Extractor
The StructuredEntityExtractor middleware can accurately extract structured entities from text documents using large-language models. The middleware uses models hosted on Amazon Bedrock, along with Bedrock Tools, to extract structured entities from text documents.
To ground the process of entity extraction, you specify a Zod typed schema describing your entities and their constraints. This middleware validates the LLM generated data against that schema, and automatically prompts the underlying model with any error generated to improve the quality of the extraction.
📖 Data Extraction
To start using this middleware in your pipelines, you import the StructuredEntityExtractor construct in your CDK stack, and specify the schema you want to use for the extraction.
💁 The below example demonstrates how to use this middleware to extract data from text documents provided by upstream middlewares.
import { z } from 'zod';import { StructuredEntityExtractor } from '@project-lakechain/structured-entity-extractor';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { const cache = new CacheStorage(this, 'Cache');
// The schema to use for the extraction. const schema = z.object({ title: z .string() .describe('The title of the document'), summary: z .string() .describe('A summary of the document') });
// Extract structured data using the given schema. const extractor = new StructuredEntityExtractor.Builder() .withScope(this) .withIdentifier('StructuredEntityExtractor') .withCacheStorage(cache) .withSource(source) .withSchema(schema) // 👈 Specify the schema .build(); }}🤖 Model Selection
You can select the specific Bedrock models to use with this middleware using the .withModel API.
ℹ️ By default, the extractor uses the
anthropic.claude-3-sonnet-20240229-v1:0model from Amazon Bedrock.
import { StructuredEntityExtractor } from '@project-lakechain/structured-entity-extractor';
const extractor = new StructuredEntityExtractor.Builder() .withScope(this) .withIdentifier('StructuredEntityExtractor') .withCacheStorage(cache) .withSource(source) .withSchema(schema) .withModel('anthropic.claude-3-5-sonnet-20240620-v1:0') // 👈 Custom model .build();💁 You can choose amongst the following models for structured entity extraction.
| Model Name | Model identifier |
|---|---|
| Claude 3 Haiku | anthropic.claude-3-haiku-20240307-v1:0 |
| Claude 3 Sonnet | anthropic.claude-3-sonnet-20240229-v1:0 |
| Claude 3.5 Sonnet | anthropic.claude-3-5-sonnet-20240620-v1:0 |
| Claude 3 Opus | anthropic.claude-3-opus-20240229-v1:0 |
| Cohere Command R | cohere.command-r-v1:0 |
| Cohere Command R+ | cohere.command-r-plus-v1:0 |
| Llama 3.1 8B | meta.llama3-1-8b-instruct-v1:0 |
| Llama 3.1 70B | meta.llama3-1-70b-instruct-v1:0 |
| Llama 3.1 405B | meta.llama3-1-405b-instruct-v1:0 |
| Mistral Large | mistral.mistral-large-2402-v1:0 |
| Mistral Large v2 | mistral.mistral-large-2407-v1:0 |
| Mistral Small | mistral.mistral-small-2402-v1:0 |
📝 Instructions
In some cases, it can be very handy to provide domain specific instructions to the model for a better, more accurate, extraction. You can provide these instructions using the .withInstructions API.
💁 For example, if you’re looking to translate a text, and want to ensure that you obtain only the translation with no preamble or other explanation, you can prompt the model with specific instructions as shown below.
import { StructuredEntityExtractor } from '@project-lakechain/structured-entity-extractor';
const extractor = new StructuredEntityExtractor.Builder() .withScope(this) .withIdentifier('StructuredEntityExtractor') .withCacheStorage(cache) .withSource(source) .withSchema(schema) .withInstructions(` You must accurately translate the given text to 'french', while ensuring that you translate exactly the entire text, sentence by sentence. `) .build();📄 Output
The structured data extracted from documents by this middleware are by default returned as a new JSON document that can be consumed by the next middlewares in a pipeline. Alternatively, you can also choose to embed the extracted data inside the document metadata, and leave the original document unchanged.
