Whisper
The Whisper transcriber enables developers to deploy Whisper models on AWS and use them as part of their processing pipelines to transcribe audio files into text. This middleware deploys a cluster of GPU-enabled containers in a VPC to automate the synthesis process, and keep all data within the boundaries of the AWS account.
📝 Transcribing Audio
To use this middleware, you import it in your CDK stack and instantiate it as part of a pipeline.
import { WhisperTranscriber } from '@project-lakechain/whisper-transcriber';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { // Sample VPC. const vpc = new ec2.Vpc(this, 'Vpc', {});
// The cache storage. const cache = new CacheStorage(this, 'Cache');
// Transcribe audio documents to text. const whisper = new WhisperTranscriber.Builder() .withScope(this) .withIdentifier('WhisperTranscriber') .withCacheStorage(cache) .withSource(source) // 👈 Specify a data source .withVpc(vpc) .build(); }}Specifying a Model
By default, the small model is used to transcribe audio files. You can however specify a different model by passing it to the withModel method.
const whisper = new WhisperTranscriber.Builder() .withScope(this) .withIdentifier('WhisperTranscriber') .withCacheStorage(cache) .withSource(source) .withVpc(vpc) .withModel('medium') .build();You can choose between the following models : tiny, tiny.en, base, base.en, small, small.en, medium, medium.en, large, large-v1, large-v2, and large-v3.
Specifying an Output Format
The Whisper middleware supports transcribing audio documents into different output formats. By default, the vtt subtitle format is used. You can however specify a different output format by passing it to the withOutputFormat method.
const whisper = new WhisperTranscriber.Builder() .withScope(this) .withIdentifier('WhisperTranscriber') .withCacheStorage(cache) .withSource(source) .withVpc(vpc) .withOutputFormat('srt') .build();You can choose between the following output formats : srt, vtt, tsv, txt, and json.
Specifying an Engine
By default, this middleware uses the OpenAI Whisper implementation to transcribe audio documents. It also supports the Faster Whisper engine to perform transcriptions. You can specify the engine to use by passing it to the withEngine method.
