RSS Feeds
The Syndication feed parser makes it possible to parse RSS and Atom feeds from upstream documents, extract each feed item from the feeds, and forward them, along with their metadata to other middlewares in the pipeline.
📰 Parsing Feeds
To use this middleware, you import it in your CDK stack and instantiate it as part of a pipeline.
import { SyndicationFeedProcessor } from '@project-lakechain/syndication-feed-processor';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { const cache = new CacheStorage(this, 'Cache');
// Create the syndication feed processor. const syndicationProcessor = new SyndicationFeedProcessor.Builder() .withScope(this) .withIdentifier('SyndicationProcessor') .withCacheStorage(cache) .withSource(source) // 👈 Specify a data source .build(); }}📝 Metadata
This middleware will automatically extract feed item metadata and make them available as part of the output CloudEvents. The following metadata are extracted, when available, from feed items.
| Metadata | Description |
|---|---|
title | The title of the feed item. |
description | The description of the feed item. |
createdAt | The creation date of the feed item. |
updatedAt | The last update date of the feed item. |
authors | The authors associated with the feed item. |
keywords | The keywords associated with the feed item. |
language | The language of the feed item. |
📄 Output
This middleware takes as an input RSS or Atom syndication feeds, and outputs multiple HTML documents that are associated with each extracted feeds. This makes it possible for downstream middlewares to process each HTML document that is part of the original feed in parallel.
Below is an example of an output HTML document extracted from a feed item by the syndication feed processor.
💁 Click to expand example
{ "specversion": "1.0", "id": "1780d5de-fd6f-4530-98d7-82ebee85ea39", "type": "document-created", "time": "2023-10-22T13:19:10.657Z", "data": { "chainId": "6ebf76e4-f70c-440c-98f9-3e3e7eb34c79", "source": { "url": "https://aws.amazon.com/blogs/aws/feed/", "type": "application/rss+xml", "size": 24536, "etag": "1243cbd6cf145453c8b5519a2ada4779" }, "document": { "url": "https://aws.amazon.com/blogs/aws/aws-weekly-roundup-amazon-ecs-rds-for-mysql-emr-studio-aws-community-and-more-january-22-2024/", "type": "text/html", "size": 19526, "etag": "2a3b4c5d6e7f8d9e0a1b2c3d4e5f6a7b" }, "metadata": { "title": "AWS Weekly Roundup: Amazon ECS, RDS for MySQL, and More – January 22, 2024", "description": "Check out the latest announcements from AWS in the AWS Weekly Roundup.", "createdAt": "2024-01-22T00:00:00.000Z", "updatedAt": "2024-01-22T00:00:00.000Z", "authors": ["Jeff Barr"], "keywords": ["Amazon ECS", "RDS for MySQL", "EMR Studio", "AWS Community"], "properties": { "kind": "text", "attrs": { "language": "en" } } }, "callStack": [] }}ℹ️ Limits
This middleware will not attempt to request via HTTP the feed items to compute their size. Therefore, the size property on the document event for feed items is not specified on output events.
Another limitation lies in that this middleware only outputs HTML documents, and does not currently forward RSS Enclosures to downstream middlewares (e.g associated images or video documents).
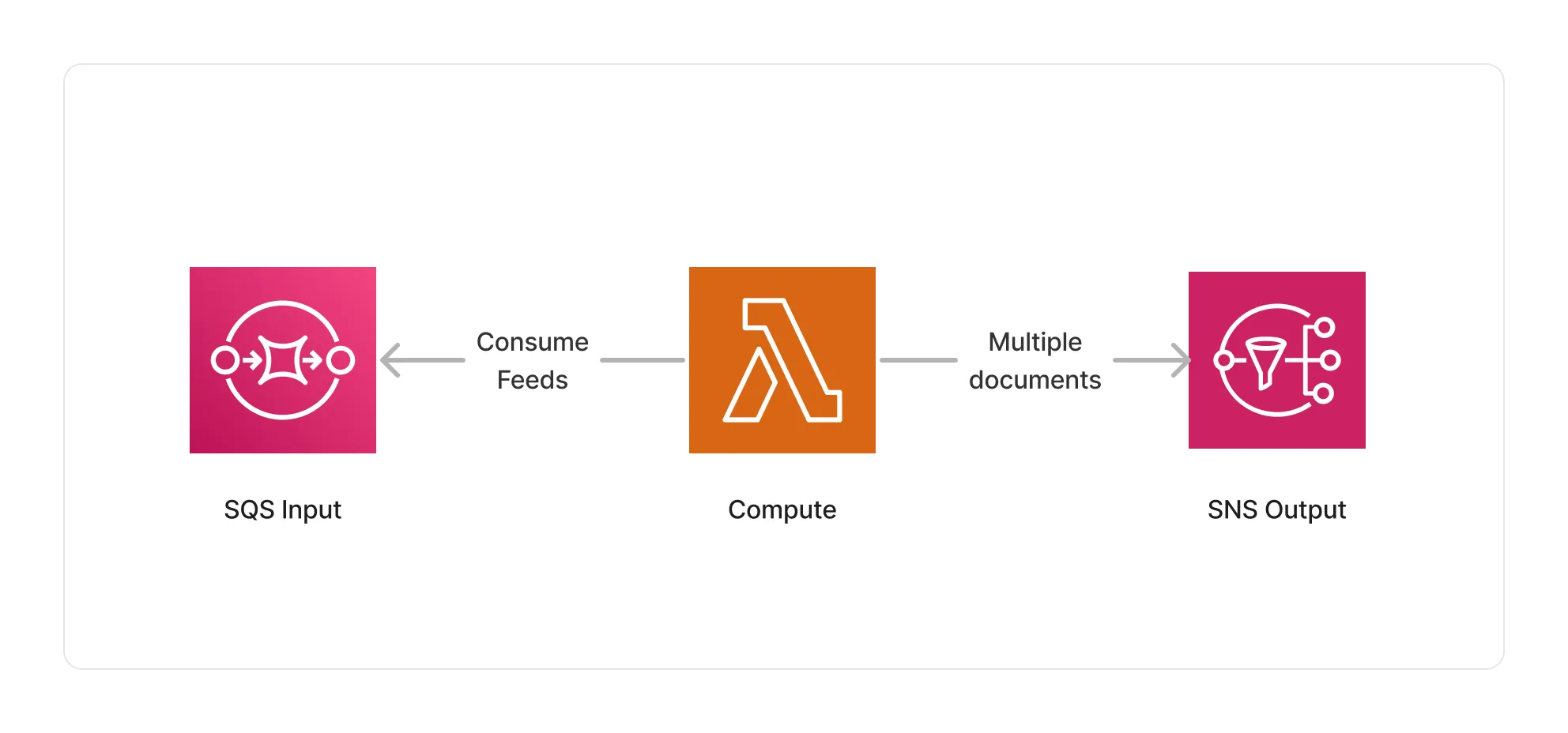
🏗️ Architecture
This middleware is based on a Lambda compute using the feedparser Python library to parse the feeds and extract the feed items.
🏷️ Properties
Supported Inputs
| Mime Type | Description |
|---|---|
application/rss+xml | RSS feeds. |
application/atom+xml | Atom feeds. |
Supported Outputs
| Mime Type | Description |
|---|---|
text/html | HTML documents. |
Supported Compute Types
| Type | Description |
|---|---|
CPU | This middleware only supports CPU compute. |
📖 Examples
- Article Curation Pipeline - Builds a pipeline converting HTML articles into plain text.