Ollama
Unstable API
0.8.0
@project-lakechain/ollama-processor
The Ollama processor makes it possible to run open-source language and multimodal models supported by Ollama on AWS.
Using this middleware, customers can analyze and transform their text and image documents, while keeping their data secure within the boundaries of their AWS account.
💁 You can view the list of models supported by Ollama here.
🦙 Running Ollama
To use this middleware, you import it in your CDK stack and connect it to a data source that provides text or image documents.
ℹ️ The below example shows how to create a pipeline that summarizes text documents uploaded to an S3 bucket.
import { S3EventTrigger } from '@project-lakechain/s3-event-trigger';import { CacheStorage } from '@project-lakechain/core';import { OllamaProcessor, OllamaModel, InfrastructureDefinition} from '@project-lakechain/ollama-processor';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { // Sample VPC. const vpc = new ec2.Vpc(this, 'VPC', {});
// The cache storage. const cache = new CacheStorage(this, 'Cache');
// Create the S3 event trigger. const trigger = new S3EventTrigger.Builder() .withScope(this) .withIdentifier('Trigger') .withCacheStorage(cache) .withBucket(bucket) .build();
// Summarize uploaded text documents. trigger.pipe(new OllamaProcessor.Builder() .withScope(this) .withIdentifier('OllamaProcessor') .withCacheStorage(cache) .withVpc(vpc) .withModel(OllamaModel.LLAMA2) .withPrompt('Give a detailed summary of the provided document.') .withInfrastructure(new InfrastructureDefinition.Builder() .withMaxMemory(15 * 1024) .withGpus(1) .withInstanceType(ec2.InstanceType.of( ec2.InstanceClass.G4DN, ec2.InstanceSize.XLARGE )) .build()) .build()); }}🤖 Model Selection
Ollama supports a variety of models, and you can specify the model and optionally the specific tag to use.
💁 When no tag is provided, the
latesttag is used. The example below showcases how to use a specific tag on a model.
import { OllamaProcessor, OllamaModel } from '@project-lakechain/ollama-processor';
const ollama = new OllamaProcessor.Builder() .withScope(this) .withIdentifier('OllamaProcessor') .withCacheStorage(cache) .withVpc(vpc) .withModel(OllamaModel.LLAMA2.tag('13b')) // 👈 Specify a model and tag. .withPrompt(prompt) .withInfrastructure(infrastructure) .build();Escape Hatch
The OllamaModel class provides a quick way to reference existing models, and select a specific tag.
However, as Ollama adds new models, you may be in a situation where a model is not yet referenced by this middleware.
To address this situation, you can manually specify a model definition pointing to the supported Ollama model you wish to run. You do so by specifying the name of the model in the Ollama library, the tag you wish to use, and its supported input and output mime-types.
💁 In the example below, we define the
llavaimage model and its inputs and outputs.
import { OllamaProcessor, OllamaModel } from '@project-lakechain/ollama-processor';
const ollama = new OllamaProcessor.Builder() .withScope(this) .withIdentifier('OllamaProcessor') .withCacheStorage(cache) .withVpc(vpc) .withModel(OllamaModel.of('llava', { tag: 'latest', inputs: ['image/png', 'image/jpeg'], outputs: ['text/plain'] })) .withPrompt(prompt) .withInfrastructure(infrastructure) .build();↔️ Auto-Scaling
The cluster of containers deployed by this middleware will auto-scale based on the number of documents that need to be processed. The cluster scales up to a maximum of 5 instances by default, and scales down to zero when there are no documents to process.
ℹ️ You can configure the maximum amount of instances that the cluster can auto-scale to by using the
withMaxInstancesmethod.
const ollama = new OllamaProcessor.Builder() .withScope(this) .withIdentifier('OllamaProcessor') .withCacheStorage(cache) .withVpc(vpc) .withSource(source) .withModel(OllamaModel.LLAMA2) .withPrompt(prompt) .withInfrastructure(infrastructure) .withMaxInstances(10) // 👈 Maximum amount of instances .build();🌉 Infrastructure
Every model requires a specific infrastructure to run optimally. To ensure the OllamaProcessor orchestrates your models using the most optimal instance, memory, and GPU allocation, you need to specify an infrastructure definition.
💁 The example below describes the infrastructure suited to run the
Mixtralmodel requiring significant RAM and GPU memory to run.
const ollama = new OllamaProcessor.Builder() .withScope(this) .withIdentifier('OllamaProcessor') .withCacheStorage(cache) .withVpc(vpc) .withModel(OllamaModel.MIXTRAL) .withPrompt(prompt) .withInfrastructure(new InfrastructureDefinition.Builder() .withMaxMemory(180_000) .withGpus(8) .withInstanceType(ec2.InstanceType.of( ec2.InstanceClass.G5, ec2.InstanceSize.XLARGE48 )) .build()) .build();Below is a description of the fields associated with the infrastructure definition.
