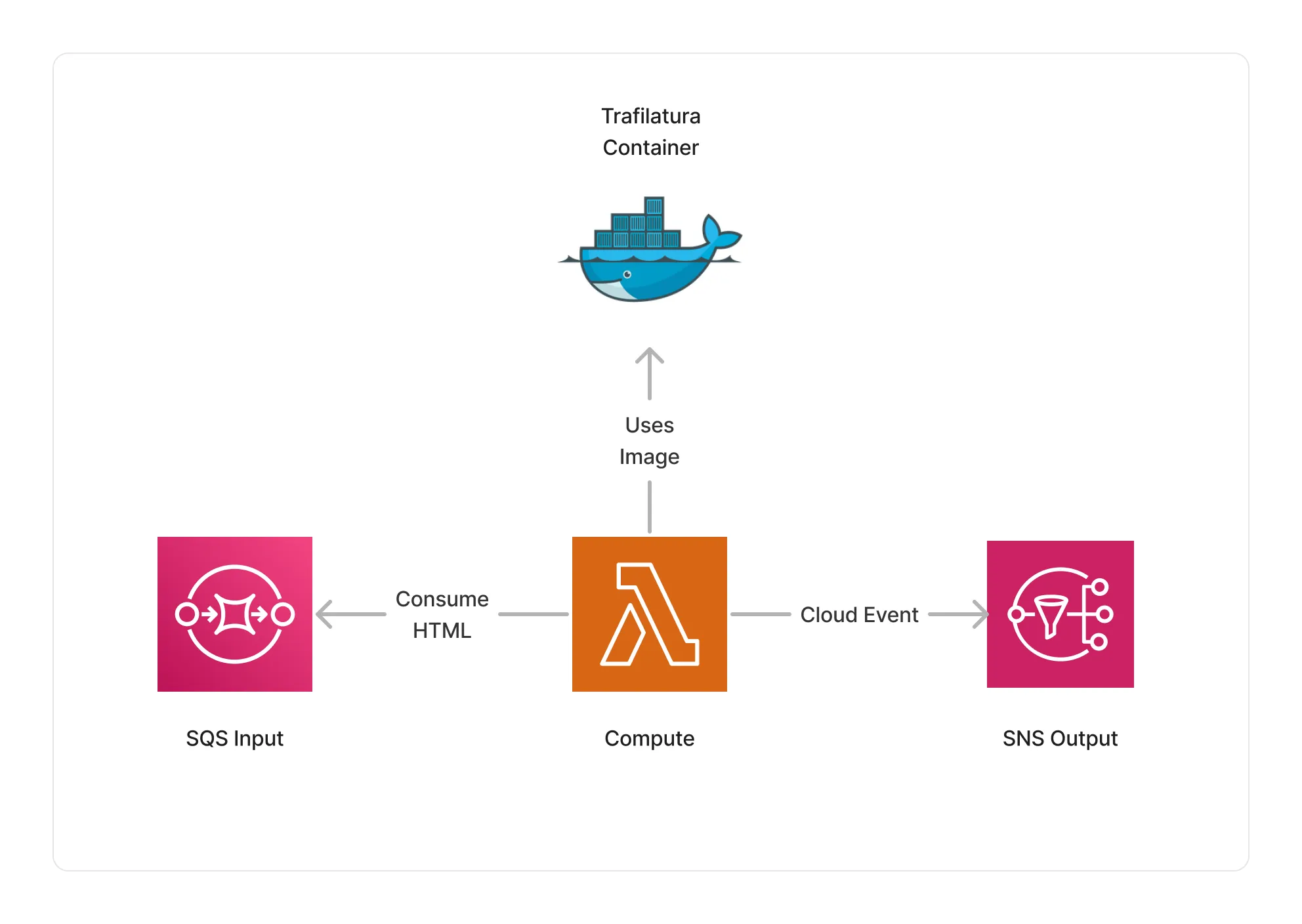
The Trafilatura middleware is based on the Trafilatura library which provides one of the most accurate rule-based engine for HTML article text extraction. It provides capability to analyze and extract the substance of HTML documents on the Web and use that text as an input to other middlewares in your pipeline.
📰 Extracting Text
To use this middleware, you import it in your CDK stack and instantiate it as part of a pipeline.