JMESPath
The JMESPath processor makes it easy to process and transform JSON documents using JMESPath expressions. JMESPath is a query language for JSON that allows you to extract and transform elements from JSON documents. This middleware brings the power of JMESPath to your pipelines to apply them at scale.
🔎 Querying JSON
To use this middleware, you import it in your CDK stack and instantiate it as part of a pipeline.
💁 The below example takes JSON documents uploaded into a source S3 bucket, and extracts the
namefield part of an array.
import { S3EventTrigger } from '@project-lakechain/s3-event-trigger';import { JMESPathProcessor } from '@project-lakechain/jmespath-processor';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { // The cache storage. const cache = new CacheStorage(this, 'Cache');
// Create the S3 event trigger. const trigger = new S3EventTrigger.Builder() .withScope(this) .withIdentifier('Trigger') .withCacheStorage(cache) .withBucket(bucket) .build();
// Apply JMESPath expression on uploaded JSON documents. trigger.pipe(new JMESPathProcessor.Builder() .withScope(this) .withIdentifier('JMESPathProcessor') .withCacheStorage(cache) .withSource(trigger) .withExpression('array[*].name') // 👈 JMESPath expression .build()); }}📄 Output
This middleware applies the given JMESPath expression to each processed JSON document and publishes the output of the expression to the next middlewares in the pipeline.
If the expression returns an object (i.e object literal, array, etc.), the result document will have the application/json mime type, otherwise we consider the result as a scalar and its mime type will be text/plain.
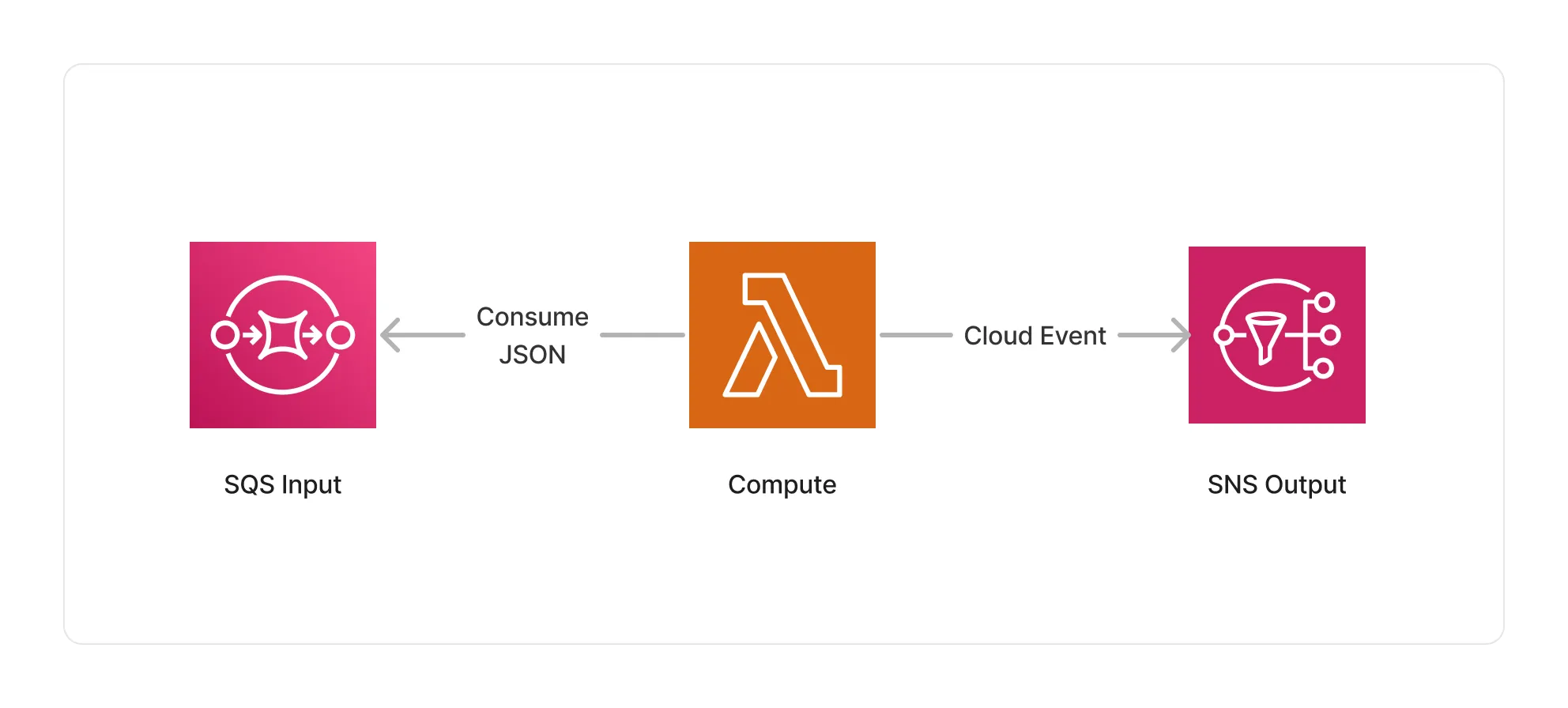
🏗️ Architecture
This middleware is based on a Lambda compute running the JMESPath Node.js library to process JSON documents.
🏷️ Properties
Supported Inputs
| Mime Type | Description |
|---|---|
application/json | JSON documents. |
Supported Outputs
| Mime Type | Description |
|---|---|
application/json | JSON documents. |
text/plain | Plain text documents. |
Supported Compute Types
| Type | Description |
|---|---|
CPU | This middleware only supports CPU compute. |
📖 Examples
- JMESPath Parsing Pipeline - An example showcasing how parse JSON documents at scale.