Rekognition
Unstable API
0.8.0
@project-lakechain/rekognition-image-processor
The Rekognition image processor enables customers to leverage the power of Amazon Rekognition and its computer vision capabilities within their image processing pipelines. Easily integrate features such as face, object, label, or text detection on your images at scale.
💡 Intents
To use this middleware, you define an intent that specifies the type of processing you want to operate on images. Intents expose a powerful functional API making it easy to describe the Amazon Rekognition capabilities you want to leverage when processing images.
In the following sections, we will explore several use-cases that demonstrate how to use intents.
Detecting Faces
Let’s start with a simple example where we use Amazon Rekognition’s ability to identify faces in images. In the below example, we define an intent that will extract face information from images and store them within the document metadata.
💁 We’re using the intent domain-specific language (DSL) to express actions within an intent.
import { RekognitionImageProcessor, dsl as r } from '@project-lakechain/rekognition-image-processor';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { // The cache storage. const cache = new CacheStorage(this, 'Cache');
// Create the Rekognition image processor. const rekognitionProcessor = new RekognitionImageProcessor.Builder() .withScope(this) .withIdentifier('ImageProcessor') .withCacheStorage(cache) .withSource(source) // 👈 Specify a data source .withIntent( r.detect().faces() ) .build(); }}ℹ️ Please note that before using Amazon Rekognition’s face detection capabilities, you should read the Amazon Rekognition Guidelines on Face Attributes.
Detecting Labels
Another powerful feature of Amazon Rekognition is its ability to detect the labels and the objects associated with an image. You can format your intent to identify labels and objects as follows.
import { RekognitionImageProcessor, dsl as r } from '@project-lakechain/rekognition-image-processor';
const rekognitionProcessor = new RekognitionImageProcessor.Builder() .withScope(this) .withIdentifier('ImageProcessor') .withCacheStorage(cache) .withSource(source) .withIntent( r.detect().labels() ) .build();Detecting Text
Amazon Rekognition can also detect text within images. Format your intent as follows to enable text detection.
import { RekognitionImageProcessor, dsl as r } from '@project-lakechain/rekognition-image-processor';
const rekognitionProcessor = new RekognitionImageProcessor.Builder() .withScope(this) .withIdentifier('ImageProcessor') .withCacheStorage(cache) .withSource(source) .withIntent( r.detect().text() ) .build();PPE Detection
To detect personal protective equipment (PPE) within images, you can express your intent as follows.
import { RekognitionImageProcessor, dsl as r } from '@project-lakechain/rekognition-image-processor';
const rekognitionProcessor = new RekognitionImageProcessor.Builder() .withScope(this) .withIdentifier('ImageProcessor') .withCacheStorage(cache) .withSource(source) .withIntent( r.detect().ppe() ) .build();Combining Actions
All actions can be combined within a single intent, and the Rekognition image processor will execute them in the order in which they are defined.
import { RekognitionImageProcessor, dsl as r } from '@project-lakechain/rekognition-image-processor';
const rekognitionProcessor = new RekognitionImageProcessor.Builder() .withScope(this) .withIdentifier('ImageProcessor') .withCacheStorage(cache) .withSource(source) .withIntent( r.detect() .faces() .labels() .text() .ppe() ) .build();📑 Using Filters
Each action within the DSL supports one or more filters that you can apply to it. For example, the faces action part of the detect verb supports different filters.
ℹ️ The below example uses the
MinConfidencefilter to detect faces with a confidence level of 90% or higher.
import { RekognitionImageProcessor, dsl as r } from '@project-lakechain/rekognition-image-processor';
const rekognitionProcessor = new RekognitionImageProcessor.Builder() .withScope(this) .withIdentifier('ImageProcessor') .withCacheStorage(cache) .withSource(source) .withIntent( r.detect() .faces(r.confidence(90)) ) .build();Chaining Filters
You can also chain multiple filters together to express more complex intent actions.
ℹ️ The below example detects faces having a confidence of at least 90%, having a
smileattribute, and limits results to a maximum of 10 faces.
import { RekognitionImageProcessor, dsl as r } from '@project-lakechain/rekognition-image-processor';
const rekognitionProcessor = new RekognitionImageProcessor.Builder() .withScope(this) .withIdentifier('ImageProcessor') .withCacheStorage(cache) .withSource(source) .withIntent( r.detect() .faces( r.confidence(90), r.attributes(r.smile()), r.limit(10) ) ) .build();🏗️ Architecture
The Rekognition image processor uses AWS Lambda as its compute, using an ARM64 architecture. The Lambda function is integrated with the Amazon Rekognition service, and issues the appropriate API calls to process images given the intent defined by the user.