const whisper = new WhisperTranscriber.Builder() .withScope(this) .withIdentifier('WhisperTranscriber') .withCacheStorage(cache) .withSource(source) .withVpc(vpc) .withEngine('openai_whisper') .build();You can choose between the following engines : openai_whisper and faster_whisper.
Auto-Scaling
The cluster of containers deployed by this middleware will auto-scale based on the number of documents that need to be processed. The cluster scales up to a maximum of 5 instances by default, and scales down to zero when there are no images to process.
ℹ️ You can configure the maximum amount of instances that the cluster can auto-scale to by using the
withMaxInstancesmethod.
const whisper = new WhisperTranscriber.Builder() .withScope(this) .withIdentifier('WhisperTranscriber') .withCacheStorage(cache) .withSource(source) .withVpc(vpc) .withMaxInstances(10) .build();🏗️ Architecture
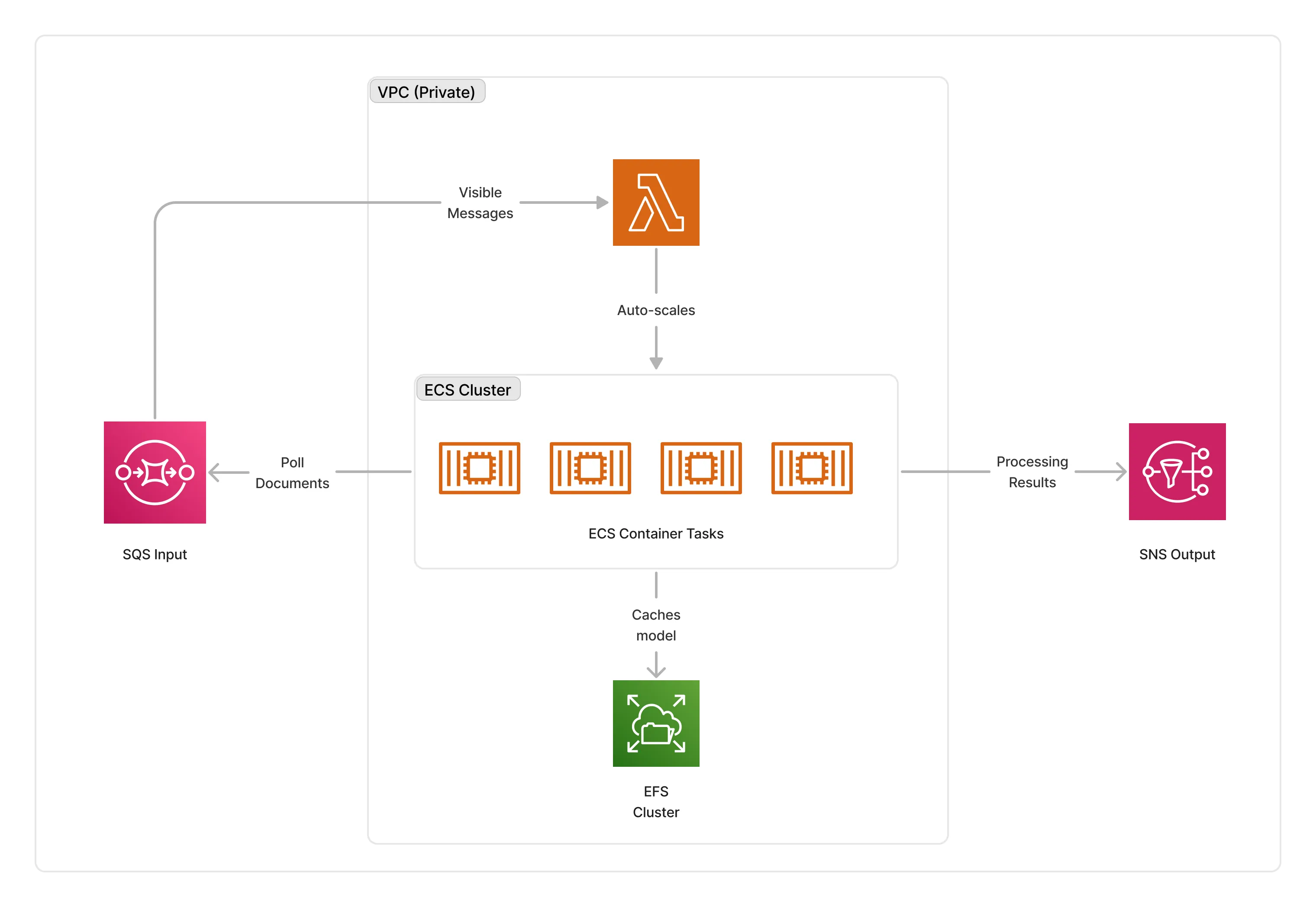
The Whisper transcriber requires GPU-enabled instances (g4dn.2xlarge for large models, and g4dn.xlarge for other models) to run transcription jobs. It is also optionally compatible with CPU based instances, in which case it will run c6a.2xlarge instances.
To orchestrate transcriptions, this middleware deploys an ECS auto-scaled cluster of containers that consume documents from the middleware input queue. The cluster is deployed in the private subnet of the given VPC, and caches the models on an EFS storage to optimize cold-starts.
ℹ️ The average cold-start for the Whisper transcriber is around 3 minutes when no instances are running.
🏷️ Properties
Supported Inputs
| Mime Type | Description |
|---|---|
audio/mpeg | MP3 audio documents. |
audio/mp4 | MP4 audio documents. |
audio/x-m4a | M4A audio documents. |
audio/wav | WAV audio documents. |
audio/webm | WEBM audio documents. |
audio/flac | FLAC audio documents. |
audio/x-flac | FLAC audio documents. |
Supported Outputs
| Mime Type | Description |
|---|---|
application/x-subrip | SRT subtitle documents. |
text/vtt | VTT subtitle documents. |
text/plain | TXT subtitle documents. |
text/tab-separated-values | TSV subtitle documents. |
application/json | JSON subtitle documents. |
Supported Compute Types
| Type | Description |
|---|---|
CPU | This middleware supports CPU compute. |
GPU | This middleware supports GPU compute. |
📖 Examples
- Whisper Pipeline - Builds a pipeline for transcribing audio documents using the OpenAI Whisper model.