Titan
Unstable API
0.8.0
@project-lakechain/bedrock-text-processors
The Titan text processor allows you to leverage Amazon Titan machine-learning models on Amazon Bedrock within your pipelines. Using this construct, you can use prompt engineering techniques to transform text documents, including, text summarization, text translation, information extraction, and more!
📝 Text Generation
To start using Titan models in your pipelines, you import the TitanTextProcessor construct in your CDK stack, and specify the specific text model you want to use.
💁 The below example demonstrates how to use the Titan text processor to summarize input documents uploaded to an S3 bucket.
import { S3EventTrigger } from '@project-lakechain/s3-event-trigger';import { TitanTextProcessor, TitanTextModel } from '@project-lakechain/bedrock-text-processors';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { const cache = new CacheStorage(this, 'Cache');
// Create the S3 event trigger. const trigger = new S3EventTrigger.Builder() .withScope(this) .withIdentifier('Trigger') .withCacheStorage(cache) .withBucket(bucket) .build();
// Transforms input documents using an Amazon Titan model. const titan = new TitanTextProcessor.Builder() .withScope(this) .withIdentifier('TitanTextProcessor') .withCacheStorage(cache) .withSource(source) .withModel(TitanTextModel.AMAZON_TITAN_TEXT_PREMIER_V1) .withPrompt(` Give a detailed summary of the text with the following constraints: - Write the summary in the same language as the original text. - Keep the original meaning, style, and tone of the text in the summary. `) .withModelParameters({ maxTokenCount: 3072 }) .build(); }}🤖 Model Selection
You can select the specific Titan model to use with this middleware using the .withModel API.
import { TitanTextProcessor, TitanTextModel } from '@project-lakechain/bedrock-text-processors';
const titan = new TitanTextProcessor.Builder() .withScope(this) .withIdentifier('TitanTextProcessor') .withCacheStorage(cache) .withSource(source) .withModel(TitanTextModel.AMAZON_TITAN_TEXT_LITE_V1) // 👈 Specify a model .withPrompt(prompt) .build();💁 You can choose amongst the following models — see the Bedrock documentation for more information.
| Model Name | Model identifier |
|---|---|
| AMAZON_TITAN_TEXT_EXPRESS_V1 | amazon.titan-text-express-v1 |
| AMAZON_TITAN_TEXT_LITE_V1 | amazon.titan-text-lite-v1 |
| AMAZON_TITAN_TEXT_PREMIER_V1 | amazon.titan-text-premier-v1:0 |
🌐 Region Selection
You can specify the AWS region in which you want to invoke Amazon Bedrock using the .withRegion API. This can be helpful if Amazon Bedrock is not yet available in your deployment region.
💁 By default, the middleware will use the current region in which it is deployed.
import { TitanTextProcessor, TitanTextModel } from '@project-lakechain/bedrock-text-processors';
const titan = new TitanTextProcessor.Builder() .withScope(this) .withIdentifier('TitanTextProcessor') .withCacheStorage(cache) .withSource(source) .withRegion('eu-central-1') // 👈 Alternate region .withModel(TitanTextModel.AMAZON_TITAN_TEXT_EXPRESS_V1) .withPrompt(prompt) .build();⚙️ Model Parameters
You can optionally forward specific parameters to the underlying LLM using the .withModelParameters method. Below is a description of the supported parameters.
💁 See the Bedrock Inference Parameters for more information on the parameters supported by the different models.
