Anthropic
Unstable API
0.8.0
@project-lakechain/bedrock-text-processors
The Anthropic text processor allows you to leverage large-language models provided by Anthropic on Amazon Bedrock within your pipelines. Using this construct, you can use prompt engineering techniques to transform text documents, including, text summarization, text translation, information extraction, and more!
📝 Text Generation
To start using Anthropic models in your pipelines, you import the AnthropicTextProcessor construct in your CDK stack, and specify the specific text model you want to use.
💁 The below example demonstrates how to use the Anthropic text processor to summarize input documents uploaded to an S3 bucket.
import { S3EventTrigger } from '@project-lakechain/s3-event-trigger';import { AnthropicTextProcessor, AnthropicTextModel } from '@project-lakechain/bedrock-text-processors';import { CacheStorage } from '@project-lakechain/core';
class Stack extends cdk.Stack { constructor(scope: cdk.Construct, id: string) { const cache = new CacheStorage(this, 'Cache');
// Monitor the S3 bucket for new documents. const trigger = new S3EventTrigger.Builder() .withScope(this) .withIdentifier('Trigger') .withCacheStorage(cache) .withBucket(bucket) .build();
// Transforms input documents using an Anthropic model. const anthropic = new AnthropicTextProcessor.Builder() .withScope(this) .withIdentifier('AnthropicTextProcessor') .withCacheStorage(cache) .withSource(trigger) .withModel(AnthropicTextModel.ANTHROPIC_CLAUDE_V3_HAIKU) .withPrompt(` Give a detailed summary of the text with the following constraints: - Write the summary in the same language as the original text. - Keep the original meaning, style, and tone of the text in the summary. `) .withModelParameters({ temperature: 0.5, max_tokens: 4096 }) .build(); }}ℹ️ Tip - Note that the Claude v3 family of models is multi-modal, and supports both text and image documents as an input.
🤖 Model Selection
You can select the specific Anthropic model to use with this middleware using the .withModel API.
import { AnthropicTextProcessor, AnthropicTextModel } from '@project-lakechain/bedrock-text-processors';
const anthropic = new AnthropicTextProcessor.Builder() .withScope(this) .withIdentifier('AnthropicTextProcessor') .withCacheStorage(cache) .withSource(source) .withModel(AnthropicTextModel.ANTHROPIC_CLAUDE_V3_SONNET) // 👈 Model selection .withPrompt(prompt) .build();💁 You can choose amongst the following models — see the Bedrock documentation for more information.
| Model Name | Model identifier |
|---|---|
| ANTHROPIC_CLAUDE_INSTANT_V1 | anthropic.claude-instant-v1 |
| ANTHROPIC_CLAUDE_V2 | anthropic.claude-v2 |
| ANTHROPIC_CLAUDE_V2_1 | anthropic.claude-v2:1 |
| ANTHROPIC_CLAUDE_V3_HAIKU | anthropic.claude-3-haiku-20240307-v1:0 |
| ANTHROPIC_CLAUDE_V3_SONNET | anthropic.claude-3-sonnet-20240229-v1:0 |
| ANTHROPIC_CLAUDE_V3_5_SONNET | anthropic.claude-3-5-sonnet-20240620-v1:0 |
| ANTHROPIC_CLAUDE_V3_OPUS | anthropic.claude-3-opus-20240229-v1:0 |
🌐 Region Selection
You can specify the AWS region in which you want to invoke Amazon Bedrock using the .withRegion API. This can be helpful if Amazon Bedrock is not yet available in your deployment region.