💁 You can control this behavior using the
.withOutputTypeAPI.
import { StructuredEntityExtractor } from '@project-lakechain/structured-entity-extractor';
const extractor = new StructuredEntityExtractor.Builder() .withScope(this) .withIdentifier('StructuredEntityExtractor') .withCacheStorage(cache) .withSource(source) .withSchema(schema) .withOutputType('metadata') // 👈 Change the output type .build();When setting metadata as the output type, the original document is used as the output of this middleware without any changes. Below is an example of how the extracted data can be accessed from the document metadata.
💁 Click to expand example
{ "specversion": "1.0", "id": "1780d5de-fd6f-4530-98d7-82ebee85ea39", "type": "document-created", "time": "2023-10-22T13:19:10.657Z", "data": { "chainId": "6ebf76e4-f70c-440c-98f9-3e3e7eb34c79", "source": { "url": "s3://bucket/text.txt", "type": "text/plain", "size": 2452, "etag": "1243cbd6cf145453c8b5519a2ada4779" }, "document": { "url": "s3://bucket/text.txt", "type": "text/plain", "size": 2452, "etag": "1243cbd6cf145453c8b5519a2ada4779" }, "metadata": { "custom": { "structured": { "title": "The title of the document", "summary": "A summary of the document" } } }, "callStack": [] }}🌐 Region Selection
You can specify the AWS region in which you want to invoke the Amazon Bedrock model using the .withRegion API. This can be helpful if Amazon Bedrock is not yet available in your deployment region.
💁 By default, the middleware will use the current region in which it is deployed.
import { StructuredEntityExtractor } from '@project-lakechain/structured-entity-extractor';
const extractor = new StructuredEntityExtractor.Builder() .withScope(this) .withIdentifier('StructuredEntityExtractor') .withCacheStorage(cache) .withRegion('us-east-1') // 👈 Custom region .withSource(source) .withSchema(schema) .build();⚙️ Model Parameters
You can optionally forward specific parameters to the underlying LLM using the .withModelParameters method. Below is a description of the supported parameters.
| Parameter | Description | Min | Max | Default |
|---|---|---|---|---|
| temperature | Controls the randomness of the generated text. | 0 | 1 | 0 |
| maxTokens | The maximum number of tokens to generate. | 1 | 4096 | 4096 |
| topP | The cumulative probability of the top tokens to sample from. | 0 | 1 | N/A |
🧩 Composite Events
In addition to handling single documents, the Anthropic text processor also supports composite events as an input. This means that it can take multiple documents and compile them into a single input to the model.
This can come in handy in map-reduce pipelines where you use the Reducer to combine multiple documents into a single input having a similar semantic, for example, multiple pages of a PDF document that you would like the model to extract data from, while keeping the context between the pages.
🏗️ Architecture
This middleware is based on a Lambda compute running on an ARM64 architecture, and integrate with Amazon Bedrock to extract data based on the given documents.