| Parameter | Description | Min | Max | Default |
|---|---|---|---|---|
| temperature | Controls the randomness of the generated text. | 0 | 1 | 0.7 |
| maxTokens | The maximum number of tokens to generate. | 1 | Model dependant | 512 |
| topP | The cumulative probability of the top tokens to sample from. | 0 | 1 | 0.9 |
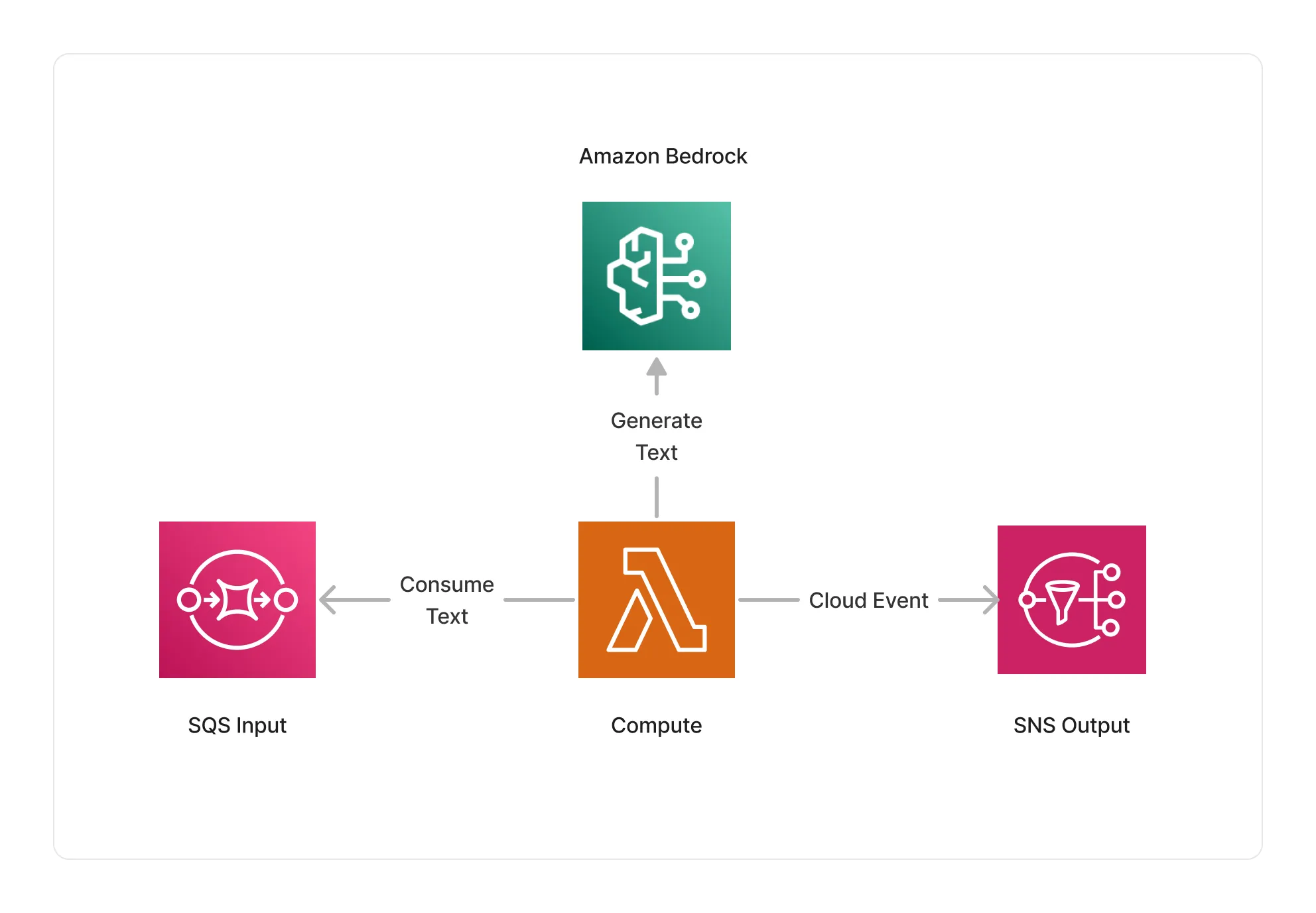
🏗️ Architecture
This middleware is based on a Lambda compute running on an ARM64 architecture, and integrate with Amazon Bedrock to generate text based on the given prompt and input documents.
🏷️ Properties
Supported Inputs
| Mime Type | Description |
|---|---|
text/plain | UTF-8 text documents. |
text/markdown | Markdown documents. |
text/csv | CSV documents. |
text/html | HTML documents. |
application/x-subrip | SubRip subtitles. |
text/vtt | Web Video Text Tracks (WebVTT) subtitles. |
application/json | JSON documents. |
application/json+scheduler | Used by the Scheduler middleware. |
Supported Outputs
| Mime Type | Description |
|---|---|
text/plain | UTF-8 text documents. |
Supported Compute Types
| Type | Description |
|---|---|
CPU | This middleware only supports CPU compute. |
📖 Examples
- Titan Summarization Pipeline - Builds a pipeline for text summarization using Amazon Titan models on Amazon Bedrock.