(bucket) .withCopyDocuments(false) // 👈 Disable copying documents .build();Storage Class
You can specify a storage class for the documents and their metadata being written in the destination bucket to tailor the cost of the storage using the .withStorageClass API.
💁 By default, the S3 Standard class will be used to store the documents and their metadata.
const connector = new S3StorageConnector.Builder() .withScope(this) .withIdentifier('S3StorageConnector') .withCacheStorage(cache) .withSource(source) .withDestinationBucket(bucket) .withStorageClass('ONEZONE_IA') // 👈 Specify the storage class .build();🏗️ Architecture
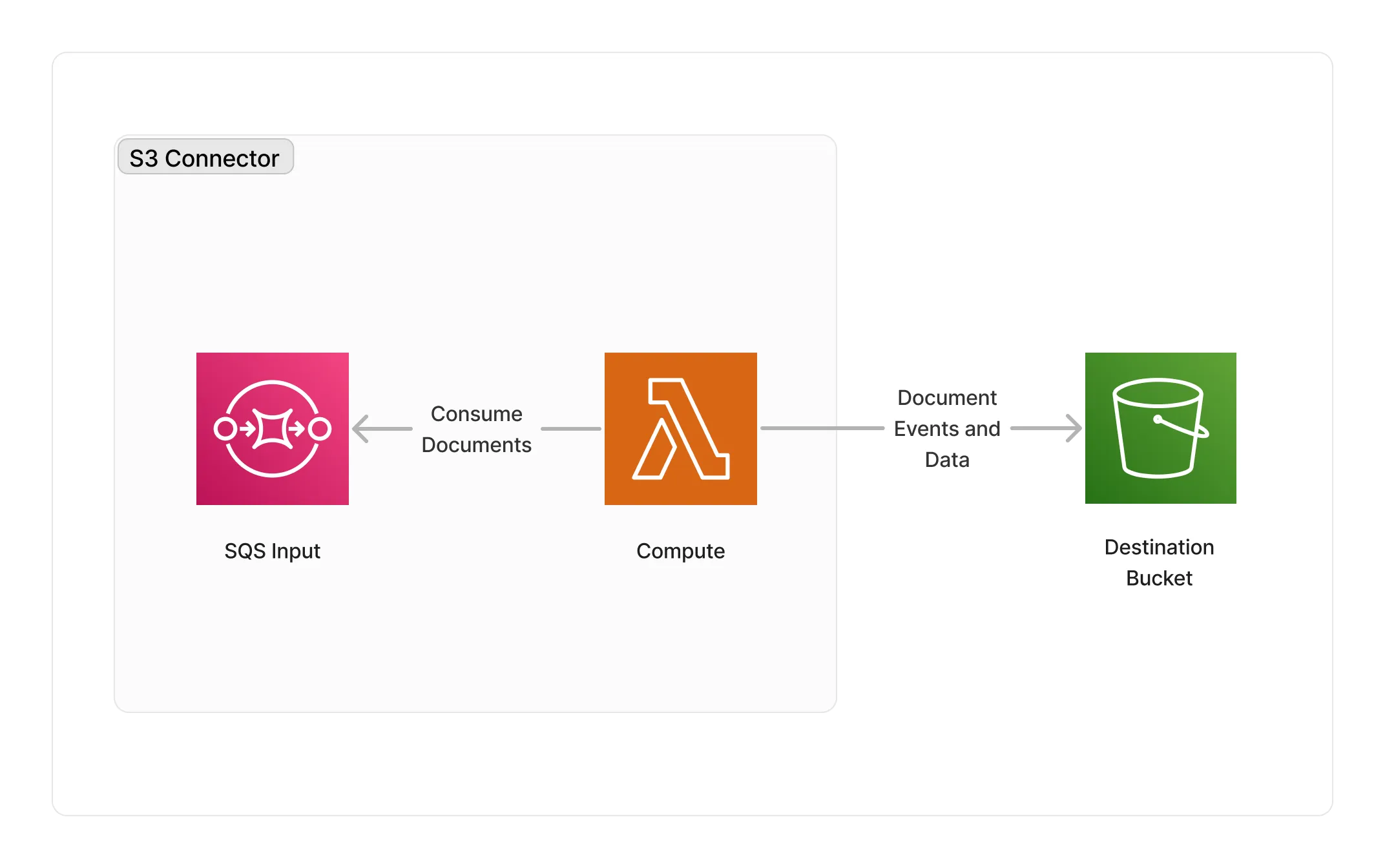
Thi middleware is based on a Lambda ARM64 compute to perform the copying of document data from source middlewares into the destination bucket.
🏷️ Properties
Supported Inputs
| Mime Type | Description |
|---|---|
*/* | This middleware supports any type of documents. |
Supported Outputs
This middleware does not emit any output.
Supported Compute Types
| Type | Description |
|---|---|
CPU | This middleware only supports CPU compute. |
📖 Examples
- Article Curation Pipeline - Builds a pipeline converting HTML articles into plain text.
- Face Detection Pipeline - An example showcasing how to build face detection pipelines using Project Lakechain.