💁 By default, the middleware will use the current region in which it is deployed.
import { AnthropicTextProcessor, AnthropicTextModel } from '@project-lakechain/bedrock-text-processors';
const anthropic = new AnthropicTextProcessor.Builder() .withScope(this) .withIdentifier('AnthropicTextProcessor') .withCacheStorage(cache) .withSource(source) .withRegion('eu-central-1') // 👈 Alternate region .withModel(AnthropicTextModel.ANTHROPIC_CLAUDE_V3_HAIKU) .withPrompt(prompt) .build();⚙️ Model Parameters
You can forward specific parameters to the text models using the .withModelParameters method. Below is a description of the supported parameters.
| Parameter | Description | Min | Max | Default |
|---|---|---|---|---|
| temperature | Controls the randomness of the generated text. | 0 | 1 | N/A |
| max_tokens | The maximum number of tokens to generate. | 1 | 4096 | 4096 |
| top_p | The cumulative probability of the top tokens to sample from. | 0 | 1 | N/A |
| top_k | The number of top tokens to sample from. | 1 | 100000000 | N/A |
💬 Prompts
The Anthropic text processor exposes an interface allowing users to specify prompts to the underlying model. A prompt is a piece of text that guides the model on how to generate the output. Using this middleware you can define 3 types of prompts to the Anthropic model.
| Type | Method | Optional | Description |
|---|---|---|---|
| User prompt | .withPrompt | No | The user prompt is text that provides instructions to the model. |
| System prompt | .withSystemPrompt | Yes | The system prompt is text that provides context to the model. |
| Assistant Prefill | .withAssistantPrefill | Yes | The assistant prefill is text that directly guides the model on how to further complete its output. |
💁 The below example demonstrates how to use both a user prompt and an assistant prefill to guide the model into outputting valid JSON.
import { AnthropicTextProcessor, AnthropicTextModel } from '@project-lakechain/bedrock-text-processors';
const anthropic = new AnthropicTextProcessor.Builder() .withScope(this) .withIdentifier('AnthropicTextProcessor') .withCacheStorage(cache) .withSource(source) .withModel(AnthropicTextModel.ANTHROPIC_CLAUDE_V3_HAIKU) .withPrompt('Extract metadata from the document as a JSON document.') .withAssistantPrefill('{') .build();🧩 Composite Events
In addition to handling single documents, the Anthropic text processor also supports composite events as an input. This means that it can take multiple text and image documents and compile them into a single input to the model.
