Regexp Splitter
The Regexp text splitter makes it easy to split text documents at scale base on a string separator or a regular expression.
📝 Splitting Text
To use this middleware, you import it in your CDK stack, and connect it to a data source providing text documents, such as the S3 Trigger.
import { RegexpTextSplitter } from '@project-lakechain/regexp-text-splitter';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { // The cache storage. const cache = new CacheStorage(this, 'Cache');
// Create the Regexp text splitter. const splitter = new RegexpTextSplitter.Builder() .withScope(this) .withIdentifier('Splitter') .withCacheStorage(cache) .withSource(source) .withSeparator('\r\n') // 👈 Specify a separator .build(); }}Using Regexps
You can also use native ECMAScript regular expressions to define the separator on which the middleware will split the text documents.
ℹ️ The below example splits text documents based on Markdown code blocks.
const splitter = new CharacterTextSplitter.Builder() .withScope(this) .withIdentifier('Splitter') .withCacheStorage(cache) .withSource(source) .withSeparator(/```[\s\S]*?```/) .build();📄 Output
This middleware takes as an input text documents, and outputs multiple text documents that are the result of the text splitting process. This allows to process each chunk of text in parallel in downstream middlewares.
In addition to producing new text documents, this middleware also associates metadata with each chunk, such as the chunk identifier and order relative to the original document. Below is an example of CloudEvent produced by this middleware.
💁 Click to expand example
{ "specversion": "1.0", "id": "1780d5de-fd6f-4530-98d7-82ebee85ea39", "type": "document-created", "time": "2023-10-22T13:19:10.657Z", "data": { "chainId": "6ebf76e4-f70c-440c-98f9-3e3e7eb34c79", "source": { "url": "s3://bucket/text.txt", "type": "text/plain", "size": 24536, "etag": "1243cbd6cf145453c8b5519a2ada4779" }, "document": { "url": "s3://bucket/text.txt", "type": "text/plain", "size": 24536, "etag": "1243cbd6cf145453c8b5519a2ada4779" }, "metadata": { "properties": { "kind": "text", "attrs": { "chunk": { "id": "4a5b6c7d8e9fd21dacb", "order": 0 } } } }, "callStack": [] }}🏗️ Architecture
This middleware runs within a Lambda compute based on the ARM64 architecture to run the text splitting process.
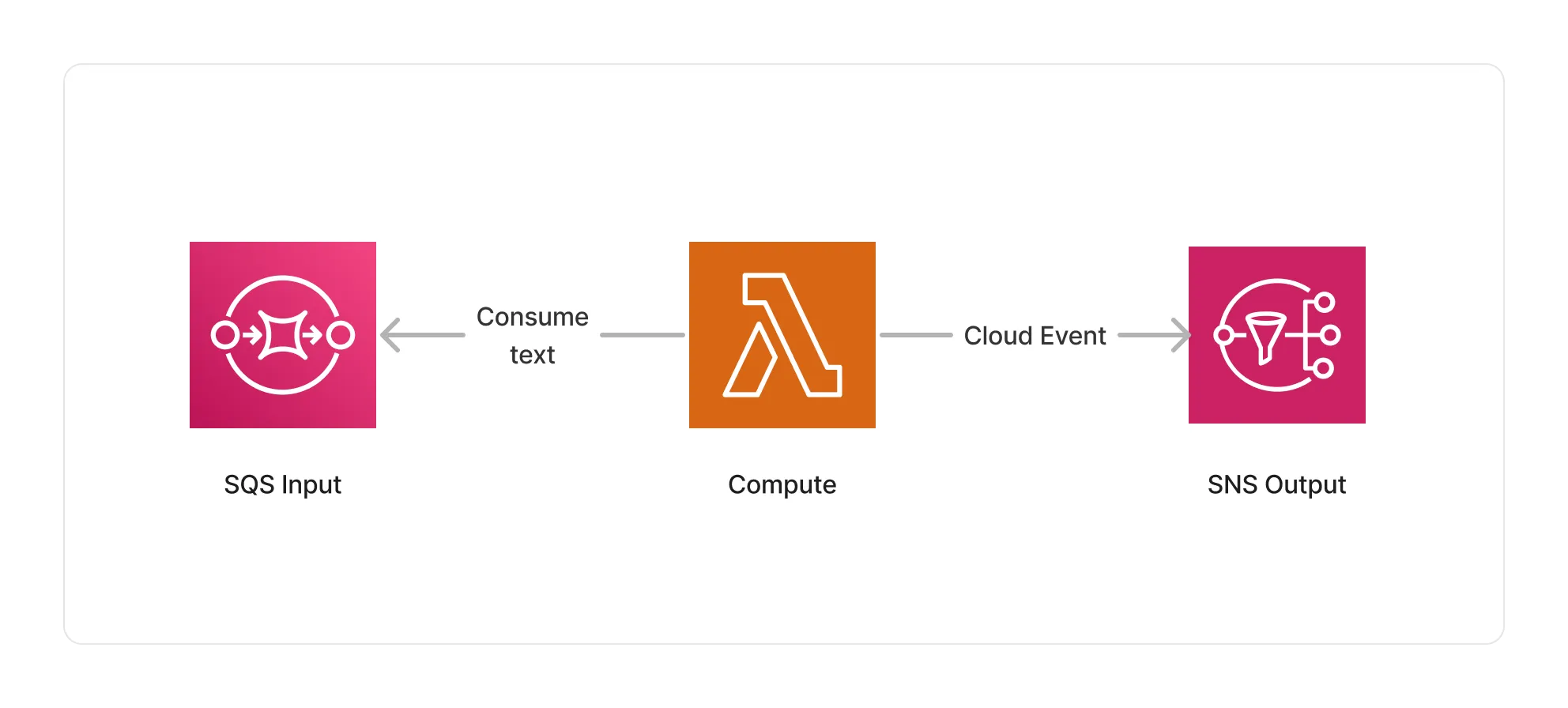
🏷️ Properties
Supported Inputs
| Mime Type | Description |
|---|---|
text/plain | UTF-8 text documents. |
Supported Outputs
| Mime Type | Description |
|---|---|
text/plain | UTF-8 text documents. |
Supported Compute Types
| Type | Description |
|---|---|
CPU | This middleware only supports CPU compute. |
📖 Examples
- Text Splitting Pipeline - Builds a pipeline for splitting text documents using different text splitting algorithms.