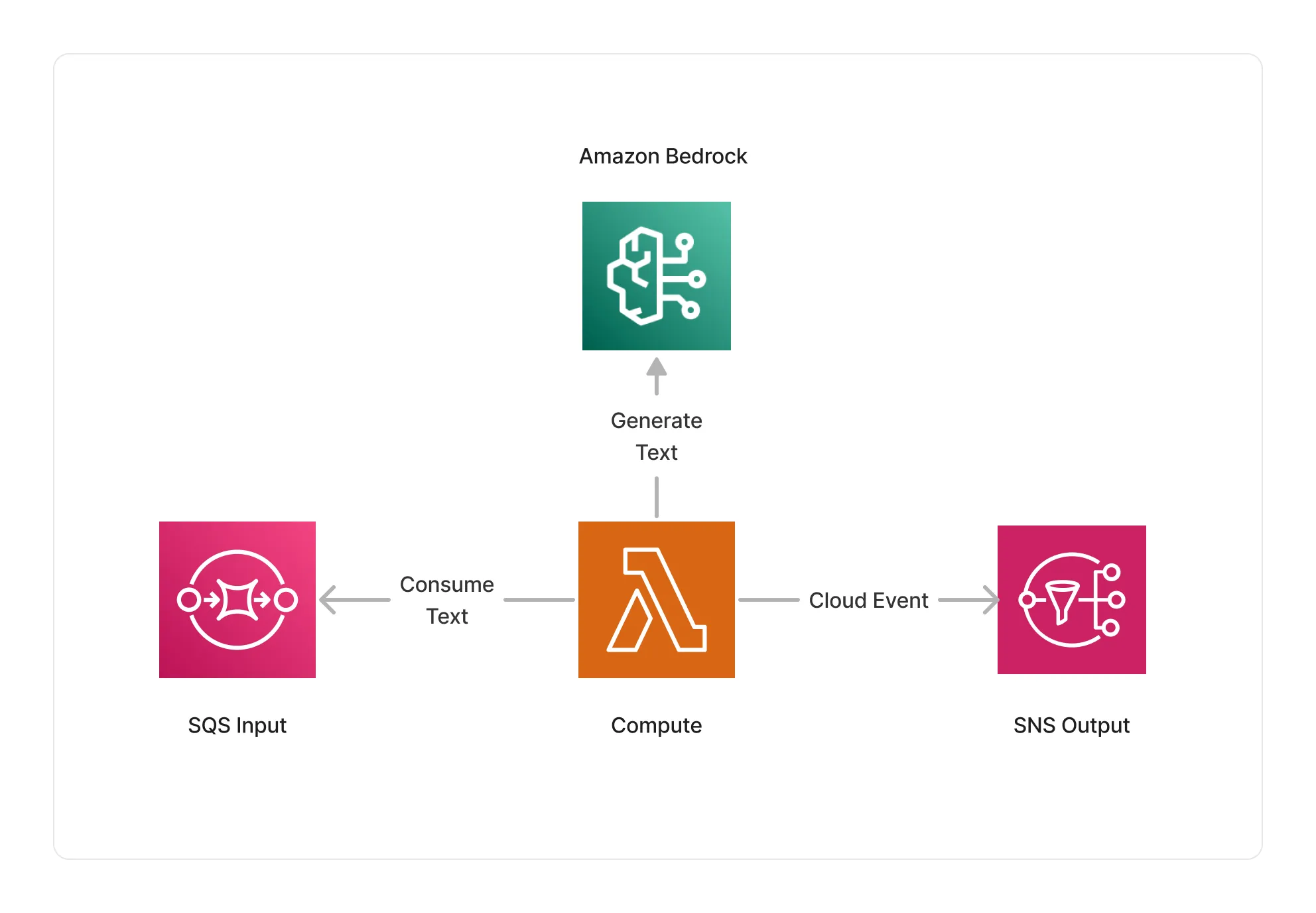
🏷️ Properties
Supported Inputs
| Mime Type | Description |
|---|---|
text/plain | UTF-8 text documents. |
text/markdown | Markdown documents. |
text/csv | CSV documents. |
text/html | HTML documents. |
application/x-subrip | SubRip subtitles. |
text/vtt | Web Video Text Tracks (WebVTT) subtitles. |
application/json | JSON documents. |
application/xml | XML documents. |
application/cloudevents+json | Composite events emitted by the Reducer. |
Supported Outputs
The supported output depends on the output type specified using the .withOutputType API. By default, this middleware will always return a JSON document with the application/json type.
If the output type is set to metadata, the original document is used as the output of this middleware.
Supported Compute Types
| Type | Description |
|---|---|
CPU | This middleware only supports CPU compute. |
📖 Examples
- Structured Data Extraction Pipeline - Builds a pipeline for structured data extraction from documents using Amazon Bedrock.
- Bedrock Translation Pipeline - An example showcasing how to translate documents using LLMs on Amazon Bedrock.