This can come in handy in map-reduce pipelines where you use the Reducer to combine multiple documents into a single input having a similar semantic, for example, multiple pages of a PDF document that you would like the model to summarize as a whole, while keeping the context between the pages.
🏗️ Architecture
This middleware is based on a Lambda compute running on an ARM64 architecture, and integrate with Amazon Bedrock to generate text based on the given prompt and input documents.
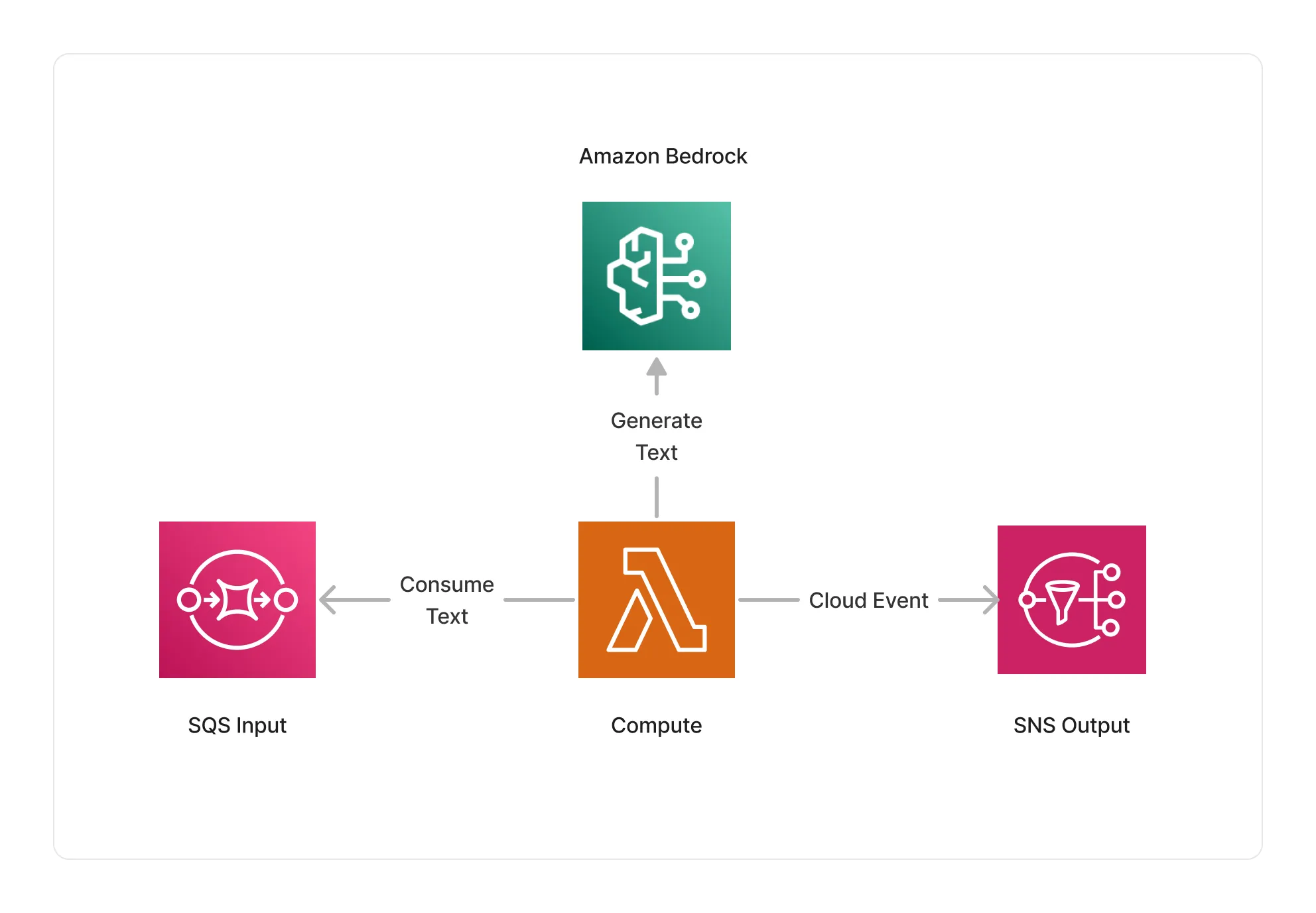
🏷️ Properties
Supported Inputs
The supported inputs depend on the selected model as the Claude v3 models are multi-modal and support text and images, while the Claude v2 model only support text. The following table lists the supported inputs for each model.
| Model | Supported Inputs |
|---|---|
ANTHROPIC_CLAUDE_INSTANT_V1 | Text |
ANTHROPIC_CLAUDE_V2 | Text |
ANTHROPIC_CLAUDE_V2_1 | Text |
ANTHROPIC_CLAUDE_V3_HAIKU | Text, Image |
ANTHROPIC_CLAUDE_V3_SONNET | Text, Image |
ANTHROPIC_CLAUDE_V3_5_SONNET | Text, Image |
ANTHROPIC_CLAUDE_V3_OPUS | Text, Image |
Text Inputs
Below is a list of supported text inputs.
| Mime Type | Description |
|---|---|
text/plain | UTF-8 text documents. |
text/markdown | Markdown documents. |
text/csv | CSV documents. |
text/html | HTML documents. |
application/x-subrip | SubRip subtitles. |
text/vtt | Web Video Text Tracks (WebVTT) subtitles. |
application/json | JSON documents. |
application/xml | XML documents. |
Image Inputs
Below is a list of supported image inputs.
| Mime Type | Description |
|---|---|
image/jpeg | JPEG images. |
image/png | PNG images. |
image/gif | GIF images. |
image/webp | WebP images. |
Composite Inputs
The middleware also supports composite events as an input, which can be used to combine multiple text and image documents into a single input for the model.
| Mime Type | Description |
|---|---|
application/cloudevents+json | Composite events emitted by the Reducer. |
Supported Outputs
| Mime Type | Description |
|---|---|
text/plain | UTF-8 text documents. |
Supported Compute Types
| Type | Description |
|---|---|
CPU | This middleware only supports CPU compute. |
📖 Examples
- Claude Summarization Pipeline - Builds a pipeline for text summarization using Amazon Bedrock and Anthropic Claude.
- Audio Recording Summarization Pipeline - Builds a pipeline for summarizing audio recordings using Amazon Transcribe and Amazon Bedrock.