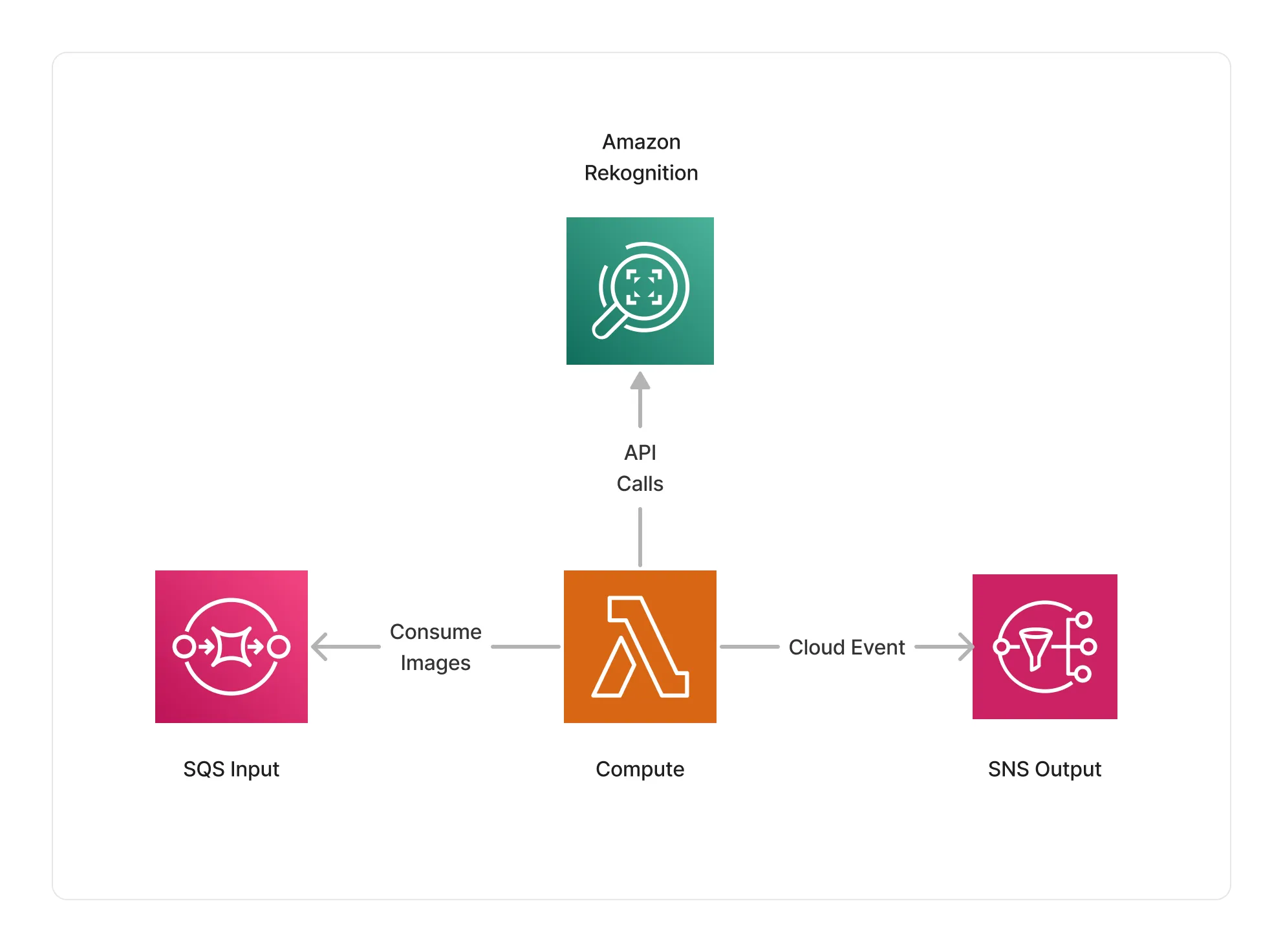
🏷️ Properties
Supported Inputs
| Mime Type | Description |
|---|---|
image/jpeg | JPEG images. |
image/png | PNG images. |
Supported Outputs
This middleware supports as outputs the same types as the supported inputs.
Supported Compute Types
| Type | Description |
|---|---|
CPU | This middleware only supports CPU compute. |
📖 Examples
- Face Detection Pipeline - An example showcasing how to build face detection pipelines using Project Lakechain.
- Document Indexing Pipeline - End-to-end document metadata extraction with OpenSearch.
- Image Moderation Pipeline - A pipeline demonstrating how to classify moderated images.