| Field | Description |
|---|---|
| maxMemory | The maximum RAM in MiB to allocate to the container. |
| gpus | The number of GPUs to allocate to the container (only relevant for GPU instances). |
| instanceType | The EC2 instance type to use for running the containers. |
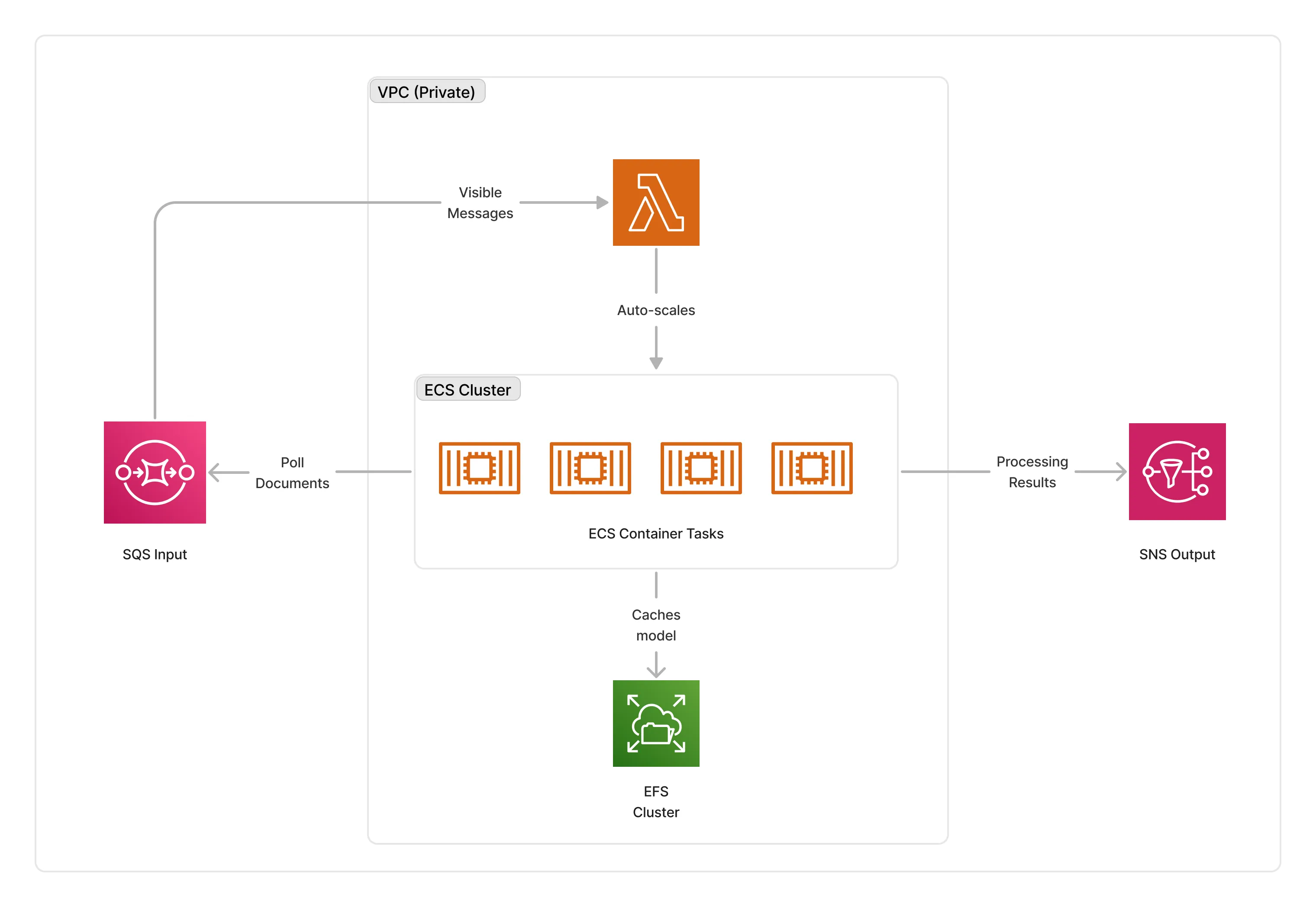
🏗️ Architecture
The Ollama processor can run on either CPU or GPU compute. It packages the Ollama server, and a small Python application loading input documents and running the inference within a Docker container.
To orchestrate deployments, this middleware deploys an ECS auto-scaled cluster of containers that consume documents from the middleware input queue. The cluster is deployed in the private subnet of the given VPC, and caches the models on an EFS storage to optimize cold-starts.
ℹ️ The average cold-start for Ollama containers is around 3 minutes when no instances are running.
🏷️ Properties
Supported Inputs
The supported inputs depend on the specific Ollama model used. The model definitions describe the supported inputs and outputs for each model.
Supported Outputs
The supported outputs depend on the specific Ollama model used. The model definitions describe the supported inputs and outputs for each model.
Supported Compute Types
| Type | Description |
|---|---|
CPU | This middleware supports CPU compute. |
GPU | This middleware supports GPU compute. |
📖 Examples
- Ollama Summarization Pipeline - Builds a pipeline for text summarization using Ollama.